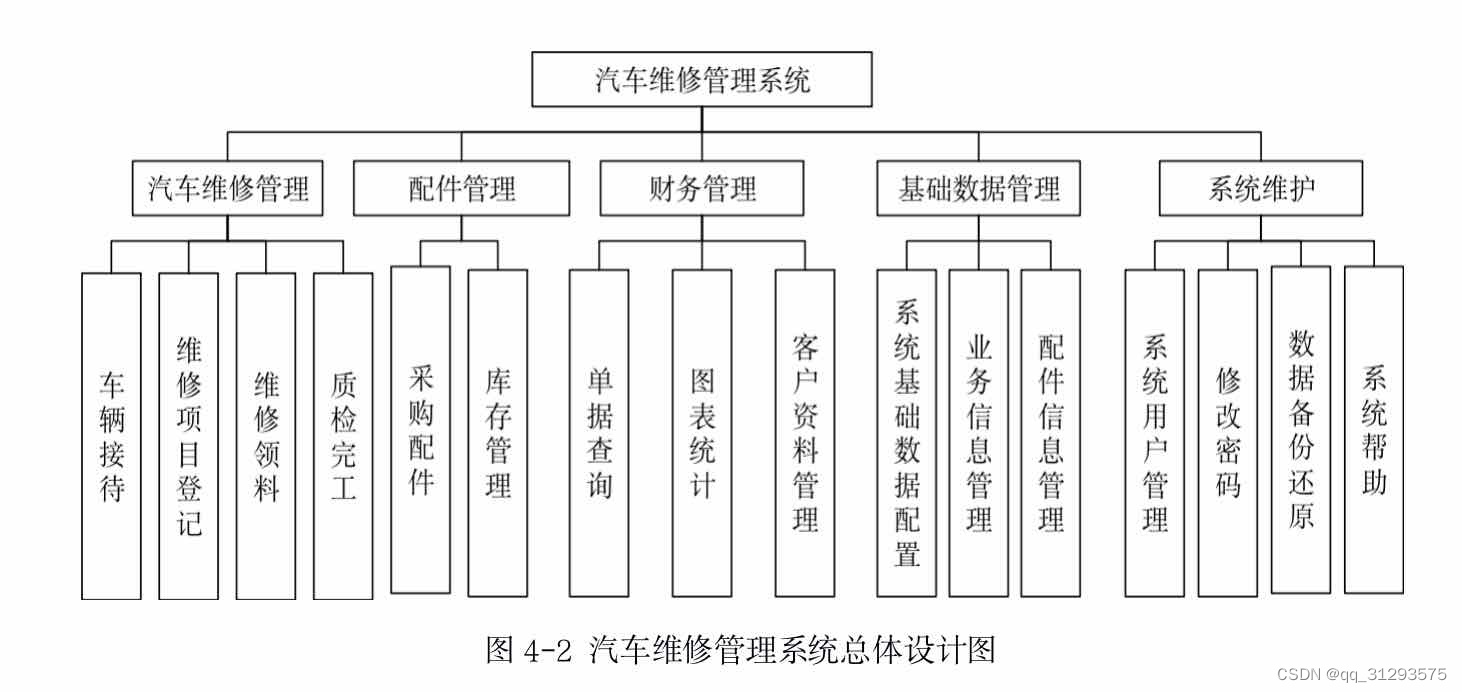
1 找到conf/schema.xml并备份
2 字符串ID处理的分区算法
conf/rule.xml
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
3 字符串的id怎么玩?
只有是字符串,就使用JCH
将给key 分配给n 个buckets。
jump Consistent hash:零内存消耗,均匀,快速,简洁,来自Google的一致性哈希算法

Hash 算法:
将一个值映射一个区间的某个值上面!
将很多的字符串我可以平均的分配到 4 个buckets 里面就ok
Rehash 的过程,所有在选择容器存储时,我们需要预估该容器里面最大的容量值,并且使用负载因子来确定 容器的size。这样的话,我们可以减少rehash的过程
总结:
以后只要使用到字符串的id 类型,就使用jch的算法就ok 了
4 测试
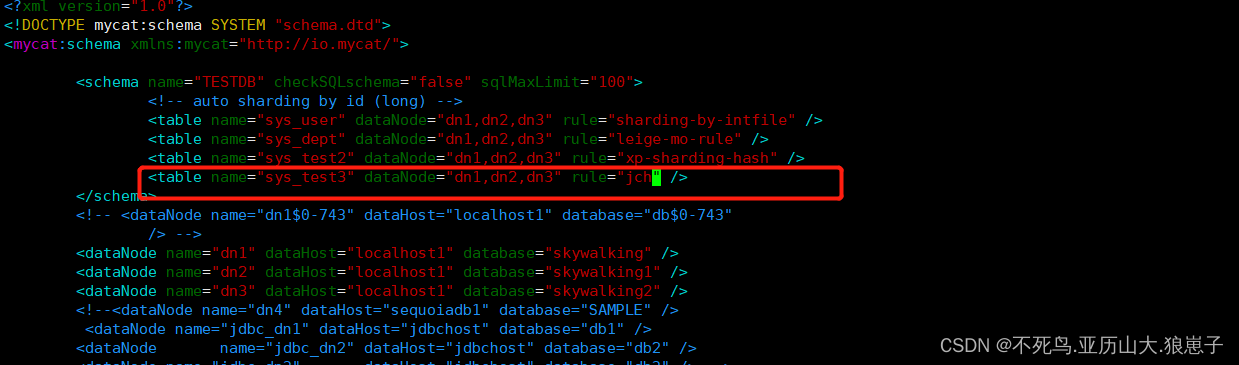
注意表的ID必须为字符串
#sys_test3
CREATE TABLE sys_test3(
id VARCHAR(30) PRIMARY KEY ,
testname VARCHAR(20) NOT NULL
);执行过程如下:
EXPLAIN INSERT INTO sys_test3(id,testname) VALUES('aaaaaaaaaaa','1111');
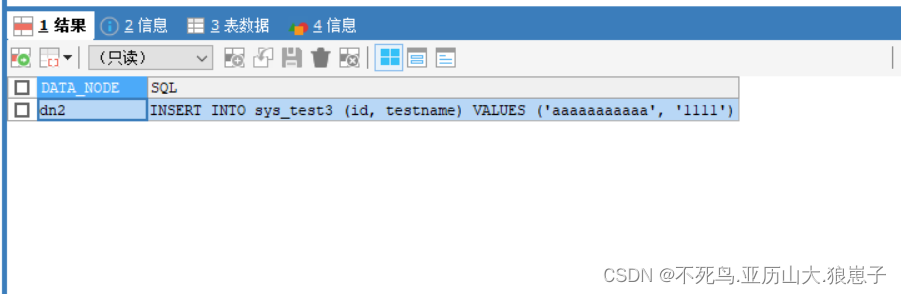
EXPLAIN INSERT INTO sys_test3(id,testname) VALUES('aa','1111');