大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型19-手把手利用pytorch框架搭建目标检测DarkNet模型,并展现网络结构。随着深度学习技术的不断发展,各种卷积神经网络模型层出不穷,其中DarkNet作为一种快速、精准的目标检测模型,在计算机视觉领域得到了广泛的应用。本文将详细介绍DarkNet模型架构与原理,并通过实例训练演示其在目标检测任务中的应用。
一、DarkNet模型架构与原理
1.1 DarkNet简介
DarkNet是一个开源神经网络框架,由Joseph Redmon创建,它是在C和CUDA中实现的,并支持CPU和GPU计算。这个框架非常轻量级且易于使用。
1.2 DarkNet模型架构
在深度学习领域,我们通常会遇到“Darknet”这个词。这里所说的“Darknet”,其实是指Yolo系列目标检测算法所使用的神经网络结构——也就是我们今天要讲述的“Darknet”。
本文将介绍Darknet53模型,它是一个深度卷积神经网络模型,用于图像识别和目标检测任务。它是YOLO物体检测算法中的基础网络结构。它是YOLOV3之后开始使用的主干特征提取网络。
Darknet53网络模型采用了53个卷积层,没有使用池化层来降低特征图的尺寸,而是使用步幅为2的卷积操作来实现特征图的下采样。这种设计能够更好地保留图像中的细节信息,并且有效地减少了参数量,提高了计算效率。
Darknet53模型的输入是一张原始图像,经过一系列的卷积、批归一化和激活函数操作,逐渐提取出图像的抽象特征。其中,主要使用了3×3和1×1的卷积核,以及LeakyReLU激活函数来增加非线性。网络最后输出一个特征图,其通道数对应着不同尺度上的目标检测结果。
Darknet53模型具有较好的感受野,可以捕捉到不同尺度和层次的图像特征。通过将Darknet53与目标检测头部结合,可以实现对图像中多个目标的准确检测和定位。
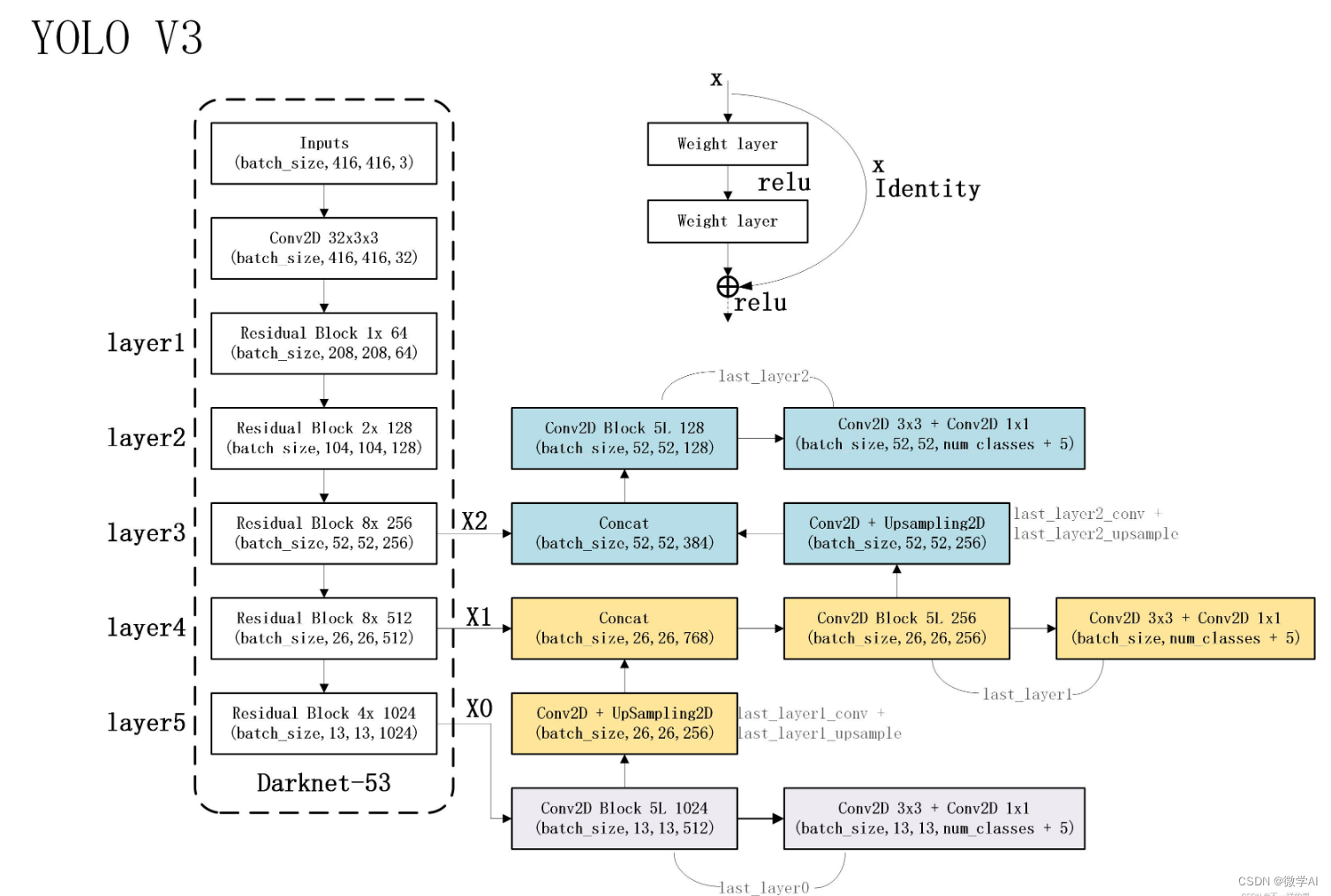
1.3 DarkNet工作原理
对于传入图像,首先通过多个卷积层和池化层提取特征信息。然后将提取到的特征信息传递给全连接层进行分类或回归操作。最后,在输出层得出预测结果。
二、应用背景: 目标检测任务
随着深度学习技术在各行业中越来越广泛地被采用, 目标检测已成为计算机视觉领域一个重要研究方向, 广泛应用于无人驾驶、安防监控等领域。
三、代码实践: 使用PyTorch训练并测试Darknet53
以下示例将基于PyTorch框架演示如何使用csv图片数据样例进行目标检测任务,训练DarkNet53模型,并打印损失值与准确率。
3.1 数据准备
首先,我们需要准备csv格式的图片数据样例。假设我们已经有了一个包含多个csv文件的目录,每个csv文件都包含了一组图片地址的数据。
import pandas as pd
# 读取CSV文件
data = pd.read_csv("my_csv")
3.2 模型定义
下面我来定义DarkNet模型。这里使用PyTorch框架实现:
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
class SE(nn.Module):
def __init__(self, in_chnls, ratio):
super(SE, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
self.compress = nn.Conv2d(in_chnls, in_chnls // ratio, 1, 1, 0)
self.excitation = nn.Conv2d(in_chnls // ratio, in_chnls, 1, 1, 0)
def forward(self, x):
out = self.squeeze(x)
out = self.compress(out)
out = F.relu(out)
out = self.excitation(out)
return x*F.sigmoid(out)
class BN_Conv2d(nn.Module):
def __init__(self, in_channels: object, out_channels: object, kernel_size: object, stride: object, padding: object,
dilation=1, groups=1, bias=False, activation=nn.ReLU(inplace=True)) -> object:
super(BN_Conv2d, self).__init__()
