回答:
我们为什么要学习源码?
1、知其然知其所以然
2、站在巨人的肩膀上,提高自己的编码水平
3、应付面试
1.1 Spring源码阅读小技巧
1、类层次藏得太深,不要一个类一个类的去看,遇到方法该进就大胆的进
2、更不要一行一行的去看,看核心点,有些方法并不重要,不要跟它纠缠
3、看不懂的先不看,根据语义和返回值能知道这个方法达到了啥目的即可
4、只看核心接口(下面标注了重点的地方)和核心代码,有些地方也许你使用spring以来都没触发过
5、debug跟步走,源码中给大家标注好了,见到 ”===>“ 就进去
进去之前,下一行打个断点,方便快速回到岔路口
进去之前,可以先点方法看源码,再debug跟进
6、广度优先,而非深度优先。先沿着主流程走,了解大概,再细化某些方法
7、认命。spring里多少万行的代码,一部书都写不完。只能学关键点
阅读源码目的
加深理解spring的bean加载过程
面试吹牛x
江湖传说,spring的类关系是这样的……
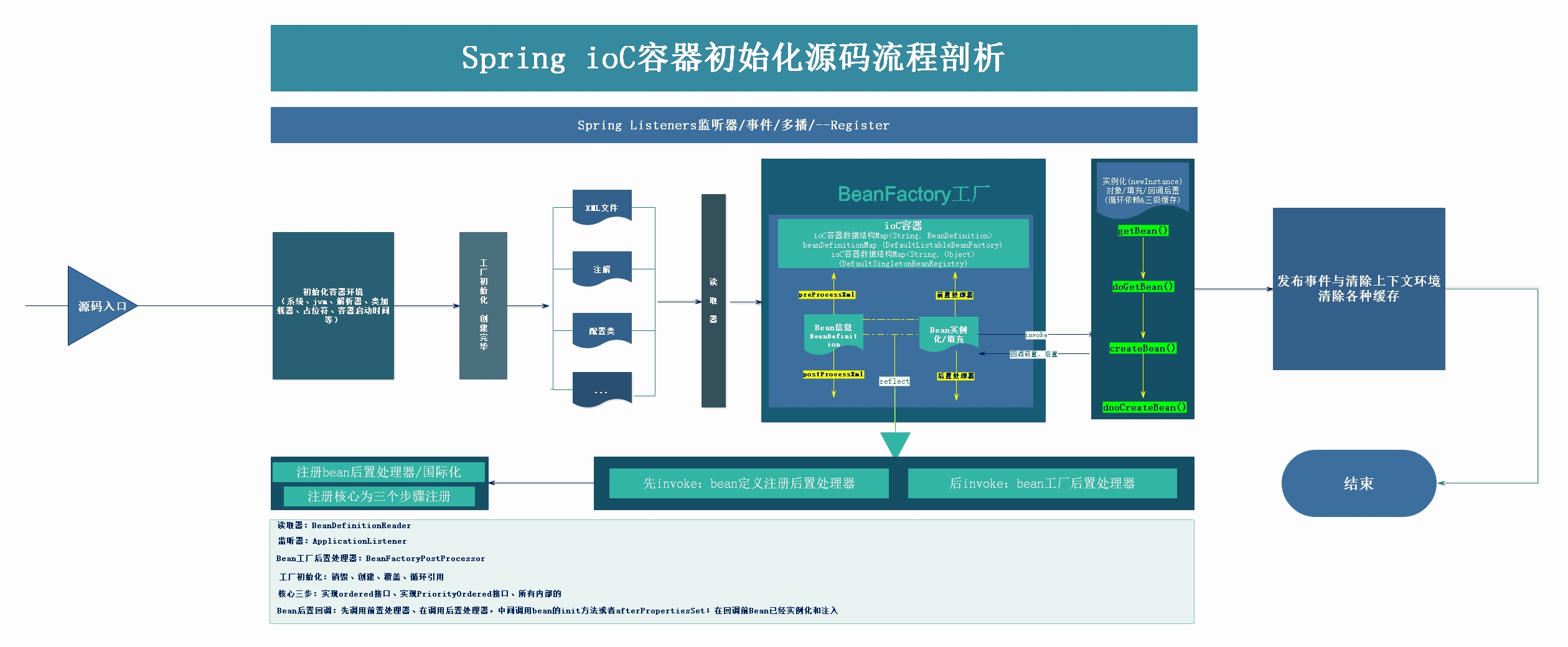
1.2 IoC初始化流程与继承关系
引言
在看源码之前需要掌握Spring的继承关系和初始化
1) IoC容器初始化流程
目标:
1、IoC容器初始化过程中到底都做了哪些事情(宏观目标)
2、IoC容器初始化是如何实例化Bean的(划重点,最终目标)
//没有Spring之前我们是这样的
User user=new User();
user.xxx();
//有了Spring之后我们是这样的
<bean id="userService" class="com.spring.test.impl.UserServiceImpl">
User user= context.getBean("xxx");
user.xxx();
IoC流程简化图:
tips:
下面的流转记不住没有关系
在剖析源码的整个过程中,我们一直会拿着这个图和源码对照
初始化:
1、容器环境的初始化
2、Bean工厂的初始化(IoC容器启动首先会销毁旧工厂、旧Bean、创建新的工厂)
读取与定义
读取:通过BeanDefinitonReader读取我们项目中的配置(application.xml)
定义:通过解析xml文件内容,将里面的Bean解析成BeanDefinition(未实例化、未初始化)
实例化与销毁
Bean实例化、初始化(注入)
销毁缓存等
扩展点
事件与多播、后置处理器
复杂的流程关键点:
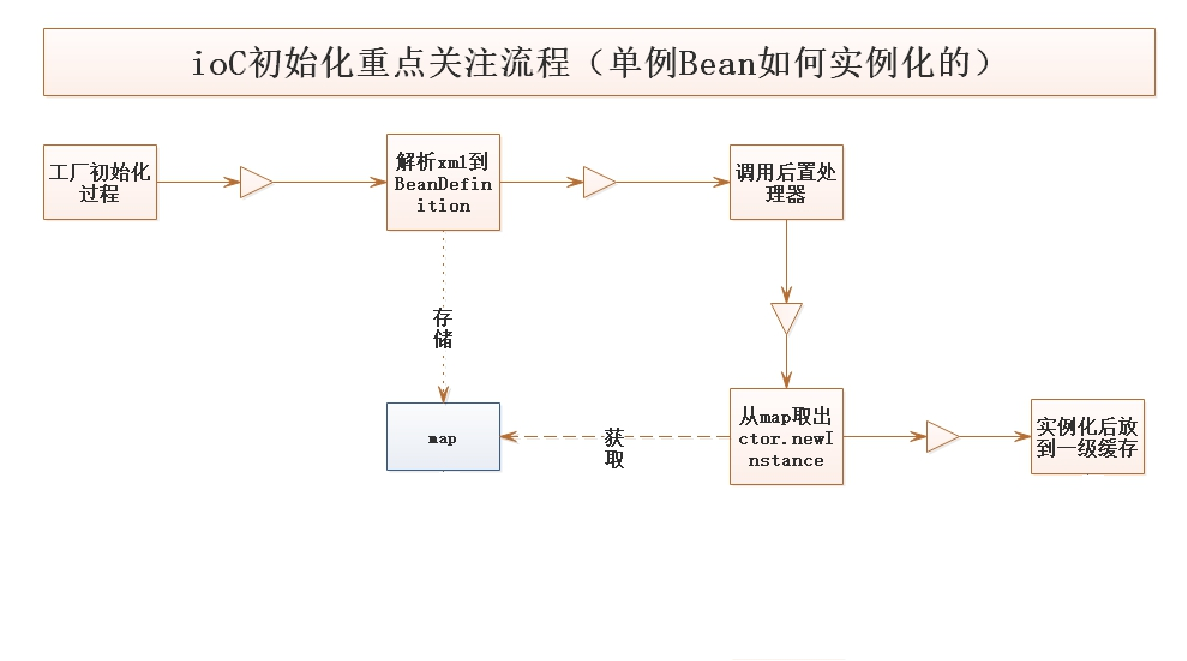
重点总结:
1、工厂初始化过程
2、解析xml到BeanDefinition,放到map
3、调用后置处理器
4、从map取出进行实例化( ctor.newInstance)
5、实例化后放到一级缓存(工厂)
2) 容器与工厂继承关系
tips:
别紧张,下面的继承记不住没有关系
关注颜色标注的几个就可以
**目标:**简单理解ioC容器继承关系

继承关系理解:
1、ClassPathXmlApplicationContext最终还是到了 ApplicationContext 接口,同样的,我们也可以使用绿颜色的 FileSystemXmlApplicationContext 和 AnnotationConfigApplicationContext 这两个类完成容器初始化的工作
2、FileSystemXmlApplicationContext 的构造函数需要一个 xml 配置文件在系统中的路径,其他和 ClassPathXmlApplicationContext 基本上一样
3、AnnotationConfigApplicationContext 的构造函数扫描classpath中相关注解的类,主流程一样
课程中我们以最经典的 classpathXml 为例。
Bean工厂继承关系
目标:
ApplicationContext 和 BeanFactory 啥关系?
BeanFactory 和 FactoryBean呢?
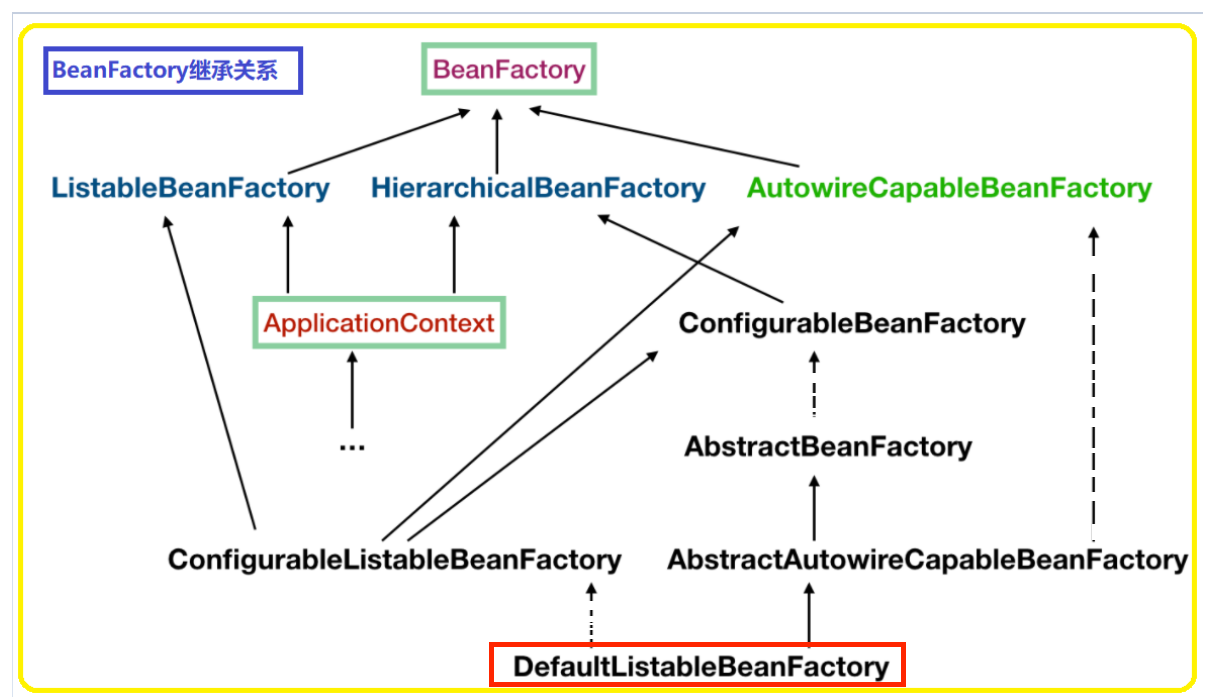
总结:
别害怕,上面的继承关系不用刻意去记住它
其实接触到的就最下面这个!
