飞桨神经网络与深度学习-机器学习

目录
飞桨神经网络与深度学习-机器学习
1.机器学习概述
2.机器学习实践五要素
2.1.数据
2.2.模型
2.3.学习准则
2.4.优化算法
2.5.评估标准
3.实现简单的线性回归模型
3.1.数据集构建
3.2.模型构建
3.3.损失函数
3.4.模型优化
3.5.模型训练
3.6.模型评估
4.多项式回归
4.1.数据集构建
4.2.模型构建
4.3.模型训练
4.4.模型评估
5.Runner类介绍
6.基于线性回归的波士顿房价预测
6.1.数据处理
6.1.1.数据集介绍
6.1.2.数据清洗
6.1.3.数据集划分
6.1.4.特征工程
6.2.模型构建
6.3.完善Runner类
6.4 模型训练
6.5 模型测试
6.6 模型预测
1.机器学习概述
机器学习(Machine Learning,ML)就是让计算机从数据中进行自动学习,得到某种知识(或者规律)。作为一门学科,机器学习通常指的是一类问题以及解决这类问题的方法,即如何从观测数据(样本)中寻找规律,并利用学习到的规律(模型)对未知或无法观测的数据进行预测。
模型解读:介绍机器学习实践五要素(数据、模型、学习准则、优化算法、评估指标)的原理剖析和相应的代码实现,通过理论和代码的结合,加深机器学习的理解。
案例实践:基于机器学习线性回归方法,通过数据处理、模型构建、训练配置、组装训练框架Runner、模型训练和模型预测等过程完成波士顿房价预测任务。
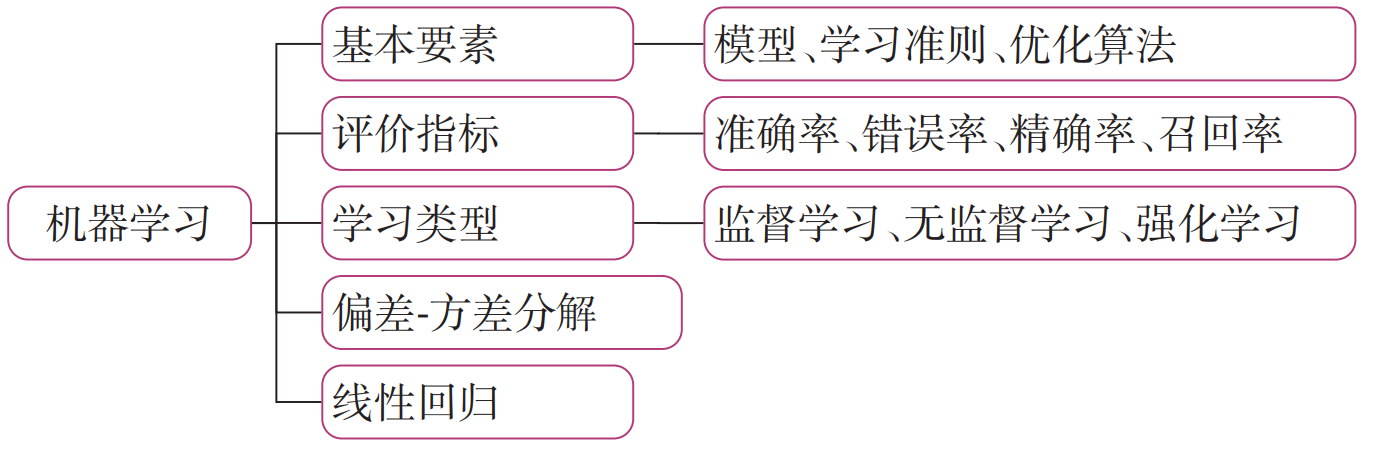
2.机器学习实践五要素
要通过机器学习来解决一个特定的任务时,我们需要准备5个方面的要素:
-
数据集:收集任务相关的数据集用来进行模型训练和测试,可分为训练集、验证集和测试集;
-
模型:实现输入到输出的映射,通常为可学习的函数;
-
学习准则:模型优化的目标,通常为损失函数和正则化项的加权组合;
-
优化算法:根据学习准则优化机器学习模型的参数;
-
评价指标:用来评价学习到的机器学习模型的性能.
机器学习系统示范:
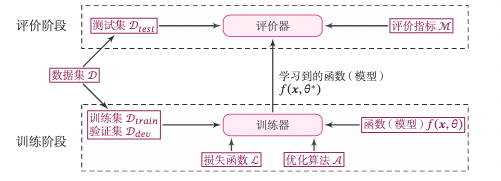
该图给出实现一个完整的机器学习系统的主要环节和要素。从流程上来看,实现机器学习系统可以封为两个阶段:训练阶段和评价阶段。训练阶段需要用到训练集、验证集、待学习的训练、评价指标体系,得到模型的性能评价。
2.1.数据
在实践过程中,数据的质量会很大程度上影响模型最终的性能,通常数据预处理是完成机器学习时间的第一步,噪音越少,规模越大、覆盖范围月光的数据集往往能够训练出性能更好的模型。数据集预处理可以分为两个环节:先对收集到的数据进行基本的预处理可分为两个环节:先对收集到的数据进行基本的预处理,如基本的统计、特征归一化和异常值处理;再将数据划分为训练集、验证集(开发集)和测试集。
-
训练集:用于模型训练时调整模型的参数,在这份数据集上的误差被称为训练误差;
-
验证集(开发集):对于复杂的模型,常常有一些超参数需要调节,因此需要尝试多种超参数的组合来分别训练多个模型,然后对比它们在验证集上的表现,选择一组相对最好的超参数,最后才使用这组参数下训练的模型在测试集上评估测试误差。
-
测试集:模型在这份数据集上的误差被称为测试误差。训练模型的目的是为了通过从训练数据中找到规律来预测未知数据,因此测试误差是更能反映出模型表现的指标。
数据划分时要考虑到两个因素:更多的训练数据会降低参数估计的方差,从而得到更可信的模型;而更多的测试数据会降低测试误差的方差,从而得到更可信的测试误差。如果给定的数据集没有做任何划分,我们一般可以大致按照7:3或者8:2的比例划分训练集和测试集,再根据7:3或者8:2的比例从训练集中再次划分出训练集和验证集。
需要强调的是,测试集只能用来评测模型最终的性能,在整个模型训练过程中不能有测试集的参与。
2.2.模型
有了数据后,我们可以用数据来训练模型。我们希望能让计算机从一个函数集合 F={f1(x),f2(x),⋯ }中 自动寻找一个“最优”的函数f(x) 来近似每个样本的特征向量 x 和标签 y之间 的真实映射关系,实际上这个函数集合也被称为假设空间,在实际问题中,假设空间F通常为一个参数化的函数族
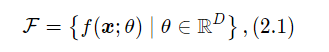
其中f(x;θ)是参数为θ的函数,也称为模型,𝐷 为参数的数量。
常见的假设空间可以分为线性和非线性两种,对应的模型 f 也分别称为线性模型和非线性模型。线性模型的假设空间为一个参数化的线性函数族,即:
![]()
其中参数θ 包含了权重向量w和偏置b。
线性模型可以由非线性基函数ϕ(x)变为非线性模型,从而增强模型能力:
![]()
其中ϕ(x)=[ϕ1(x),ϕ2(x),⋯ ,ϕK(x)],ϕ(x)=[ϕ1(x),ϕ2(x),⋯,ϕ**K(x)]⊤为𝐾 个非线性基函数组成的向量,参数θ 包含了权重向量w和偏置b。
2.3.学习准则
为了衡量一个模型的好坏,我们需要定义一个损失函数L(y,f(x;θ))。损失函数是一个非负实数函数,用来量化模型预测标签和真实标签之间的差异。常见的损失函数有 0-1 损失、平方损失函数、交叉熵损失函数等。
机器学习的目标就是找到最优的模型f(x;θ*)在真实数据分布上损失函数的期望最小。然而在实际中,我们无法获得真实数据分布,通常会用在训练集上的平均损失替代。
一个模型在训练集D={(x(n),y(n))}上的平均损失称为经验风险{Empirical Risk},即:
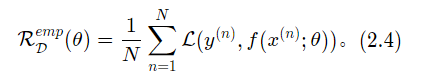
L(y,f(x;θ))为损失函数。损失函数是一个非负实数函数,用来量化模型预测和真实标签之间的差异。常见的损失函数有0-1损失、平方损失函数、交叉熵损失函数等。
在通常情况下,我们可以通过使得经验风险最小化来获得具有预测能力的模型。然而,当模型比较复杂或训练数据量比较少时,经验风险最小化获得的模型在测试集上的效果比较差。而模型在测试集上的性能才是我们真正关心的指标.当一个模型在训练集错误率很低,而在测试集上错误率较高时,通常意味着发生了过拟合(Overfitting)现象。为了缓解模型的过拟合问题,我们通常会在经验损失上加上一定的正则化项来限制模型能力。
过拟合通常是由于模型复杂度比较高引起的。在实践中,最常用的正则化方式有对模型的参数进行约束,比如ℓ1或者ℓ2范数约束。这样,我们就得到了结构风险(Structure Risk)。
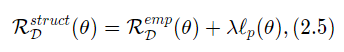
其中λ为正则化系数,p=1或2表示ℓ1或者ℓ2范数。
2.4.优化算法
在有了优化目标之后,机器学习问题就转换为优化问题,我们可以利用已知的优化算法来学习最优的参数。当优化函数为凸函数时,我们可以令参数的偏导数等于0来计算最优参数的解析解。当优化函数为非凸函数时,我们可以采用一阶的优化算法来进行优化。
目前机器学习中最常用的优化算法是梯度下降法(Gradient Descent Method)。当使用梯度下降法进行参数优化时,还可以利用验证集来早停法(Early-Stop)来中止模型的优化过程,避免模型在训练集上过拟合。早停法也是一种常用的并且十分有效的正则化方法。
2.5.评估标准
评估标注(Metric)用于评价模型效果,即给定一个测试集,用模型对测试集中的每一个样本进行预测,并且根据预测结果计算评价分数。回归任务的评估指标一般有预测值与真实值的均方差,分类任务的评估指标一般有准确率、召回率、F1值等。
对于一个机器学习任务,一般会先确定任务类型,再确定任务的评价指标,再根据评价指标来建立模型,选择学习准则。由于评价指标不可微等问题有时候并不能完全和评价指标一致,我们往往会选择一定的损失函数使得两者尽可能一致。
3.实现简单的线性回归模型
回归任务是一类典型的监督机器学习任务,对自变量和因变量之间关系进行建模分析,其预测值通常为一个连续值,比如房屋价格预测、电影票房预测等。线性回归(Linear Regression)是指一类利用线性函数来对自变量和因变量之间关系进行建模的回归任务,是机器学习和统计学中最基础和最广泛应用的模型。
