导航小助手
一、认识搜索引擎
二、项目目标
三、模块划分
四、创建项目
五、关于分词
六、实现索引模块
6.1 实现 Parser类
6.2 实现 Index类
6.2.1 创建 Index类
6.2.2 创建DocInfo类
6.2.3 创建 Weight类
6.2.4 实现 getDocInfo 和 getInverted方法
6.2.5 实现 addDoc方法
6.2.6 实现save方法
6.2.7 实现 load方法
6.3 在 Parser 中调用 Index
6.3.1 新增 Index实例
6.3.2 修改 parseHTML方法
6.3.3 新增save方法的调用
6.4 验证索引模块
6.5 优化制作索引速度
七、实现搜索模块
7.1 创建 DocSearcher类
7.1.1 创建 Result类
7.1.2 实现 search方法
7.1.3 验证 DocSearcher类
7.1.4 修改 Parser类
八、实现Web模块
一、认识搜索引擎
关于搜索引擎,平时的时候都是用的比较多,如:百度、搜狗、谷歌等搜索引擎,但是并没有仔细的观察过~
以搜狗搜索为例,我们打开搜狗搜索,就会发现,有一个搜索主页,并且有一个搜索框,我们可以在搜索框中搜索 想要知道的内容,点击 搜索,就可以查找搜索结果的页面~
搜索引擎 的核心功能,就是查找到 一组和用户输入的查询词(或者是一句话),所相关联的网页~
通过观察可以发现,对于每一条搜索结果,都会显示该搜索结果的 标题、描述、展示url等属性(虽然有的结果样式上可能会更复杂,但是还是会有 标题、描述、展示url属性),当我们点击一条搜索记录的时候,就跳转到相应的页面(称之为 落地页)~
搜索引擎的核心实现思路:
搜索引擎的核心目的是:在很多很多的网页中 找到和查询词相关联的内容~
那么,对于一个搜索引擎来说,首先需要获取到很多的网页,然后再根据用户输入的查询词,在这些网页中进行查找~
这就涉及到了几个问题:
- 搜索引擎的网页是怎么获取到的(此处主要是涉及到 "爬虫" 程序,此处不过多介绍)
- 用户输入查询词之后,如何让查询词和当前的这些网页进行匹配呢(这个是重点)
假设 当前已经爬取到了 1亿 个网页(html文件),用户输入了一个 "蛋糕"查询词,此时如果使用的是 "暴力搜索"的话,那么就需要把 "蛋糕"这个字符串 在这1亿个网页里面进行查找,那肯定是效率很低的(特别是对于搜索引擎来说,我们都希望 再进行搜索之后,会立刻出现我们所要查找的结果)~
因此为了更加高效的解决这个问题,大佬们专门设计了一种特殊的数据结构 —— 倒排索引~
需要知道的知识:
举个例子:
在日常的生活中,我们也会有所体会(就比如说在 玩王者荣耀的时候):



二、项目目标
像搜索引擎这样的程序,是一个很复杂的程序,很难做出像百度、搜狗一样的规模庞大的搜索引擎,所以可以简化一下目标:可以做一个针对 Java API文档的搜索引擎~

通过观察可以发现,官方文档上面并没有一个搜索框,所以想要去查找某个类,但又不知道这个类在哪个包里,就会显得很麻烦~
因此就可以实现这样一个站内搜索引擎,让用户输入一些查询词,之后就可以找到相关的文档页面~

获取Java文档:
要想实现这个项目,首先就需要把相关的网页文档给获取到,然后才可以继续接下来的过程~
相关网页在 oracle官方网站上面,想要把上面所有的页面获取到,并不是一件很容易的事情~
虽然说,可以通过 "爬虫"技术,把这些文档获取到,但是 "爬虫"技术 还没有学到(听说 实现"爬虫"程序 会存在法律风险的),所以就暂时放弃这个方法~
针对于 Java API文档 来说,还有更加简单的方法 —— 可以直接从官网上直接下载,因此就不必通过爬虫来实现~
Java API文档 线上版本:https://docs.oracle.com/javase/8/docs/api/index.html
Java API文档 线下版本 下载地址:https://www.oracle.com/java/technologies/downloads/

三、模块划分
1)索引模块
- 扫描下载到的文档,分析文档内容,构建出 正排索引+倒排索引,并且把索引内容保存到文件中~
- 加载制作好的索引,并提供一些API实现查正排和查倒排这样的功能~
2)搜索模块
- 调用索引模块,实现一个搜索的完整过程~
- 输入:用户的查询词;输出:完整的搜索结果(包含了很多条记录,每个记录有 标题、描述、展示url,并且点击可以跳转)~
3)Web模块
- 需要实现一个简单的 web程序,能够通过网页的形式和用户进行交互~
四、创建项目

五、关于分词
用户在搜索引擎中,输入的查询词,不一定真的只是一个词,也有可能是一句话:
由上面的搜索结果我们可以知道,先针对完整的句子进行分词,然后根据每个词的分词结果,分别找到相关的文档~
针对 "分词"操作,人是非常容易完成的;但是对于机器来说,这就困难很多;英文的话还好,有空格就可以了,但是中文博大精深,额,就非常的哇塞了~
比如说,"我一把把车把把住","小龙女也想过过过儿过过的生活","下雨天留客天留我不留" ~
好在,我们要想实现这个分词效果,就可以基于一些现成的第三方库,从而实现分词效果~
分词实现原理
虽然说,我们现在使用的是第三方库,并不是自己实现分词逻辑,但是还是需要了解一下 分词的原理~
第一种情况:基于词库!
以汉语为例,虽然说,汉字很多,但是仍然是可以尝试着把所有的词都穷举在一本词典文件中,然后就可以依次的取句子中的内容:如:每隔一个字,就在词典里查一下;每隔两个字,查一下;......
