大家好呀,全国研究生数学建模竞赛今天早上开赛啦,在这里先带来初步的选题建议及思路。
目前团队正在写E题完整论文,此外C已经完成了第一问代码及结果,本文章只是一个比较粗略的文字版思路,更加详细的半小时视频讲解版移步:
【数模研赛思路】2023华为杯研究生数学建模竞赛选题建议及CDEF题思路_哔哩哔哩_bilibili
首先是主基调:
本次研赛推荐小白选择E题,典型的数据分析类题目,内容会比较丰富,求解方法也比较确定。AB太硬核难度过大,C本质上是优化类题目,第一问还好,后面几问较难。D是评价类题目,难度介于ce之间,但做起来需要了解每个指标具体含义,较繁琐。F数据量过大,只推荐有大数据处理能力的队伍选择。
本次我会写E完整论文,预计23号中午更新,C目前完成了第一问代码及结果。
接下来开始具体讲解:
C题 大规模创新类竞赛评审方案研究
问题一
在每个评审阶段,作品通常都是随机分发的,每份作品需要多位评委独立评审。为了增加不同评审专家所给成绩之间的可比性,不同专家评审的作品集合之间应有一些交集。但有的交集大了,则必然有交集小了,则可比性变弱。请针对3000支参赛队和125位评审专家,每份作品由5位专家评审的情况,建立数学模型确定最优的“交叉分发”方案,并讨论该方案的有关指标(自己定义)和实施细节。
问题一主要是要求我们给出一个方案,尽量增加不同专家给出成绩的可比性。这里我们确定思路:
- 参赛队伍数量:3000
- 评审专家数量:125
- 每份作品的评审专家数:5
目标:
- 最大化不同专家之间的可比性。
- 确保每个评审专家得到的作品数量基本相等。
- 确保每份作品都由5位专家评审。
建立约束条件之后,我们可以通过matlab代码进行实际求解:
部分代码:
num_teams = 3000;
num_judges = 125;
judges_per_team = 5;
max_iterations = 10000;
% 初始化分配矩阵
assignment = zeros(num_teams, num_judges);
for i = 1:num_teams
judges_for_team = randperm(num_judges, judges_per_team);
assignment(i, judges_for_team) = 1;
end
% 调整分配,使每对评审专家至少有一个共同的团队
iteration = 0;
while iteration < max_
最终结果展示:

问题二
这里我们可以考虑下面的因素:
考虑权重系统:对于那些在多个评审中都获得高分的作品,为它们赋予更大的权重,这可能会更公平地评价作品的质量。
然后重新设计标准分计算方案,重点是我们需要根据二次评审的结果进行测试方案优劣。
具体求解等我更新。。。。
D题 区域双碳目标与路径规划研究
这道题题目本身思路不难,但在指标选取以及各个指标的相互关系上,我们需要深刻理解每个指标的实际现实意义,以及需要认真研读题目给出的指标文字说明。
问题一:
区域碳排放量以及经济、人口、能源消费量的现状分析
指标体系搭建没什么好说的,比较简单。
对于要求1:以2010年为基期,分析某区域十二五(2011-2015年)和十三五(2016-2020年)期间的碳排放量状况(如总量、变化趋势等);
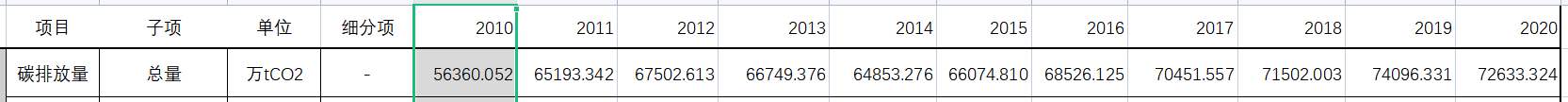
比较简单,计算变化量后绘制趋势图就行。
分析对该区域碳排放量产生影响的各因素及其贡献;
用第一问的指标体系进行预测排放量,这里用基于决策树的机器学习预测即可,比如随机森林,gbdt。我们要的不是预测结果,而是预测过程中我们可以得到各个指标的权重值。这些权重值就是贡献度。
(3)区域碳排放量以及经济、人口、能源消费量各指标及其关联模型
要求1:分析相关指标的变化(环比与同比);要求2:建立各项指标间的关联关系模型;要求3:基于相关指标的变化,结合双碳政策与技术进步等多重效应,确定碳排放预测模型参数(如能源利用效率提升和非化石能源消费比重等)取值。
计算环比同比这些不用多说,各个指标之间的关联模型直接采用相关性分析即可,之后,我们是需要去建立碳排放量,但大家要注意的是,在预测模型中,我们不能简单地一股脑把所有指标数据作为自变量扔进机器学习模型中,该预测模型中,我们要采用的参数是能源利用效率以及非化石能源消费比重这些,这些我们都是需要计算得出的,根据题目后面的参数介绍来。
至于后面的问题二问题三,基本也都是机器学习模型,等我更新吧。。。。
E题 出血性脑卒中临床智能诊疗建模
本题E题是典型的数据分析类题目,求解思路比较确定,内容也很丰富,我会优先更新这道题的完整论文哈。
问题一
a) 请根据“表1”(字段:入院首次影像检查流水号,发病到首次影像检查时间间隔),“表2”(字段:各时间点流水号及对应的HM_volume),判断患者sub001至sub100发病后48小时内是否发生血肿扩张事件。
结果填写规范:1是0否,填写位置:“表4”C字段(是否发生血肿扩张)。如发生血肿扩张事件,请同时记录血肿扩张发生时间。结果填写规范:如10.33小时,填写位置:“表4”D字段(血肿扩张时间)。
首先是计算发病到检测时间,注意,题目给出的表一中,给出的是发病到首次检测时间:

