LLM 是 “Large Language Model” 的简写,目前一般指百亿参数以上的语言模型, 主要面向文本生成任务。跟小尺度模型(10亿或以内量级)的“百花齐放”不同,目前LLM的一个现状是Decoder-only架构的研究居多,像OpenAI一直坚持Decoder-only的GPT系列就不说了,即便是Google这样的并非全部押注在Decoder-only的公司,也确实投入了不少的精力去研究Decoder-only的模型,如PaLM就是其中之一。那么,为什么Decoder-only架构会成为LLM的主流选择呢?
我们都知道,Transformer 模型一开始是用来做 seq2seq 任务的,所以它包含 Encoder 和 Decoder 两个部分;他们两者的区别主要是,Encoder 在抽取序列中某一个词的特征时能够看到整个序列中所有的信息,即上文和下文同时看到;而 Decoder 中因为有 mask 机制的存在,使得它在编码某一个词的特征时只能看到自身和它之前的文本信息。
一、Encoder 的低秩问题
LLM之所以主要都用Decoder-only架构,除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。(参考:为什么现在的LLM都是Decoder-only的架构?)
二、更好的Zero-Shot性能、更适合于大语料自监督学习
首先,对 encoder-decoder 与 decoder-only 的比较早已有之。咱们先把目光放放到模型参数动辄100B之前的时代,看看小一点的模型参数量下、两个架构各有什么优势——Google Brain 和 HuggingFace联合发表的 What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization? 曾经在5B的参数量级下对比了两者性能。
NLP论文速读:探索语言模型的最佳架构和训练方法[ICML’22 × 2]
论文最主要的一个结论是:decoder-only 模型在没有任何 tuning 数据的情况下、zero-shot 表现最好,而 encoder-decoder 则需要在一定量的标注数据上做 multitask finetuning 才能激发最佳性能。 而目前的Large LM的训练范式还是在大规模语料上做自监督学习,很显然,Zero-Shot性能更好的decoder-only架构才能更好地利用这些无标注数据。此外,Instruct GPT在自监督学习外还引入了RLHF作辅助学习。RLHF本身也不需要人工提供任务特定的标注数据,仅需要在LLM生成的结果上作排序。虽然目前没有太多有关RLHF + encoder-decoder的相关实验,直觉上RLHF带来的提升可能还是不如multitask finetuning,毕竟前者本质只是ranking、引入监督信号没有后者强。
三、大数据训练+大参数模型的涌现能力替代了multitask finetuning
前面说到,5B参数量+170B token 数据量时,在做 multitask finetuning 后 encoder-decoder 相比 decoder-only 反而在新任务(zero-shot)上会有一定的优势。那么,在参数量再上一个台阶后,我们知道了LLM大模型表现出了涌现能力 (emergent abilities)。关于涌现能力,爱丁堡大学的Yao Fu博士有一篇很好的博客详细阐述:
A Closer Look at Large Language Models Emergent Abilities
简言之,在模型参数量足够大时,模型的能力提升不再遵守以往的log-linear的提升法则,而是突然急速增强性能。
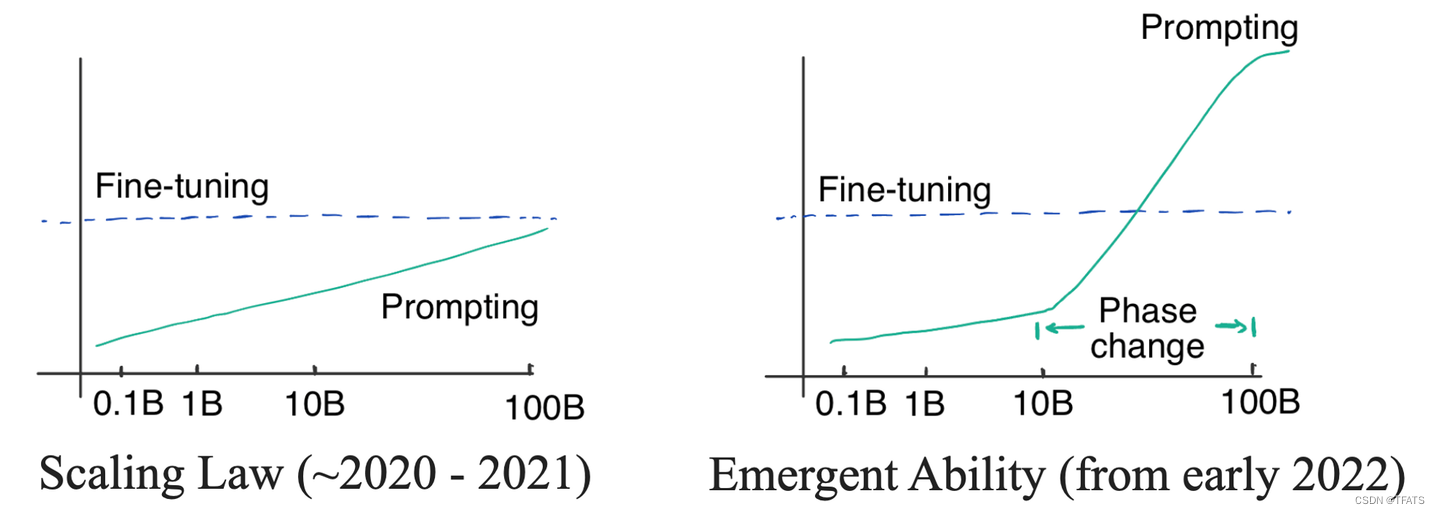
我们迄今还没有办法解释涌现能力为何出现。涌现能力的一个表现是,参数量达到一定量级后,模型具有了"复杂的推理能力"——譬如从非结构化的文本中自动地提取结构化的知识。
那么,LLM也可以自动地从大数据里面做 “self multitask finetuning”。具体来讲,大数据里面本身天然蕴含了许多任务:比如 双语网页数据-机器翻译、论文(摘要+正文)数据-文本摘要、维基百科数据-命名实体识别等等。
因此,对于常见的NLP任务、LLM可以视为已经self finetuning过了;对于复杂问题,LLM的推理能力可以把这些问题转换成几个基本任务的”和“。譬如Closed-book question-answering任务,模型可以将其转换为 Knowledge Graph Completion + Reading Comprehension + Question Answering的组合。
由此,encoder-decoder在multitask finetuning上的优势在大参数量时被LLM的推理能力给拉平了。
四、In-context learning 对 LLM 有 few-shot finetune 的作用