但是,这并不能把所有的词都穷举出来,而且 随着时间的推移,也会产生越来越多的新词,......,关是基于词库,并不能分出所有的词~
第二种情况:基于统计!
利用这种方法,收集很多很多的 "语料库"(如:现有的一些文章、资料等等),接着就可以进一步进行人工标注/或者是直接统计,接着就进一步的知道了哪些词 成词的情况比较高(就类似于根据用户的习惯)~
分词的实现,就是属于 "人工智能" 典型应用的场景 ~
使用第三方库:
在Java中可以实现分词的第三方库 也是有很多的,在这里我们可以使用 ansj分词库~
<!-- 引入分词依赖,下载安装ansj -->
<!-- https://mvnrepository.com/artifact/org.ansj/ansj_seg -->
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>示例:
public static void main(String[] args) {
//准备一个比较长的话,用来分词(中文分词)
String str1 = "人终将被少年不可得之物困其一生,但也终会因一事一景解开一生困惑";
List<Term> terms1 = ToAnalysis.parse(str1).getTerms();
for (Term term1 : terms1) {
System.out.print(term1.getName() + '/');
}
System.out.println();
//英文分词(会把大写字母转换成小写字母)
String str2 = "I have a dream!";
List<Term> terms2 = ToAnalysis.parse(str2).getTerms();
for (Term term2 : terms2) {
System.out.print(term2.getName() + ' ');
}
}结果:

六、实现索引模块
6.1 实现 Parser类
创建一个Parser类,通过这个类来完成制作索引的过程~
Parser:读取之前下载好的离线文档,去解析文档的内容,并完成索引的制作!
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
public class Parser {
//指定加载文档的路径
private static final String INPUT_PATH = "E:/doc_searcher_index/jdk-8u361-docs-all/docs/api/";
private void run() {
//整个Parser类的入口
//1、根据上面指定的路径,枚举出该路径中所有的 html文件(包括子目录中的文件)
//2、针对上面罗列出文件的路径,打开文件,读取文件内容,并进行解析,并构建索引
//3、todo 把在内存中构造好的索引数据结构,保存到指定的文件中
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
/**
* System.out.println(fileList);
* System.out.println(fileList.size());
*/
for (File f:fileList) {
//通过parseHTML()方法解析 .html文件
System.out.println("开始解析:" + f.getAbsolutePath());
parseHTML(f);
}
}
/**
* 解析 .html文件 的方法
* @param f
*/
private void parseHTML(File f) {
//解析 标题
String title = parseTitle(f);
//解析 url
String url = parseUrl(f);
//解析 对应的正文(描述 是正文的一小部分,先解析出来正文,然后才可以获取到 描述)
String content = parseContent(f);
//todo 把解析出来的这些信息,加入到索引当中
}
/**
* 通过观察,可以发现,在 .html文件中,<title>标签 里面的就是标题
* 进一步可以发现,.html文件名 就是该文件的标题
*/
private String parseTitle(File f) {
return f.getName().substring(0,f.getName().length() - ".html".length());
}
/**
* url 是在线文档对应的链接
*/
private String parseUrl(File f) {
//先获取到固定的前缀
String part1 = "https://docs.oracle.com/javase/8/docs/api/";
//后获取 线下文档api后面的部分
String part2 = f.getAbsolutePath().substring(INPUT_PATH.length());
return part1 + part2;
}
/**
* 一个完整的 .html文件,里面有的是 <html>标签 + 内容
* 所以 解析正文的核心工作是:去掉 <html>标签,只剩下 内容
*/
public String parseContent(File f) {
//先按照一个字符一个字符的方式来读取( < 和 > 来控制拷贝数据的开关)
try( FileReader fileReader = new FileReader(f)) {
//加上一个开关:true拷贝,false不拷贝
boolean isCopy = true;
//加上一个保存结果的stringBuilder
StringBuilder stringBuilder = new StringBuilder();
while (true) {
//read()返回值是 int,而不是 char
//主要是为了表示一些非法情况,文件读完了,返回-1
int ret = fileReader.read();
if (ret == -1) {
break;
}
//如果结果不是-1,那就是合法的字符
char c = (char) ret;
if (isCopy) {
//开关打开,遇到普通字符就拷贝到 StringBuilder中
if (c == '<') {
//关闭开关
isCopy = false;
continue;
}
//去掉 .html文件当中的换行,不然实在是不好看
if (c == '\n' || c == '\r') {
//把换行替换成空格
c = ' ';
}
//其他字符,直接拷贝
stringBuilder.append(c);
}else {
//开关不拷贝,直到遇到 >
if (c == '>') {
isCopy = true;
}
}
}
return stringBuilder.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
/**
*
* @param inputPath 表示从哪个目录开始进行递归遍历
* @param fileList 表示递归所得到的结果
*/
private void enumFile(String inputPath, ArrayList<File> fileList) {
File rootPath = new File(inputPath);
File[] files = rootPath.listFiles(); //listFiles()方法,获取到rootPath目录下的路径名(仅仅只能看到一层内容)
//使用递归,看见所有子目录下面的内容
for (File f:files) {
//根据f类型,来决定是否需要递归
if (f.isDirectory()) {
//f 是一个目录,递归调用enumFile()方法,进一步获取子目录的内容
enumFile(f.getAbsolutePath(),fileList);
}else {
//f 是一个普通文件,加入到 fileList中
//在此处排除非.html文件(以.html的文件才添加上去)
if (f.getAbsolutePath().endsWith(".html")) {
fileList.add(f);
}
}
}
}
public static void main(String[] args) {
//通过 main方法,实现整个制作索引的过程
Parser parser = new Parser();
parser.run();
}
}
在Parser类当中,主要做的是,枚举出当前指定目录中的所有的 .html文档,通过递归函数 enumFile(INPUT_PATH,fileList) ,把所获取到的文档存储在 fileList里面;接下来就可以循环遍历这里的每一个文件,再针对文件进行解析,每一个文件都是一个 .html,解析 .html文件的 标题、描述、展示url ~
在解析好了这些信息,就可以把它们加入到索引数据结构当中;于是,就可以专门创建一个 Index类,来负责构建索引数据结构~
6.2 实现 Index类
6.2.1 创建 Index类
Index类 主要实现的功能有:
- 正排索引
- 倒排索引
- 新增一个文档
- 保存索引文件
- 加载索引文件
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
/**
* 通过这个类在内存中构造出索引结构
*/
public class Index {
//使用数组下标表示 docId(正排索引)
private ArrayList<DocInfo> forwardIndex = new ArrayList<>();
//使用 哈希表 来表示倒排索引(key是词,value是一组和这个词相关联的文章)
private HashMap<String,ArrayList<Weight>> invertedIndex = new HashMap<>();
//这个类所提供的方法
//1.正排索引:给定一个 docId,在正排索引中,可以查询到文档的详细信息
//2.倒排索引:给定一个词,在倒排索引中,查找那些文档和这个词有关联
//3.将前面所解析出来的信息添加进去,向索引当中新增一个文档
//4.把内存中的索引结构保存到磁盘中
//5.把磁盘中的索引数据加载到内存
//1.