layers = [nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=bias),
nn.BatchNorm2d(out_channels)]
if activation is not None:
layers.append(activation)
self.seq = nn.Sequential(*layers)
def forward(self, x):
return self.seq(x)
class BN_Conv2d_Leaky(nn.Module):
def __init__(self, in_channels: object, out_channels: object, kernel_size: object, stride: object, padding: object,
dilation=1, groups=1, bias=False) -> object:
super(BN_Conv2d_Leaky, self).__init__()
self.seq = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=bias),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
return F.leaky_relu(self.seq(x))
class Dark_block(nn.Module):
"""block for darknet"""
def __init__(self, channels, is_se=False, inner_channels=None):
super(Dark_block, self).__init__()
self.is_se = is_se
if inner_channels is None:
inner_channels = channels // 2
self.conv1 = BN_Conv2d_Leaky(channels, inner_channels, 1, 1, 0)
self.conv2 = nn.Conv2d(inner_channels, channels, 3, 1, 1)
self.bn = nn.BatchNorm2d(channels)
if self.is_se:
self.se = SE(channels, 16)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.bn(out)
if self.is_se:
coefficient = self.se(out)
out *= coefficient
out += x
return F.leaky_relu(out)
class DarkNet(nn.Module):
def __init__(self, layers: object, num_classes, is_se=False) -> object:
super(DarkNet, self).__init__()
self.is_se = is_se
filters = [64, 128, 256, 512, 1024]
self.conv1 = BN_Conv2d(3, 32, 3, 1, 1)
self.redu1 = BN_Conv2d(32, 64, 3, 2, 1)
self.conv2 = self.__make_layers(filters[0], layers[0])
self.redu2 = BN_Conv2d(filters[0], filters[1], 3, 2, 1)
self.conv3 = self.__make_layers(filters[1], layers[1])
self.redu3 = BN_Conv2d(filters[1], filters[2], 3, 2, 1)
self.conv4 = self.__make_layers(filters[2], layers[2])
self.redu4 = BN_Conv2d(filters[2], filters[3], 3, 2, 1)
self.conv5 = self.__make_layers(filters[3], layers[3])
self.redu5 = BN_Conv2d(filters[3], filters[4], 3, 2, 1)
self.conv6 = self.__make_layers(filters[4], layers[4])
self.global_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(filters[4], num_classes)
