目录
前言
3D语义场景补全
视频修复
3D人脸重建
视频线条检测
3D物体重建
尾言

前言
作者介绍:作者本人是一名人工智能炼丹师,目前在实验室主要研究的方向为生成式模型,对其它方向也略有了解,希望能够在CSDN这个平台上与同样爱好人工智能的小伙伴交流分享,一起进步。谢谢大家鸭~~~

如果你觉得这篇文章对您有帮助,麻烦点赞、收藏或者评论一下,这是对作者工作的肯定和鼓励。
3D语义场景补全
Semantic Scene Completion via Integrating Instances and Scene in-the-Loop
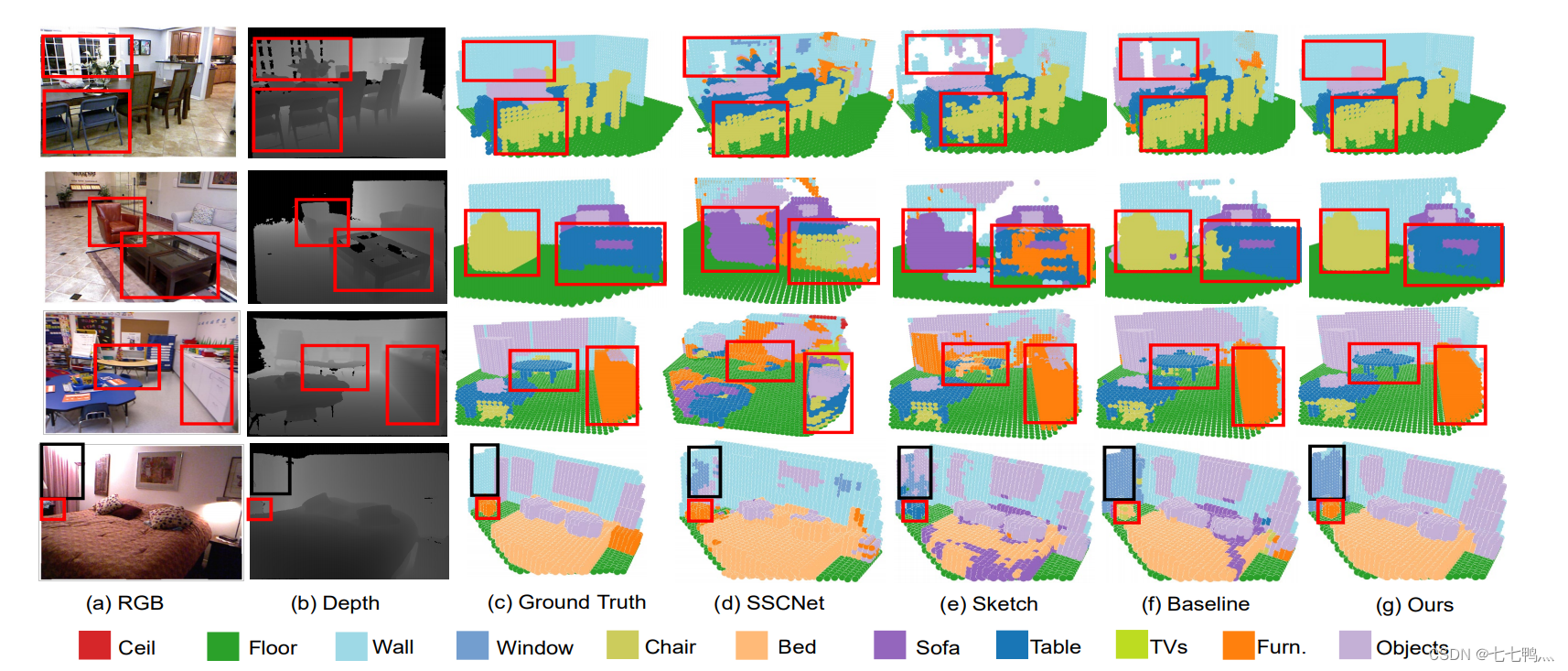
摘要:语义场景补全旨在从单视角深度或RGBD图像中重建具有精确体素级语义的完整3D场景。这是室内场景理解中至关重要但具有挑战性的问题。在这项工作中,我们提出了一种名为“场景-实例场景网络(SISNet)”的新框架,它充分利用了实例和场景级语义信息的优势。我们的方法能够推断出精细的形状细节,以及语义类别容易混淆的附近对象。关键是我们将实例从粗略完成的语义场景中分离出来,而不是从原始输入图像中分离,以指导实例和整体场景的重建。SISNet进行了迭代的场景到实例(SI)和实例到场景(IS)语义补全。具体而言,SI能够编码对象周围的上下文,以有效地将实例从场景中分离出来,每个实例都可以被像素化为更高分辨率以捕获更细的细节。通过IS,精细的实例信息可以集成回3D场景中,从而实现更准确的语义场景补全。利用这种迭代机制,场景和实例的补全相互受益,以实现更高的补全精度。大量实验证明,我们提出的方法在真实的NYU、NYUCAD和合成的SUNCG-RGBD数据集上始终优于最先进的方法。
Code:https://github.com/yjcaimeow/SISNet
论文:https://arxiv.org/abs/2104.03640
视频修复
Progressive Temporal Feature Alignment Network for Video Inpainting