public DocInfo getDocInfo(int docId) {
//todo
return null;
}
//2.
public List<Weight> getInverted(String term) {
//todo
return null;
}
//3.
public void addDoc(String title,String url,String content) {
//todo
}
//4.
public void save() {
//todo
}
//5.
public void load() {
//todo
}
}
6.2.2 创建DocInfo类
DocInfo类主要表示的是:在正排索引中,根据 docId 所查询的文档的相关细节~
/**
* 该类当中可以表示一个文档的相关细节
*/
public class DocInfo {
private int docId;
private String title;
private String url;
private String content;
public int getDocId() {
return docId;
}
public void setDocId(int docId) {
this.docId = docId;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
6.2.3 创建 Weight类
Weight类主要表示的是:在倒排索引中,文档id 和 文档与词的相关性 的权重~
/**
* 这个类是把 文档id 和 文档与词的相关性 的权重 进行一个包裹
*/
public class Weight {
private int docId;
//weight表示 文档和词之间的"相关性",值越大,就说明 这个词和这个文档越有关的
private int weight;
public int getDocId() {
return docId;
}
public void setDocId(int docId) {
this.docId = docId;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
}
6.2.4 实现 getDocInfo 和 getInverted方法
//1.
public DocInfo getDocInfo(int docId) {
return forwardIndex.get(docId);
}
//2.
public List<Weight> getInverted(String term) {
return invertedIndex.get(term);
}6.2.5 实现 addDoc方法
//3.
public void addDoc(String title,String url,String content) {
//新增文档操作,需要给正排索引和倒排索引都新增
//构建正排索引
DocInfo docInfo = buildForward(title,url,content);
//构建倒排索引
buildInverted(docInfo);
}
private void buildInverted(DocInfo docInfo) {
//倒排索引,是词与文档id的映射关系
//就需要知道当前的文档,里面存在有哪些词,就需要实现"分词"
//就需要针对 标题、正文 进行分词,之后就可以根据分词的结果,知道当前的文档id 应该要加入到哪一个倒排索引的key里
//1.针对标题进行分词,遍历分词结果,统计每个词出现的次数
//2.针对正文进行分词,遍历分词结果,统计每个词出现的个数
//3.汇总到HashMap中,简单设置权重,权重=标题出现的次数*10 + 正文出现的次数
//4.遍历HashMap,依次更新倒排索引中的结构
class WordCount {
public int titleCount; //标题次数
public int contentCount;//正文次数
}
//用来统计词频的数据结构
HashMap<String,WordCount> wordCountHashMap = new HashMap<>();
List<Term> terms = ToAnalysis.parse(docInfo.getTitle()).getTerms();
for (Term term:terms) {
//先判定term 是否存在
String word = term.getName();
WordCount wordCount = wordCountHashMap.get(word);
if (wordCount == null) {
//不存在,创建一个新的键值对,插入进去,titleCount设为1
WordCount newWordCount = new WordCount();
newWordCount.titleCount = 1;
newWordCount.contentCount = 0;
wordCountHashMap.put(word,newWordCount);
}else {
//存在,找到之前的值,对应的 titleCount+1
wordCount.titleCount += 1;
}
}
terms = ToAnalysis.parse(docInfo.getContent()).getTerms();
for (Term term:terms) {
String word = term.getName();
WordCount wordCount = wordCountHashMap.get(word);
if (wordCount == null) {
WordCount newWordCount = new WordCount();
newWordCount.titleCount = 0;
newWordCount.contentCount = 1;
wordCountHashMap.put(word,newWordCount);
}else {
wordCount.contentCount += 1;
}
}
for (Map.Entry<String,WordCount> entry : wordCountHashMap.entrySet()) {
//先根据这里的词去倒排索引中查一查
List<Weight> invertedList = invertedIndex.get(entry.getKey()); //倒排拉链
if (invertedList == null) {
ArrayList<Weight> newInvertedList = new ArrayList<>();
//把新的文档(当前 DocInfo),构造成 Weight对象,插入进来
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
//权重计算公式:标题中出现的次数*10+正文中出现的次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
newInvertedList.add(weight);
//如果为空,就插入一个新的键值对
invertedIndex.put(entry.getKey(),newInvertedList);
}else {
//如果非空,就把这个文档,构造一个 Weight对象,插入到倒排拉链的后面
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
//权重计算公式:标题中出现的次数*10+正文中出现的次数
weight.setWeight(entry.getValue().titleCount * 10 + entry.getValue().contentCount);
invertedList.add(weight);
}
}
}6.2.6 实现save方法
至于为什么要实现save方法呢其实原因也是很简单的:当前索引是存储在 内存 中,而构建索引的过程(即上面实现的addDoc方法),实际上是非常耗时间的,仅仅一个API就有上万份文档了,更别说其他的了~
因此我们不应该服务器启动的时候才构建索引(启动服务器就可能会被拖慢很多了),万一服务器在运行过程中又崩溃了,那又要重启服务器,那又要浪费更长的时间了~
通常的操作可以是:先把这些耗时的操作,单独的去执行;执行好了之后,再让线上服务器直接加载这个构造好的索引;此时,加载的速度就仅在读磁盘上面花费时间了~
至于具体该如何去保存到文件中呢?我们都知道,文件里保存的不是 二进制数据,就是文本数据;这就需要把内存中的索引结构 变成一个字符串(这个过程叫做 序列化),然后就可以直接写文件就可以了~
类似的,把特定结构的字符串 按照一定的结构解析回来(类/对象/基础数据结构),我们就称之为 反序列化~
其实,序列化和反序列化 ,都有许多现成的方法,此处可以使用JSON的格式,来完成 序列化和反序列化,就可以很轻松的完成保存和加载索引的操作了~
此处使用JSON的格式,可以从中央仓库中引入 相关依赖:
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind --> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.15.2</version> </dependency>
//引入 jackson 里面的核心对象
private ObjectMapper objectMapper = new ObjectMapper();
//保存的地址
private static final String INDEX_PATH = "E:\\doc_searcher_index\\";由于涉及到两种索引,就可以分别使用两个文件 来保存正排索引和倒排索引~
//4.