def __make_layers(self, num_filter, num_layers):
layers = []
for _ in range(num_layers):
layers.append(Dark_block(num_filter, self.is_se))
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.redu1(out)
out = self.conv2(out)
out = self.redu2(out)
out = self.conv3(out)
out = self.redu3(out)
out = self.conv4(out)
out = self.redu4(out)
out = self.conv5(out)
out = self.redu5(out)
out = self.conv6(out)
out = self.global_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
# return F.softmax(out)
return out
def darknet_53(num_classes=1000):
return DarkNet([1, 2, 8, 8, 4], num_classes)
def test():
net = darknet_53()
summary(net, (3, 256, 256))
test()
3.3 训练模型
定义完模型之后,我们就可以开始训练了:
# 实例化模型并设置为训练模式
model = darknet_53()
model.train()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
# 开始训练循环
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
inputs, labels = data
# 前向传播
outputs = model(inputs)
# 计算损失值
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch [%d/%d], Loss: %.4f' %(epoch+1, num_epochs, loss.item()))
3.4 模型结构展示
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 256, 256] 864
BatchNorm2d-2 [-1, 32, 256, 256] 64
ReLU-3 [-1, 32, 256, 256] 0
ReLU-4 [-1, 32, 256, 256] 0
ReLU-5 [-1, 32, 256, 256] 0
ReLU-6 [-1, 32, 256, 256] 0
ReLU-7 [-1, 32, 256, 256] 0
ReLU-8 [-1, 32, 256, 256] 0
BN_Conv2d-9 [-1, 32, 256, 256] 0
Conv2d-10 [-1, 64, 128, 128] 18,432
BatchNorm2d-11 [-1, 64, 128, 128] 128
ReLU-12 [-1, 64, 128, 128] 0
ReLU-13 [-1, 64, 128, 128] 0
ReLU-14 [-1, 64, 128, 128] 0
ReLU-15 [-1, 64, 128, 128] 0
ReLU-16 [-1, 64, 128, 128] 0
ReLU-17 [-1, 64, 128, 128] 0
BN_Conv2d-18 [-1, 64, 128, 128] 0
Conv2d-19 [-1, 32, 128, 128] 2,048
BatchNorm2d-20 [-1, 32, 128, 128] 64
BN_Conv2d_Leaky-21 [-1, 32, 128, 128] 0
Conv2d-22 [-1, 64, 128, 128] 18,496
BatchNorm2d-23 [-1, 64, 128, 128] 128
Dark_block-24 [-1, 64, 128, 128] 0
Conv2d-25 [-1, 128, 64, 64] 73,728
BatchNorm2d-26 [-1, 128, 64, 64] 256
ReLU-27 [-1, 128, 64, 64] 0
ReLU-28 [-1, 128, 64, 64] 0
ReLU-29 [-1, 128, 64, 64] 0
ReLU-30 [-1, 128, 64, 64] 0
ReLU-31 [-1, 128, 64, 64] 0
