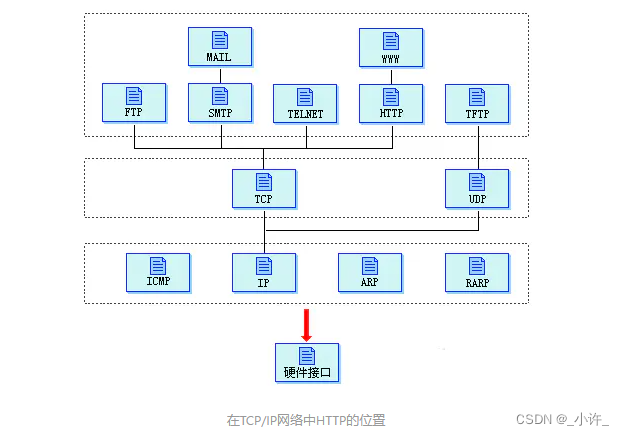
文章目录
- 前言
- 一、8.1,8.2 正交化
- 二、8.3,8.4评估指标
- 1、 单一量化评估指标
- 2、满足和优化指标
- 三、8.5-8.7训练开发测试数据集
- 1、训练开发测试数据集的分布。
- 2、训练开发测试数据集的大小选择
- 3、何时更改指标或者开发测试数据集
- 四、 8.8-8.12 与人类水平相比较
- 1、为什么选择与人类水平相比较
- 2、避免偏见
- 3、human-level performance
- 4、超越人类水平
- 5、
前言
一、8.1,8.2 正交化
我理解的ML中 的正交化就是任务分开做,比如之前的early stopping就不是正交化,它一方面考虑如何在训练数据集上取得较好的结果,另一方米娜又担心过拟合,考虑在开发数据集上的效果。
把任务分开,有助于我们更好的解决问题,但并不是不能使用early stopping这种方法,有时候,他也能取得很好的效果。

对于不同的问题,我们有不同的解决方法。
比如如果在训练数据集上不能取得很好的效果,我们可以构建更大的网络或者采用Adam优化算法。
如果在开发数据集上不能取得很好的效果,我们可以获得更多数据集或者采用正则化等。
二、8.3,8.4评估指标
对于构建神经网络,我们最好先设定一个评估指标,这有利于加快我们的步伐,评估指标有利于我们知道哪个算法更优。
1、 单一量化评估指标
对于一个问题,我们可以采用单一的评估指标,来确定哪个算法更优。
比如判断一个猫的系统

精准率和识别率我们之前讲过,不在叙述。
简单的说精准率就是我们识别出的猫有多少是准确的。
召回率是我们系统中真正的猫我们识别出来多少。
而对于不同的问题,我们的评价指标不同,我们可以用F1 score将这两者结合起来,是一个调和平均值,不是平均数。
2、满足和优化指标
有时候对于一个评价指标我们或许很难只选取一个单一的指标来评估。
可能有多个评价指标,这时候我们可以选择一个最重要的作为优化指标,而把其他的作为满足指标。
比如运行时间是满足指标,我们规定运行时间不得大于100ms,那么不满足这个指标的模型我们可以直接舍弃。在符合满足指标的基础上去优化我们的优化指标,比如准确度。
三、8.5-8.7训练开发测试数据集
1、训练开发测试数据集的分布。
选择正确的开发数据集和评价指标相当于设定了一个目标,我们去全身心最优化这个目标。
但是如果我们开发数据集选择不当的话,会导致我们的心思全部白费了。
比如我们选取中产阶级的贷款作为开发数据集,在我们确定之后,我们可以根据它来开发我们的模型,之后我们却要把这个模型应用在收入较低的人群中去测试,那效果肯定是不好的。
所以我们选取训练开发测试数据集时要选择相同的分布,才不会导致我们的工作白费。
2、训练开发测试数据集的大小选择
数据较少时,我们可以采用传统意义上的7/3或者6/2/2
但是随着大数据时代的到来,我们获取的数据量越来越多,有时候我们的开发数据集和测试数据集的大小会远远小于之前的百分之三十和百分之二十。
比如有100万个训练集,我们有时候或许只要1万个开发测试数据就可以。
对于开发数据,只要能评判哪个算法或者参数好就可以。
对于测试数据,只要能评判我们这个模型哪个更好就可以。
3、何时更改指标或者开发测试数据集
比如一个系统,我们的指标表明A算法更好,
但是A算法对于用户而言却有很多不好的体验,用户就会更偏向于B算法。
此时说明我们的评价指标有问题,我们应该更改我们的评价指标。
又或者另一个系统,比如识别猫🐱,我们的开发测试数据集收集的都是清晰的照片,模型在开发测试数据集上的效果很好,但是在实际运行中产生的效果并不好,这是因为我们在实际运行中,用户手机中的猫的照片相对而言会很模糊,识别率不高。导致分布不同。此时我们就需要调整我们的指标以及开发测试数据集。
四、 8.8-8.12 与人类水平相比较
1、为什么选择与人类水平相比较