public void save() {
//序列化
//使用两个文件,分别保存正排和倒排
System.out.println("保存所以开始!");
//1.先判断索引对应的目录是否存在,不存在就创建
File indexPathFile = new File(INDEX_PATH);
if (!indexPathFile.exists()) {
indexPathFile.mkdirs();
}
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
objectMapper.writeValue(forwardIndexFile,forwardIndex);
objectMapper.writeValue(invertedIndexFile,invertedIndex);
}catch (IOException e) {
e.printStackTrace();
}
System.out.println("保存索引完成!");
}
6.2.7 实现 load方法
//5.
public void load() {
//反序列化
System.out.println("加载索引开始!");
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {});
invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {});
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("加载索引结束!");
}当然,由于索引中的文件可能会有很多,构造出来的索引数据也是比较大的,那么保存和加载到底会消耗多长时间呢?我们就可以修改一下 load和save方法,来衡量出它们的运行时间:
//4. public void save() { //序列化 long beg = System.currentTimeMillis(); //使用两个文件,分别保存正排和倒排 System.out.println("保存索引开始!"); //1.先判断索引对应的目录是否存在,不存在就创建 File indexPathFile = new File(INDEX_PATH); if (!indexPathFile.exists()) { indexPathFile.mkdirs(); } File forwardIndexFile = new File(INDEX_PATH + "forward.txt"); File invertedIndexFile = new File(INDEX_PATH + "inverted.txt"); try { objectMapper.writeValue(forwardIndexFile,forwardIndex); objectMapper.writeValue(invertedIndexFile,invertedIndex); }catch (IOException e) { e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("保存索引完成!所消耗的时间是:" + ( end - beg ) + "ms"); } //5. public void load() { //反序列化 long beg = System.currentTimeMillis(); System.out.println("加载索引开始!"); File forwardIndexFile = new File(INDEX_PATH + "forward.txt"); File invertedIndexFile = new File(INDEX_PATH + "inverted.txt"); try { forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {}); invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<HashMap<String, ArrayList<Weight>>>() {}); } catch (IOException e) { e.printStackTrace(); } long end = System.currentTimeMillis(); System.out.println("加载索引结束!消耗时间:" + ( end - beg ) + "ms"); }
6.3 在 Parser 中调用 Index
当然,关于 Parser类 和 Index类 之间的关系 我们需要清楚:Parser类 就相当于是 制作索引的入口,通过 Parser类 中的 main方法,就可以把整个流程给跑起来;Index类 就相当于是实现了 索引的数据结构,并且提供了一些API供他人调用~
因此,Index类 需要给 Parser类 调用,才可以完成整个制作索引的过程~
这也是上面的曾经留下了 两个todo 需要做的事情:

6.3.1 新增 Index实例
public class Parser {
......
//创建一个 Index实例
private Index index = new Index();
......