ReLU-32 [-1, 128, 64, 64] 0
BN_Conv2d-33 [-1, 128, 64, 64] 0
Conv2d-34 [-1, 64, 64, 64] 8,192
BatchNorm2d-35 [-1, 64, 64, 64] 128
BN_Conv2d_Leaky-36 [-1, 64, 64, 64] 0
Conv2d-37 [-1, 128, 64, 64] 73,856
BatchNorm2d-38 [-1, 128, 64, 64] 256
Dark_block-39 [-1, 128, 64, 64] 0
Conv2d-40 [-1, 64, 64, 64] 8,192
BatchNorm2d-41 [-1, 64, 64, 64] 128
BN_Conv2d_Leaky-42 [-1, 64, 64, 64] 0
Conv2d-43 [-1, 128, 64, 64] 73,856
BatchNorm2d-44 [-1, 128, 64, 64] 256
Dark_block-45 [-1, 128, 64, 64] 0
Conv2d-46 [-1, 256, 32, 32] 294,912
BatchNorm2d-47 [-1, 256, 32, 32] 512
ReLU-48 [-1, 256, 32, 32] 0
ReLU-49 [-1, 256, 32, 32] 0
ReLU-50 [-1, 256, 32, 32] 0
ReLU-51 [-1, 256, 32, 32] 0
ReLU-52 [-1, 256, 32, 32] 0
ReLU-53 [-1, 256, 32, 32] 0
BN_Conv2d-54 [-1, 256, 32, 32] 0
Conv2d-55 [-1, 128, 32, 32] 32,768
BatchNorm2d-56 [-1, 128, 32, 32] 256
BN_Conv2d_Leaky-57 [-1, 128, 32, 32] 0
Conv2d-58 [-1, 256, 32, 32] 295,168
BatchNorm2d-59 [-1, 256, 32, 32] 512
Dark_block-60 [-1, 256, 32, 32] 0
Conv2d-61 [-1, 128, 32, 32] 32,768
BatchNorm2d-62 [-1, 128, 32, 32] 256
BN_Conv2d_Leaky-63 [-1, 128, 32, 32] 0
Conv2d-64 [-1, 256, 32, 32] 295,168
BatchNorm2d-65 [-1, 256, 32, 32] 512
Dark_block-66 [-1, 256, 32, 32] 0
Conv2d-67 [-1, 128, 32, 32] 32,768
BatchNorm2d-68 [-1, 128, 32, 32] 256
BN_Conv2d_Leaky-69 [-1, 128, 32, 32] 0
Conv2d-70 [-1, 256, 32, 32] 295,168
BatchNorm2d-71 [-1, 256, 32, 32] 512
Dark_block-72 [-1, 256, 32, 32] 0
Conv2d-73 [-1, 128, 32, 32] 32,768
BatchNorm2d-74 [-1, 128, 32, 32] 256
BN_Conv2d_Leaky-75 [-1, 128, 32, 32] 0
Conv2d-76 [-1, 256, 32, 32] 295,168
BatchNorm2d-77 [-1, 256, 32, 32] 512
Dark_block-78 [-1, 256, 32, 32] 0
Conv2d-79 [-1, 128, 32, 32] 32,768
BatchNorm2d-80 [-1, 128, 32, 32] 256
BN_Conv2d_Leaky-81 [-1, 128, 32, 32] 0
Conv2d-82 [-1, 256, 32, 32] 295,168
BatchNorm2d-83 [-1, 256, 32, 32] 512
Dark_block-84 [-1, 256, 32, 32] 0
Conv2d-85 [-1, 128, 32, 32] 32,768
BatchNorm2d-86 [-1, 128, 32, 32] 256
BN_Conv2d_Leaky-87 [-1, 128, 32, 32] 0
Conv2d-88 [-1, 256, 32, 32] 295,168
BatchNorm2d-89 [-1, 256, 32, 32] 512