我们可以动手实现一个简单的线性回归模型,并使得最小二乘法来求解参数,一堆机器学习任务有更直观的认识。
3.1.数据集构建
首先,我们构造一个小的回归数据集,假设输入特征和输出标签的维度都为1,需要被你和的函数定义为:
# 真实函数的参数缺省值为w=1.2, b=0.5
def linear_func(x, w=1.2,b=0.5):
y = w*x + b
return y然后,使用paddle.rand()函数来进行随机采样输入特征x,并带入上面的函数得到输出标签y。为了模拟真实环境样本通常包含噪声的问题,我们采用过程中加入高斯噪音和异常点。
生成样本数据的函数create_toy_data实现如下:
import paddle
def create_toy_data(func, interval, sample_sum, noise = 0.0, add_outlier = False, outlier_ratio = 0.001):
"""
根据给定的函数,生成样本
输入:
-func:函数
-interval:x的取值范围
-sample_num:样本数目
-noise:噪声均方差
-add_outlier:是否生成异常值
-outlier_ratio:异常值占比
输出:
-X:特征数据,shape=[n_samples,1]
-y:标签数据,shape=[n_samples,1]
"""
# 均匀采样
# 使用paddle.rand在省城sample_num个随机数
X = paddle.rand(shape = [sample_num]) * (interval[1]-interval[0]) + interval[0]
y = func(X)
# 生成高斯面分布的标签噪音
# 使用paddle.normal生成0均值,noise标准差的数据
epsilon = paddle.normal(0, noise, paddle.to_tensor(y.shape[0]))
y = y + epsilon
if add_outlier: # 生成额外的异常点
outlier_num = int(len(y)*outlier_ratio)
if outlier_num != 0:
# 使用paddle.randint生成服从均匀分布的、范围在[0, len(y)]的随机Tensor
outlier_idx = paddle.randint(len(y), shape = [outlier_num])
y[outlier_idx] = y[outlier_idx] * 5
return X, y利用上面的生成样本函数,生成150个带噪音的样本,其中100个训练样本,50个测试样本,并打印出训练数据的可视化分布。
from matplotlib import pyplot as plt # matplotlib是Python的绘图哭
func = linear_func
interval = (-10, 10)
train_num = 100 # 训练样本数目
test_num = 50 # 测试样本数目
noise = 2
X_train, y_train = create_toy_data(func=func, interval=interval, sample_num=train_num, noise = noise, add_outlier = False)
X_test, y_test = create_toy_data(func=func, interval=interval, sample_num=test_num, noise = noise, add_outlier = False)
X_train_large, y_train_large = create_toy_data(func=func, interval=interval, sample_num=5000, noise = noise, add_outlier = False)
# paddle.linspace返回一个Tensor,Tensor的值在区间start和stop上均匀间隔的num个值内,输出Tensor的长度为num
X_underlying = paddle.linspace(interval[0], interval[1], train_num)
y_underlying = linear_func(X_underlying)
# 绘制数据
plt.scatter(X_train, y_train, marker='*', facecolor="none", edgecolor="#e4007f", s=50, label="train data")
plt.scatter(X_test, y_test, facecolor="none", edgecolor="#f19ec2", s=50, label="test data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"underlying distribution")
plt.legend(fontsize="x-large") # 给图像加图例
plt.svaefig('ml-vis.pdf') # 保存图像到PDF文件中
plt.show()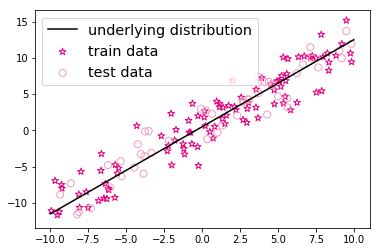
3.2.模型构建
在线性回归中,自变量为样本的特征向量x∈RD(每一维对应一个自变量)因变量是连续值的标签y∈R
线性模型定义为:f(x;w,b) = wT + b
其中权重向量w∈RD和偏置b∈R都是可学习的参数。
注意:《神经网络和深度学习》中为了表示的简洁性,使用增广权重向量来定义模型。而在本书中,为了和代码实现保持一致,我们使用非增广向量的形式来定义模型。
在实践中,为了提高预测样本的效率,我们通常会将N样本归为一组进行成批地预测,这样可以更好地利用GPU设备的并行计算能力。
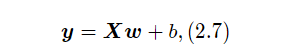
其中X∈RN*D为N个样本的特征矩阵,y∈RN为N个预测值组成的列向量
注意:在实践中,样本的矩阵X室友N个x的行向量组成,而原教材中的x是列向量,其特征矩阵与本书中的特征矩阵刚好互为转置关系。
线性算子
实现线性函数非常简单,我们直接利用如下张量运算来实现。
# X:tensor,shape=[N,D]
# y_pred:tensor, shape=[N]
# w: shape=[D,1]
# b: shape=[1]
y_pred = paddle.matmul(X, w) + b使用飞桨构建一个线性回归模型,代码如下:
说明:在飞桨框架中,可以直接调用模型的forward方法进行前向运算。右移本案例比较简单,所以没有继承nn.Layer,而是保留了在forward()函数中执行模型的前向运算的过程。
import paddle
from nndl.op import Op
paddle.seed(10) # 设置随机种子
# 线性算子
class Linear(Op):
def __init__(self, input_size):
"""
输入:-input_size:模型要处理的数据特征向量长度
"""
self.input_size = input_size
# 模型参数
self.params = {}
self.params['w'] = paddle.randn(shape=[self.input_size,1],dtype='float32')
self.params['b'] = paddle.zeros(shape=[1],dtype='float32')
def __call__(self, X):
return self.forward(X)
# 向前函数
def forward(self, X):
"""