题目要求判断是否l血肿扩张,是后续检查比首次检查绝对体积增加≥6 mL或相对体积增加≥33%。
那么后续检查时间是什么?

这个时间点对应的体积为:

所以,用这些时间点对应的体积量相减计算得出是否血肿扩张即可,但必须要注意的是,距离发病不能超过48小时。所以两次检测时间相减之后,需要加上前面的那个时间间隔看有没有超出48.
a) 请以是否发生血肿扩张事件为目标变量,基于“表1” 前100例患者(sub001至sub100)的个人史,疾病史,发病相关(字段E至W)、“表2”中其影像检查结果(字段C至X)及“表3”其影像检查结果(字段C至AG,注:只可包含对应患者首次影像检查记录)等变量,构建模型预测所有患者(sub001至sub160)发生血肿扩张的概率。
把题目说的这些因素数据全部扔进去,以我们前面得出的是否发生血肿,做0/1的二分类机器学习预测就行,比较无脑。
第二问:
血肿周围水肿的发生及进展建模,并探索治疗干预和水肿进展的关联关系。
a) 请根据“表2”前100个患者(sub001至sub100)的水肿体积(ED_volume)和重复检查时间点,构建 一条全体患者水肿体积随时间进展曲线(x轴:发病至影像检查时间,y轴:水肿体积,y=f(x)),计算前100个患者(sub001至sub100)真实值和所拟合曲线之间存在的残差。
把所有人的曲线都绘制进去,然后拟合算残差,不难但是有点繁琐而已。
a) 请探索患者水肿体积随时间进展模式的个体差异,构建不同人群(分亚组:3-5个)的水肿体积随时间进展曲线,并计算前100个患者(sub001至sub100)真实值和曲线间的残差。
先肉眼看曲线图是否存在显著差异,如果真的差异很大,可以手动分类。否则就聚类分析分成三到五类也可以。然后分组重新绘图并计算残差。
a) 请分析不同治疗方法(“表1”字段Q至W)对水肿体积进展模式的影响。
做差异性分析就行,看一下不同治疗方法之间是否存在显著差异。
a) 请分析血肿体积、水肿体积及治疗方法(“表1”字段Q至W)三者之间的关系。
相关性分析即可。
问题三:
a) 请根据前100个患者(sub001至sub100)个人史、疾病史、发病相关(“表1”字段E至W)及首次影像结果(表2,表3中相关字段)构建预测模型,预测患者(sub001至sub160)90天mRS评分。
比较无脑的机器学习,7分类的分类预测。后面两问也就是这样的思路。
总体而言,e题还是比较简单,推荐小白去选择。
F题 强对流降水临近预报
怎么说呢,题目本身是个机器学习预测的无脑题目,但是这个数据量吧。。。:

解压之后70多个gb,然后里面的数据整合这些非常麻烦,总之,没有大数据处理经验的队伍慎选。
OK以上只是比较简略的图文版讲解,团队目前完成了C第一问的完整代码和结果,此外正在写E题完整论文,E题完整论文预定以及C题第一问代码结果请点击我的下方个人卡片查看喽↓: