原文链接:https://arxiv.org/abs/2306.02851
1. 引言
与传统的3D框物体表达相比,使用3D占用表达是几何感知的,因为3D框表达简化了物体的形状。此外,现有基于视觉的方法很少考虑时间信息;单阶段方法缺少从粗到细的细化过程。
本文提出OccNet,一种基于多视图图像的方法,包含级联体素解码器,利用时间信息重建3D占用,接入任务头即可支持不同的自动驾驶任务。OccNet的核心是紧凑而有代表性的3D占用嵌入,用来描述3D场景。OccNet使用级联方式,从BEV特征中解码3D占用特征。解码器使用基于体素的时间自注意力和空间交叉注意力,逐步恢复高度信息。
OccNet支持包括检测、分割和规划等各种任务。为比较各种方法,本文基于nuScenes,提出OpenOcc,一种带有密集高质量标注的3D占用基准。它将物体运动标注为有向流以支持规划任务。
OccNet能在语义场景补全、3D目标检测方面大幅增加性能;在规划方面,比起基于BEV分割或3D边界框的规划策略,OccNet能大幅减少碰撞。
3. 方法
本文的OccNet分为两个阶段:占用重建和占用利用。两阶段的连接部分是驾驶场景的统一表达,被称为占用描述符。
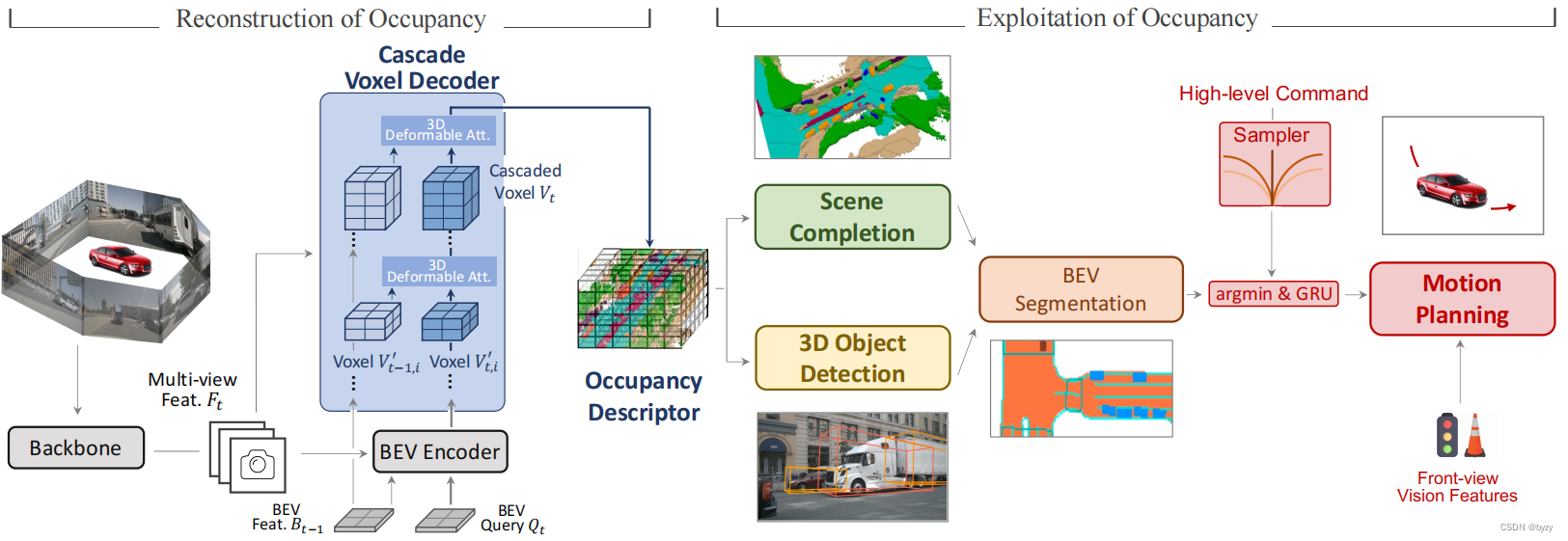 占用重建:目标是获取占用描述符已支持下游任务。直接从图像建立体素特征有极大的计算开销,但仅建立BEV特征又不足以感知高度。本文的OccNet从上述两个方案取得平衡,以可接收的代价获取较高的性能。首先提取多视图图像特征
F
t
F_t
Ft,并与历史帧的BEV特征
B
t
−
1
B_{t-1}
Bt−1以及当前帧的BEV查询
Q
t
Q_t
Qt一起输入BEV编码器(与BEVFormer相同),得到当前帧的BEV特征
B
t
B_t
Bt。然后,通过级联BEV解码器将图像特征、历史帧和当前帧的BEV特征解码为占用描述符。
占用重建:目标是获取占用描述符已支持下游任务。直接从图像建立体素特征有极大的计算开销,但仅建立BEV特征又不足以感知高度。本文的OccNet从上述两个方案取得平衡,以可接收的代价获取较高的性能。首先提取多视图图像特征
F
t
F_t
Ft,并与历史帧的BEV特征
B
t
−
1
B_{t-1}
Bt−1以及当前帧的BEV查询
Q
t
Q_t
Qt一起输入BEV编码器(与BEVFormer相同),得到当前帧的BEV特征
B
t
B_t
Bt。然后,通过级联BEV解码器将图像特征、历史帧和当前帧的BEV特征解码为占用描述符。
占用利用:基于重建的占用描述符,可以进行3D检测和3D语义场景补全。随后压缩3D占用网格与边界框的高度得到BEV分割图。BEV分割图能与高级指令采样器一起直接输入运动规划头,通过argmin和GRU模块得到自车轨迹。
3.1 级联体素解码器
BEV到级联体素:本文将BEV特征重建为体素特征的过程分为
N
N
N步,每一步逐步增加体素高度并减小通道数。如图所示,
B
t
−
1
B_{t-1}
Bt−1和
B
t
B_t
Bt被FFN提升为
V
t
−
1
,
i
′
V'_{t-1,i}
Vt−1,i′和
V
t
,
i
′
V'_{t,i}
Vt,i′,然后通过第
i
i
i层体素解码器得到修正的
V
t
,
i
′
V'_{t,i}
Vt,i′。每个体素解码器由基于体素的时间自注意力和基于体素的空间交叉注意力组成,分别使用
V
t
−
1
,
i
V_{t-1,i}
Vt−1,i和
F
t
F_t
Ft修正
V
t
,
i
′
V'_{t,i}
Vt,i′。最终得到占用描述符
V
t
V_t
Vt。
基于体素的时间自注意力:给定历史帧的体素特征
V
t
−
1
,
i
′
V'_{t-1,i}