当一个算法没有超过人类性能时,我们可以借助很多工具,这时候算法的性能会提升很快,但是一旦超过了人类的表现,算法的提升就很慢了,因为人类在某些问题上已经接近贝叶斯最低误差了。一个算法最终一定会有一些误差不会百分之百正确,所以即使一个算法再好,最后也不会超过贝叶斯最低误差。
①首先是,人类在某些问题上的水平是相当不错的,比如识别图片,识别音频等。
②若是一个算法没有超过人类指标,那我们可以依照人类来优化我们的算法,比如一个识别猫的系统,我们可以借助人类的识别系统,来像我们的算法做正确的标记,以此来减小算法的偏差与方差。

2、避免偏见

在前面我们提到过贝叶斯误差,我们知道,再识别物体的例子中,人类的识别误差是很小的,但是人类的识别误差也一定会大于贝叶斯误差,但在这里,由于差距不大,我们可以把人类误差当作贝叶斯误差,第一列中比如人类的识别误差是百分之一,而模型的训练误差达到了百分之八,开发误差达到了百分之十。
第二列,假设人类误差是百分之七点五,模型误差不变。
根据人类识别误差的不同作为根据,我们这两个模型集中的侧重点也不同。
第一个可避免偏差为百分之7,而方差为百分之二,所以我们着重消除偏差。
第二个可避免偏差为百分之0.5,而方差为百分之二,所以我们着重消除方差。
3、human-level performance
也可以说是人类水平误差,贝叶斯误差是最小的误差,对于很多人类表现较好的领域,是可以用人类误差来代替贝叶斯误差的,也称为贝叶斯误差估计。
对于人类水平误差的正确理解有助于我们更好的去训练一个模型。

这是不同的人对一个医学照片分析误差的表现。那我们到底该选取哪个作为贝叶斯误差估计呢?
贝叶斯误差是最小的误差,我们应该选取0.5%这个作为贝叶斯误差的估计。
但在实际应用中我们也可以选用不同的值来进行比较。比如我们训练出来的模型误差为0.8%,它已经超过了一个专业医生的水平,那它在现实生活中也是很有价值的。

从上图中我们可以发现,当模型距离人类水平误差还很大的时候我们是很好区分要着重消除方差还是偏差。
但是当模型的优化已经很好时,这时候对于贝叶斯误差的估计就很重要了,当然这也只是在你的模型已经训练的很好的情况下才很重要,这时候对贝叶斯误差的估计往往决定着我们能否训练出一个更好的模型。比如最后一列,如果我们仅仅知道人类水平误差为百分之0.7,那么这时候我们训练误差也是0.7%,而开发误差是0.8%,我们就不会想到去继续优化我们的模型,而是去着重消除方差,但如果我们知道对于一个专业团队,它的误差是0.5%,那么这时候我们就会去进一步优化我们的模型,得到一个更好的模型。
4、超越人类水平
对于模型在没有超越人类水平之前,是很容易根据一些工具来提高性能的,并且也有自己明确的目标,但是在超越人类水平之后,就很难取得进展了,或者说是进展很慢。因为我们的方向和目标不明确了,我们这时候不知道可避免的误差是多少,不知道到底该着手于哪里去优化。
但是这并不是说我们没有优化的空间了,在一些领域,深度学习已经超越了人类的水平误差。比如自然感知领域(人类很擅长这方面)推荐广告,计算a-b花费时间等等,但是在其它一些领域比如图像识别等,深度学习也有优于人类的。
5、
可避免偏差与我们之前说的偏差不同,之前都是用百分之0当作基准误差,但并不是所有的都能达到百分之百正确,之前的哪个偏差我们应该叫做估计偏差。但是这个可避免偏差在实际中是很重要的,我们可以根据它来确定我们的模型还能提高优化多少。