Dark_block-90 [-1, 256, 32, 32] 0
Conv2d-91 [-1, 128, 32, 32] 32,768
BatchNorm2d-92 [-1, 128, 32, 32] 256
BN_Conv2d_Leaky-93 [-1, 128, 32, 32] 0
Conv2d-94 [-1, 256, 32, 32] 295,168
BatchNorm2d-95 [-1, 256, 32, 32] 512
Dark_block-96 [-1, 256, 32, 32] 0
Conv2d-97 [-1, 128, 32, 32] 32,768
BatchNorm2d-98 [-1, 128, 32, 32] 256
BN_Conv2d_Leaky-99 [-1, 128, 32, 32] 0
Conv2d-100 [-1, 256, 32, 32] 295,168
BatchNorm2d-101 [-1, 256, 32, 32] 512
Dark_block-102 [-1, 256, 32, 32] 0
Conv2d-103 [-1, 512, 16, 16] 1,179,648
BatchNorm2d-104 [-1, 512, 16, 16] 1,024
ReLU-105 [-1, 512, 16, 16] 0
ReLU-106 [-1, 512, 16, 16] 0
ReLU-107 [-1, 512, 16, 16] 0
ReLU-108 [-1, 512, 16, 16] 0
ReLU-109 [-1, 512, 16, 16] 0
ReLU-110 [-1, 512, 16, 16] 0
BN_Conv2d-111 [-1, 512, 16, 16] 0
Conv2d-112 [-1, 256, 16, 16] 131,072
BatchNorm2d-113 [-1, 256, 16, 16] 512
BN_Conv2d_Leaky-114 [-1, 256, 16, 16] 0
Conv2d-115 [-1, 512, 16, 16] 1,180,160
BatchNorm2d-116 [-1, 512, 16, 16] 1,024
Dark_block-117 [-1, 512, 16, 16] 0
Conv2d-118 [-1, 256, 16, 16] 131,072
BatchNorm2d-119 [-1, 256, 16, 16] 512
BN_Conv2d_Leaky-120 [-1, 256, 16, 16] 0
Conv2d-121 [-1, 512, 16, 16] 1,180,160
BatchNorm2d-122 [-1, 512, 16, 16] 1,024
Dark_block-123 [-1, 512, 16, 16] 0
Conv2d-124 [-1, 256, 16, 16] 131,072
BatchNorm2d-125 [-1, 256, 16, 16] 512
BN_Conv2d_Leaky-126 [-1, 256, 16, 16] 0
Conv2d-127 [-1, 512, 16, 16] 1,180,160
BatchNorm2d-128 [-1, 512, 16, 16] 1,024
Dark_block-129 [-1, 512, 16, 16] 0
Conv2d-130 [-1, 256, 16, 16] 131,072
BatchNorm2d-131 [-1, 256, 16, 16] 512
BN_Conv2d_Leaky-132 [-1, 256, 16, 16] 0
Conv2d-133 [-1, 512, 16, 16] 1,180,160
BatchNorm2d-134 [-1, 512, 16, 16] 1,024
Dark_block-135 [-1, 512, 16, 16] 0
Conv2d-136 [-1, 256, 16, 16] 131,072
BatchNorm2d-137 [-1, 256, 16, 16] 512
BN_Conv2d_Leaky-138 [-1, 256, 16, 16] 0
Conv2d-139 [-1, 512, 16, 16] 1,180,160
BatchNorm2d-140 [-1, 512, 16, 16] 1,024
Dark_block-141 [-1, 512, 16, 16] 0
Conv2d-142 [-1, 256, 16, 16] 131,072
BatchNorm2d-143 [-1, 256, 16, 16] 512
BN_Conv2d_Leaky-144 [-1, 256, 16, 16] 0
Conv2d-145 [-1, 512, 16, 16] 1,180,160
BatchNorm2d-146 [-1, 512, 16, 16] 1,024
Dark_block-147 [-1, 512, 16, 16] 0
Conv2d-148 [-1, 256, 16, 16] 131,072
BatchNorm2d-149 [-1, 256, 16, 16] 512
BN_Conv2d_Leaky-150 [-1, 256, 16, 16] 0
Conv2d-151 [-1, 512, 16, 16] 1,180,160
BatchNorm2d-152 [-1, 512, 16, 16] 1,024
Dark_block-153 [-1, 512, 16, 16] 0
Conv2d-154 [-1, 256, 16, 16] 131,072
BatchNorm2d-155 [-1, 256, 16, 16] 512
BN_Conv2d_Leaky-156 [-1, 256, 16, 16] 0
Conv2d-157 [-1, 512, 16, 16] 1,180,160
BatchNorm2d-158 [-1, 512, 16, 16] 1,024
Dark_block-159 [-1, 512, 16, 16] 0
Conv2d-160 [-1, 1024, 8, 8] 4,718,592
BatchNorm2d-161 [-1, 1024, 8, 8] 2,048
ReLU-162 [-1, 1024, 8, 8] 0
ReLU-163 [-1, 1024, 8, 8] 0
ReLU-164 [-1, 1024, 8, 8] 0
ReLU-165 [-1, 1024, 8, 8] 0
ReLU-166 [-1, 1024, 8, 8] 0
ReLU-167 [-1, 1024, 8, 8] 0
BN_Conv2d-168 [-1, 1024, 8, 8] 0
Conv2d-169 [-1, 512, 8, 8] 524,288
BatchNorm2d-170 [-1, 512, 8, 8] 1,024
BN_Conv2d_Leaky-171 [-1, 512, 8, 8] 0
Conv2d-172 [-1, 1024, 8, 8] 4,719,616
BatchNorm2d-173 [-1, 1024, 8, 8] 2,048
Dark_block-174 [-1, 1024, 8, 8] 0
Conv2d-175 [-1, 512, 8, 8] 524,288
BatchNorm2d-176 [-1, 512, 8, 8] 1,024
BN_Conv2d_Leaky-177 [-1, 512, 8, 8] 0
Conv2d-178 [-1, 1024, 8, 8] 4,719,616
BatchNorm2d-179 [-1, 1024, 8, 8] 2,048
Dark_block-180 [-1, 1024, 8, 8] 0
Conv2d-181 [-1, 512, 8, 8] 524,288
BatchNorm2d-182 [-1, 512, 8, 8] 1,024
BN_Conv2d_Leaky-183 [-1, 512, 8, 8] 0
Conv2d-184 [-1, 1024, 8, 8] 4,719,616
BatchNorm2d-185 [-1, 1024, 8, 8] 2,048
Dark_block-186 [-1, 1024, 8, 8] 0
Conv2d-187 [-1, 512, 8, 8] 524,288
BatchNorm2d-188 [-1, 512, 8, 8] 1,024
BN_Conv2d_Leaky-189 [-1, 512, 8, 8] 0
Conv2d-190 [-1, 1024, 8, 8] 4,719,616
BatchNorm2d-191 [-1, 1024, 8, 8] 2,048
Dark_block-192 [-1, 1024, 8, 8] 0
AdaptiveAvgPool2d-193 [-1, 1024, 1, 1] 0
Linear-194 [-1, 1000] 1,025,000
================================================================
参数情况:
Total params: 41,620,488
Trainable params: 41,620,488
Non-trainable params: 0
Input size (MB): 0.75
Forward/backward pass size (MB): 472.52
Params size (MB): 158.77
Estimated Total Size (MB): 632.04