}6.3.2 修改 parseHTML方法
新增 addDoc方法的调用
private void parseHTML(File f) {
//解析 标题
String title = parseTitle(f);
//解析 url
String url = parseUrl(f);
//解析 对应的正文(描述 是正文的一小部分,先解析出来正文,然后才可以获取到 描述)
String content = parseContent(f);
//todo 把解析出来的这些信息,加入到索引当中[新增]
index.addDoc(title,url,content);
}6.3.3 新增save方法的调用
private void run() {
long beg = System.currentTimeMillis();
System.out.println("索引制作开始!");
//整个Parser类的入口
//1、根据上面指定的路径,枚举出该路径中所有的 html文件(包括子目录中的文件)
//2、针对上面罗列出文件的路径,打开文件,读取文件内容,并进行解析,并构建索引
//3、todo 把在内存中构造好的索引数据结构,保存到指定的文件中
long begEnumFile = System.currentTimeMillis();
ArrayList<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH,fileList);
long endEnumFile = System.currentTimeMillis();
System.out.println("枚举文件完毕!消耗时间:" + ( endEnumFile - begEnumFile ) + "ms");
/**
* System.out.println(fileList);
* System.out.println(fileList.size());
*/
long begFor = System.currentTimeMillis();
for (File f:fileList) {
//通过parseHTML()方法解析 .html文件
System.out.println("开始解析:" + f.getAbsolutePath());
parseHTML(f);
}
long endFor = System.currentTimeMillis();
System.out.println("循环遍历文件完毕!消耗时间:" + ( endFor - begFor ) + "ms");
//新增save方法的调用(好吧,其实也新增了一些时间戳)
index.save();
long end = System.currentTimeMillis();
System.out.println("索引制作完毕!消耗时间:" + ( end - beg ) + "ms");
}6.4 验证索引模块
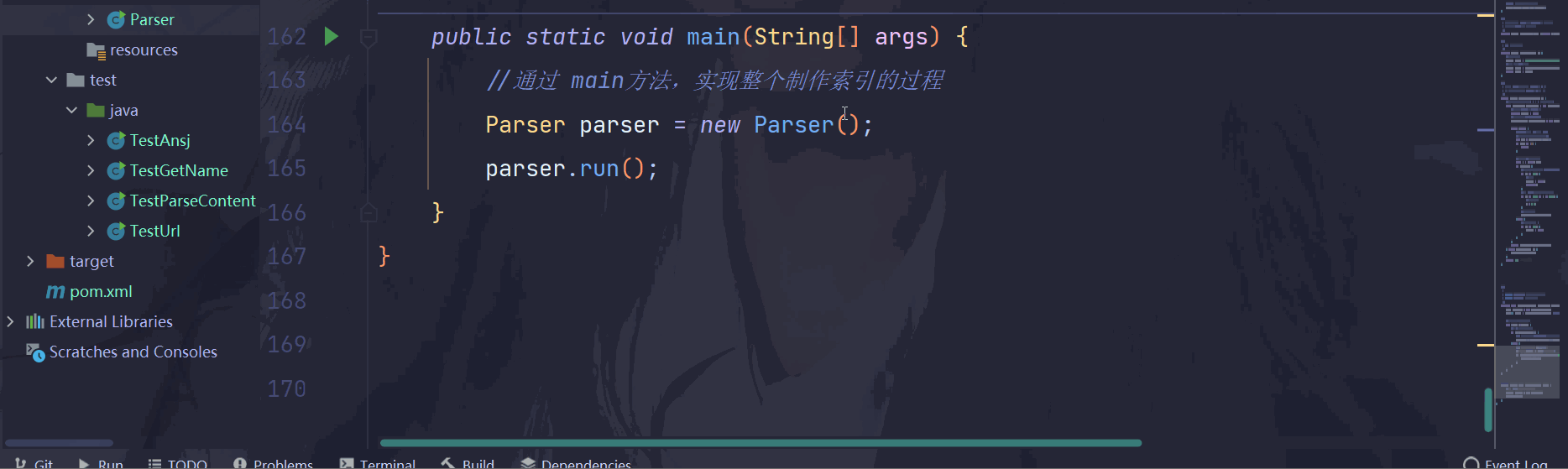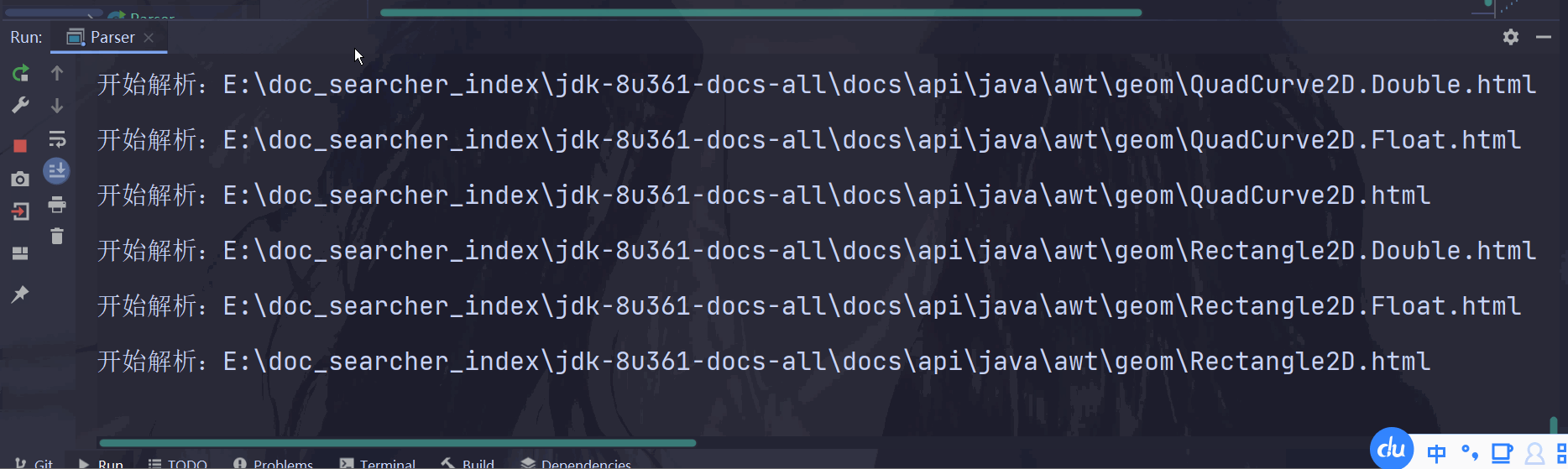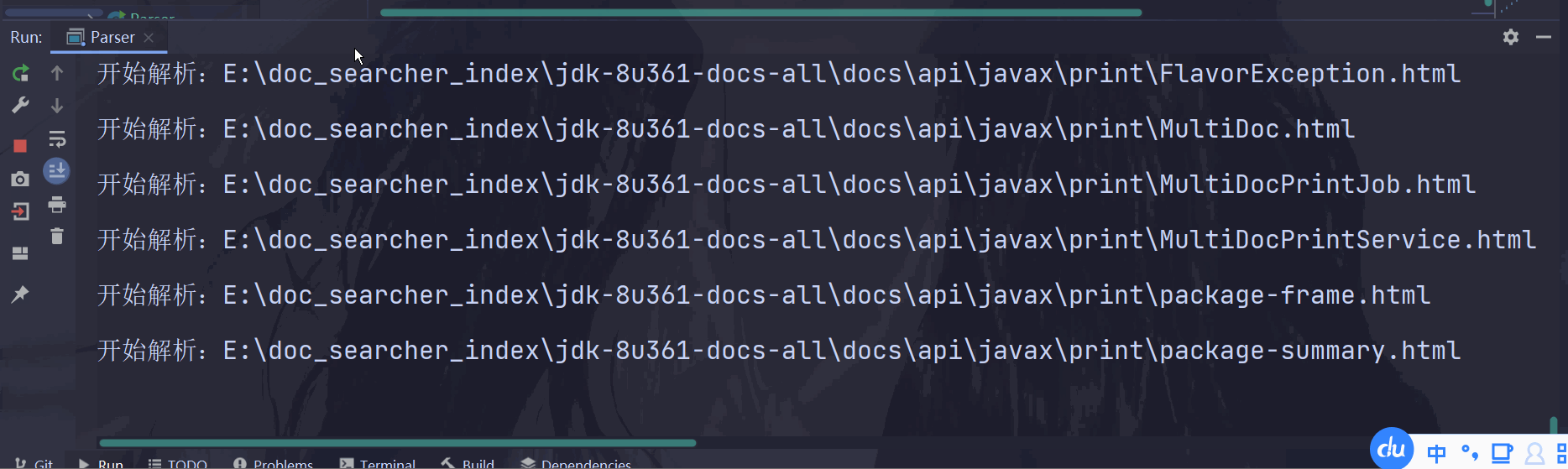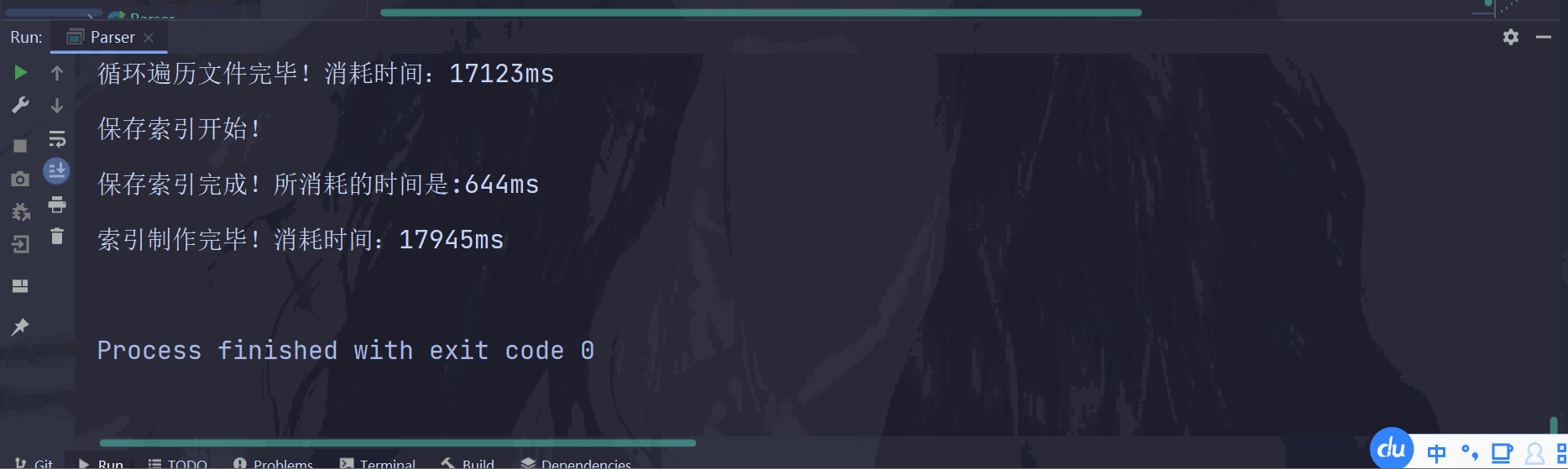
运行Parser类,观察运行结果:



6.5 优化制作索引速度
关于性能优化,首先就需要通过 "测试的手段"(咳咳,通过一些时间戳 知道某一段程序运行所花费的时间),找到其中的 "性能瓶颈"~
通过结果发现,主要花费的时间(性能瓶颈) 就是在循环遍历文件 上面,每次遍历一个 .html文件,都需要进行 读文件+分词+解析内容 等操作(主要就是花费在CPU运算上面)~
在单个线程的情况下,这些任务都是串行执行的;因此,可以引进多线程,并发执行,优化速度(当然,需要通过加锁来完成线程安全)~
//通过这个方法实现多线程制作索引
public void runByThread() throws InterruptedException {
long beg = System.currentTimeMillis();
System.out.println("索引制作开始!");
//1.枚举所有文件
ArrayList<File> files = new ArrayList<>();
enumFile(INPUT_PATH,files);
//2.循环遍历文件(引入线程池)
CountDownLatch latch = new CountDownLatch(files.size());
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (File f:files) {
executorService.submit(new Runnable() {
@Override
public void run() {
System.out.println("解析:" + f.getAbsolutePath());
parseHTML(f);
latch.countDown();
}
});
}
//await方法会阻塞,直到所有选手都调用countDown撞线,才会阻塞结束
latch.await();
executorService.shutdown(); //手动杀死线程池里面的线程
//3.保存索引
index.save();
long end = System.currentTimeMillis();
System.out.println("索引制作完毕(多线程)!消耗时间:" + ( end - beg ) + "ms");
}解决线程安全问题:
//创建两个锁对象
private Object locker1 = new Object();
private Object locker2 = new Object();修改 buildForward方法:
private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo = new DocInfo();
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
synchronized (locker1) {
docInfo.setDocId(forwardIndex.size());
forwardIndex.add(docInfo);
}
return docInfo;
}修改 buildInverted方法:
private void buildInverted(DocInfo docInfo) {
......
for (Map.Entry<String,WordCount> entry : wordCountHashMap.entrySet()) {
//先根据这里的词去倒排索引中查一查
synchronized (locker2) {
......
