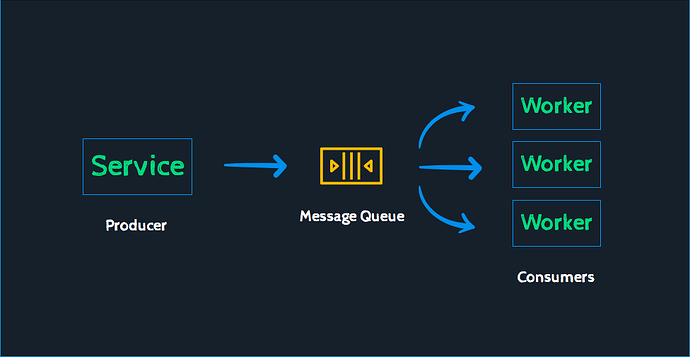
MQA (multi query attention)
Fast Transformer Decoding: One Write-Head is All You Need
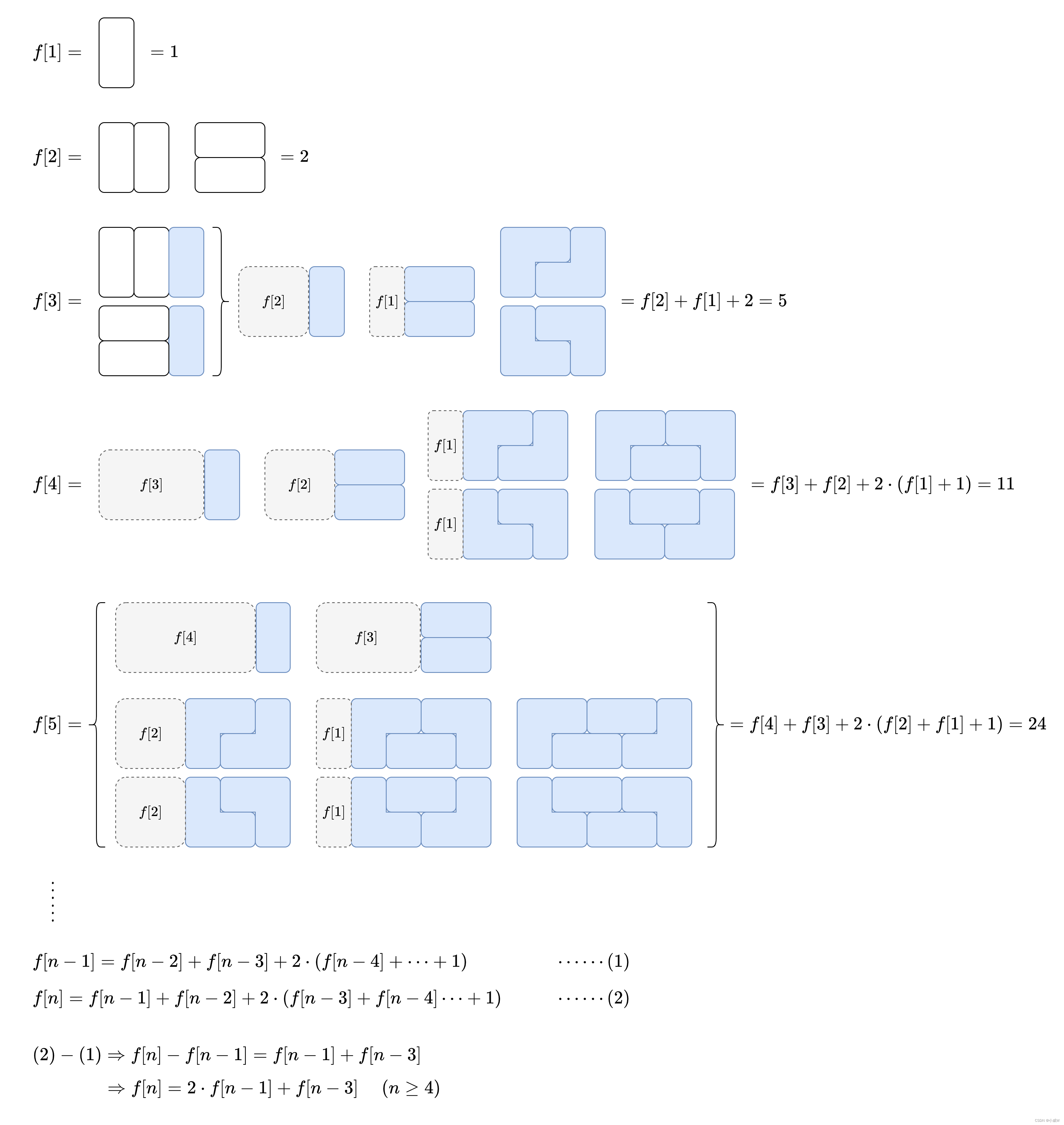
MQA 是 19 年提出的一种新的 Attention 机制,其能够在保证模型效果的同时加快 decoder 生成 token 的速度。
那到底能提升多少的速度呢,我们来看论文中给出的结果图[生成每个token消耗的时间ms]:
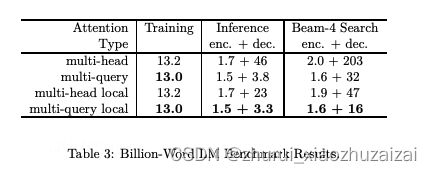
从字面上看,Multi Query Attention(MQA) 和 Multi Head Attention(MHA)只差了一个单词,
就是从「Head」变成了「Query」。
我们知道,在 transformer 中是包含若干个注意力头(head)组成的,
而每个 head 又是由: query(Q),key(K),value(V) 3 个矩阵共同实现的。
「参数共享」并不是一个很新奇的思路,在 Albert 里也有通过使用跨层共享参数(Cross-layer parameter sharing)的方式来大大减少 bert 的参数量,具体做法可以参考这里:何枝:基于BERT的几种改进模型
现在,
我们知道了 MQA 实际上是将 head 中的 key 和 value 矩阵抽出来单独存为一份共享参数,
而 query 则是依旧保留在原来的 head 中,每个 head 有一份自己独有的 query 参数。
FlashAttention V1
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
当输入序列(sequence length)较长时,Transformer的计算过程缓慢且耗费内存,这是因为self-attention的time和memory complexity会随着sequence length的增加成二次增长。
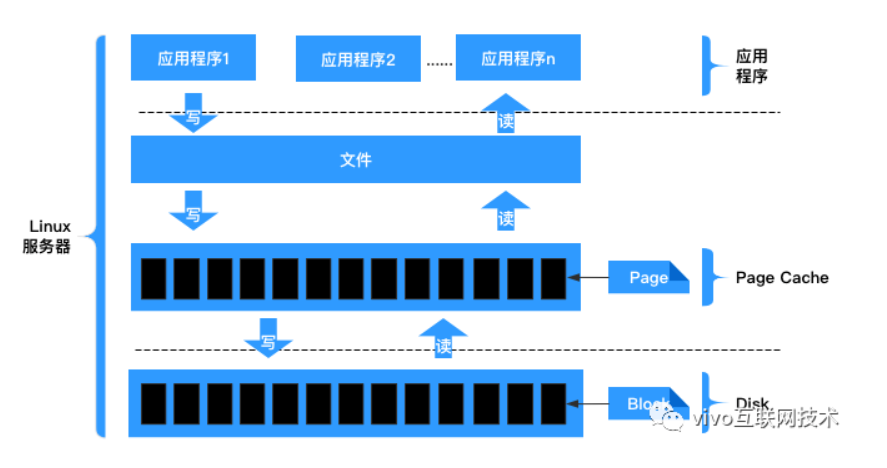