摘要:视频修复旨在用合理的内容填充时空上的“损坏”区域。为了实现这一目标,需要找到从相邻帧中的对应关系,以忠实地虚构未知内容。目前的方法通过注意力、基于光流的扭曲或3D时间卷积来实现这一目标。然而,基于光流的扭曲在光流不准确时可能会产生伪影,而时间卷积可能会受到空间不对齐的影响。我们提出了“渐进式时间特征对齐网络”,它通过使用光流逐渐丰富从当前帧提取的特征,并将其与从相邻帧扭曲的特征结合起来。我们的方法在时间特征传播阶段纠正了空间不对齐,极大地提高了修复视频的视觉质量和时间一致性。使用我们提出的架构,与现有的深度学习方法相比,我们在DAVIS和FVI数据集上实现了最先进的性能。
Code:https://github.com/MaureenZOU/TSAM
论文:https://arxiv.org/abs/2104.03507
3D人脸重建
Riggable 3D Face Reconstruction via In-Network Optimization
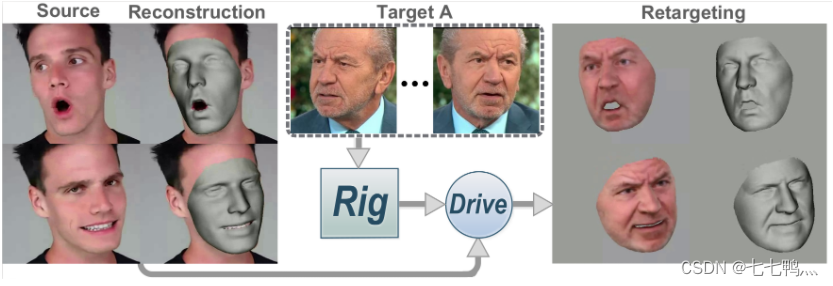
摘要:本文提出了一种从单目图像进行可控三维人脸重建的方法,该方法共同估计了个性化的人脸模型和包括表情、姿势和光照在内的每张图像的参数。为了实现这一目标,我们设计了一个端到端可训练的网络,嵌入了一个可微分的网络内优化过程。网络首先使用神经解码器将人脸模型参数化为一个紧凑的潜在代码,然后通过可学习的优化过程来估计潜在代码以及每张图像的参数。通过估计个性化的人脸模型,我们的方法超越了静态重建,实现了诸如视频重定向等下游应用。网络内优化明确强制执行了从第一原理中导出的约束,因此引入了比基于回归方法更多的先验信息。最后,利用深度学习的数据驱动先验来限制不适定的单目设置,减轻了优化难度。实验证明,我们的方法在重建精度、稳健性和泛化能力方面都达到了最先进水平,并支持标准的人脸模型应用。
Code:https://github.com/zqbai-jeremy/INORig
论文:https://arxiv.org/abs/2104.03493
视频线条检测
SOLD2 : Self-supervised Occlusion-aware Line Description and Detection

摘要:与特征点的检测和描述相比,检测和匹配线段提出了额外的挑战。然而,线特征对于多视图任务来说是特征点的有力补充。线段在图像梯度的作用下具有明确定义,在纹理较差的区域甚至经常出现,并提供了强大的结构线索。因此,我们在此介绍了首个在单一深度网络中联合检测和描述线段的方法。由于采用了自监督训练,我们的方法不需要任何注释的线标签,因此可以推广到任何数据集。我们的检测器能够在图像中重复且准确地定位线段,不同于线框解析方法。利用描述符学习的最新进展,我们提出的线段描述符具有高度区分性,同时对视角变化和遮挡具有鲁棒性。我们在多视图数据集上评估了我们的方法,这些数据集是通过同态变换创建的,还包括了真实世界的视角变化。我们的完整流程提供了更高的重复性、定位精度和匹配度量,因此代表了与学习的特征点方法缩小差距的第一步。
Code:https://github.com/cvg/SOLD2
论文:https://arxiv.org/abs/2104.03362
3D物体重建
3D Shape Generation and Completion through Point-Voxel Diffusion
摘要:我们提出了一种用于概率生成三维形状的新方法。与大多数现有的模型不同,这些模型学习将潜在向量确定性地转换为形状,我们的模型,Point-Voxel Diffusion(PVD),是一个统一的、概率的公式,用于无条件形状生成和有条件的多模态形状完成。PVD将去噪扩散模型与三维形状的混合点-体素表示相结合。它可以看作是一系列去噪步骤,将观察到的点云数据的扩散过程逆转为高斯噪声,并通过优化条件似然函数的变分下界进行训练。实验证明,PVD能够合成高保真度的形状,完成部分点云数据,并从实际物体的单视图深度扫描中生成多个完成结果。
Code: GitHub - alexzhou907/PVD
论文: https://arxiv.org/abs/2104.03670
尾言
如果您觉得这篇文章对您有帮忙,请点赞、收藏。您的点赞是对作者工作的肯定和鼓励,这对作者来说真的非常重要。如果您对文章内容有任何疑惑和建议,欢迎在评论区里面进行评论,我将第一时间进行回复。