1.3 开始搭建测试项目
四步:
1、新建测试module项目
首先我们在 Spring 源码项目中新增一个测试项目,点击 New -> Module… 创建一个 Gradle 的 Java 项目
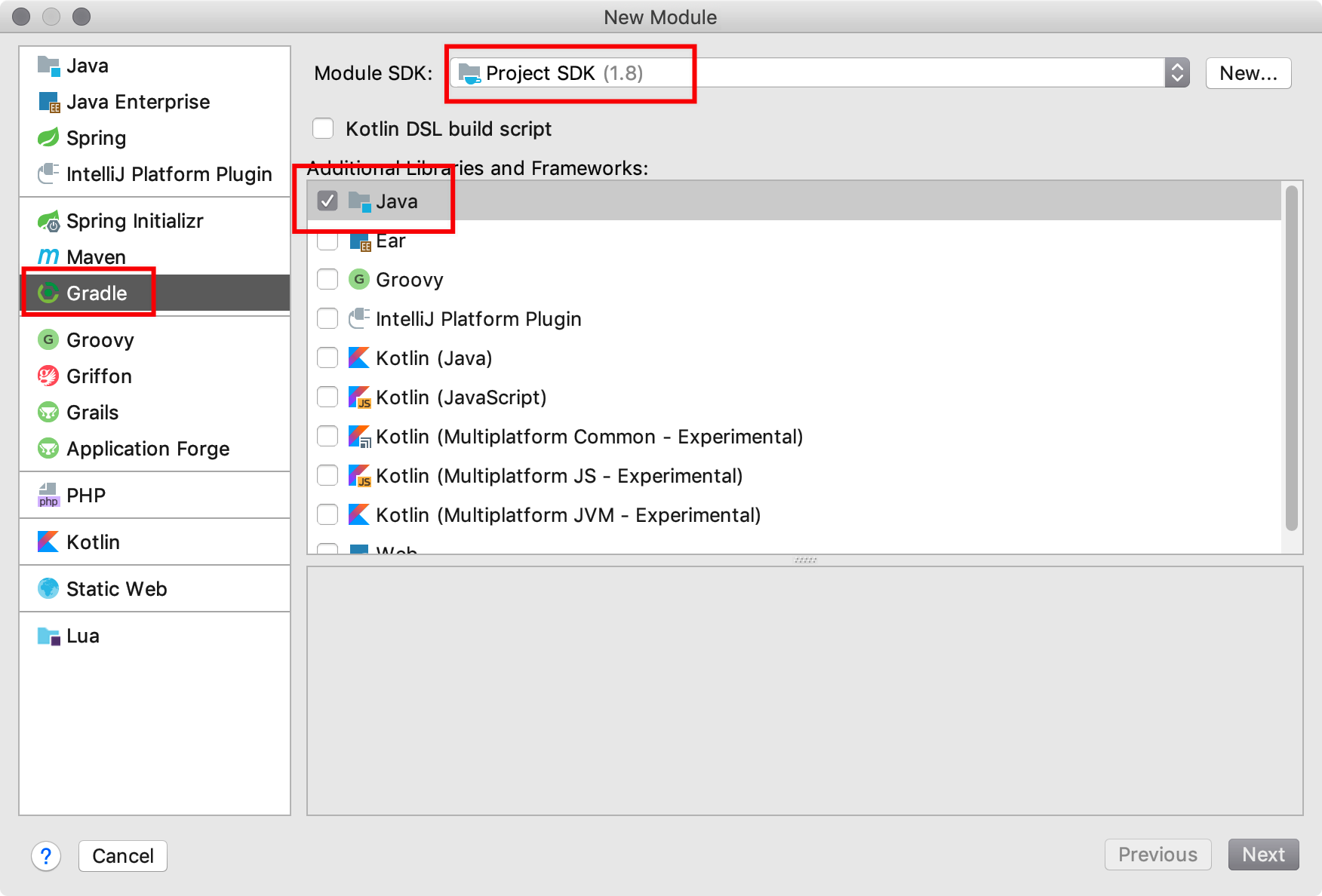
2、详细信息
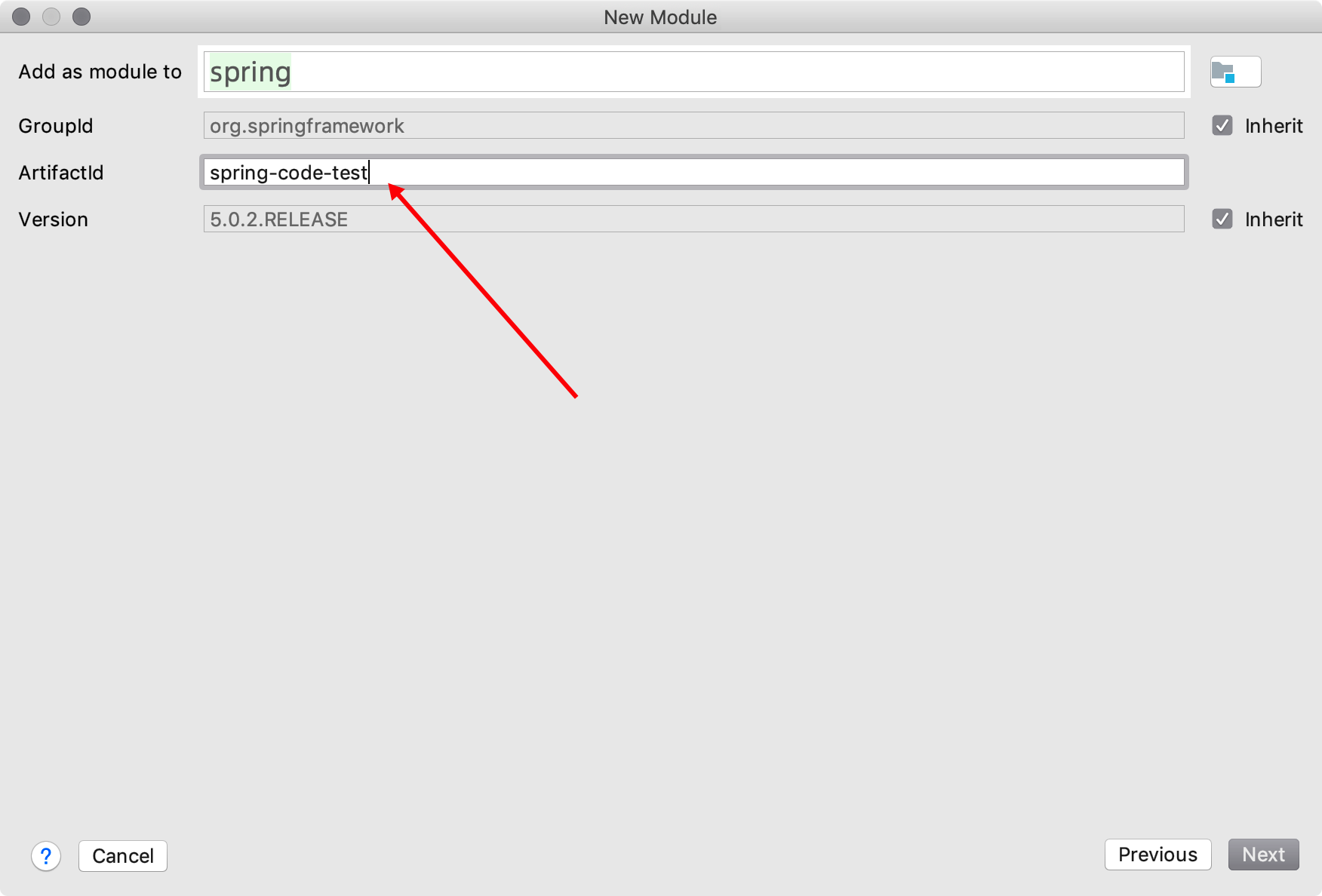
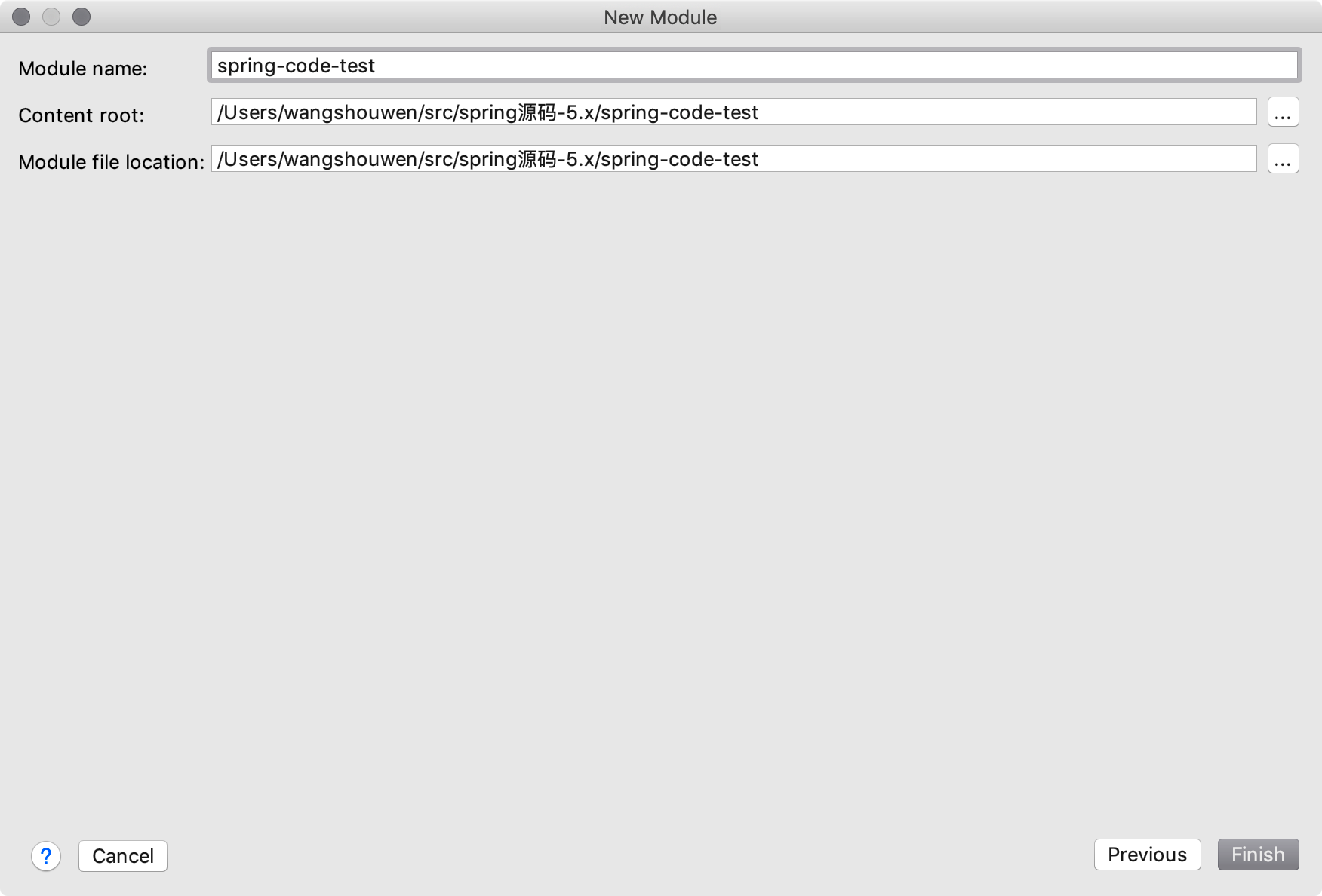
3、设置gradle
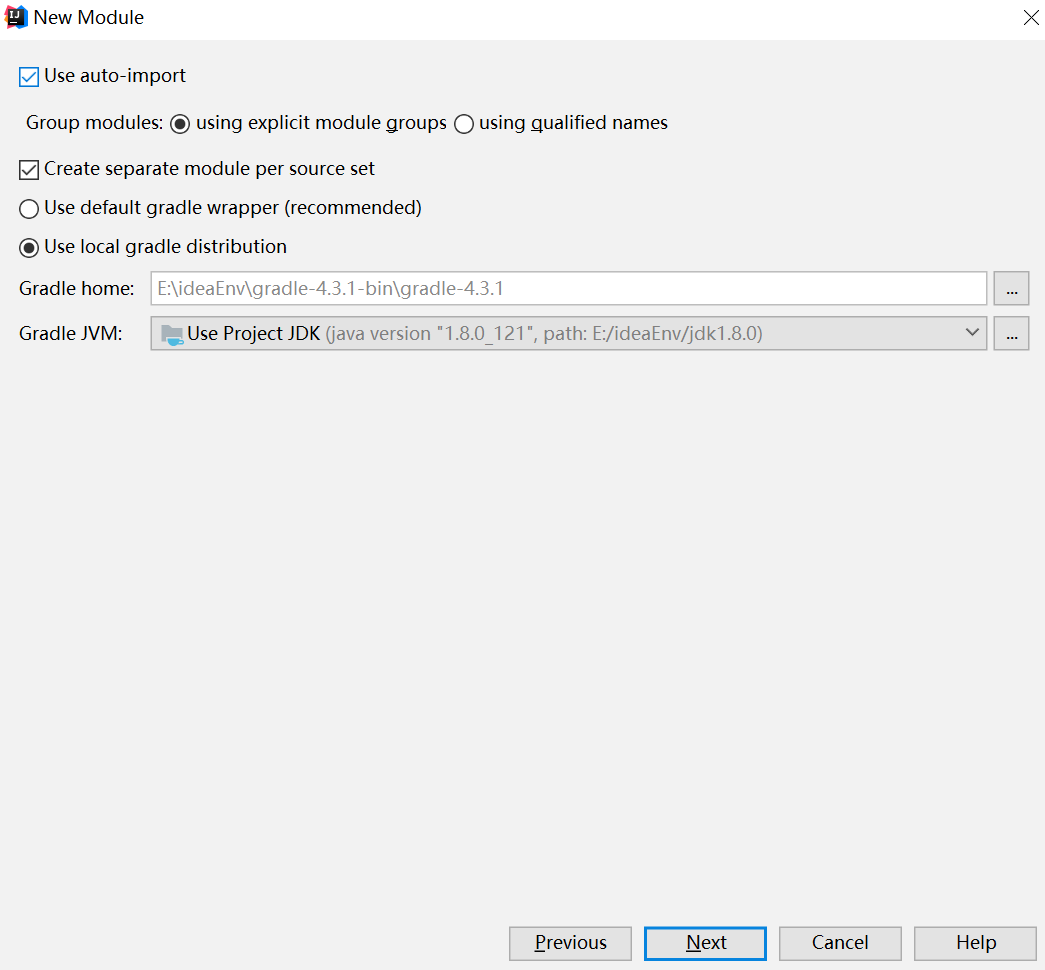
4、完善信息
在 build.gradle 中添加对 Spring 源码的依赖:
compile(project(':spring-context'))

spring-context 会自动将 spring-core、spring-beans、spring-aop、spring-expression 这几个基础 jar 包带进来。
接着,我们需要在项目中创建一个 bean 和配置文件(application.xml)及启动文件(Main.java)
接口如下:
package com.spring.test.service;
public interface UserService {
public String getName();
}
实现类
package com.spring.test.impl;
import com.spring.test.service.UserService;
public class UserServiceImpl implements UserService {
@Override
public String getName() {
return "Hello World";
}
}
Main代码如下
public class Test {
public static void main(String[] args) {
ApplicationContext context =
new ClassPathXmlApplicationContext("classpath*:application.xml");
UserService userService = context.getBean(UserService.class);
System.out.println(userService);
// 这句将输出: hello world
System.out.println(userService.getName());
}
}
配置文件 application.xml(在 resources 中)配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="userService" class="com.spring.test.impl.UserServiceImpl"/>
</beans>
运行
输出如下
com.spring.test.impl.UserServiceImpl@2aa5fe93
Hello World
1.4 工厂的构建
引言:
接下来,我们就正式讲解Spring ioC容器的源码
我们的目的:看一下ioC如何帮我们生成对象的
生命周期
1)ApplicationContext入口
参考 IocTest.java
测试代码:spring支持多种bean定义方式,为方便大家理解结构,以xml为案例,后面的解析流程一致
ApplicationContext context = new ClassPathXmlApplicationContext("classpath*:${xmlName}.xml");
// (c)从容器中取出Bean的实例,call:AbstractApplicationContext.getBean(java.lang.Class<T>)
//工厂模式(simple)
UserService userService = (UserService) context.getBean("userServiceBeanId");
// 这句将输出: hello world
System.out.println(userService.getName());
进入到ClassPathXmlApplicationContext的有参构造器
org.springframework.context.support.ClassPathXmlApplicationContext#ClassPathXmlApplicationContext(java.lang.String[], boolean, org.springframework.context.ApplicationContext)