标准Attention的中间结果S,P通常需要通过高带宽内存(HBM)进行存取,两者所需内存空间复杂度为O(N2)。
FlashAttention对HBM访问的次数为O(N2d2M-1)
Attention对HBM访问的次数为O(Nd+ N2)
往往N远远大于d(例如GPT2中N=1024,d=64),因此FlashAttention会快很多。下图展示了两者在GPT-2上的Forward+Backward的GFLOPs、HBM、Runtime对比(A100 GPU):
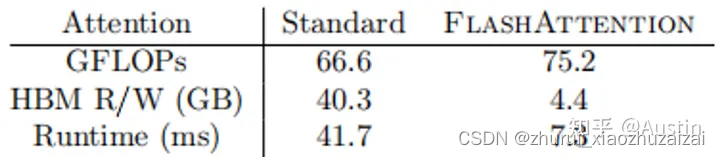
GPU中存储单元主要有HBM和SRAM:HBM容量大但是访问速度慢,SRAM容量小却有着较高的访问速度。例如:A100 GPU有40-80GB的HBM,带宽为1.5-2.0TB/s;每108个流式多核处理器各有192KB的片上SRAM,带宽估计约为19TB/s。可以看出,片上的SRAM比HBM快一个数量级,但尺寸要小许多数量级。
综上,FlashAttention目的不是节约FLOPs,而是减少对HBM的访问。重点是FlashAttention在训练和预测过程中的结果和标准Attention一样,对用户是无感的,而其他加速方法做不到这点。
对应的计算过程:
每次外循环(outer loop,j)Kj Vj载入的的大小为Bcd=768d,一共循环次Tc=2次
每次内循环(inner loop,i)载入的Qi 的大小为Brd=64d,一共循环Tr=16次(总次数还需要乘以外循环)
Sij = Qi*KjT,即为(下标表示维度):。
Pij’,表示和标准attention Pij计算的有区别,因为得到的row_max(Sij)最大值可能不是S第i行的最大值。的大小和一样,都为。
Pij’和Sij只是部分结果,如下图所示,外循环是横向(特征维d)移动的,内循环是纵向(序列维N)移动的。换句话说,外循环在顺序计算特征,内循环在顺序计算序列。
Oi的大小为Br*d,第二维d是满的(和最终一样),这意味着每次外循环都要重新更新当前批次中的特征,即虽然第一次外循环P00’*V0和第二次外循环P01’*V1都会得到O0,但是第二次的O0是基于第一次O0重新生成的。
