前言
💓作者简介: 加油,旭杏,目前大二,正在学习C++,数据结构等👀
💓作者主页:加油,旭杏的主页👀⏩本文收录在:再识C进阶的专栏👀
🚚代码仓库:旭日东升 1👀
🌹欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖
学习目标:
在上一篇博客中,我们学习了回调函数,以及怎么使用qsort函数去排序;那么在这一篇博客中,我们来更加详细地学习qsort函数内部是怎么进行排序的,以及想要用冒泡排序去模拟实现一下可以排序任意类型数据,最后我们要进行做题来巩固一下所学的知识点。
学习内容:
通过上面的学习目标,我们可以列出要学习的内容:
- 学习qsort函数内部是怎么进行排序的
- 用冒泡排序去模拟实现一下可以排序任意类型数据
- 做题巩固一下知识点
- 指针的笔试题
一、学习qsort函数内部是怎么进行排序的
在学习qsort函数内部是如何实现的,我们需要在认真地将qsort函数的形参进行一遍分析,因为其形参的个数实在是太多了,这就和数学公式一样,要记住每一个字母表示的含义,这样我们才能用的对。
1.1 qsort函数中的四个参数的意思
这时,我们需要打开cplusplus的网站,进行搜索qsort函数,如下图所示:接下来一一分析:

1.1.1 void* base
首先,映入我们眼帘的是其类型:void* 。
这个类型还是很重要的,void* 类型要记住一些要点:
- void* 创建的变量可以接收任意类型的指针变量;
- void* 创建的变量不能进行加减整数的运算,因为不知道类型,无法确定加减整数后,指针移动几位字节。
之后,这个参数存放的是待排序数组的第一个元素的地址。
1.1.2 size_t num
这个形参的类型可能读者也没有见过,简单地理解其就是无符号整形。我们在VS转到定义时,可以看到是用 typedef 定义的,如下图:

这个参数存放的是待排序数组的元素个数。
1.1.3 size_t size
因为qsort函数可以排序任意类型的数据,但是任意类型数据的大小是不同,我们需要将我们所要排序的数据类型传过去,让qsort函数知道数据的大小,好进行排序。
这个参数存放的是待排序数组中一个元素的大小。
1.1.4 int (*comper) (const void*, const void*)
这个参数就是我们上一篇博客所学习的函数指针,qsort函数需要我们自己写一个比较函数,因为qsort函数默认是升序排序的,这个要知道,不然容易迷。
这个比较函数所返回的值与0进行比较,会产生不同的结果,如果大于0即成立,交换两个数,如果小于0即不成立,不交换。如下图:(如果图里的情况看不懂,我们可以看下面的代码)

int compare(const void* e1, const void* e2)
{
int* p1 = e1;
int* p2 = e2;
if (*p1 > *p2)
{
return 1;
}
else if (*p1 == *p2)
{
return 0;
}
else if (*p1 < *p2)
{
return -1;
}
}这个参数的含义是:函数指针——cmp指向了一个函数,这个函数是用来比较两个元素的。
1.2 引出qsort函数内部算法的思想
qsort函数内部是用快速算法进行实现,因为我的算法博客也更新到这一篇,我就直接在这一篇上写了,快速算法肯定不同于我们之前所学的归并排序和堆排序,我们先用一个简单的题目引出类似于快速排序算法的思路。
1.2.1 将数组分为两个区域的问题
在讲述荷兰国旗问题之前,我们先来看一个更简单的题,来帮助我们进入荷兰国旗问题的思路。
题目:
给定一个数组arr,和一个数num,请把数组中小于等于num的数放在数组的左边,把数组中大于num的数放在数组的右边,无需排序。要求空间复杂度为:O(1),时间复杂度为:O(N)
思路:
我们可以将数组分为两个区:一个是<=num区,一个是>num区。我们可以先将<=num区放在数组首元素的前一个位置,将指针指向数组中第一个元素与num进行比较。
如果第一个元素比num小于或者等于,<=num区往前加一,将指针加一,继续与num进行比较;
如果指针指向的元素比num大,<=num区不动,指针向后移动,直到比num小停止,将这个数与<=num区的后面一个数进行交换即可。循环整个过程,直到指针指向空。
代码:
void swap(int arr[], int a, int b) { int temp = arr[a]; arr[a] = arr[b]; arr[b] = temp; } void prather(int* arr, int left, int right, int num) { int less = left - 1; int index = left; while (index <= right) { if (arr[index] <= num) { swap(arr, ++less, index++); } else { index++; } } } int main() { int arr[10] = { 2,3,6,3,4,7,9,0,2,3 }; int left = 0; int right = 9; int num = 3; prather(arr, left, right, num); for (int i = 0; i < 10; i++) { printf("%d ", arr[i]); } return 0; }
这个问题的关键主要就是将数组分为两个部分,而荷兰国旗问题是将数组分为三个部分,是属于其的进阶。 将数组分为两个区域,我们用了一个作用界限;而将数组分为三个区域是否需要两个作用界限呢?
1.2.2 荷兰国旗问题
题目:
牛牛今天带来了一排气球,气球有n个,然后每一个气球里面都包含一个数字,牛牛是一个善于思考的人,于是他就想到了一个问题,牛牛随便给你一个值K,这个值在这些气球中不一定存在,聪明的你需要把气球中包含的数字是小于K的放到这排气球的左边,大于K的放到气球的右边,等于K的放到这排气球的中间,最终返回一个整数数组,其中只有两个值,分别是气球中包含的数字等于K的部分的左右两个下标值,如果气球中没有K这个数字就输出-1,-1。
思路:
这个就相当于将一个数组通过所给的数字分为三个区:一个是<num区,一个是==num区,一个是>num区。我们需要将<num区,和>num区同时卡住,这样剩下就是==num区的内容,于是思路就有了。
定义两个指针变量,一个指针变量 less 指向数组首元素的前一个位置,一个指针变量 more 指向数组最后一个元素的后一个位置,用一个索引index指向数组的首元素。
如果index指向的元素小于num,则less++,交换less++的元素与index指向的元素,然后index++;
如果index指向的数组元素等于num,则index++;
如果index指向的元素大于num,则交换index与more--的元素,index不++。
代码:
#include <stdio.h> #include <malloc.h> void swap(int arr[], int a, int b) { int temp = arr[a]; arr[a] = arr[b]; arr[b] = temp; } void Nether(int arr[], int left, int right, int k) { int less = left - 1; int more = right + 1; int index = left; while (index < more) { if (arr[index] < k) swap(arr, ++less, index++); else if (arr[index] > k) swap(arr, --more, index); else index++; } if (less + 1 <= more - 1) { int* ret = (int*)malloc(sizeof(int) * 2); ret[0] = less + 1; ret[1] = more - 1; for (int i = 0; i < 2; i++) { printf("%d ", ret[i]); } } else{ for(int i = 0; i < 2; i++) { printf("-1 "); } } } int main() { int n = 0, k = 0; int arr[100010]; scanf("%d %d", &n, &k); for (int i = 0; i < n; ++i) { scanf("%d ", &arr[i]); } int left = 0; int right = n - 1; Nether(arr, left, right, k); return 0; }
1.3 qsort函数内部是怎么实现的
在 1.2 中,学习了荷兰国旗问题的思路,其实qsort函数内部算法的实现是快速排序,而快速排序在发展中,有三个阶段:分别是快速排序 1.0,快速排序 2.0 和快速排序 3.0。
1.3.1 快速排序 1.0
在这个版本下,快速排序的思路与荷兰国旗问题的思路基本相同,不过不一样的地方是荷兰国旗问题比较的是随机给的数字,而快速排序比较的一定是数组中的数字。
不买关子了,快速排序的算法思路是:将数组最后一个元素作为比较数,将数组分为:<=比较数区,>比较数区,这样就将最后一个元素排好序了,其数组下标记作p;将数组分为左右两个部分,利用递归再比较p-1和p+1的元素,将他们排好序,递归下去,就可以将数组中的元素排好序。
但这个思路有一个比较明显的不足,不足之处在于数组中有连续相等的数字,但也会损失一下常数时间,所以在快速排序 2.0 版本下,将数组分为三个区:<比较数区,==比较数区,>比较数区。这样就能节省一些常数时间。
1.3.2 快速排序 2.0
在快速排序 1.0 中,已经提出了快速排序 2.0 的思路了,也就比快速排序 1.0优化了一下常数时间。不过这两种方式都不是最优的,如果我们考虑最差情况,在最差情况中,两者的时间复杂度接近于O(N*N),与冒泡排序没什么两样,为什么呢?