public ClassPathXmlApplicationContext(
String[] configLocations, boolean refresh, @Nullable ApplicationContext parent)
throws BeansException {
//继承结构图
//1、返回一个classloader
//2、返回一个解析器
super(parent);
// 1、获取环境(系统环境、jvm环境)
// 2、设置Placeholder占位符解析器
// 2、将xml的路径解析完存储到数组
setConfigLocations(configLocations);
//默认为true
if (refresh) {
//核心方法(模板)
refresh();
}
}
重点步骤解析(断点跟踪讲解)
super方法做了哪些事情
1、super方法:通过点查看父容器与子容器概念
2、super方法:调用到顶端,一共5层,每一层都要与讲义中的【ioC与Bean工厂类关系继承】进行对照
3、super方法:在什么地方初始化的类加载器和解析器
setConfigLocations方法做了哪些事情:
1、如何返回的系统环境和jvm环境
2、路径的解析
3、设置占位符解析器
进入核心方法refresh
2)预刷新
prepareRefresh()【准备刷新】
// synchronized块锁(monitorenter --monitorexit),不然 refresh() 还没结束,又来个启动或销毁容器的操作
synchronized (this.startupShutdownMonitor) {
//1、【准备刷新】【Did four things】
prepareRefresh();
......。略
讲解重点(断点跟踪、类继承关系、架构图讲解)
prepareRefresh干了哪些事情
//1、记录启动时间/设置开始标志
//2、子类属性扩展(模板方法)
//3、校验xml配置文件
//4、初始化早期发布的应用程序事件对象(不重要,仅仅是创建setg对象)
3)创建bean工厂【重点】
【获得新的bean工厂】obtainFreshBeanFactory()
最终目的就是解析xml,注册bean定义
关键步骤
//1、关闭旧的 BeanFactory
//2、创建新的 BeanFactory(DefaluListbaleBeanFactory)
//3、解析xml/加载 Bean 定义、注册 Bean定义到beanFactory(未初始化)
//4、返回全新的工厂
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
4)bean工厂前置操作
【准备bean工厂】prepareBeanFactory(beanFactory);
//1、设置 BeanFactory 的类加载器
//2、设置 BeanFactory 的表达式解析器
//3、设置 BeanFactory 的属性编辑器
//4、智能注册
tips
当前代码逻辑简单、且非核心
5)bean工厂后置操作
【后置处理器Bean工厂】postProcessBeanFactory(beanFactory) 空方法
tips:子类实现
空方法,跳过
6)工厂后置处理器【重点】
【调用bean工厂后置处理器】invokeBeanFactoryPostProcessors(beanFactory);
//调用顺序一:bean定义注册后置处理器
//调用顺序二:bean工厂后置处理器
PostProcessorRegistrationDelegate 类里有详细注解
tips
invoke方法近200行
关注两类后置处理器的方法执行步骤和顺序
7)bean后置处理器
【注册bean后置处理器】registerBeanPostProcessors(beanFactory)
//6、【注册bean后置处理器】只是注册,但是不会反射调用
//功能:找出所有实现BeanPostProcessor接口的类,分类、排序、注册
registerBeanPostProcessors(beanFactory);
// 核心:查看重要的3步;最终目的都是实现bean后置处理器的注册
// 第一步: implement PriorityOrdered
// 第二步: implement Ordered.
// 第三步: Register all internal BeanPostProcessors.
