文章目录
- 1. 写在前面
- 2. TextRank关键词提取算法
- 3. TFIDF算法
- 4. jionlp算法
- 5. sklearn算法
- 6. Rake算法
- 7. hanlp情感分析
- 8. 大语言模型
1. 写在前面
做过舆情项目或文本内容情感分析的大家都知道,我们要从大量的文本内容中提取核心短语或者关键词!最近我们的爬虫项目中正好遇到了这么一个需求,我们收集了大量的评论内容文本数据,需要从中分析提炼关键词(最好是去哪找带情感色彩来提炼更佳)
本次测试的评论短文本内容,如下所示:
1、一星都不想给,动不动就登录不上,啥垃圾玩意儿!
可以看到以上评论内容带着强烈的情绪,应该是很容易提炼出有价值的关键词!
2. TextRank关键词提取算法
TextRank通过词之间的相邻关系构建网络,然后用PageRank迭代计算每个节点的rank值,排序rank值即可得到关键词
TextRank是一种基于随机游走的关键词提取算法,考虑到不同词对可能有不同的共现(co-occurrence),TextRank将共现作为无向图边的权值
测试代码实现如下:
import jieba
import jieba.analyse as analyse
def textrank_extract(topK=10, cut_all=False):
textrank = analyse.textrank
stopwords = ['一星都不想给,动不动就登录不上,啥垃圾玩意儿']
words = jieba.lcut(stopwords[0], cut_all=cut_all)
words = " ".join([i for i in words if (i not in stopwords and i != '')])
keywords = jieba.analyse.textrank(words, topK=topK, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v','nr', 'nt'))
for keyword, score in keywords:
print('textrank: {} {}'.format(keyword, score))

以上程序实现如下:
(1)把给定的文本T按照完整句子进行分割
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即,其中 ti,j 是保留后的候选关键词
(3)构建候选关键词图G = (V,E),其中V为节点集,由2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词
(4)根据上面公式,迭代传播各节点的权重,直至收敛
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词
(6)由5得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词
缺点: 严重依赖于分词结果、提取时无法将两个词黏合在一起!不过TextRank考虑到了词之间的关系、倾向于将频繁词作为关键词!
3. TFIDF算法
TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度,字词的重要性随着它在文件中出现的次数成正比增加
测试代码实现如下:
import jieba
import jieba.analyse as analyse
def tf_idf_extract(topK=10, cut_all=False):
stopwords = stopwords = ['一星都不想给,动不动就登录不上,啥垃圾玩意儿']
words = jieba.lcut(stopwords[0], cut_all=cut_all)
words = " ".join([i for i in words if (i not in stopwords and i != '')])
keywords = jieba.analyse.extract_tags(words, topK=topK, withWeight=True)
for keyword, score in keywords:
print('tf_idf: {} {}'.format(keyword, score))
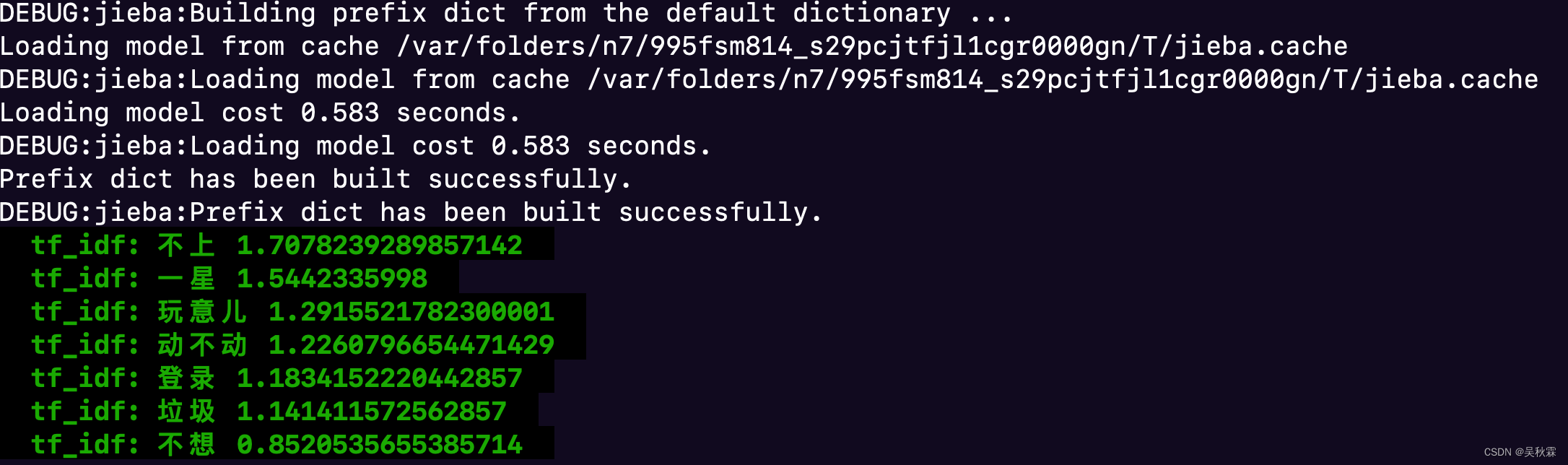
缺点:TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多!
4. jionlp算法
jionlp在 tfidf 方法提取的碎片化的关键词(默认使用 pkuseg 的分词工具)基础上,将在文本中相邻的关键词合并,并根据权重进行调整,同时合并较为相似的短语,并结合 LDA 模型,寻找突出主题的词汇,增加权重,组合成结果进行返回
测试代码实现如下:
import jionlp as jio
def jionlp_extract(topk=10):
content = '一星都不想给,动不动就登录不上,啥垃圾玩意儿'
keyword = jio.keyphrase.extract_keyphrase(content)
print('jionlp: {}'.format(keyword))