}
}
}
在调用多线程的方法之后,我们就可以发现 制作索引的速度就快了很多:

一些其他的小问题:
比如说,第一次制作索引的时候,它的制作速度会特别慢,在之后制作索引的时候,速度又会快很多;但把电脑关掉,再一次重启电脑,第一次制作索引的时候又变得慢很多,后面的时候速度又会快很多,这是为什么呢?
分析:在代码中 核心操作还是在 循环遍历上面,循环遍历上面 又调用了 parseHTML方法,parseHTML方法中又调用了 parseContent方法,进行了读取文件的操作~
在计算机读取文件的时候,是一个开销比较大的操作~
我们就可以猜想:是不是开机之后,首次读取文件的时候 速度特别慢呢~
实际上,是因为缓存的问题~
首次运行的时候,由于当前的这些 Java API 文档,没有在内存中进行缓存,因此读取的时候就只能从硬盘上进行读取(这是及其耗时的);后面再运行的时候,由于前面已经读取过文档了,即 在操作系统中其实已经有了一个缓存(在内存中),所以这次读取的就不是直接读硬盘,而是直接读内存的缓存(速度就会快很多)~
当然,这也是可以进行优化的~
BufferedReader 和 FileReader 搭配着来使用,BufferedReader 内部会内置一个缓冲区,就可以自动的把 FileReader 中的一些内容预读到内存中,从而减少直接访问磁盘的次数~
虽然说,后面的运行程序 的时候操作系统已经做了缓存,此时运行速度也提高不了太多,但也好歹是优化了一点点~
七、实现搜索模块
搜索模块 主要是调用 索引模块,来完成搜索的核心过程!!!!!!
其中是可以包括:
- 分词:针对用户输入的查询词,进行分词
- 触发:拿着每一个分词结果,去倒排索引当中找出具有相关性的文章(调用 Index类 里面查倒排的方法即可)
- 排序:根据上面所触发出来的结果,根据相关性降序进行排序
- 包装结果:根据排序后的结果,依次去查正排,获取到每个文档的详细信息,包装成一定结构的数据返回出去
7.1 创建 DocSearcher类
import java.util.List;
//通过这个类 来完成整个搜索模块的过程
public class DocSearcher {
//此处需要加上索引对象的实例,同时需要完成索引加载的工作
private Index index = new Index();
public DocSearcher() {
index.load();
}
/**
* 完成整个搜索过程的方法
* @param query 查询词
* @return 搜索结果的集合
*/
public List<Result> searcher(String query) {
//1.分词
//2.触发
//3.排序
//4.包装结果
return null;
}
}
7.1.1 创建 Result类
//这个类来表示一个搜索结果
public class Result {
private String title;
private String url;
private String desc; //描述(正文的一段摘要)
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
@Override
public String toString() {
return "Result{" +
"title='" + title + '\'' +
", url='" + url + '\'' +
", desc='" + desc + '\'' +
'}';
}
}
7.1.2 实现 search方法
//通过这个类 来完成整个搜索模块的过程
public class DocSearcher {
//此处需要加上索引对象的实例,同时需要完成索引加载的工作
private Index index = new Index();
public DocSearcher() {
index.load();
}
/**
* 完成整个搜索过程的方法
* @param query 查询词
* @return 搜索结果的集合
*/
public List<Result> searcher(String query) {
//1.分词
List<Term> terms = ToAnalysis.parse(query).getTerms();
//2.触发(/针对分词结果进行倒排查找)
List<Weight> allTermResult = new ArrayList<>();
for (Term term:terms) {
String word = term.getName();
List<Weight> invertedList = index.getInverted(word);
if (invertedList == null) {
//说明这个词在所有文档中不存在
continue;
}
allTermResult.addAll(invertedList);
}
//3.排序
allTermResult.sort(new Comparator<Weight>() {
@Override
public int compare(Weight o1, Weight o2) {
//如果是升序排序:return o1.getWeight() - o2.getWeight()
//如果是降序排序:return o2.getWeight() - o1.getWeight()
return o2.getWeight() - o1.getWeight();
}
});
//4.包装结果
List<Result> results = new ArrayList<>();
for (Weight weight:allTermResult) {
DocInfo docInfo = index.getDocInfo(weight.getDocId());
Result result = new Result();
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
result.setDesc(GenDesc(docInfo.getContent(),terms)); //描述
results.add(result);
}
return results;
}
//生成描述信息
private String GenDesc(String content, List<Term> terms) {
//先遍历分词结果,看看结果是否在 content 中存在
//正文需要先转成小写(重要)
int firstPos = -1;
for (Term term:terms) {
String word = term.getName();
firstPos = content.toLowerCase().indexOf( " " + word + " ");
if (firstPos >= 0) {
//找到了位置
break;
}
}
if (firstPos == -1) {
//所有的分词结果不在正文中存在
//取正文的前 160 个字符作为描述
return content.substring(0,160) + "...";
}
//从 firstPos 作为基准位置,往前找60个字符,往后找100个字符
String desc = " ";
int descBeg = firstPos < 60 ? 0 : firstPos-60;
if (descBeg + 160 > content.length()) {
//descBeg 位置很靠后面了
desc = content.substring(descBeg);
} else {
desc = content.substring(descBeg,descBeg+160) + "...";
}
return desc;
}
}
在包装结果生成描述的时候,需要注意的是:
- 前面使用第三方库分词的结果 都是小写形式的,所以不可以直接对着内容进行比较,需要先转换成小写才可以
- 其实需要根据实际的情况,类似于 买了一份"老婆饼",并不可以送一个"老婆",我们搜索的时候,不能把两个单词由于差不多,就归结于相关性较强,所以在查找单词的时候,可以在前面和后面加上 " ",虽然可能会查询不到在最前面或者最后面,但这毕竟还是少数情况(当然,也可以使用正则表达式去解决这个问题)
7.1.3 验证 DocSearcher类
验证 DocSearcher类
public static void main(String[] args) {
DocSearcher docSearcher = new DocSearcher();
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.print("-> ");
String query = scanner.next();
List<Result> results = docSearcher.searcher(query);
for (Result result : results) {
System.out.println("====================================");
System.out.println(result);
}
}
}
我们观察结果可以发现,在有的查询结果中出现了下面的内容:

其实,这个内容就是 JavaScript 的代码,由于在处理文档的时候,只是针对正文 进行了 "去标签",而有的 HTML 里面包含了 script标签,就导致了在去标签过后,JS的代码也被整理到索引里面了,所以查的时候就出现了这个情况~
而这种情况并不科学,因此还需要在后面去掉(可以使用正则表达式)~
7.1.4 修改 Parser类
修改 Parser类(换成使用正则表达式来解决):
/**
* 通过这个方法内部基于正则表达式,实现去除标签,以及 script的效果
*/
public String parseContentByRegex(File f) {
//1.先把这个文件都读到 String 里面
String content = readFile(f);
//2.替换script标签
content = content.replaceAll("<script.*?>(.*?)</script>"," ");
//3.替换普通的 .html标签
content = content.replaceAll("<.*?>"," ");
return content;
}
private String readFile(File f) {
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(f))) {
StringBuilder content = new StringBuilder();
while (true) {
int ret = bufferedReader.read();
if (ret == -1) {
//读完了
break;
}
char c = (char) ret;
if (c == '\n' || c == '\r') {
c = ' ';
}
content.append(c);
}
return content.toString();
}catch (IOException e) {
e.printStackTrace();
}
return "";
}此时,就可以验证一下效果如何:


可是,新的看起来也不是很好看(原因是因为空格太多了),我们就可以把多个空格合并成一个即可(同样是使用正则表达式):
//4.使用正则表达式,把多个空格合并成一个空格
content = content.replaceAll("\\s+"," ");
所以在解析正文的时候,就可以使用正则的方式了~
八、实现Web模块
此时,搜索的核心功能都已经实现出来了,但是此时仍然需要提供一个Web接口,以网页的形式,把程序呈现给用户~
因为 此时的效果只能是在控制台中进行操作,此时对于普通用户来说 并不友好,此时如果想真正的搜索引擎一样,有一个搜索框,有一个搜索按钮......想必这样的界面对于用户来说更加的友好~
要想实现这样的Web模块,需要约定一下前后端通信的接口,需要明确的描述出,服务器都能接受什么样的请求 ,都能返回什么样的响应的~
前端(HTML+CSS+JS)+ 后端(Java + Servlet/Spring相关)~
针对于这个项目,我们只需要实现一个 搜索接口 即可~
//约定 //请求: GET/searcher?query=[查询词] HTTP/1.1 //响应: HTTP/1.1 [ { title:"这是标题1", url:"这是描述1", desc:"这是描述1" } ]
如果是使用 Servlet 来实现后端的接口的话,第一步需要引入相关的依赖的jar包~
<!-- 引入 Servlet依赖 -->
<!-- https://mvnrepository.com/artifact/javax.servlet/javax.servlet-api -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>创建 DocSearchServlet类,基于Servlet来实现后端
//指定当前的路径 和哪个Servlet类对应
@WebServlet("/searcher")
public class DocSearchServlet extends HttpServlet {
//引入 DocSearcher实例,调用 searcher方法
private static DocSearcher docSearcher = new DocSearcher();
private ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//1.先解析请求,拿到用户所提交的查询词
String query = req.getParameter("query");
if (query == null || query.equals(" ")) {
//用户的参数是不科学的,一个没有key,一个有key没有value
String msg = "您的参数非法!没有获得query的值";
System.out.println(msg);
System.out.println();
resp.sendError(404,msg);
return;
}
//2.打印 记录 query的值
System.out.println("query=" + query);
//3.调用搜索模块,来进行一下搜索
List<Result> results = docSearcher.searcher(query);
//4.把当前的搜索结果进行打包
resp.setContentType("application/json;charset=utf-8");
objectMapper.writeValue(resp.getWriter(),results);
}
}
嗯,最后剩下的就是实现前端页面的部分了,关于这一部分内容,就不细细展开了~

而如果是使用 Spring Boot 来实现后端接口的话,那么可以这样做:
在 controller包下面,创建 DocSearcherController 类:
@RestController
public class DocSearcherController {
private static DocSearcher = new DocSearcher();
private ObjectMapper objectMapper = new ObjectMapper();
@RequestMapping("/searcher")
public String search(@RequestParam("query") String query) throws JsonProcessingException {
//参数是查询词,返回值是响应内容
//参数来自于请求query string中的query这个key的值
List<Result> results = searcher.search(query);
return objectMapper.writeValueAsString(results);
}
}
对了,由于在运行的时候,路径会发生错误,因为有两条路径:一条是云服务器上的路径,一条是本地路径~
那么想要在哪里运行的话,就需要去运行哪条路径~
所以,想要更加方便的运行,可以制作一个开关来切换路径~
虽然说在实际开发中不是这样子的,但是这个却是一个更加简单粗暴的方法:
//创建一个Config类
public class Config {
// 这个变量为 true,表示在云服务器上运行,为 false,表示在本地运行
public static boolean isOnline = false;
}//Index类底下
public class Index {
private static String INDEX_PATH = null;
static {
if (Config.isOnline) {
INDEX_PATH = "/root/java/doc_searcher_index/";
}else {
INDEX_PATH = "E:\\doc_searcher_index\\";
}
}
......
}//DocSearcher类底下
public class DocSearcher {
//停用词表的路径
private static String STOP_WORD_PATH = null;
static {
if (Config.isOnline) {
STOP_WORD_PATH = "/root/java/doc_searcher_index/stop_word.txt";
}else {
STOP_WORD_PATH = "E:\\doc_searcher_index\\stop_word.txt";
}
}
......
}