8)国际化
【初始化消息源】国际化问题i18n initMessageSource();
tips:
就加了个bean进去,非核心步骤,跳过
9)初始化事件广播器
【初始化应用程序事件多路广播】initApplicationEventMulticaster();
tips:
需要讲解观察者设计模式
重点:就放了个bean进去, 到下面的 listener再联调。
10)刷新
【刷新】 onRefresh();
空的,交给子类实现:默认情况下不执行任何操作
// 具体的子类可以在这里初始化一些特殊的 Bean(在初始化 singleton beans 之前)
onRefresh();
不重要,跳过
11)注册监听器【重点】
**【注册所有监听器】**registerListeners();
测试代码参考:MulticastTest
//获取所有实现了ApplicationListener,然后进行注册
//1、集合applicationListeners查找
//2、bean工厂找到实现ApplicationListener接口的bean
//3、this.earlyApplicationEvents;
tips:
需要讲解观察者设计模式
重点:演示多播和容器发布
12)完成bean工厂【重点】
【完成bean工厂初始化操作】finishBeanFactoryInitialization(beanFactory);
//【完成bean工厂初始化操作】负责初始化所有的 singleton beans
//此处开始调用Bean的前置处理器和后置处理器
finishBeanFactoryInitialization(beanFactory);
讲解重点(断点跟踪、类继承关系、架构图讲解)
//1、设置辅助器:例如:解析器、转换器、类装载器
//2、实例化
//3、填充
//4、调用前置、后置处理器
//核心代码在 getBean() , 下面单独讲解
13)完成刷新
【完成刷新】
protected void finishRefresh() {
// 1、清除上下文级资源缓存
clearResourceCaches();
// 2、LifecycleProcessor接口初始化
// ps:当ApplicationContext启动或停止时,它会通过LifecycleProcessor来与所有声明的bean的周期做状态更新
// 而在LifecycleProcessor的使用前首先需要初始化
initLifecycleProcessor();
// 3、启动所有实现了LifecycleProcessor接口的bean
//DefaultLifecycleProcessor,默认实现
getLifecycleProcessor().onRefresh();
// 4、发布上下文刷新完毕事件到相应的监听器
//ps:当完成容器初始化的时候,
// 要通过Spring中的事件发布机制来发出ContextRefreshedEvent事件,以保证对应的监听器可以做进一步的逻辑处理
publishEvent(new ContextRefreshedEvent(this));
// 5、把当前容器注册到到MBeanServer,用于jmx使用
LiveBeansView.registerApplicationContext(this);
}
tips:
非核心步骤
2 singleton bean 创建【重点】
下面拎出来,重点讲 getBean方法。
参考代码:
先看没有循环依赖的情况,普通单例bean的初始化 SinigleTest.java
后面再讲循环依赖
1)调用入口
大家都知道是getBean()方法,但是这个方法要注意,有很多调用时机
如果你把断点打在了这里,再点进去getBean,你将会直接从singleton集合中拿到一个实例化好的bean
无法看到它的实例化过程。
可以debug试一下。会发现直接从getSingleTon返回了bean,这不是我们想要的模样……

思考一下,为什么呢?
回顾 1.4中的第 12 小节,在bean工厂完成后,会对singleton的bean完成初始化,那么真正的初始化应该发生在那里!
那就需要找到:DefaultListableBeanFactory的第 809 行,那里的getBean
也可以从 1.4的第12小节的入口跟进去。断点打在这里试试:
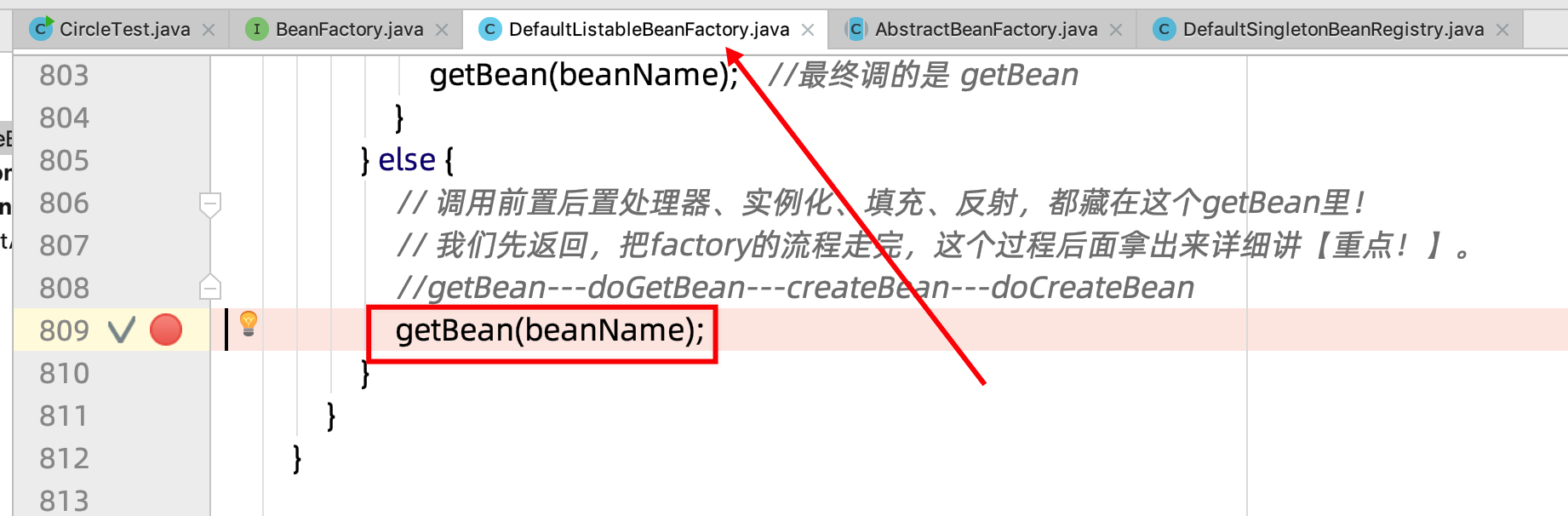
这也是我们在上面留下的尾巴。
本小节我们从这里继续……
2)主流程
小tip:先搞清除3级缓存的事
关于bean的三级缓存:DefaultSingletonBeanRegistry代码
/**
* 一级缓存:单例(对象)池,这里面的对象都是确保初始化完成,可以被正常使用的
* 它可能来自3级,或者2级
*/
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/**
* 三级缓存:单例工厂池,这里面不是bean本身,是它的一个工厂,未来调getObject来获取真正的bean
* 一旦获取,就从这里删掉,进入2级(发生闭环的话)或1级(没有闭环)
*/
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/**
* 二级缓存:早期(对象)单例池,这里面都是半成品,只是有人用它提前从3级get出来,把引用暴露出去
* 它里面的属性可能是null,所以叫早期对象,early!半成品
* 未来在getBean付完属性后,会调addSingleton清掉2级,正式进入1级
*/
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
传统叫三级缓存里拿bean,其实就是仨map
严格意义上,只有single一级缓存,其他俩根本算不上是缓存
他们只是在生成bean的过程中,暂存过bean的半成品。
就那么称呼,不必较真
主流程图很重要!后面的debug会带着这张图走
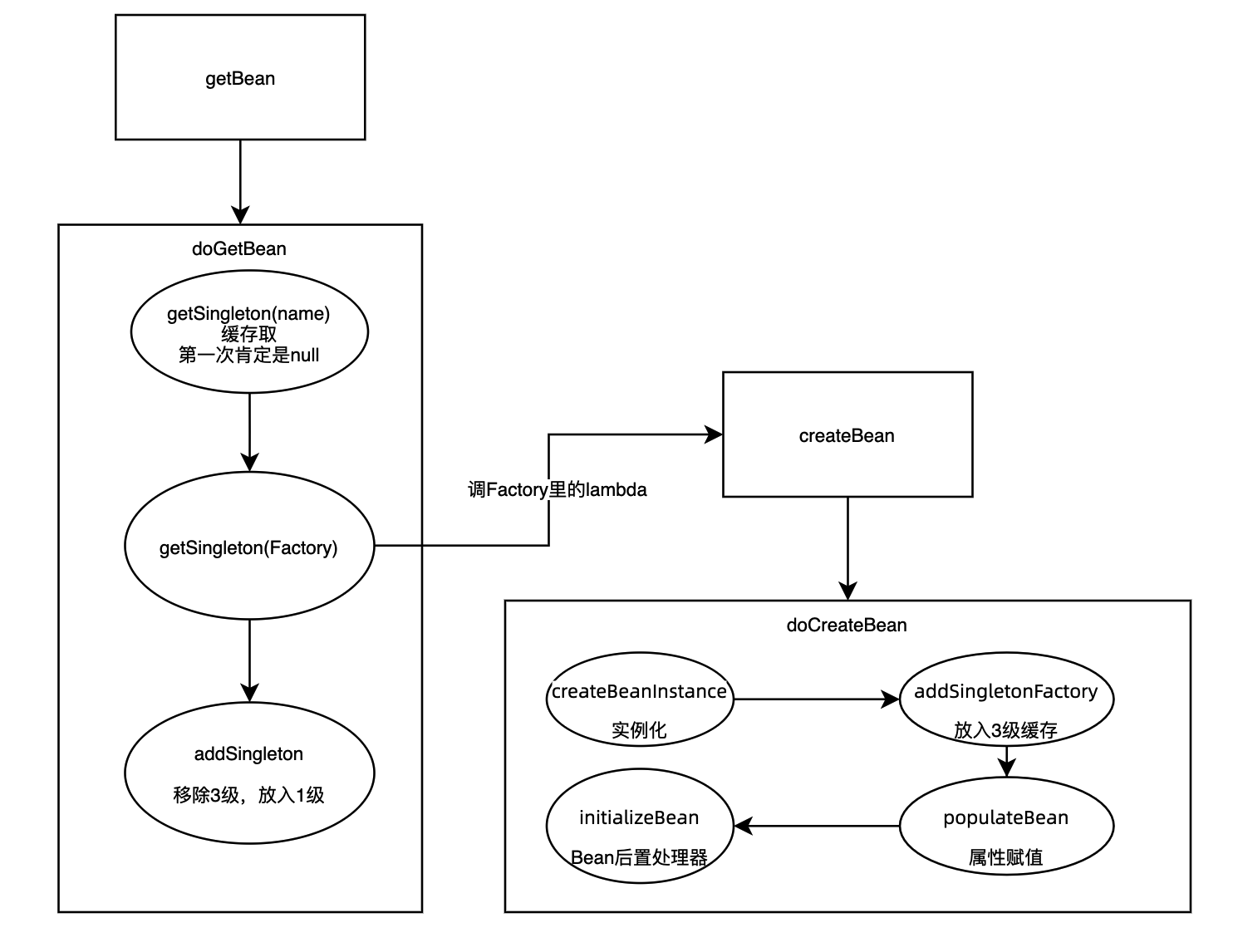
getBean :
入口
doGetBean :
调getSingleton查一下缓存看看有没有,有就返回,没有给singleton一个lambda表达式,函数式编程里调下面的createBean拿到新的bean,然后清除3级缓存,放入1级缓存
createBean :
调这里。一堆检查后,进入下面
doCreateBean :
真正创建bean的地方: 调构造函数初始化 - 放入3级缓存 - 解析属性赋值 - bean后置处理器
3)getSingleton
在DefaultSingletonBeanRegistry里,有三个,作用完全不一样
//啥也没干,调下面传了个true
public Object getSingleton(String beanName)
//从1级缓存拿,1级没有再看情况
//后面的参数如果true,就使用3级升2级返回,否则直接返回null
protected Object getSingleton(String beanName, boolean allowEarlyReference)
//1级没有,通过给的factory创建并放入1级里,清除2、3
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory)
4)bean实例化
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#createBeanInstance
5)放入三级缓存
循环依赖和aop
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#addSingletonFactory
4)注入属性
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#populateBean
真正给bean设置属性的地方!