Vt−1,i′,首先根据自车位置与当前帧占用特征
V
t
,
i
′
V'_{t,i}
Vt,i′对齐。为减小计算,设计基于体素的3D可变形注意力,使得每个查询仅和局部感兴趣的体素交互。
3D可变形注意力:将2D可变形注意力扩展为3D形式。给定体素特征
V
t
−
1
,
i
′
V'_{t-1,i}
Vt−1,i′、查询特征
q
q
q和3D参考点
p
p
p,3D可变形注意力如下:
3D-DA
(
q
,
p
,
V
t
,
i
′
)
=
∑
m
=
1
M
W
m
∑
k
=
1
K
A
m
k
W
k
′
V
t
,
i
′
(
p
+
Δ
p
m
k
)
\text{3D-DA}(q,p,V'_{t,i})=\sum_{m=1}^MW_m\sum_{k=1}^KA_{mk}W'_kV'_{t,i}(p+\Delta p_{mk})
3D-DA(q,p,Vt,i′)=m=1∑MWmk=1∑KAmkWk′Vt,i′(p+Δpmk)其中
M
M
M为注意力头数,
K
K
K为采样点数,
W
m
W_m
Wm和
W
k
′
W'_k
Wk′为学习权重,
A
m
k
A_{mk}
Amk为归一化后的注意力权重,
p
+
Δ
p
m
k
p+\Delta p_{mk}
p+Δpmk为可学习的3D采样点位置(使用三线性插值从体素采样特征)。
基于体素的空间交叉注意力:体素特征
V
t
,
i
′
V'_{t,i}
Vt,i′会与多尺度图像特征
F
t
F_t
Ft通过2D可变形注意力交互,第
i
i
i层的解码器为每个体素直接采样若干3D点,并投影到图像平面采样特征。
3.2 在多种任务上进行占用利用
语义场景补全:为每个体素使用MLP预测语义标签,并使用Focal损失。此外,使用L1损失的flow head为每个体素网格估计流速度。
3D目标检测:将占用描述符压缩为BEV,并使用基于查询的检测头(类似DeformableDETR)预测3D边界框。
BEV分割:地图分割与语义分割同样从BEV特征预测。前者使用可驾驶区域分割头和车道头表达地图,后者使用汽车分割头和行人分割头进行语义分割。
运动规划:首先将语义场景补全结果和3D边界框转化到BEV下(压缩高度),且每个BEV网格的值为0或1(表示是否占用),并输入安全代价函数计算采样轨迹的安全代价、舒适代价和进度代价。所有候选轨迹由随机速度、加速度和曲率采样得到。考虑高级指令(前进、左转、右转),相应于指令的、代价最低的轨迹会被输出。与ST-P3相同,还会使用前视图特征进行GRU细化轨迹,得到最终轨迹。
4. OpenOcc:3D占用基准
为公平比较各种方案,本文基于nuScenes提出OpenOcc的3D占用基准。
4.1 基准概述
使用稀疏激光雷达点云和3D边界框生成带高质量标注的占用数据。标注的类别包括前景和背景,且对前景物体体素标注了流速度。
4.2 高质量标注生成
独立积累背景和前景:为了生成密集表达,直观的做法是积累关键帧和中间帧的点云。但是由于运动物体的存在,通过坐标变换进行积累是有问题的。本文基于3D边界框,将激光雷达点云分为静态背景与前景物体,并分别在世界坐标系和物体坐标系下积累得到密集点云。
标注生成:先将积累的密集点云体素化,然后按照多数标注点的标注信息对体素进行标注。此外,基于边界框的速度标注,还对体素进行了流速度标注,以进行运动规划任务。对于不含标注点(来自中间帧)的体素,基于周围体素进行标注。最后进行细化,如填充道路上的洞以提高质量。此外,通过追踪相机射线,对相机不可见的体素进行了标注,使得对相机输入的任务更合理。
5. 实验
5.1 主要结果
语义场景补全:OccNet能超过其他方法的性能。
占用用于激光雷达分割:语义场景补全在体素大小趋于0的情况下与激光雷达分割等价。在只使用图像输入的情况下,OccNet能接近激光雷达分割方法的性能。