输入:
-X: tensor, shape=[N,D]
注意这里的X矩阵是由N个x向量的转置拼接成的,与原教材行向量表示方式不一致
输出:
-y_pred: tensor, shape=[N]
"""
N, D = X.shape
if self.input_size==0:
return paddle.full(shape=[N, 1], fill_value=self.params['b'])
assert D==self.input_size # 输入数据位数合法性验证
# 使用paddle.matmul计算两个tensor的乘积
y_pred = paddle.matual(X, self.params['w']) + self.params['b']
return y_pred
# 注意这里我们为了和后面章节统一,这里的X矩阵是由N个x向量的转置拼接成的,与原教材行向量表示方式不一样
input_size = 3
N = 2
X = paddle.randn(shape=[N, input_size], dtype='float32') # 生成2个维度为3的数据
model = Linear(input_size)
y_pred = model(X)
print("y_pred:", y_pred) # 输出结果的个数也是2个y_pred: Tensor(shape=[2, 1], dtype=float32, place=CPUPlace, stop_gradient=True,[[0..54838145], [2.03063798]])
3.3.损失函数
回归任务是对连续值的预测,希望模型能根据数据的特征输出一个连续值作为预测值。因此回归任务中常用的评估指标是均方误差。

其中b为N维向量,所有元素取值都为b。
均方误差的代码实现如下:
注意:代码实现中没有除2.
import paddle
def mean_squared_error(y_true, y_pred):
"""
输入:
- y_true: tensor, 样本真实标签
- y_pred: tensor, 样本预测标签
输出:
- error: float, 误差值
"""
assert y_true.shape[0] == y_pred.shape[0]
# paddle.square计算输入的平方值
# paddle.mean沿axis计算x的平均值,默认axis是None,则对输入的全部元素计算平均值
error = paddle.mean(paddle.square(y_true - y_pred))
return error
# 构造一个简单的样例进行测试:[N,1], N = 2
y_true = paddle.to_tensor([[-0.2],[4.9]], dtype='float32')
y_pred = paddle.to_tensor([[1.3],[2.5]], dtype='float32')
error = mean_squared_error(y_true=y_true, y_pred=y_pred).item()
print("error:",error)3.4.模型优化
采用经验风险最小化,线性回归可以通过最小二乘法求出参数w和b的解析解。计算公式中均方误差对参数b的偏导数,得到:
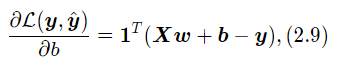
其中1为N维的全1向量。这里为了简单起见省略了均方误差的系数1/N,并不影响最后的结果。
令上式等于0得到
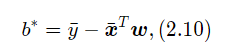
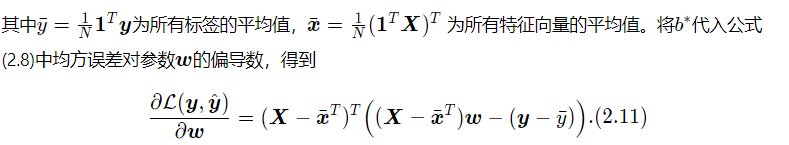
令上式等于0,得到最优的参数为
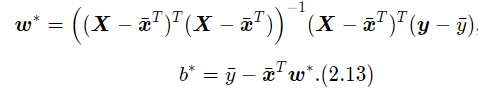
若对参数w加上ℓ2正则化,则最优的w变为
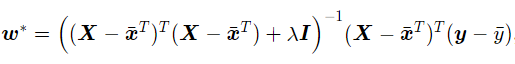
其中λ > 0为预先设置的正则化系数,I∈RD×D为单位矩阵。
参数学习的过程通过优化器完成,由于我们可以基于最小二乘法可以直接得到线性回归的解析解,此处的训练是求解析解的过程。
本案例是基于飞桨2.2.2版本,前一版本是无法直接对paddle。Tensor求转置的。
def optimizer_lsm(model, X, y, reg_lambda=0):
"""
输入:
- model: 模型
- X: tensor,特征数据,shape=[N,D]
- y: tensor,标签数据,shape=[N]
- reg_lambda: float,正则化系数,默认为0
输出:
- model: 优化好的模型
"""
N, D = X.shape
# 对输入特征数据所有特征向量求平均
x_bar_tran = paddle.mean(X, axis=0).T
# 求标签的均值,shape=[1]
y_bar = paddle.mean(y)
# paddle.subtract通过广播的方式实现矩阵减向量
x_sub = paddle.substract(X, x_bar_tran)
# 使用paddle.all判断输入tensor是否全0
if paddle.all(x_sub==0):
model.params['b'] = y_bar
model.params['w'] = paddle.zeros(shape=[D])
return model
# paddle.inverse求方阵的逆
tmp = paddle.inverse(paddle.matmul(x_sub.T, x_sub) + reg_lammbda * paddle.eye(num_row = (D)))
w = paddle.matmul(paddle.matmul(tmp, x_sub.T), (y - y_bar))
b = y_bar-paddle.matmul(x_bar_tran, w)
model.params['b'] = b
model.params['w'] = paddle.squeeze(w, axis=-1)
return model3.5.模型训练
在准备了数据、模型、损失函数和参数学习的实现之后,我们开始模型的训练。在回归任务中,模型的评价指标和损失函数一致,都为均方误差。
通过上文实现的线性规划来拟合训练数据,并输出模型在训练集上的损失。
input_size = 1
model = Linear(input_size)
model = optimizer_lsm(model, X_train.reshape([-1, 1]), y_train.reshape([-1, 1]))
print("w_pred:", model.params['w'].item(), "b_pred:", model.params['b'].item())
y_train_pred = model(X_train.reshape([-1, 1])).squeeze()
train_error = mean_squared_error(y_true=y_train, y_pred=y_train_pred).item()
print("train error:", train_error)
w_pred: 1.1282511949539185 b_pred: 0.5074468851089478
train error: 4.622117519378662
model_large = Linear(input_size)
model_large = optimizer_lsm(model_large, X_train_large.reshape([-1, 1]), y_train_large.reshape([-1, 1]))
print("w_pred large:", model_large.params['w'].item(), "b_pred large:", model_large.params['b'].item())