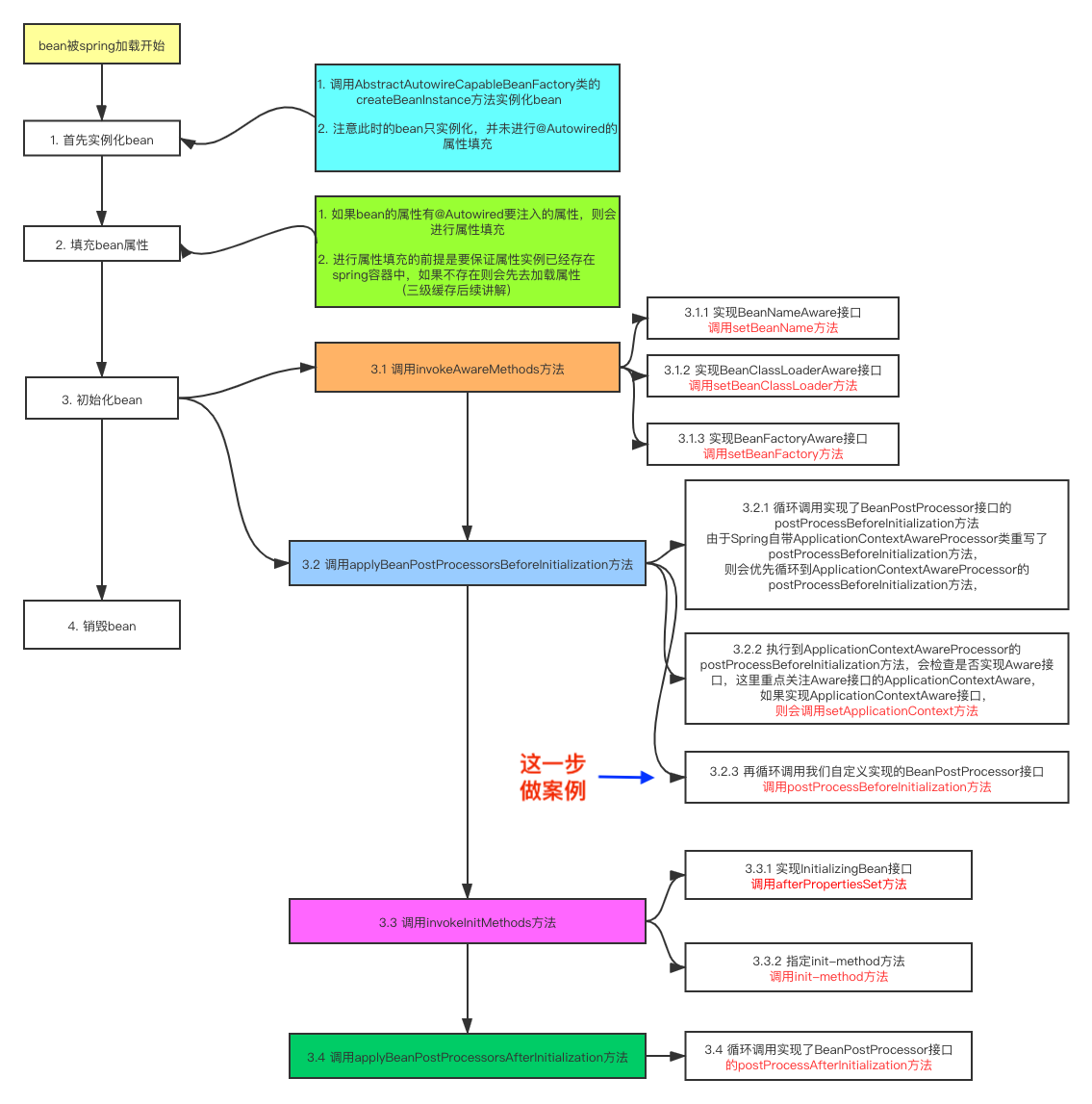
7)bean前后置
还记得上面我们自定义的 Bean后置处理器吗
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#initializeBean
前、后置的调用,在这里
详细见下图第3步,很多,了解即可,需要时查一下在相关地方扩展
8)小结
伪代码,无循环依赖时,生成bean流程一览
getBean("A"){
doGetBean("A"){
a = getSingleton("A"){
a = singletonObjects(); //查1级缓存,null
if("创建过3级缓存"){ //不成立
//忽略
}
return a;
}; // null
if(a == null){
a = getSingleton("A" , ObjectFactory of){
a = of.getObject() -> { //lambda表达式
createBean("A"){
doCreateBean("A"){
createBeanInstance("A"); // A 实例化
addSingletonFactory("A"); // A 放入3级缓存
populateBean("A"); // A 注入属性
initializeBean("A"); // A 后置处理器
} //end doCreateBean("A")
} //end crateBean("A")
} // end lambda A
addSingleton("A" , a) // 清除2、3级,放入1级
} // end getSingleton("A",factory)
} // end if(a == null)
return a;
} //end doGetBean("A")
}//end getBean("A")
3 Spring的循环依赖
引言
在上面,我们剖析了bean实例化的整个过程
也就是我们的Bean他是单独存在的,和其他Bean没有交集和引用
而我们在业务开发中,肯定会有多个Bean相互引用的情况
也就是所谓的循环依赖
3.1 什么是循环依赖
简单回顾下
通俗的讲就是N个Bean互相引用对方,最终形成闭环。
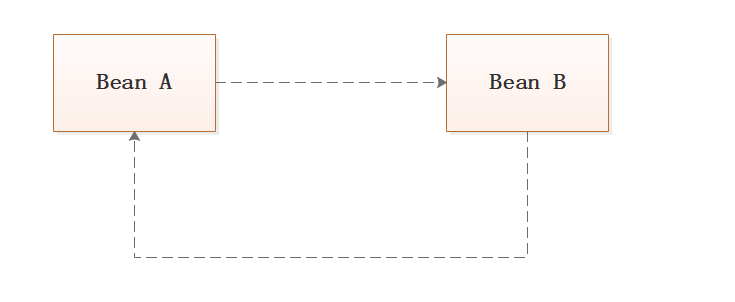
项目代码介绍如下(测试类入口: CircleTest.java)
配置文件
<!--循环依赖BeanA依赖BeanB -->
<bean id="userServiceImplA" class="com.spring.test.impl.UserServiceImplA">
<property name="userServiceImplB" ref="userServiceImplB"/>
</bean>
<!--循环依赖BeanB依赖BeanA -->
<bean id="userServiceImplB" class="com.spring.test.impl.UserServiceImplB">
<property name="userServiceImplA" ref="userServiceImplA"/>
</bean>
userServiceImplA代码如下
public class UserServiceImplA implements UserService {
private UserServiceImplB userServiceImplB;
public void setUserServiceImplB(UserServiceImplB userServiceImplB) {
this.userServiceImplB = userServiceImplB;
}
@Override
public String getName() {
return "在UserServiceImplA的Bean中" +
"userServiceImplB注入成功>>>>>>>>>"+userServiceImplB;
}
}
userServiceImplB代码如下
//实现类
public class UserServiceImplB implements UserService {