原因如下:因为如果数组元素中最后一个数排序过后不在中间的位置,那么时间复杂度就会增加,如果说如果每一次要排序元素在正中间的话是最好的情况!不过不太可能,所以在这两个版本下,时间复杂度都会增加。
1.3.3 快速排序 3.0
快速排序 3.0中,我们不同于以往将数组的最后一个元素进行比较,而是将随机匹配一个数组元素进行比较,根据概论发现,如果数组有N个元素,那么每一个元素被选中的概率是1/N。经过数学计算后,会发现这个排序的时间复杂度为:O(N*logN),达到了我们的目的。
1.3.4 快速排序的代码
#include <stdlib.h>
#include <string.h>
#include <malloc.h>
void swap(int arr[], int a, int b) //交换函数
{
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
int* partion(int arr[], int left, int right); //函数声明,不要忘记
void quicksort(int arr[], int left, int right)
{
if (left < right) //递归终止条件
{
//先随机选一个元素与数组中最后一个元素进行交换,然后进行partion
int num = rand() % (right - left + 1); //产生0~sz的任意数字
swap(arr, left + num, right);
int* ans = (int*)malloc(sizeof(int) * 2);
ans = partion(arr, left, right);
quicksort(arr, left, ans[0] - 1); //<arr[num]区
quicksort(arr, ans[1] + 1, right);//>arr[num]区
}
}
int* partion(int arr[], int left, int right)
{
int less = left - 1;
int more = right + 1;
int index = left;
int* ret = (int*)malloc(sizeof(int) * 2);
while (index < more)
{
if (arr[index] < arr[right])
{
swap(arr, ++less, index++);
}
else if (arr[index] > arr[right])
{
swap(arr, --more, index);
}
else
index++;
}
ret[0] = less + 1;
ret[1] = more - 1;
return ret;
}二、用冒泡排序去模拟实现一下可以排序任意类型数据
在模拟实现冒泡排序前,先来熟悉一下冒泡排序的思想,记住,知识点要进行大量的重复记忆,这样才能会用。
2.1 冒泡排序的思路
冒泡排序,冒泡排序,就是让最大的数像重物一样沉到底部,两两进行比较,然后进行交换位置,这就是基本思路。
第一次将最大的数字沉到底部,第二次将次大的数字沉到底部,第三次……是一个循环将最大数从大到小依次沉到底部,所以我们来实现一下代码:
void bubble_sort(int arr[], int sz)
{
for (int i = 0; i < sz - 1; ++i)
{
for (int j = 0; j < sz - 1 - i; ++j)
{
if (arr[j] > arr[j + 1])
{
swap(arr, j, j + 1);
}
}
}
}2.2 模拟实现任何类型的冒泡排序