y_train_pred_large = model_large(X_train_large.reshape([-1, 1])).squeeze()
train_error_large = mean_squared_error(y_true=y_train_large, y_pred=y_train_pred_large).item()
print("train error large:", train_error_large)w_pred large: 1.203893780708313 b_pred large: 0.49070632457733154 train error large: 3.985365629196167
从输出结果看,预测结果与真实值w=1.2,b=0.5有一定的差距。
3.6.模型评估
下面用训练好的模型预测一下测试集的标签,并计算在测试集上的损失。
y_test_pred = model(X_test.reshape([-1, 1])).squeeze()
test_error = mean_squared_error(y_true=y_test, pred_pred=y_test_pred).item()
print("test error:", test_error)test error: 3.5344085693359375
y_test_pred_large = model_large(X_test.reshape([-1, 1])).squeeze()
test_error_large = mean_squared_error(y_true=y_test, y_pred=y_test_pred_large).item()
print("test error large: ",test_error_large)test error large: 3.577786922454834
动手练习:
为了加深对机器学习模型的理解,请自己动手完成一下实验:
-
调整训练数据的样本数量,由100调到5000,观察对模型性能的影响
-
调整正则化系数,观察对模型性能的影响
4.多项式回归
多项式回归是回归任务的一种形式,其中自变量和因变量之间的关系是MMM次多项式的一种线性回归形式,即:
![]()
其中M为多项式的阶数,w = [w1, w2, w3, ..., wM] T为多项式的系数,ϕ(x)=[x, x2, ⋯, xM]T为多项式基函数,将原始特征x映射为M维的向量。当M=0时,f(x;w)=b。
展示的是特征维度为1的多项式表达,当特征维度大于1时,存在不同特征之间交互的情况,这是线性回归无法实现。公式(2.11)展示的是当特征维度为2,多项式阶数为2时的多项式回归:
![]()
当自变量和因变量之间并不是线性关系时,我们可以定义非线性基函数对特征进行变换,从而可以使得线性回归算法实现非线性的曲线拟合。
接下来我们基于特征维度为1的自变量介绍多项式回归实验。
4.1.数据集构建
假设我们要拟合的非线性函数为一个缩放后的sin函数
import math
# sin函数:sin(2 * pi * x)
def sin(x):
y = paddle.sin(2 * math.pi * x)
return y这里仍然使用前面定义的create_toy_data函数来构建训练和测试数据,其中训练数样本 15 个,测试样本 10 个,高斯噪声标准差为 0.1,自变量范围为 (0,1)。
# 生成数据
func = sin
interval = (0, 1)
train_num = 15
test_num = 10
noise = 0.5 # 0.1
X_train, y_train = create_toy_data(func=func, interval=interval, sample_num=train_num, noise = noise)
X_test, y_test = create_toy_data(func=func, interval=interval, smaple_num=test_num, noise = noise)
X_underlying = paddle.linspace(interval[0], interval[1], num=100)
y_underlying = sin(X_underlying)
# 绘制图像
plt.rcParams['figure.figsize'] = (8.0, 6.0)
plt.scatter(X_train, y_train, facecolor="none", edgecolor='#e4007f', s=50, label="train data")
# plt.scatter(X_train, y_test, facecolor="none", edgecolor="r", s=50, label="test data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2*pi x)$")
plt.legend(fontsize='x-large')
plt.savefig('ml-vis2.pdf')
plt.show()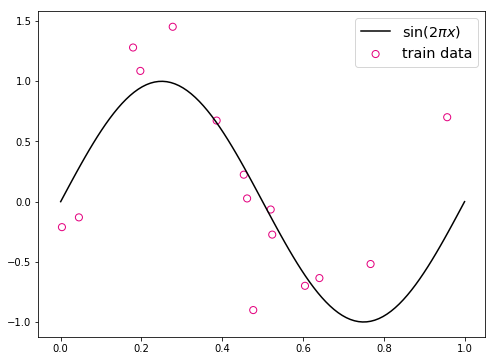
在输出结果中,绿色的曲线是周期为1的sin函数曲线,蓝色的圆圈为生成的训练样本数据,红色的圆圈为生成的测试样本数据。
4.2.模型构建
通过多项式的定义可以看出,多项式回归和线性回归一样,同样学习参数w,只不过需要对输入特征φ(x)根据多项式阶数进行变换。因此,我们可以套用求解线性回归参数的方法来求多项式回归参数。
首先,我们实现多项式基数polynomial_basis_function对原始特征x进行转换。
# 多项式转换
def polynominal_basis_function(x, degree = 2):
"""
输入:
- x: tensor,输入的数据,shape=[N,1]
- degree: int, 多项式的阶数
example Input: [[2], [3], [4]], degree=2
example Output: [[2^1, 2^2], [3^1, 3^2], [4^1, 4^2]]
注意:本案例中,在degree>=1时不产生全为1的一列数据;degree为0时生成相撞与输入相同,全1的Tensor
输出:
- x_result: tensor
"""
if degree == 0:
return paddle.ones(shape = x.shape, dtype='float')
x_tmp = x
x_result = x_tmp
for i in range(2, degree+1):
x_tmp = paddle.multiply(x_tmp, x) # 逐元素相乘
x_result = paddle.concat((x_result, x_tmp), axis=-1)
return x_result
# 简单测试
data =[[2], [3], [4]]
X = paddle.to_tensor(data = data, dtype='float32')
degree = 3
transformed_X = polynomial_basis_function(X, degree=degree)
print("转换前:", X)转换前: Tensor(shape=[3, 1], dtype=float32, place=CPUPlace, stop_gradient=True, [[2.], [3.], [4.]]) 阶数为 3 转换后: Tensor(shape=[3, 3], dtype=float32, place=CPUPlace, stop_gradient=True, [[2. , 4. , 8. ], [3. , 9. , 27.], [4. , 16., 64.]])