最后,在实际使用LLM时,我们经常会加入 Chain-of-Thought 或者 In-Context (在in-context learning中,模型不根据下游任务调整参数,而是将下游任务的输入输出接起来之后作为prompt,引导模型根据测试集的输入生成预测结果。该方法的表现可以大幅超越零监督学习,并给大模型高效运用提供了新的思路。)信息来作为prompt进一步激发模型潜力——例如加入一些例句让GPT类模型来模仿、生成更好的结果。
近期有论文指出In-Context信息可以视为一种task finetuning
Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers
论文的数学推导是定性的,大体上是将prompt信息归为对Transformer Attention层参数的微调。
按照这篇论文的思路,decoder-only 的架构相比 encoder-decoder 在 In-Context 的学习上会更有优势,因为前者的 prompt 可以更加直接地作用于 decoder 每一层的参数,微调信号更强。也因此,更适合 ChatGPT 这类开放域的对话模型作为基础模型。同理,在总数据量少的情况下,In-Context + Decoder-only 也更具有 few-shot 的优势——Google近期的论文在机器翻译上也观察到了类似现象,即中等量的单语数据+大模型+In context就能学习出很好的翻译效果:
NLP论文阅读:大语言模型的few-shot或许会改变机器翻译的范式
五、目标函数
GPT 模型选择了 Decoder,也正是因为 GPT 的预训练目标函数选取的是标准的语言模型目标函数,使得模型在预测某一个词的时候只考虑上文信息而不参考下文。
BERT 在预训练的时候选择的不是标准的语言模型作为目标函数,而是一种 MLM 的掩码语言模型, 也就是在预测句子中某一个词的时候可以同时看到它前后的所有上下文信息,类似于一种完形填空任务,所以 BERT 选择的是 Transformer 的编码器模块。
Decoder 选择的是一个更难的目标函数,它是根据前面的信息去预测下文,预测未来肯定是比完形填空难度要更大的。这也能从某种程度上解释了为什么相同规模的 GPT 和 BERT 模型,GPT 的效果要比 BERT 差。但是从另一个角度去想,如果能够把预测未来这个事情做好的话,它最终所能达到的效果的天花板一定是更高的,这可能也是 OpenAI 从一开始到现在一直坚持使用标准语言模型目标函数来做预训练模型的其中一个原因吧,当然这只是一种猜想。事实证明,从 GPT-3 开始,到最近的 ChatGPT,OpenAI 所取得的令人惊艳的效果也一定程度上证明了他们的选择的正确性。
六、更高的上限和多样性
模型在scale up之后,尤其是加上instruction tuning之后,其他架构能做的 decoder-only 模型也都能做了(比如一众NLU任务),同时还有更高的上限和多样性(NLG)。
七、总结
总而言之,decoder-only 在参数量不太大时就更具有更强的zero-shot性能、更匹配主流的自监督训练范式;而在大参数量的加持下,具有了涌现能力后、可以匹敌encoder-decoder做finetuning的效果;在In Context的环境下、又能更好地做few-shot任务。
decoder-only 架构符合传统的 Language Model 的模式。 前几年 encoder-decoder 模型的火爆更多是依赖于在特定标注数据上的训练——比如Transformer论文中经典的WMT机器翻译任务。
八、encoder-decoder的未来
在未来,Large Language Model+自监督训练应该还是会继续采用 decoder-only 的架构。encoder-decoder有两个特点可能会使得它在以下两类任务上有优势:
- encoder 的多样性。许多多模态工作(BLIP、ALBEF、SimVLM)上可以看见 encoder-decoder的影子,因为encoder 可以用来 encoder 多种模态的信息,而decoder-only的多模态工作相对较少(微软近日的visual-ChatGPT更多偏向模型级联pipeline)。
- Deep Encoder+Shallow Decoder的推理优势。Encoder-decoder架构本来在计算效率上(以FLOPs衡量)就是优于其他LM的,且工业界目前常使用Deep Encoder+Shallow Decoder的组合,由于encoder本身并行度高,这类encoder-decoder的infer速度远超大型的decoder-only。在有较多标注数据的任务上,encoder-decoder还是具有成本优势的。
参考:
为什么现在的LLM都是Decoder-only的架构?
为什么现在的LLM都是Decoder only的架构?