而单一的冒泡排序用法实在是太少了,在学习了qsort函数之后,我们就是能将冒泡排序也改造为能够排任意类型的数据呢?那么接下来,我们就要朝着这个方向进行:
2.2.1 实现任何类型的冒泡排序的主体
2.2.1.1 参数部分
因为不同类型的数据进行比较时,他们的比较方法是不同,如果我们想要比较不同类型的数据还要写不同的比较方法,这样函数就变多了,这样就不是一个函数了,所以我们将这个比较方法抽离出来,让用户自己写。因为不同类型的数据的大小不同,所以用户要传入要排序数据的大小,还要传入要排序数据的多少。因此,此函数与qsort函数的参数类似。
void bubble_sort(void* base, size_t num, size_t size, int (*cmp)(const void*, const void*))2.2.1.2 主体部分
在参数部分中,有一个函数指针,函数主体的大体部分是一样的,我们只需要改变一下比较条件,类似于qsort函数的条件,默认是一个是升序排序。
void bubble_sort(void* base, size_t num, size_t size, int (*cmp)(const void*, const void*))
{
for (int i = 0; i < num - 1; ++i)
{
for (int j = 0; j < num - 1 - i; ++j)
{
if (cmp((char* )base + j * size, (char*)base + (j + 1) * size) > 0)
{
swap((char*)base + j * size, (char*)base + (j + 1) * size, size);
}
}
}
}2.2.2 实现任何类型的冒泡排序的交换部分
不同数据类型的数据大小也是不一样的,因为数据类型大小的基本单位是字节,所以我们用char*指针来接收(char类型的大小为1个字节)。我们不能将这个数据进行交换,我们只能一个字节一个字节的交换。
void swap(char* a, char* b, size_t size)
{
for (int i = 0; i < size; ++i)
{
char temp = *a;
*a = *b;
*b = temp;
a++;
b++;
}
}三、一些有关 sizeof 和 strlen 的题目
这个题目有点多,可能会有点费时间,但是主要是将括号内的东西理解清楚是什么?我们来一一进行:
3.1 sizeof 类型
3.1.1 一维数组
//一维数组
int a[] = { 1,2,3,4 }; //答案
printf("%d\n", sizeof(a)); //16
printf("%d\n", sizeof(a + 0)); //4/8
printf("%d\n", sizeof(*a)); //4
printf("%d\n", sizeof(a + 1)); //4/8
printf("%d\n", sizeof(a[1])); //4
printf("%d\n", sizeof(&a)); //4/8
printf("%d\n", sizeof(*&a)); //16
printf("%d\n", sizeof(&a + 1)); //4/8
printf("%d\n", sizeof(&a[0])); //4/8
printf("%d\n", sizeof(&a[0] + 1));//4/8解析:
1. 数组名在一般情况下,表示的数组首元素的地址,而数组名单独放在sizeof内部,数组名表示整个数组,计算的是整个数组的大小,单位是字节。
2. 数组名未单独出现,也没有&,所以数组名表示的是首元素的地址,a + 0还是首元素的地址,是一个指针,大小是4/8个字节。