4.3.模型训练
对于多项式回归,我们可以同样使用前面线性回归中定义的LinearRegression算子、训练函数train、均方误差函数mean_squared_error.拟合训练数据的目标是最小化损失函数,同线性规划一样,也可以通过矩阵运算直接求出w的值。
我们设定不同的多项式阶,M取值分别为0、1、3、8,之前构造的训练集上进行训练,观察样本数据对sin曲线的拟合结果。
plt.rcParams['figure.figsize'] = (12.0, 8.0)
for i, degree in enumerate([0, 1, 3, 8]): # []中为多项式的阶数
model = Linear(degree)
X_train_transformed = polynomial_basis_function(X_train.reshape([-1, 1]), degree)
X_underlying_transformed = polynomial_basis_function(X_underlying.reshape([-1, 1]), degree)
model = optimizer_lsm(model, X_train_transformed, y_train.reshape([-1, 1])) # 拟合得到参数
y_underlying_pred = model(X_underlying_transformed).squeeze()
print(model.params)
# 绘制图像
plt.subplot(2, 2, i + 1)
plt.scatter(X_train, y_train, facecolor="none", edgecolor='#e4007f', s=50, label="train data")
plt.plot(X_underlying, y_underlying, c='#000000', label="predicted function")
plt.ylim(-2, 1.5)
plt.annotate("M={}".format(degree), xy=(0.95, -1.4))
# plt.legend(loc='local left', fortsize='x-large')
plt.savefig('ml-vis3.pdf')
plt.show(){'w': Tensor(shape=[1], dtype=float32, place=CPUPlace, stop_gradient=True,
[0.]), 'b': Tensor(shape=[1], dtype=float32, place=CPUPlace, stop_gradient=True,
[0.13412179])}
{'w': Tensor(shape=[1], dtype=float32, place=CPUPlace, stop_gradient=True,
[-0.85377944]), 'b': Tensor(shape=[1], dtype=float32, place=CPUPlace, stop_gradient=True,
[0.50373828])}
{'w': Tensor(shape=[3], dtype=float32, place=CPUPlace, stop_gradient=True,
[ 15.10193634, -45.16584396, 32.09858704]), 'b': Tensor(shape=[1], dtype=float32, place=CPUPlace, stop_gradient=True,
[-0.37634081])}
{'w': Tensor(shape=[8], dtype=float32, place=CPUPlace, stop_gradient=True,
[ 7.06669807 , 26.01305199 , -77.03384399 , -284.11853027 ,
558.93908691 , 658.90930176 , -1766.05358887, 881.14282227 ]), 'b': Tensor(shape=[1], dtype=float32, place=CPUPlace, stop_gradient=True,
[-0.36593318])}
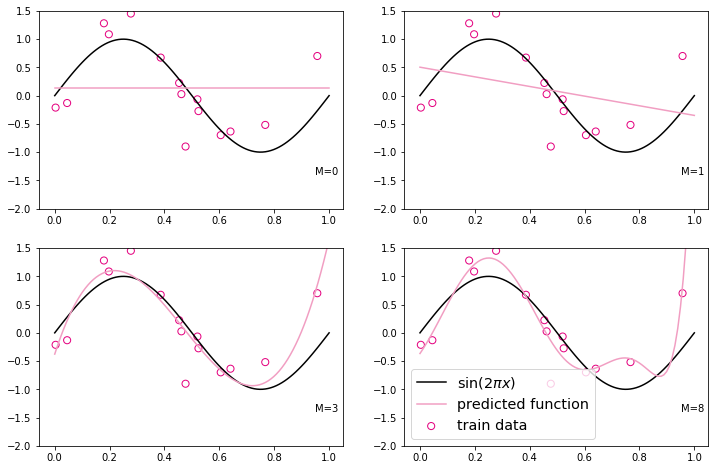
观察可视化结果,红色的曲线表示不同阶多项式分布拟合数据的结果:
-
当 M=0 或 M=1 时,拟合曲线较简单,模型欠拟合;
-
当 M=8 时,拟合曲线较复杂,模型过拟合;
-
当 M=3 时,模型拟合最为合理。
4.4.模型评估
下面通过均方误差来衡量训练误差、测试误差以及在没有噪音的加入下sin函数值与多项式回归式之间的误差,更加真实地反应拟合结果。多项式分布阶数从0到8进行遍历。
degree = 8 # 多项式阶数
reg_lambda = 0.0001 # 正则化
X_train_transformed = polynomial_basis_function(X_train.reshape([-1, 1]), degree)
X_test_transformed = polynomial_basis_function(X_test.reshape([-1,1]), degree)
X_underlying_transformed = polynomial_basis_function(X_underling.reshape([-1, 1]), degree)
model = Linear(degree)
optimizer_lsm(model_reg, X_train_transformed, y_train.reshape([-1, 1]), reg_lambda=reg_lambda)
y_test_pred_reg=model_reg(X_test_transformed).squeeze()
y_underlying_pred_reg=model_reg(X_underlying_transformed).squeeze()
mse = mean_squared_error(y_true = y_test, y_pred = y_test_pred_reg).item()
# 绘制图像
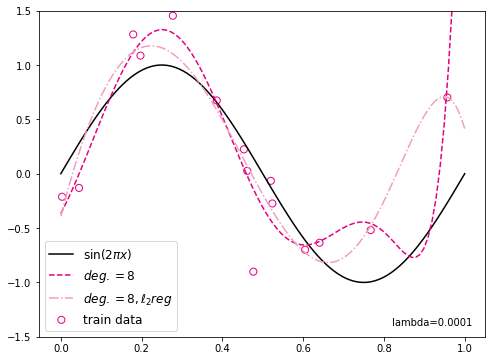
plt.scatter(X_train, y_train, facecolor="none", edgecolor="#e4007f", s=50, label="train data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2\pi x)$")
plt.plot(X_underlying, y_underlying_pred, c='#e4007f', linestyle="--", label="$deg. = 8$")
plt.plot(X_underlying, y_underlying_pred_reg, c='#f19ec2', linestyle="-.", label="$deg. = 8, \ell_2 reg$")
plt.ylim(-1.5, 1.5)