private UserServiceImplA userServiceImplA;
public void setUserServiceImplA(UserServiceImplA userServiceImplA) {
this.userServiceImplA = userServiceImplA;
}
@Override
public String getName() {
return "在UserServiceImplB的Bean中" +
"userServiceImplA注入成功>>>>>>>>>"+userServiceImplA;
}
入口Main
ApplicationContext context = new ClassPathXmlApplicationContext("classpath*:application.xml");
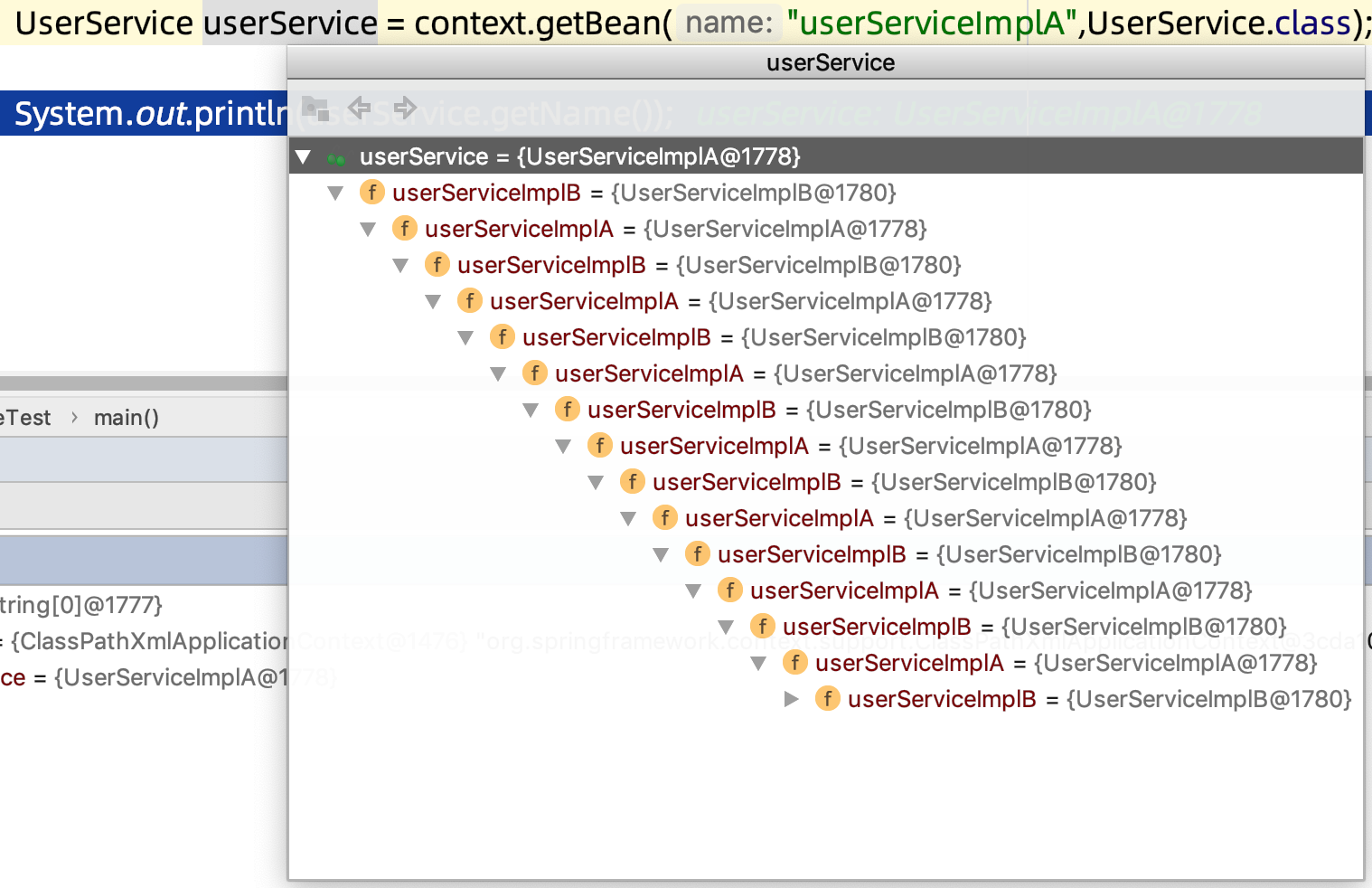
UserService userService = context.getBean("userServiceImplA",UserService.class);
System.out.println(userService.getName());
输出如下

3.2 Spring如何解决循环依赖
假如无法解决循环依赖
1、Bean无法成功注入,导致业务无法进行
2、产生死循环(一种假设情景)
1)三级缓存变化过程
目标:
只有明白三级缓存变化过程,才能知道是如何解决循环依赖的
略去其他步骤,只看缓存变化

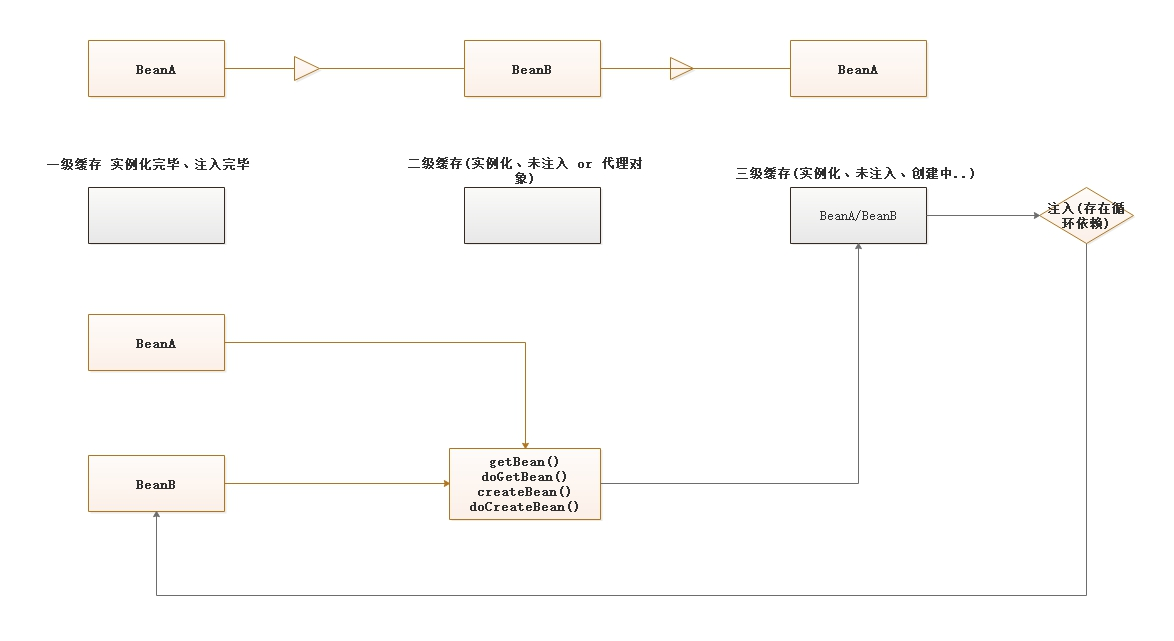
变化过程3-1:如下图:
步骤:
A :… - 走到doCreateBean: 初始化 - 进3级缓存 - 注入属性,发现需要B
B :… - 走到doCreateBean: 初始化 - 进3级缓存
1、BeanA经历gdcd四个方法,走到doCreatebean里在实例化后、注入前放到三级缓存
2、放到三级缓存后;BeanA在正式的注入的时候,发现有循环依赖,重复上【1】的步骤
3、最终:BeanA和BeanB都放到了三级缓存
变化过程3-2:如下图:
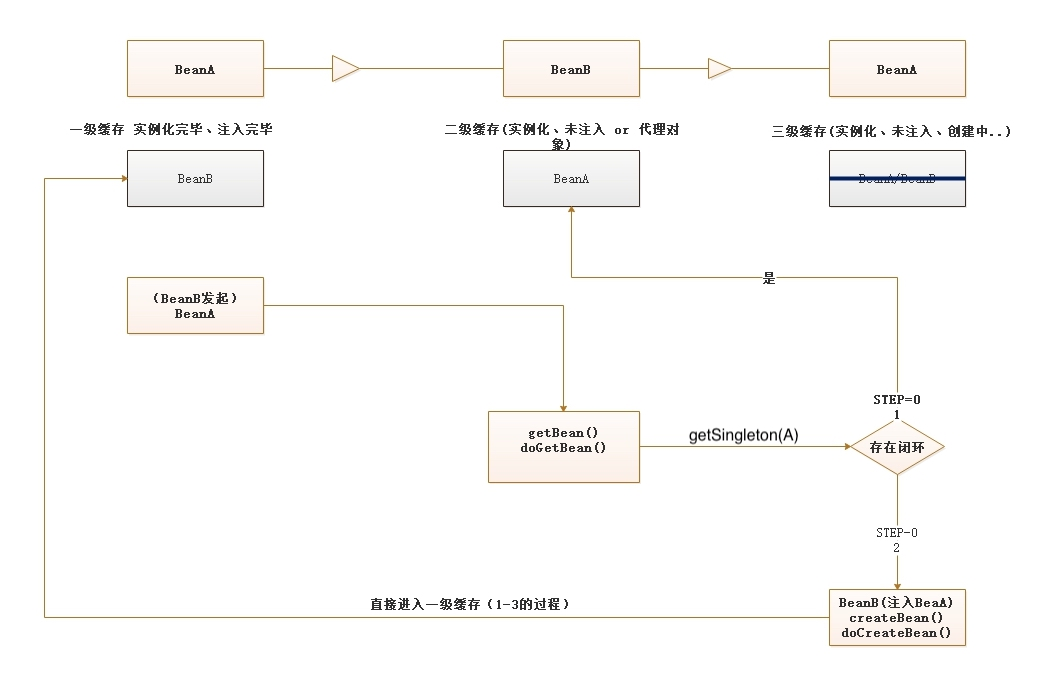
步骤:
1、BeanB放到三级缓存后,这个时候BeanB要开始注入了;
于是,BeanB找到了循环依赖BeanA后,再从头执行A的getBean和doGetBean方法;
此处在getSingleton里面(这货第一次是必经的,但第二次来行为不一样了)将BeanA设置到了二级缓存,并且把BeanA从三级缓存移除走了
2、BeanB如愿以偿的拿到了A,注入,此时,完成了注入过程;一直到DefaultSingletonBeanRegistry#addSingleton方法后;BeanB从三级缓存直接进入一级缓存,完成它的使命
3、目前,一级缓存有BeanB(里面的BeanA属性还是空)、二级缓存有BeanA 三级缓存为空
效果如下
走到这一步,B里面有A,它已完成。
但是很不幸,A里面的B还是null,我们第三步会继续完成这个设置
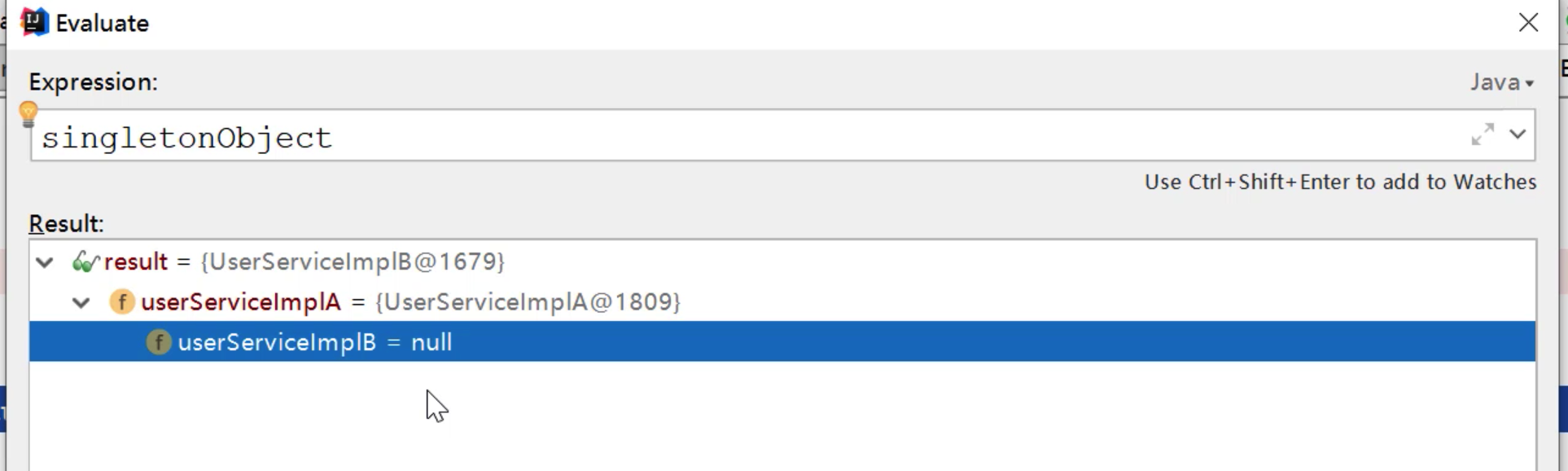
思考一下:
如果不用三级,我们直接用2级也能实现,但是3级我们说它是一个Factory,里面可以在创建的前后嵌入我们的代码,和前后置处理器,Aop之类的操作就发生在这里
而2级存放的是bean实例,没这么多扩展的可能性,如果仅仅用于bean循环创建,倒是可以
总结:
1、如果不调用后置,返回的bean和三级缓存一样
2、如果调用后置,返回的就是代理对象
3、这就是三级缓存设计的巧妙之处!!!!Map<String, ObjectFactory<?>>
变化过程3-3:如下图:
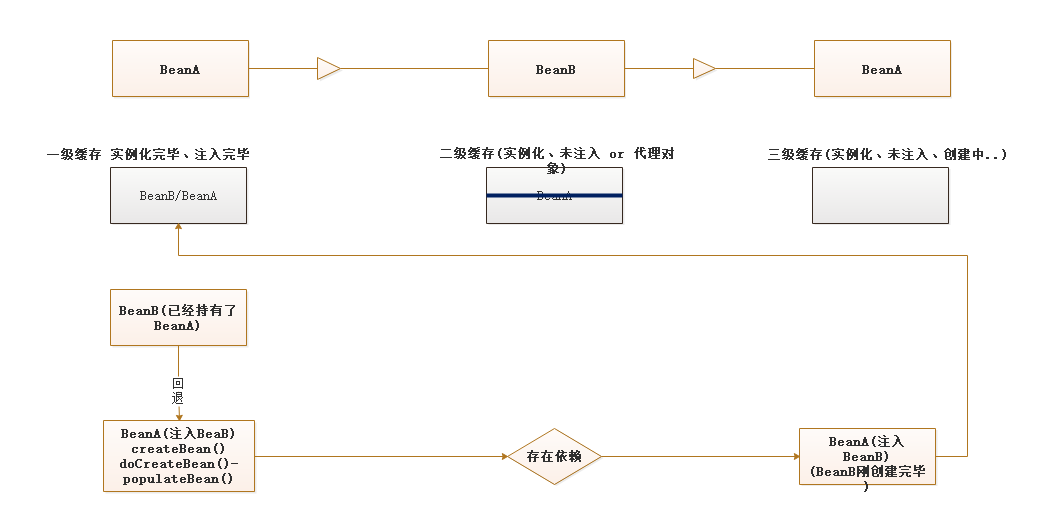
步骤:
此时, BeanB里面已经注入了BeanA,它自己完成并进入了一级缓存
要注意,它的完成是被动的结果,也就是A需要它,临时先腾出时间创建了它
接下来,BeanA 还要继续自己的流程,然后populateBean方法将BeanB注入到自己里
最后,BeanA 进一级缓存,删除之前的二级
整个流程完成!