3. 数组名未单独出现,也没有&,所以数组名表示的是首元素的地址,解引用表示数组的首元素,大小为4个字节。
4. 与2类似。
5. 表示的是数组中第一个元素,其大小为4个字节。
6. &数组名取出的数组的地址,还是一个指针,大小为4/8个字节。
7. 解引用与取地址可以互相抵消,则其表示的是数组,计算的是数组的大小,为16个字节。
8. 与6类似,&数组名取出的是数组的地址,加1表示跳过一个数组大小,指向跳过一个数组的大小的地方。
9. &a[0]表示的是取出数组首元素的地址,是一个指针,大小为4/8个字节。
10. 与9类似,还是一个地址,大小为4/8个字节。
3.1.2 字符数组
//字符数组
char arr[] = {'a','b','c','d','e','f'}; //答案
printf("%d\n", sizeof(arr)); //6
printf("%d\n", sizeof(arr + 0)); //4/8
printf("%d\n", sizeof(*arr)); //1
printf("%d\n", sizeof(arr[1])); //1
printf("%d\n", sizeof(&arr)); //4/8
printf("%d\n", sizeof(&arr + 1)); //4/8
printf("%d\n", sizeof(&arr[0] + 1)); //4/83.1.3 二维数组
//二维数组
int a[3][4] = {0}; //答案
printf("%d\n", sizeof(a)); //48
printf("%d\n", sizeof(a[0][0])); //4
printf("%d\n", sizeof(a[0])); //16
printf("%d\n", sizeof(a[0] + 1)); //4/8
printf("%d\n", sizeof(*(a[0] + 1))); //4
printf("%d\n", sizeof(a + 1)); //4/8
printf("%d\n", sizeof(*(a + 1))); //16
printf("%d\n", sizeof(&a[0] + 1)); //4/8
printf("%d\n", sizeof(*(&a[0] + 1))); //16
printf("%d\n", sizeof(*a)); //16
printf("%d\n", sizeof(a[3])); //16解析:
1. 当数组名单独出现在sizeof内部时,数组名表示整个数组,计算的是整个数组的大小,单位是字节;
2. a[0][0]表示的是这个二维数组的第一行第一列的数组元素,sizeof计算的是类型大小,即数组元素的类型大小,单位是字节;
3. 这里要对二维数组有一个新的认识,就是二维数组是一维数组的数组,其首元素表示的是二维数组的第一行,即一维数组。因此,当二维数组的首元素单独出现在sizeof内部时,表示的是二维数组的一行元素,计算的是一行元素的大小,单位是字节;
4. 如果二维数组的元素不是单独出现,则表示的是这一行首元素的地址,加减一个整数即为地址,因为没有对二维数组元素进行取地址,则这里指针的类型是int* ,当加一时,表示的是这一行元素的第二个元素;
5. 由4可得,对这个地址进行解引用,得到的是一个元素的大小;
6. 数组名没有单独出现,表示的是数组的第一行地址,此时指针类型为数组指针类型,进行加一时,指向的是第二行的地址;
7. 由6可得,指向的是数组第二行的地址,进行解引用时,得到的是第二行元素的大小;
8. &数组名,取出的是第一行元素的地址,再加一,指向的是第二行地址;