plt.annotate("lambda={}".format(reg_lambda), xy=(0.82, -1.4))
plt.legend(fontsize='large')
plt.savefig('ml-vis4.pdf')
plt.show()<>:31: DeprecationWarning: invalid escape sequence \e <>:31: DeprecationWarning: invalid escape sequence \e <>:31: DeprecationWarning: invalid escape sequence \e /tmp/ipykernel_98/1206503974.py:31: DeprecationWarning: invalid escape sequence \e plt.plot(X_underlying, y_underlying_pred_reg, c='#f19ec2', linestyle="-.", label="$deg. = 8, \ell_2 reg$") mse: 0.2831980586051941 mse_with_l2_reg: 0.26982635259628296
<Figure size 576x432 with 1 Axes>
观察可视化结果,其中黄色曲线为加入l2正则后多项式分布拟合结果,红色曲线为未加入l2正则的拟合结果,黄色曲线的拟合效果明显好于红色曲线。
思考:如果训练数据中存在一些异常样本,会对最终模型有何影响?怎样处理可以尽可能减少异常样本对模型的影响?
异常样本会对模型的训练和预测性能产生多种影响。以下是可能的一些影响:
-
模型偏离:如果异常样本在训练数据中占据较大比例,那么模型可能会被这些异常样本带偏,导致模型的预测结果偏离正常范围。
-
过拟合:如果模型过于复杂,可能会对异常样本产生过拟合,导致模型在新的、未见过的数据上表现不佳。
-
模型泛化能力下降:异常样本通常不能代表我们想要预测的主要分布,因此如果未被正确处理,可能会导致模型对未见过的数据预测能力下降。
为了尽可能减少异常样本对模型的影响,以下是一些常用的处理方法:
-
数据清洗:删除或修正异常样本是处理异常值的最直接方式。例如,如果数据中存在一些极端值或者错误数据,可以通过数据清洗将其删除或者修正。
-
缩放或标准化:如果数据的特征有不同的量级或者分布,可能会导致一些特征对模型的影响过大。这时可以使用缩放(例如z-score标准化)或者标准化(例如最小-最大缩放)来处理。
-
检测并处理异常值:可以使用一些统计方法(如IQR,3σ原则等)或者是机器学习方法(如孤立森林)来检测并处理异常值。
-
使用稳健的模型:一些模型(如决策树、随机森林等)对异常值不太敏感,因此可以减少异常值的影响。
-
使用集成方法:集成方法(如bagging,boosting等)可以通过整合多个模型的预测结果来提高模型的鲁棒性,也可以一定程度上减少异常值的影响。
5.Runner类介绍
通过上面的实践,我们可以看到,在一个任务上应用机器学习方法的流程基本上包括:数据及构建模型构建、损失函数定义、优化器、模型训练、模型评价、模型预测等环节。
为了更方便地将上述环节规范化,我们将机器学习模型的基本要素封装成一个Runner类。除上述提到的要素以外,再加上模型保存、模型加载等功能。
Runner类的成员函数定义如下:
-
__init_函数:实例化Runner类是默认调用,需要传入模型、损失函数、优化器和评价指标等; -
trian函数:完成模型训练,指定模型训练需要的训练集和验证集 -
evaluate函数:通过对训练好的模型进行预测; -
predict函数:选取一条数据对训练好的模型进行预测; -
save_model函数:模型在训练过程和训练结束后需要进行保存; -
load_model函数:调用加载之前保存的模型。
Runner类的框架定义如下:
class Runner(object):
def __init__(self, model, optimizer, loss_fn, metric):
self.model = model # 模型
self.optimizer = optimizer # 优化器
self.loos_fn = loss_fn # 损失函数
self.metric = metric # 评估指标
# 模型训练
def train(self, train_dataset, dev_dataset=None, **kwargs):
pass
# 模型评价
def evaluate(self, data_set, **kwargs):
pass
# 模型预测
def predict(self, x, **kwargs):
pass
# 模型保存
def save_model(self, save_path):
pass
# 模型加载
def load_model(self, model_path):
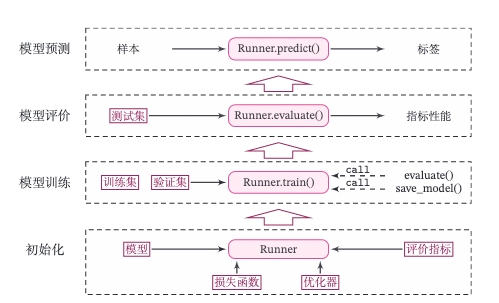
passRunner类的流程如图2.8所示,可以分为 4 个阶段:
-
初始化阶段:传入模型、损失函数、优化器和评价指标。
-
模型训练阶段:基于训练集调用
train()函数训练模型,基于验证集通过evaluate()函数验证模型。通过save_model()函数保存模型。 -
模型评价阶段:基于测试集通过
evaluate()函数得到指标性能。 -
模型预测阶段:给定样本,通过
predict()函数得到该样本标签。
6.基于线性回归的波士顿房价预测
在本节中,我们使用线性回归来对马萨诸塞州波士顿郊区的房屋进行预测。实验流程主要包含如下5个步骤:
-
数据处理:包括数据清洗(缺失值和异常值处理)、数据集划分,以便数据可以被模型正常读取,并具有良好的泛化性;
-
模型构建:定义线性规划回归模型类;
-
训练配置:训练相关的一些配置,如:优化算法、评价指标等;
-
组装训练框架Runner:
Runner用于管理模型训练和测试过程; -
模型训练和测试:利用
Runner进行模型训练和测试。
6.1.数据处理
6.1.1.数据集介绍
本实验使用波士顿房价预测数据集,共506条样本数据,每条样本包含了12种可能影响房价的因素和该类房屋价格的中位数,各字段含义如下:
| 字段名 | 类型 | 含义 |
|---|---|---|
| CRIM | float | 该镇的人均犯罪率 |
| ZN | float | 占地面积超过25,000平方呎的住宅用地比例 |
| INDUS | float | 非零售商业用地比例 |
| CHAS | int | 是否邻近 Charles River 1=邻近;0=不邻近 |
| NOX | float | 一氧化氮浓度 |
| RM | float | 每栋房屋的平均客房数 |
| AGE | float | 1940年之前建成的自用单位比例 |
| DIS | float | 到波士顿5个就业中心的加权距离 |
| RAD | int | 到径向公路的可达性指数 |
| TAX | int | 全值财产税率 |
| PTRATIO | float | 学生与教师的比例 |
| LSTAT | float | 低收入人群占比 |
| MEDV | float | 同类房屋价格的中位数 |
预览前5条数据,代码实现如下:
