1 找到conf/schema.xml并备份

2 固定分片hash算法
本条规则类似于十进制的求模运算,区别在于是二进制的操作,是取id的二进制低10位,即id二进制 。 此算法的优点在于如果按照 10进制取模运算,在连续插入1-10 时候1-10会被分到1-10个分片,增 大了插入的事务控制难度,而此算法根据二进制则可能会分到连续的分片,减少插入事务事务控制难度。
<tableRule name="xp-sharding-hash">
<rule>
<columns>id</columns>
<algorithm>xp-mo-rule-hash</algorithm>
</rule>
</tableRule>
配置说明: 上面columns 标识将要分片的表字段,algorithm 分片函数, partitionCount 分片个数列表,partitionLength 分片范围列表 分区长度:默认为最大2^n=1024 ,即最大支持1024分区 约束 : count,length两个数组的长度必须是一致的。 1024 = sum((count[i]*length[i])). count 和length两个向量的点积恒等于1024
用法例子: 本例的分区策略:希望将数据水平分成3 份,前两份各占25%,第三份占50%。(故本例非均匀分区)
// |<———————1024———————————>|
// |<—-256—>|<—-256—>|<———-512————->|
| partition0 | partition1 | partition2 |
// | 共2份,故count[0]=2 | 共1份,故count[1]=1 | int[] count = new int[] { 2, 1 }; int[] length = new int[] { 256, 512 };
<function name="xp-mo-rule-hash"
class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">2,1</property>
<property name="partitionLength">256,512</property>
</function>partitionCount分别的数量级
partitionLength 分别数量级的长度
以上的配置是2*256+1*512=1024 那么1024就是分区的模 必须有(2+1)个datanode节点
配置完,重启mycat
3 测试
将sys_test2 表设计出来,然后把它的分片规则修改为区间内轮询的概念
CREATE TABLE sys_test2(
id INT PRIMARY KEY ,
testname VARCHAR(20) NOT NULL
);插入测试—第一圈
1-255 dn1
256-511 dn2
512-1023 dn3
插入测试—第二圈
(1024)-(1024+255) dn1
(1024+256)-(1024+511) dn2
(1024+512)-(2047) dn3
4 执行过程如下
EXPLAIN INSERT INTO sys_test2(id,testname) VALUES(1,'博主很帅');

EXPLAIN INSERT INTO sys_test2(id,testname) VALUES(513,'博主非常帅');

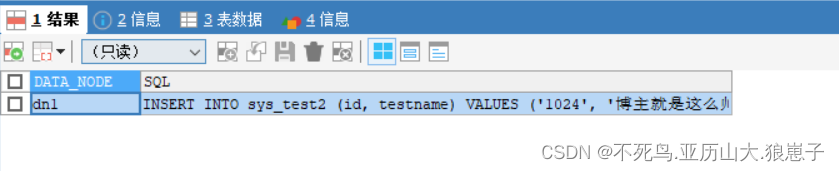
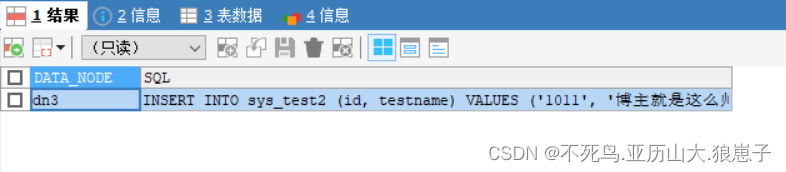
EXPLAIN INSERT INTO sys_test2(id,testname) VALUES(1011,'博主就是这么帅');
EXPLAIN INSERT INTO sys_test2(id,testname) VALUES(1024,'博主就是这么帅');