可调的参数也是特别的多,比较灵活。参考如下:
print(jio.keyphrase.extract_keyphrase.__doc__)
5. sklearn算法
scikit-learn(sklearn)是一个用于机器学习和数据挖掘的Python库,它提供了许多用于文本分析和自然语言处理(NLP)的工具和算法。在scikit-learn中,文本关键词抽取通常通过TF-IDF或Count Vectorization(词袋模型)等技术来实现!
测试代码实现如下:
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
def sklearn_extract(topk=10, cut_all=False):
stopwords = ['一星都不想给,动不动就登录不上,啥垃圾玩意儿']
# 第一步,先进行分词
words = jieba.lcut(stopwords[0], cut_all=cut_all)
# 第二步,去除停用词
words = " ".join([i for i in words if (i not in stopwords and i != '')])
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
X = vectorizer.fit_transform([words]) # 将文本转为词频矩阵
tfidf = transformer.fit_transform(X) # 计算tf-idf
word = vectorizer.get_feature_names_out() # 获取词袋模型中的所有词语
weight = tfidf.toarray() # 将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
keyword = [(wd, score) for wd, score in zip(word, weight[0])]
keyword = sorted(keyword, key=lambda x: x[1], reverse=True)[:topk]
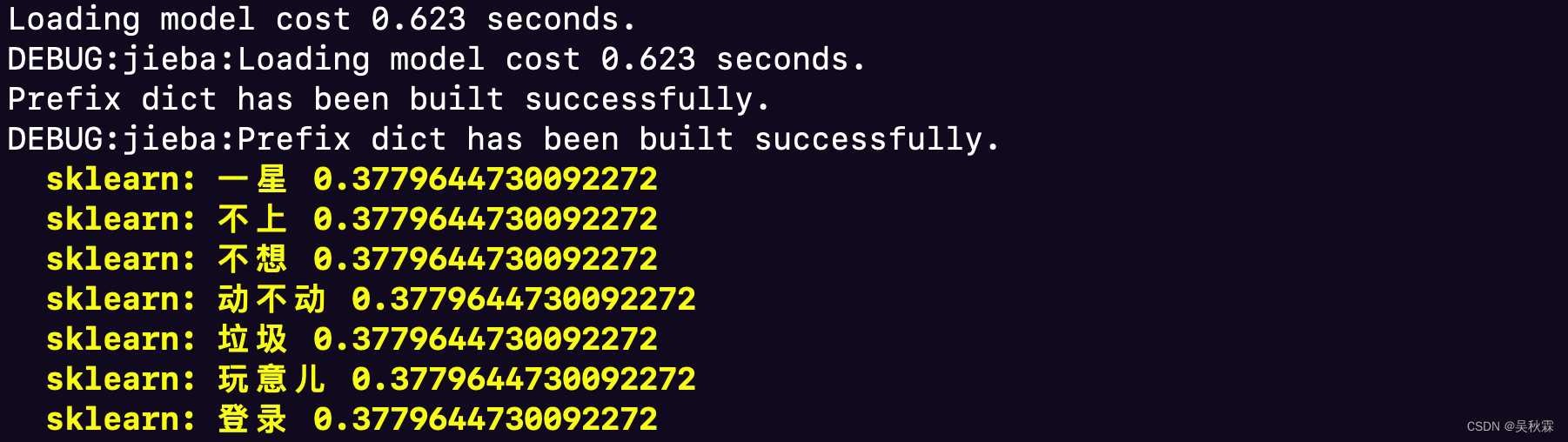
for k, score in keyword:
print(YELLOW % 'sklearn: {} {}'.format(k, score))
CountVectorizer:该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
TfidfTransformer:该类会统计每个词语的tf-idf权值
6. Rake算法
Rake实际上提取的是关键的短语,并且倾向于较长的短语,在英文中,关键词通常包括多个单词,但很少包含标点符号和停用词,例如and,the,of等,以及其他不包含语义信息的单词
Rake算法首先使用标点符号将文本分成若干分句,然后对于每一个分句,使用停用词作为分隔符将分句分为若干短语,这些短语作为最终提取出的关键词的候选词
然后将其中每个单词的得分累加,并进行排序,RAKE将候选短语总数的前三分之一的认为是抽取出的关键词!
测试代码实现如下:
def rake_extract(topk=10):
swLibList = ['一星都不想给,动不动就登录不上,啥垃圾玩意儿']
conjLibList = []
rawtextList = pseg.cut(swLibList[0])
textList = []
listofSingleWord = dict()
lastWord = ''
poSPrty = ['m', 'x', 'uj', 'ul', 'mq', 'u', 'v', 'f']
meaningfulCount = 0
checklist = []
for eachWord, flag in rawtextList:
checklist.append([eachWord, flag])
if eachWord in conjLibList or not notNumStr(
eachWord) or eachWord in swLibList or flag in poSPrty or eachWord == '\n':
if lastWord != '|':
textList.append("|")
lastWord = "|"
elif eachWord not in swLibList and eachWord != '\n':
textList.append(eachWord)
meaningfulCount += 1
if eachWord not in listofSingleWord:
listofSingleWord[eachWord] = Word(eachWord)
lastWord = ''
newList = []
tempList = []
for everyWord in textList:
if everyWord != '|':
tempList.append(everyWord)
else:
newList.append(tempList)
tempList = []
tempStr = ''
for everyWord in textList:
if everyWord != '|':
tempStr += everyWord + '|'
else:
if tempStr[:-1] not in listofSingleWord:
listofSingleWord[tempStr[:-1]] = Word(tempStr[:-1])
tempStr = ''
for everyPhrase in newList:
res = ''
for everyWord in everyPhrase:
listofSingleWord[everyWord].updateOccur(len(everyPhrase))
res += everyWord + '|'
phraseKey = res[:-1]
if phraseKey not in listofSingleWord:
listofSingleWord[phraseKey] = Word(phraseKey)
else:
listofSingleWord[phraseKey].updateFreq()
outputList = dict()
for everyPhrase in newList:
if len(everyPhrase) > 5:
continue
score = 0
phraseString = ''
outStr = ''
for everyWord in everyPhrase:
score += listofSingleWord[everyWord].returnScore()
phraseString += everyWord + '|'
outStr += everyWord
phraseKey = phraseString[:-1]
freq = listofSingleWord[phraseKey].getFreq()
if freq / meaningfulCount < 0.01 and freq < 3:
continue
outputList[outStr] = score
sorted_list = sorted(outputList.items(), key=operator.itemgetter(1), reverse=True)
for keyword in sorted_list:
print(YELLOW % 'rake: {} {}'.format(keyword[0], keyword[1]))
这个提取算法的效果相比前面几个,显得是有点越来越离谱:

7. hanlp情感分析
这里再给大家介绍一个用于文本情感分析的开源工具hanlp,像我们在做评论的情感分析时,想区分这条评论的内容是一个正向的还是负面的,它支持一个在线演示:
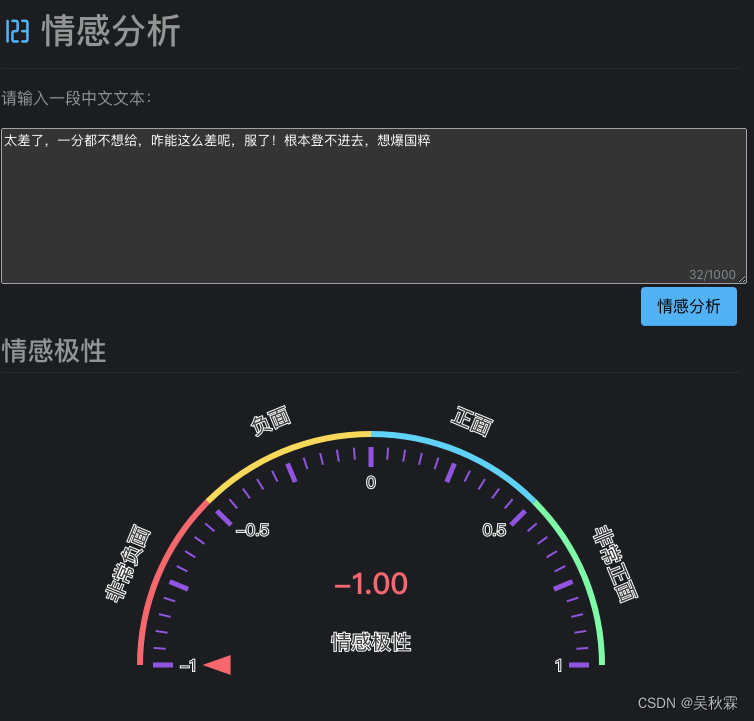
情感分析任务的目标是判断上面这段文本的情感极性。 情感极性为[-1, 1]之间的数值,数值的正负代表正负面情绪,数值的绝对值代表情感的强烈程度
8. 大语言模型
最后我们使用最火的GPT大语言模型来提取我们的文本关键词,个人感觉更加贴近理想效果:

好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章

![web:[HCTF 2018]WarmUp](https://img-blog.csdnimg.cn/46a3507b117245819d42c50a1ccb6f94.png)