大功告成:双方相互持有对方效果如下:
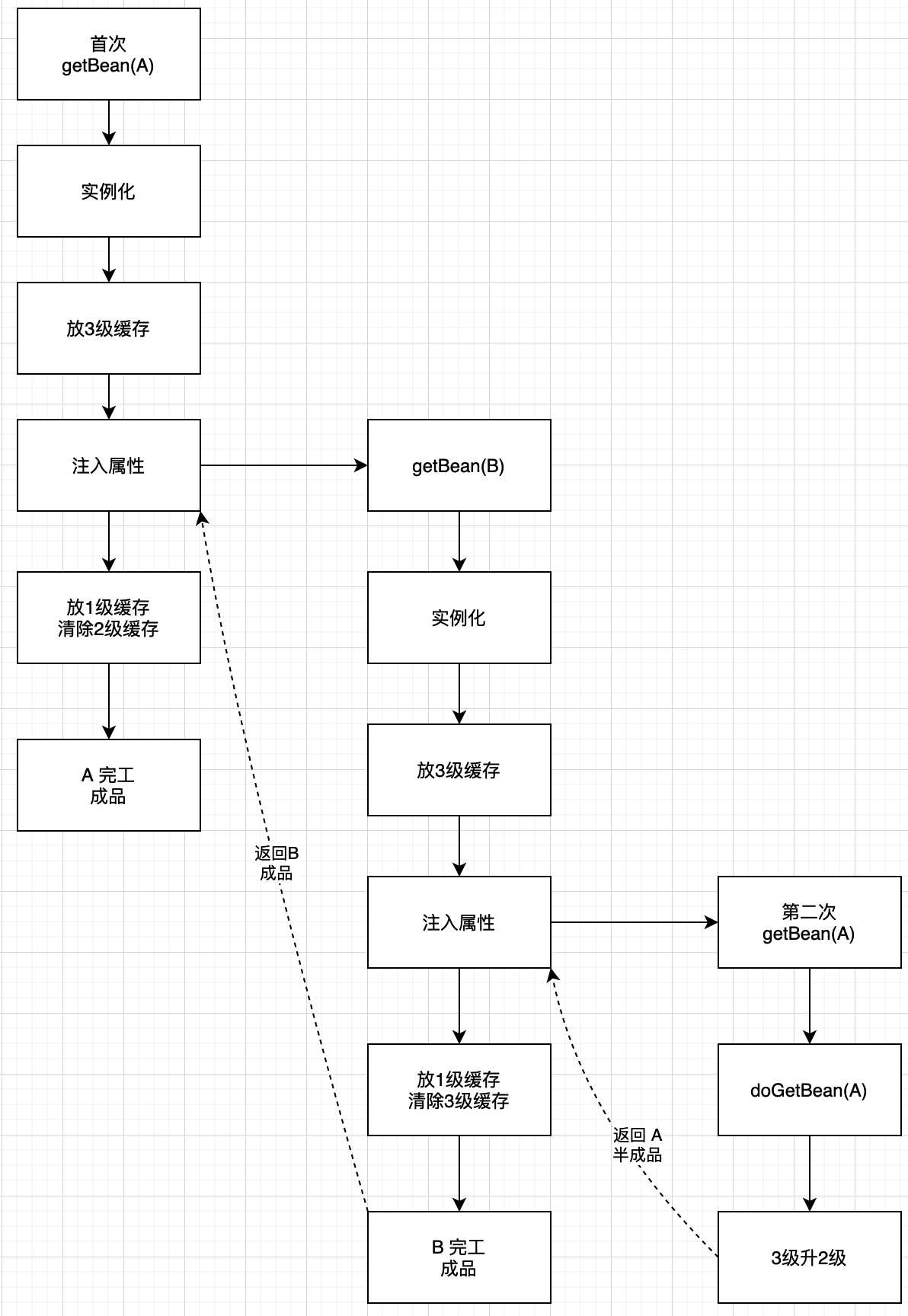
2)三级缓存解决方案总结
简化版
序列图
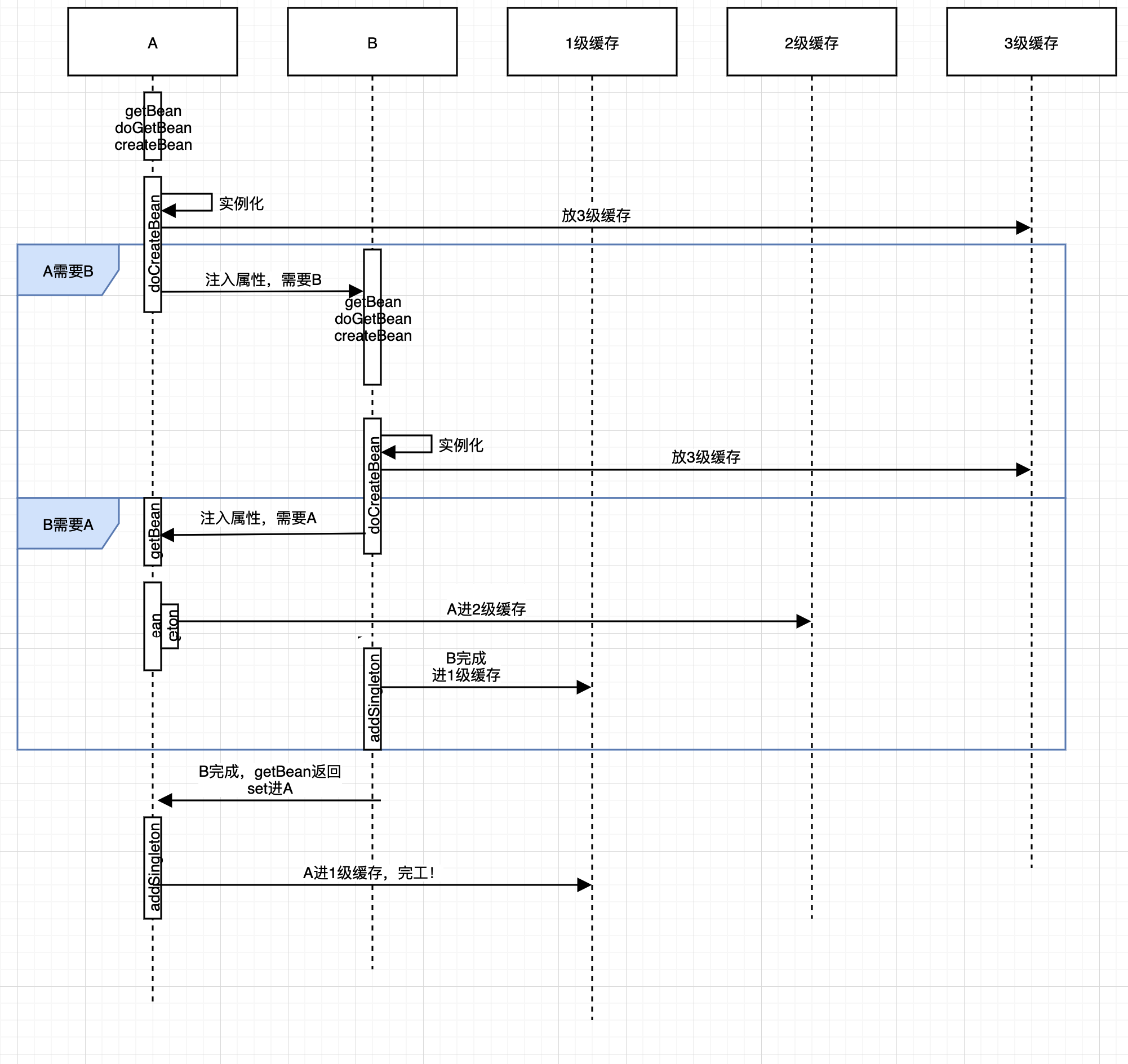
三级缓存解决循环依赖过程(回顾)
1、BeanA经过gdcd方法、放入到3级缓存、如果有循环依赖BeanB,重复执行gdcd方法
2、直到发现了它也需要A,而A前面经历了一次get操作,将3级缓存的BeanA放到2级缓存
3、然后2级缓存的A注入进BeanB, BeanB完事进一级缓存,此时BeanB持有BeanA
3、接下来,继续完成BeanA剩下的操作,取BeanB填充进BeanA,将BeanA放到一级缓存,完成!
伪代码,循环依赖流程一览,都是关键步骤,不能再简化了
建议粘贴到vscode等编辑器里查看,因为……它层级太tmd深了!
getBean("A"){
doGetBean("A"){
a = getSingleton("A"){
a = singletonObjects(); //查1级缓存,null
if("创建过3级缓存"){ //不成立
//忽略
}
return a;
}; // A第一次,null
if(a == null){
a = getSingleton("A" , ObjectFactory of){
a = of.getObject() -> { //lambda表达式
createBean("A"){
doCreateBean("A"){
createBeanInstance("A"); // A 实例化
addSingletonFactory("A"); // A 放入3级缓存
populateBean("A"){
//A 需要B,进入B的getBean
b = getBean("B"){
doGetBean("B"){
b = getSingleton("B"); // B第一次,null
if(b == null){
b = getSingleton("B", ObjectFactory of){
b = of.getObject() -> {
createBean("B"){
doCreateBean("B"){
createBeanInstance("B"); // B 实例化
addSingletonFactory("B"); // B 放入3级缓存
populateBean("B"){
//B 需要A,2次进入A的getBean
a = getBean("A"){
doGetBean("A"){
a = getSingleton("A"){
a = singletonObjects(); //查1级缓存,null
if("创建过3级缓存"){ //成立!
a = singletonFactory.getObject("A"); //取3级缓存,生成a
earlySingletonObjects.put("A", a); //放入2级缓存
singletonFactories.remove("A"); //移除3级缓存
return a;
}
}; // A第二次,不是null,但是半成品,还待在2级缓存里
} // end doGetBean("A")
} // end getBean("A")
} // end populate B
initializeBean("B",b); // B后置处理器
} // end doCreateBean B
} // end createBean B
} // end lambda B
// B 创建完成,并且是完整的,虽然它里面的A还是半成品,但不影响它进入1级
addSingleton("B",b) ; // 清除3级缓存,进入1级
); // end getSingleton("B",factory)
} // end if(b==null);
return b;
} // end doGetBean("B")
} // end getBean("B")
} // end populateBean("A")
initializeBean("A"); // A 后置处理器
} //end doCreateBean("A")
} //end crateBean("A")
} // end lambda A
addSingleton("A" , a) // 清除2、3级,放入1级
} // end getSingleton("A",factory)
} // end if(a == null)
return a;
} //end doGetBean("A")
}//end getBean("A")
总结
可以发现,通过spring的三级缓存完美解决了循环依赖
Spring处理机制很聪明;它先扫描一遍Bean,先放到一个容器(3级缓存待命)
此时也不知道是否存在循环依赖,先放到三级缓存再说
等到设置属性的时候,取对应的属性bean去(此时才发现有了循环依赖) ,在放到第二个容器(2级缓存,半成品)
继续,然后从二级缓存拿出进行填充(注入)
填充完毕,将自己放到一级缓存(这个bean是被动创建出来的,因为别人需要它,结果它先完成了)
然后不断循环外层,处理最原始要创建的那个bean
为什么设计三级?二级缓存能否解决循环依赖?