9. 由8可得,对第二行地址进行解引用,得到的是第二行元素的大小;
10. 数组名未单独出现,对其解引用得到的是数组首元素,即第一行元素的大小;
11. 这里并没有越界,因为sizeof只是需要知道,用户传过去的是什么类型的即可,并没有去访问。a[3]与a[0]一样表示的一行元素,即一行元素的大小。
3.2 strlen 类型
//字符数组
char arr[] = {'a','b','c','d','e','f'}; //答案
printf("%d\n", strlen(arr)); //随机值
printf("%d\n", strlen(arr + 0)); //随机值
printf("%d\n", strlen(*arr)); //error
printf("%d\n", strlen(arr[1])); //error
printf("%d\n", strlen(&arr)); //随机值
printf("%d\n", strlen(&arr + 1)); //随机值-6
printf("%d\n", strlen(&arr[0] + 1)); //随机值-1解析:
1. strlen计算的字符串的长度,要有'\0'的结束标志,由于这个字符数组中没有'\0'的结束标志,所以是随机值。
2. 同理,也是随机值。
3. *arr表示的是一个字符,但在strlen中,只能是地址,所以strlen认为这是一个非法地址,会报错。
4. 与3同理
5. &arr尽管取出的是数组的地址,但是在数值上与数组首元素的地址是一样,所以也是随机值。
6和7与5类似。
3.3 总结
再来复习一下数组名的意义:
- sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小;
- &数组名,这里的数组名表示整个数组,取出的是整个数组的地址;
- 除此之外,所有的数组名都表示首元素的地址。
四、指针的笔试题
这个题目有点多,在这里小编先挑几条重要进行讲解,之后小编会整理一下所有的笔试题在写一篇博客的。那么,我们来看笔试题:
笔试题一:
题目:
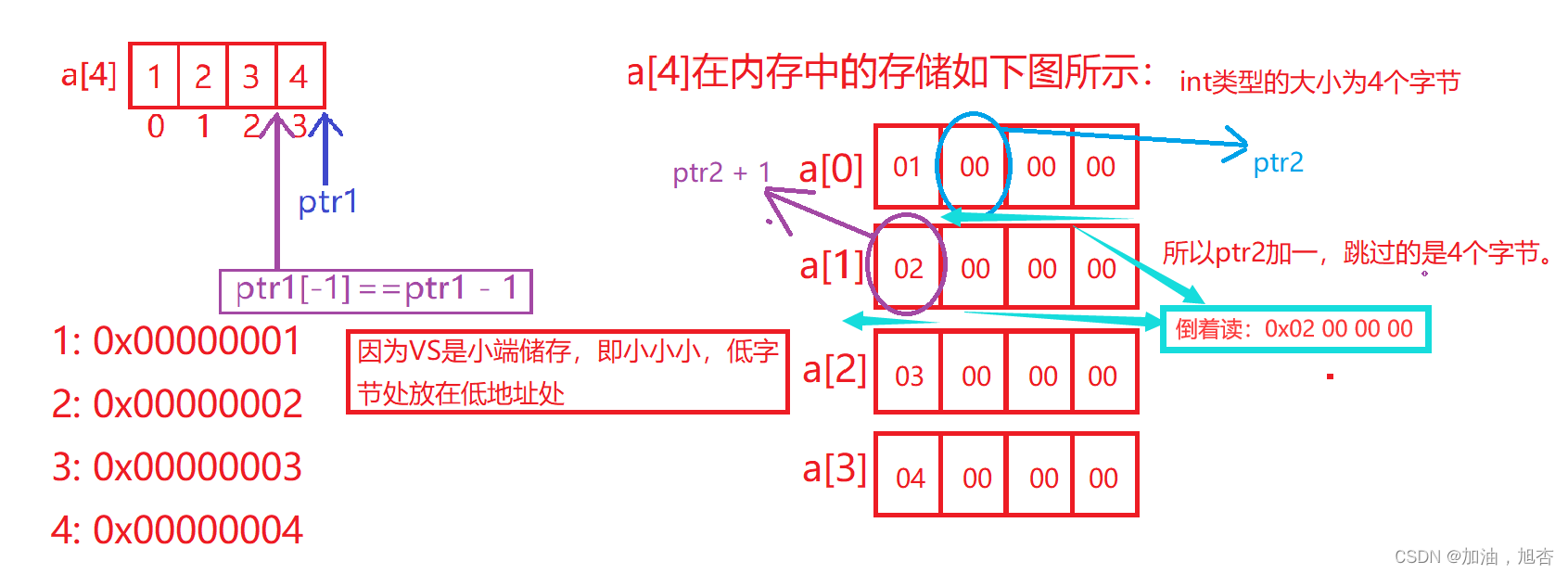
int main() { int a[4] = { 1,2,3,4 }; int* ptr1 = (int*)(&a + 1); int* ptr2 = (int*)((int)a + 1); printf("%x, %x\n", ptr1[-1], *ptr2); return 0; }解析:
第一个是比较简单的,&数组名将数组的整个地址取出,进行加一时,跳过整个数组,看图;第二个就有点难度,因为a表示的是数组首元素的地址,强制类型转换为整形,再加一,只跳过一个字节,而一个整形的大小是4个字节,即这个指针指向的是第一个整形变量中的第二个字节,因此要考虑编译器是小端传输还是大端传输,这是很重要的。
答案:
0x00000004, 0x02000000
笔试题二:
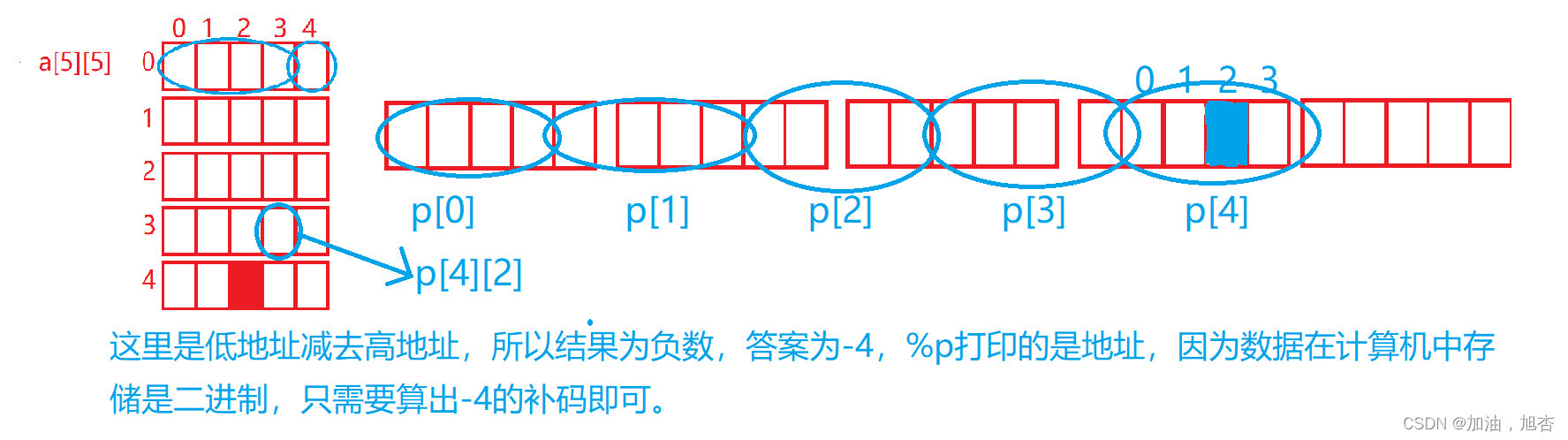
题目:
int main() { int a[5][5]; int(*p)[4]; p = a; printf("%p, %d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]); return 0; }解析:
p是一个数组指针,将二维数组a的地址赋给p不太合适,但是也能接收,那就可以将p看成一行元素为4个的二维数组,看解析图:
答案:
大家自己去验证,这里就不算了。
学习产出:
- 学习qsort函数内部是怎么进行排序的
- 用冒泡排序去模拟实现一下可以排序任意类型数据
- 做题巩固一下知识点
- 指针的笔试题