diag(……)作用是将vector生成为一个对角矩阵,从而实现相同长度的两个vector进行element-wise相乘。
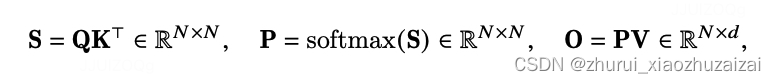





GPU 知识
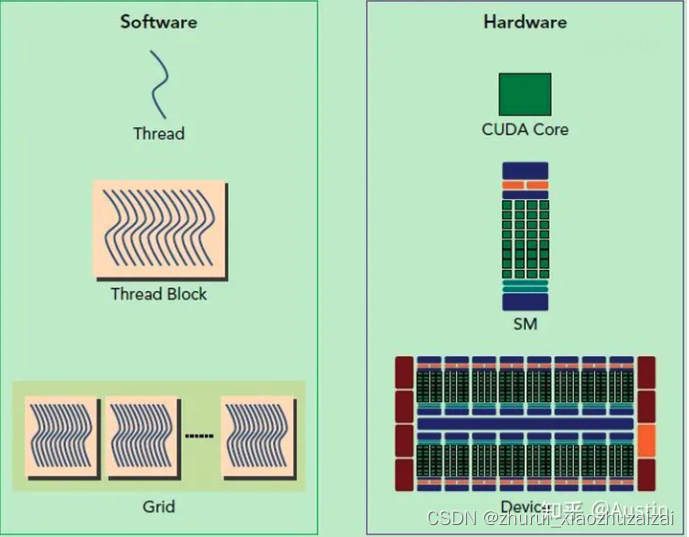
从Hardware角度来看:
Streaming Processor(SP):是最基本的处理单元,从fermi架构开始被叫做CUDA core。
Streaming MultiProcessor(SM):一个SM由多个CUDA core(SP)组成,每个SM在不同GPU架构上有不同数量的CUDA core,例如Pascal架构中一个SM有128个CUDA core。
SM还包括特殊运算单元(SFU),共享内存(shared memory),寄存器文件(Register File)和调度器(Warp Scheduler)等。register和shared memory是稀缺资源,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。
从Software(编程)角度来看:
thread:一个CUDA并行程序由多个thread来执行thread是最基本的执行单元(the basic unit of execution)。
warp:一个warp通常包含32个thread。每个warp中的thread可以同时执行相同的指令,从而实现SIMT(单指令多线程)并行。
warp是SM中最小的调度单位(the smallest scheduling unit on an SM),一个SM可以同时处理多个warp
thread block:一个thread block可以包含多个warp,同一个block中的thread可以同步,也可以通过shared memory进行通信。
thread block是GPU执行的最小单位(the smallest unit of execution on the GPU)。