占用用于3D检测:在场景补全任务中,前景物体的位置能被粗略地回归,能帮助进行3D检测。当同时进行3D检测和场景补全时,基于BEV的方法、基于体素的方法和基于占用的方法(OccNet)均能提高性能。但是由于体素较大,在联合训练时mATE与mASE会略微上升。
占用预训练进行3D检测和BEV分割:在数据集的一小部分进行预训练时,OccNet比FCOS3D的检测性能更好;比较不同的预训练任务对BEV分割性能的影响,占用(场景补全)预训练能比3D检测预训练有更高的性能。
占用用于规划:使用OccNet的占用预测结果转化为BEV分割结果并用于规划时,比使用ST-P3直接估计的BEV分割结果有更低的碰撞率。
5.2 讨论
模型效率:比较基于BEV的方法、基于体素的方法和基于占用的方法(OccNet),OccNet能有最好的性能,且有适中的效率。
不规则物体:用3D边界框表达不规则物体如建筑车辆和交通标志是困难且不精确的。本文将3D边界框转化为体素后比较其在不规则物体上的IoU,发现占用表达能更合适地表达不规则物体。此外,减小体素大小,占用变得更细粒,能增大与3D检测的差距。
密集与稀疏占用的比较:与稀疏占用相比,密集占用能更完整地表达场景,包含更多信息,因此在下游任务上的性能更优。
附录
A. 评价指标
语义场景补全(SSC)指标:语义场景补全即预测每个体素的语义标签。评价指标为平均交并比(mIoU):
mIoU
=
1
C
∑
c
=
1
C
TP
c
TP
c
+
FP
c
+
FN
c
\text{mIoU}=\frac{1}{C}\sum_{c=1}^C\frac{\text{TP}_c}{\text{TP}_c+\text{FP}_c+\text{FN}_c}
mIoU=C1c=1∑CTPc+FPc+FNcTPc其中
C
C
C为类别数。此外还考虑类别无关的
IoU
g
e
o
\text{IoU}_{geo}
IoUgeo来评估场景的几何重建。
3D目标检测指标:与nuScenes官方相同。
运动规划指标:真实轨迹和规划轨迹的L2距离用于衡量回归精度;碰撞率用于衡量安全性。
C. OccNet的实施细节
体素解码器的特征变换:为将体素特征 V t , i ′ ∈ R Z i × H × W × C i V'_{t,i}\in\mathbb{R}^{Z_i\times H\times W\times C_i} Vt,i′∈RZi×H×W×Ci转换为 V t , i + 1 ′ ∈ R Z i + 1 × H × W × C i + 1 V'_{t,i+1}\in\mathbb{R}^{Z_{i+1}\times H\times W\times C_{i+1}} Vt,i+1′∈RZi+1×H×W×Ci+1,本文使用MLP变换特征维度。在空间交叉注意力中,图像特征会通过MLP变换为 C i C_i Ci维度。
D. 有关OpenOcc的更多细节
前景物体的积累:由于非关键帧没有边界框标注,本文使用关键帧标注进行线性插值,然后进行前景物体的积累。
数据集生成流程:
- 基于前景点和背景点的标注生成占用数据,此时仍有一部分来自中间帧的无标注体素。
- 基于已生成的占用,为部分无标注占用生成标注(按照正文的说法是根据邻域体素确定标注);
- 仍无标注的占用被视为噪声丢弃;
- 后处理,如填充小洞,来保证场景的完整性。
E. 更多实验
时间自注意力帧数的消融研究:增大帧数能略微提高性能,但是性能会逐渐饱和。
规划的占用指标评估:使用预测占用或真实占用进行规划,均比使用相应的边界框进行规划有更好的性能。
规划的预训练:实验表明,与检测预训练相比,对规划任务进行占用预训练不能提高性能。因此,需要直接使用占用的场景补全结果而非预训练特征进行规划。