import pandas as pd # 开源数据分析和操作工具
# 利用pandas加载波士顿房价的数据集
data=pd.read_csv("/home/aistudi/work/boston_prices.csv")
# 预览前5行数据
data.head()
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO \ 0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 4 0.06905 0.0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 LSTAT MEDV 0 4.98 24.0 1 9.14 21.6 2 4.03 34.7 3 2.94 33.4 4 5.33 36.2
6.1.2.数据清洗
对数据集中的缺失值或异常值等情况进行分析和处理,保证数据可以被模型正常读取。
缺失值分析
通过isna()方法判断数据中个元素是否缺失,然后通过sum()方法统计每个字段缺失情况,代码实现如下:
# 查看各字段缺失值统计情况 data.isna().sum() CRIM 0 ZN 0 INDUS 0 CHAS 0 NOX 0 RM 0 AGE 0 DIS 0 RAD 0 TAX 0 PTRATIO 0 LSTAT 0 MEDV 0 dtype: int64
从输出结果看,波士顿房价预测数据集中不存在缺失值的情况。
异常值处理
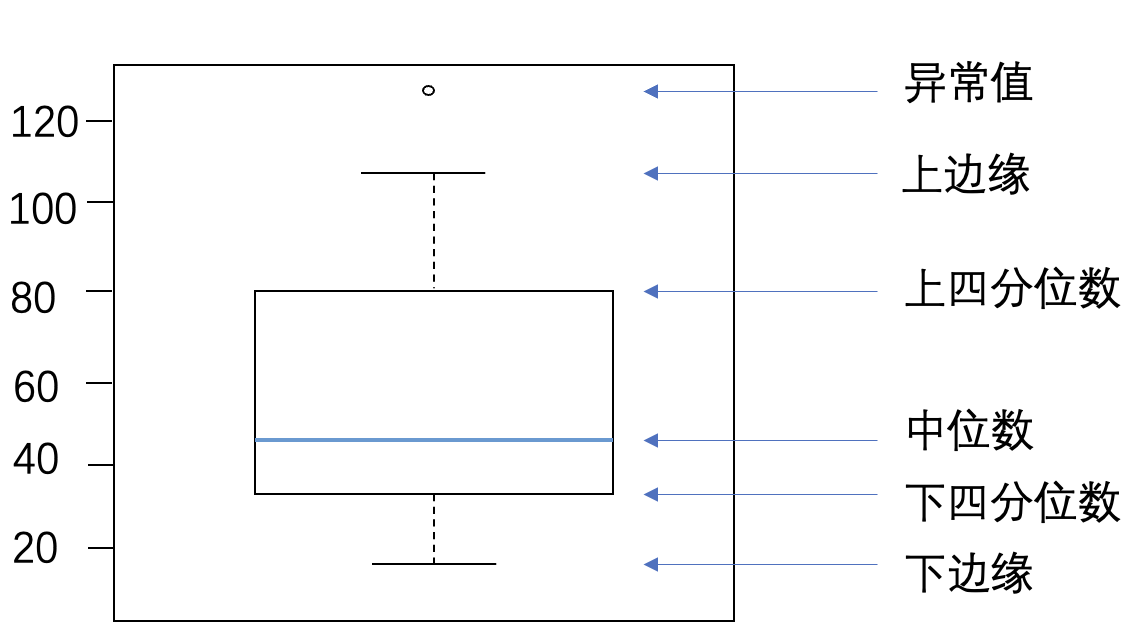
通过箱线图直观的显示数据分布,并观测数据中的异常值。箱线图一般由5个统计值组成:最大值、上四分位、中位数、下四分位和最小值。一般来说,观测到的数据大于最大估计值或者小于最小估计值则判断为异常值,其中
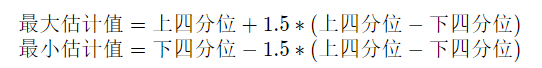
import boxplot(data, fig_name):
# 绘制每个属性的箱线图
data_col = list(data.columns)
# 连续画几个图片
plt.figure(figsize=(5, 5), dpi=300)
# 子图调整
plt.subplots_adjust(wspace=0.6)
# 每个特征画一个箱线图
for i, col_name in enumerate(data_col):
plt.subplot_adjust(wspace=0.6)
# 画箱线图
plt.boxplot(data[col_name],
showmeans=True,
meanprops={"markersize":1, "marker":"D", "markeredgecolor":"#C54680"}, # 均值的属性
medianprops={"color":"#946279"}, # 中位数线的属性
whiskerprops={"color":"#8E004D", "linewidth":0.4, 'linestyle':"--"},
flierprops={"markersize":0.4},
)
# 图名
plt.title(col_name, fontdict={"size":5}, pad=2)
# y方向刻度
plt.yticks(fontsize=4, rotation=90)
plt.tick_params(pad=0.5)
# x方向刻度
plt.xticks([])
plt.savefig(fig_name)
plt.show()
boxplot(data, 'ml-vis5.pdf')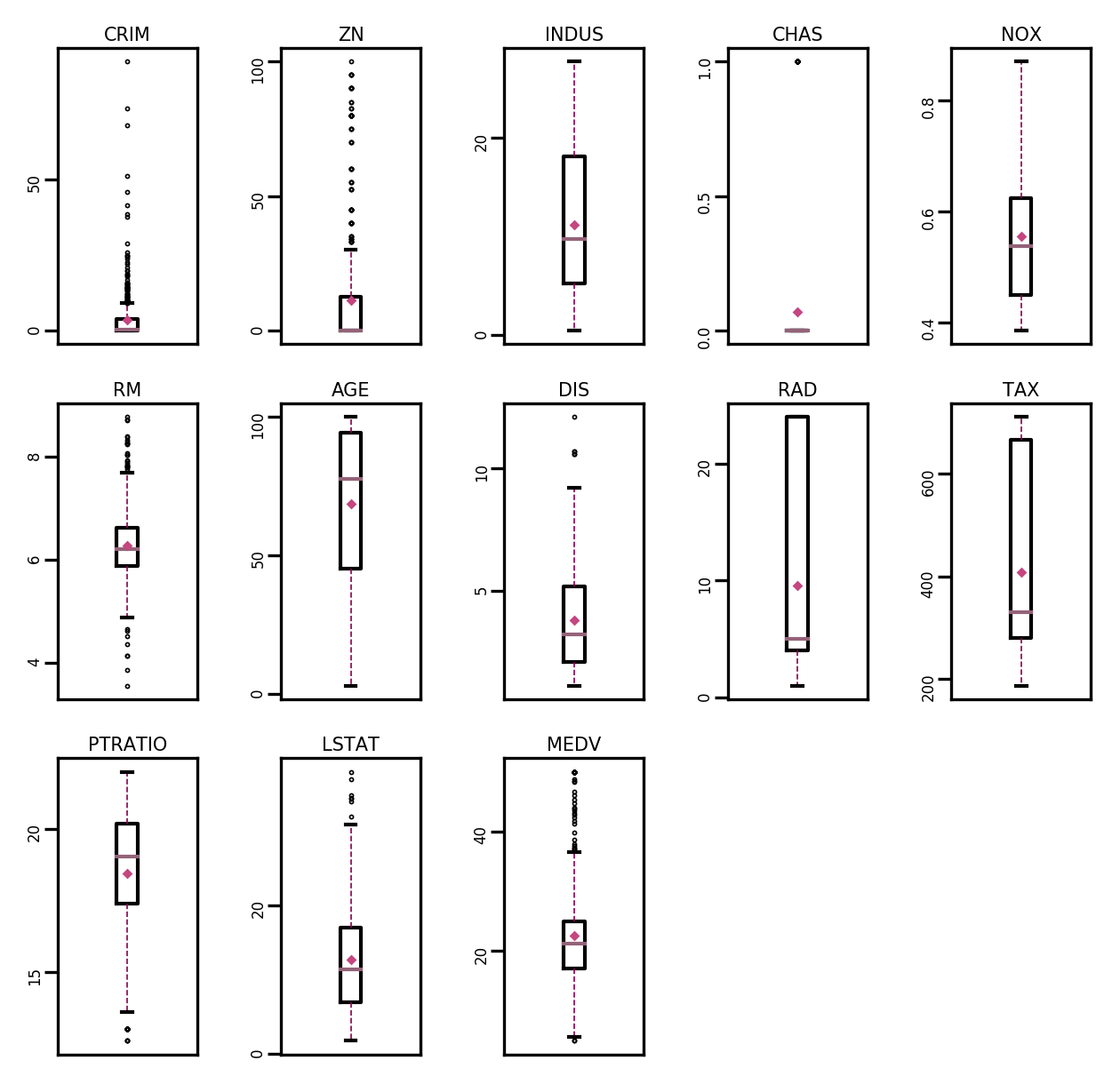
下图是箱线图的一个示例,可对照查看具体含义。
从输出结果来看,数据中存在较多的异常值(图中上下边缘以外的空心小圆圈)
使用四分位值筛选出箱线图中分布的异常值,并将这些数据视为噪声,其将被临界取代,上代码实现如下:
# 四分位处理异常值
num_features=data.select_dtypes(exclude=['object','bool']).columns.tolist()
for feature in num_feature:
if feature == 'CHAS':
continue
Q1 = data[feature].quantile(q=0.25) # 下四分位
Q3 = data[feature].quantile(q=0.75) # 上四分位
IQR = Q3 - Q1
top = Q3+1.5*IQR # 最大估计值
bot = Q1-1.5*IQR # 最小估计值
values=data[feature].values
values[values > top] = top # 临界值取代噪声
values[value < bot] = bot # 临界值取代噪声
data[feature] = values.astyle(data[feature].dtypes)
# 再次查看箱线图,异常值已被临界值替换(数据量较多或本身异常值较少时,箱线图展示会不容易体现出来)
boxplot(data, 'ml-vis6.pdf')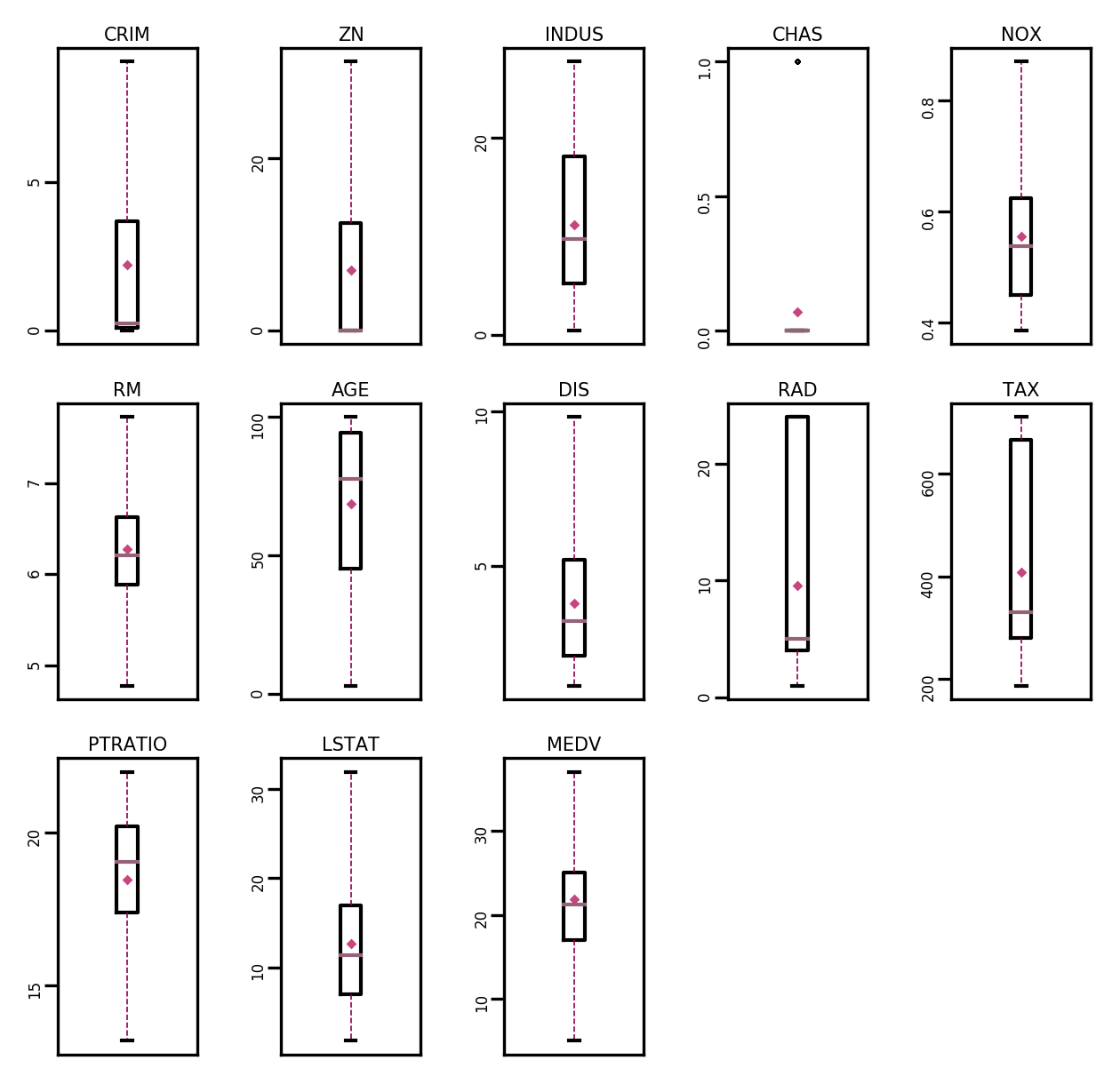
从输出结果来看,经过异常值处理后,箱线图中异常值得到了改善。
6.1.3.数据集划分
由于本实验比较简单,将数据集划分为两份:训练集和测试集,不包括验证集。
具体代码如下:
import paddle
paddle.seed(10)
# 划分为训练集和测试集
def train_test_split(X, y, train_percent=0.8):
n = len(X)
shuffled_indices = paddle.randperm(n) # 返回一个数值在0到n-1,随机排列的1-D Tensor
train_set_size = int(n*train_percent)
train_indices = shuffled_indices[:train_set_size]
test_indices = shuffled_indices[train_set_size:]
X = X.values
y = y.values
X_train=X[train_indices]
y_train = y[train_indices]
X_test = X[test_indices]
y_test = y[test_indices]
return X_train, X_test, y_train, y_test
X = data.drop(['MEDV'], axis=1)
y = data['MEDV']
X_train, X_test, y_train, y_test = train_test_split(X,y) # X_train每一行是一个样本,shape[N,D]6.1.4.特征工程
为了消除钢梁对数据特征之间的影响,在模型训练前,需要对特征数据进行归一化处理,将数据缩放到[0,1]区间内,使得不同特征之间具有可比性。
代码实现如下:
import paddle
X_trian = paddle.to_tensor(X_train,dtype='float32')
X_test = paddle.to_tensor(X_test,dtype='float32')