可以解决。别说2级,1级都行
虽然二级缓存能解决循环依赖,但是aop时会可能会引发问题,三级是一个factory,在里面配备了对应的后置处理器,其中就有我们的aop (后面会讲到),如果有人要用它,会在调用factory的getObject时生效,生成代理bean而不是原始bean。
如果不这么做,直接创建原始对象注入,可能引发aop失效。
所以spring的3级各有意义:
1级:最终成品
2级:半成品
3级:工厂,备用
在上面的方法getEarlyBeanReference(提前暴露的引用)
回顾下
AbstractAutowireCapableBeanFactory.getEarlyBeanReference
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
//循环所有Bean后置处理器
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
//重点:开始创建AOP代理
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
总结下:
1、如果不调用后置处理器,返回的Bean和三级缓存一样,都是实例化、普通的Bean
2、如果调用后置,返回的就是代理对象,不是普通的Bean了
其实;这就是三级缓存设计的巧妙之处
那为什么要2级呢? 不能直接放入1级吗?
不能!
A-B-A中,第二次A的时候,A还是个半成品,不能放入1级
以上面为例,A在进入2级缓存的时候,它里面的B还是个null !
如果放入1级,被其他使用的地方取走,会引发问题,比如空指针
4 IoC用到的那些设计模式
引言:
Spring中使用了大量的设计模式(面试)
4.1 工厂
**工厂模式(Factory Pattern)**提供了一种创建对象的最佳方式。
工厂模式(Factory Pattern)分为三种
1、简单工厂
2、工厂方法
3、抽象工厂
1. 简单工厂模式
ApplicationContext context =
new ClassPathXmlApplicationContext("classpath*:application.xml");\
UserService userService = context.getBean(UserService.class);
简单工厂模式对对象创建管理方式最为简单,因为其仅仅简单的对不同类对象的创建进行了一层简单的封装
定义接口IPhone
public interface Phone {
void make();
}
实现类
public class IPhone implements Phone {
public IPhone() {
this.make();
}
@Override
public void make() {
// TODO Auto-generated method stub
System.out.println("生产苹果手机!");
}
}
实现类
public class MiPhone implements Phone {
public MiPhone() {
this.make();
}
@Override
public void make() {
// TODO Auto-generated method stub
System.out.println("生产小米手机!");
}
}
定义工厂类并且测试
public class PhoneFactory {
public Phone makePhone(String phoneType) {
if (phoneType.equalsIgnoreCase("MiPhone")) {
return new MiPhone();
} else if (phoneType.equalsIgnoreCase("iPhone")) {
return new IPhone();
}
return null;
}
//测试简单工厂
public static void main(String[] arg) {
PhoneFactory factory = new PhoneFactory();
Phone miPhone = factory.makePhone("MiPhone");
IPhone iPhone = (IPhone) factory.makePhone("iPhone");
}
}

4.2 模板
**模板模式(Template Pattern)😗*基于抽象类的,核心是封装算法
Spring核心方法refresh就是典型的模板方法
org.springframework.context.support.AbstractApplicationContext#refresh
模板设计模式—
模板方法定义了一个算法的步骤,并允许子类为一个或多个步骤提供具体实现
//模板模式
public abstract class TemplatePattern {
protected abstract void step1();
protected abstract void step2();
protected abstract void step3();
protected abstract void step4();
//模板方法
public final void refresh() {
//此处也可加入当前类的一个方法实现,例如init()
step1();
step2();
step3();
step4();
}
}
定义子类
//模板模式
public class SubTemplatePattern extends TemplatePattern {
@Override
public void step1() {
System.out.println(">>>>>>>>>>>>>>1");
}
@Override
public void step2() {
System.out.println(">>>>>>>>>>>>>>2");
}
@Override
public void step3() {
System.out.println(">>>>>>>>>>>>>>3");
}
@Override
public void step4() {
System.out.println(">>>>>>>>>>>>>>4");
}
//测试
public static void main(String[] args) {
TemplatePattern tp = new SubTemplatePattern();
tp.refresh();
}
}
输出

4.3 观察者
什么是观察者模式
观察者模式(Observer Pattern):当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知依赖它的对象。
Spring 的事件机制就是具体的观察者模式的实现
spring中的多播与事件
AbstractApplicationContext#initApplicationEventMulticaster
AbstractApplicationContext#registerListeners
观察者模式有哪些角色?
事件 ApplicationEvent 是所有事件对象的父类,继承JDK的EventObject
事件监听 ApplicationListener,也就是观察者对象,继承自 JDK 的 EventListener,可以监听到事件;该类中只有一个方法 onApplicationEvent。当监听的事件发生后该方法会被执行。
事件发布ApplicationContext, 实现事件的发布。
(发布事件)
or=========
Spring中的多播
事件发布 ApplicationEventMulticaster,用于事件监听器的注册和事件的广播。
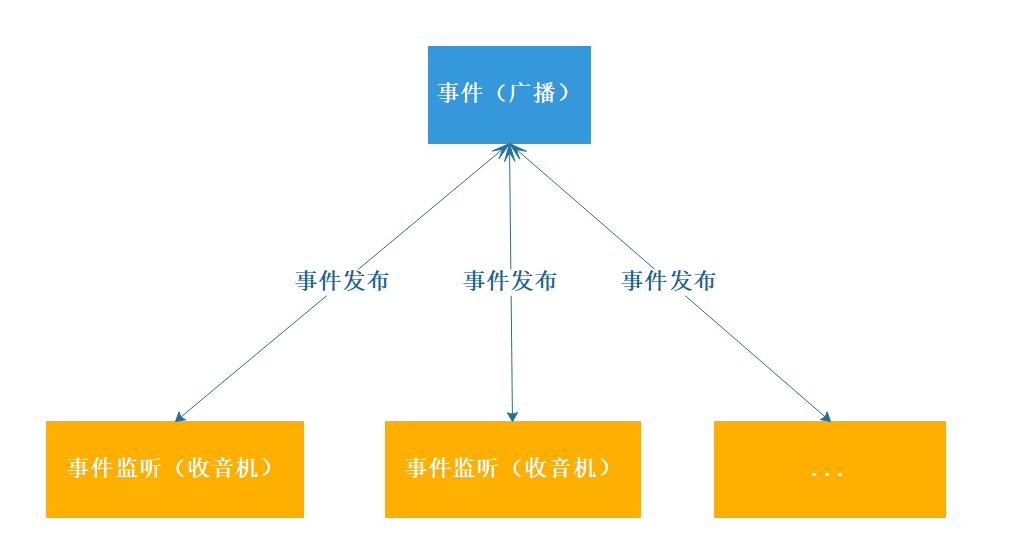
自定义一个事件MessageSourceEvent并且实现ApplicationEvent接口
//在Spring 中使用事件监听机制(事件、监听、发布)
//定义事件
//执行顺序
//1、进入到事件源的有参数构造器
//2、发布事件
//3、进入到监听器类---one
//4、进入到事件源的方法
//5、进入到监听器类---two
//6、进入到事件源的方法
public class MessageSourceEvent extends ApplicationEvent {
public MessageSourceEvent(Object source) {
super(source);
System.out.println("进入到事件源的有参数构造器");
}
public void print() {
System.out.println("进入到事件源的方法");
}
}
有了事件之后还需要自定义一个监听用来接收监听到事件,自定义ApplicationContextListener监听 需要交给Spring容器管理, 实现ApplicationListener接口并且重写onApplicationEvent方法,
监听一
//在Spring 中使用事件监听机制(事件、监听、发布)
//监听类,在spring配置文件中,注册事件类和监听类
public class ApplicationContextListener implements ApplicationListener {
@Override
public void onApplicationEvent(ApplicationEvent event) {
if (event instanceof MessageSourceEvent) {
System.out.println("进入到监听器类---one");
MessageSourceEvent myEvent = (MessageSourceEvent) event;
myEvent.print();
}
}
}
监听二
//在Spring 中使用事件监听机制(事件、监听、发布)
//监听类,在spring配置文件中,注册事件类和监听类
public class ApplicationContextListenerTwo implements ApplicationListener {
@Override
public void onApplicationEvent(ApplicationEvent event) {
if(event instanceof MessageSourceEvent){
System.out.println("进入到监听器类---two");
MessageSourceEvent myEvent=(MessageSourceEvent)event;
myEvent.print();
}
}
}
发布事件
//在Spring 中使用事件监听机制(事件、监听、发布)
//该类实现ApplicationContextAware接口,得到ApplicationContext对象
// 使用该对象的publishEvent方法发布事件
public class ApplicationContextListenerPubisher implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
public void publishEvent(ApplicationEvent event) {
System.out.println("发布事件");
applicationContext.publishEvent(event);
}
}
配置文件
<!-- Spirng中的事件>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> -->
<!--<bean id="messageSourceEvent" class="com.spring.test.pattern.observer.MessageSourceEvent" />-->
<bean id="applicationContextListener" class="com.spring.test.pattern.observer.ApplicationContextListener"/>
<bean id="applicationContextListenerTwo" class="com.spring.test.pattern.observer.ApplicationContextListenerTwo"/>
<bean id="applicationContextListenerPubisher" class="com.spring.test.pattern.observer.ApplicationContextListenerPubisher"/>
<!-- Spirng中的事件>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> -->
测试
//总结 :使用bean工厂发布和使用多播器效果是一样的
public class Test {
public static void main(String[] args) {
ApplicationContext context =
new ClassPathXmlApplicationContext("classpath*:application.xml");
//***************使用spring的多播器发布**********************
ApplicationEventMulticaster applicationEventMulticaster = (ApplicationEventMulticaster) context.getBean("applicationEventMulticaster");
applicationEventMulticaster.multicastEvent(new MessageSourceEvent("测试..."));
//***************使用BeanFactory的publishEvent发布*********************
// ApplicationContextListenerPubisher myPubisher = (ApplicationContextListenerPubisher)
//context.getBean("applicationContextListenerPubisher");
//myPubisher.publishEvent(new MessageSourceEvent("测试..."));
}
}
多播发布

工厂发布

总结:
1、spring的事件驱动模型使用的是 观察者模式
2、通过ApplicationEvent抽象类和ApplicationListener接口,可以实现事件处理
3、ApplicationEventMulticaster事件广播器实现了监听器的注册,一般不需要我们实现,只需要显示的调用 applicationcontext.publisherEvent方法即可
4、使用bean工厂发布和使用多播器效果是一样的
本文由
传智教育博学谷教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!


![[SpringBoot] AOP-AspectJ 切面技术](https://img-blog.csdnimg.cn/5726ce2133414fe596d8d38f34d9795e.png)