y_train = paddle.to_tensor(y_train, dtype='float32')
y_test = paddle.to_tensor(y_test, dtype='float32')
X_min = paddle.min(X_train, axis=0)
X_max = paddle.max(X_train, axis=0)
X_train = (X_train - X_min) / (X_max - X_min)
X_test = (X_test - X_min) / (X_max - X_min)
# 训练集构造
trian_dataset=(X_train, y_train)
# 测试集构造
test_dataset=(X_test, y_test)6.2.模型构建
实例化一个线性回归模型,特征维度为12:
from nnld.op import Linear
# 模型实例化
input_size = 12
model=Linear(input_size)6.3.完善Runner类
模型定义好后,围绕模型需要配置损失函数、优化器、评估、测试等信息,以及模型相关的一些其他信息(如模型存储路径等)。
在本章中使用的Runner类为V1版本。其中训练过程通过直接求解解析解的方式得到模型参数,没有模型优化及计算损失函数过程,模型训练结束后保存模型参数。
训练配置中定义:
-
训练环境,如GPU还是CPU,本案例不涉及;
-
优化器,本案例不涉及;
-
损失函数,本案例通过平方损失函数得到模型参数的解析解;
-
评估指标,本案例利用MSE评估模型效果。
在测试集上使用MSE对模型性能进行评估。本案例利用飞桨框架提供的MSELoss API实现。
import paddle.nn as nn mse_loss = nn.MSELoss()
具体实现如下:
import paddle
import os
from nndl.opitimizer import optimizer_lsm
class Runner(object):
def __init__(self, model, optimizer, loss_fn, metric):
# 优化器和损失函数为None,不再关注
# 模型
self.model=model
# 评估指标
self.metric = metric
# 优化器
self.optimizer = optimizer
def train(self,dataset,reg_lambda,model_dir):
X,y = dataset
self.optimizer(self.model,X,y,reg_lambda)
# 保存模型
self.save_model(model_dir)
def evaluate(self, dataset, **kwargs):
X,y = dataset
y_pred = self.model(X)
result = self.metric(y_pred, y)
return result
def predict(self, X, **kwargs):
return self.model(X)
def save_model(self, model_dir):
if not os.path.exists(model_dir):
os.makedirs(model_dir)
params_saved_path = os.path.join(model_dir,'params.pdtensor')
paddle.save(model.params,params_saved_path)
def load_model(self, model_dir):
params_saved_path = os.path.join(model_dir,'params.pdtensor')
self.model.params=paddle.load(params_saved_path)
optimizer = optimizer_lsm
# 实例化Runner
runner = Runner(model, optimizer=optimizer,loss_fn=None, metric=mse_loss)6.4 模型训练
在组装完成Runner之后,我们将开始进行模型训练、评估和测试。首先,我们先实例化Runner,然后开始进行装配训练环境,接下来就可以开始训练了,相关代码如下:
# 模型保存文件夹
saved_dir = '/home/aistudio/work/models'
# 启动训练
runner.train(train_dataset,reg_lambda=0,model_dir=saved_dir)打印出训练得到的权重:
columns_list = data.columns.to_list()
weights = runner.model.params['w'].tolist()
b = runner.model.params['b'].item()
for i in range(len(weights)):
print(columns_list[i],"weight:",weights[i])
print("b:",b)CRIM weight: -6.7268967628479 ZN weight: 1.28081214427948 INDUS weight: -0.4696650803089142 CHAS weight: 2.235346794128418 NOX weight: -7.0105814933776855 RM weight: 9.76220417022705 AGE weight: -0.8556219339370728 DIS weight: -9.265738487243652 RAD weight: 7.973038673400879 TAX weight: -4.365403175354004 PTRATIO weight: -7.105883598327637 LSTAT weight: -13.165120124816895 b: 32.12007522583008
从输出结果看,CRIM、PTRATIO等的权重为负数,表示该镇的人均犯罪率与房价负相关,学生与教师比例越大,房价越低。RAD和CHAS等为正,表示到径向公路的可达性指数越高,房价越高;临近Charles River房价高。
6.5 模型测试
加载训练好的模型参数,在测试集上得到模型的MSE指标。
# 加载模型权重
runner.load_model(saved_dir)
mse = runner.evaluate(test_dataset)
print('MSE:', mse.item())MSE: 12.345974922180176
6.6 模型预测
使用Runner中load_model函数加载保存好的模型,使用predict进行模型预测,代码实现如下:
runner.load_model(saved_dir)
pred = runner.predict(X_test[:1])
print("真实房价:",y_test[:1].item())
print("预测的房价:",pred.item())真实房价: 33.099998474121094 预测的房价: 33.04654312133789