一个warp中的threads必然在同一个block中,如果block所含thread数量不是warp大小的整数倍,那么多出的那个warp中会剩余一些inactive的thread。也就是说,即使warp的thread数量不足,硬件也会为warp凑足thread,只不过这些thread是inactive状态,但也会消耗SM资源。
grid: 在GPU编程中,grid是一个由多个thread block组成的二维或三维数组。grid的大小取决于计算任务的规模和thread block的大小,通常根据计算任务的特点和GPU性能来进行调整。
Hardware和Software的联系:
SM采用的是Single-Instruction Multiple-Thread(SIMT,单指令多线程)架构,warp是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。
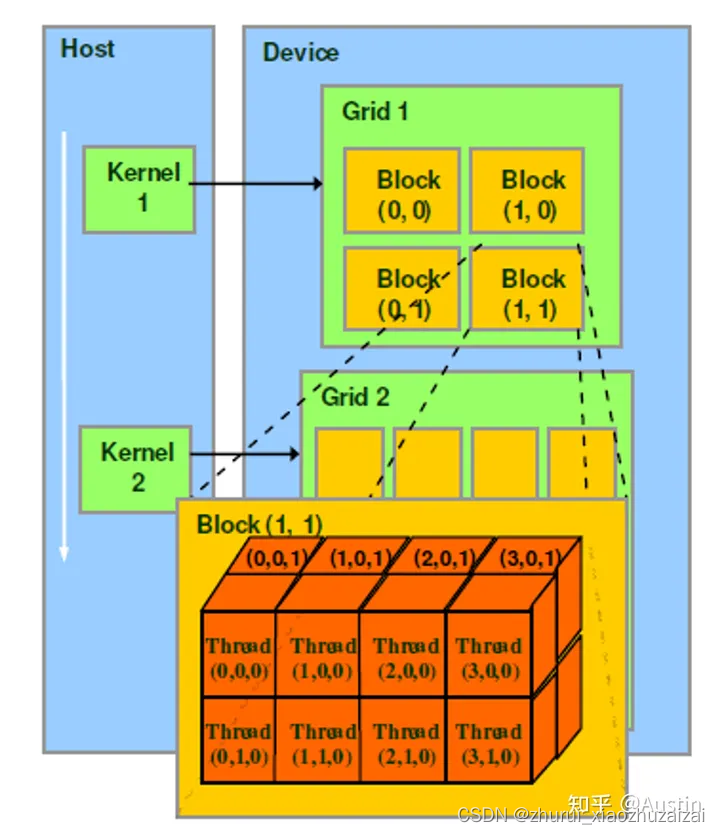
当一个kernel被执行时,grid中的thread block被分配到SM上,大量的thread可能被分到不同的SM上,但是一个线程块的thread只能在一个SM上调度,SM一般可以调度多个block。每个thread拥有自己的程序计数器和状态寄存器,并且可以使用不同的数据来执行指令,从而实现并行计算,这就是所谓的Single Instruction Multiple Thread。
一个CUDA core可以执行一个thread,一个SM中的CUDA core会被分成几个warp,由warp scheduler负责调度。GPU规定warp中所有thread在同一周期执行相同的指令,尽管这些thread执行同一程序地址,但可能产生不同的行为,比如分支结构。一个SM同时并发的warp是有限的,由于资源限制,SM要为每个block分配共享内存,也要为每个warp中的thread分配独立的寄存器,所以SM的配置会影响其所支持的block和warp并发数量。
GPU执行模型小结:
GPU有大量的threads用于执行操作(an operation,也称为a kernel)。这些thread组成了thread block,接着这些blocks被调度在SMs上运行。在每个thread block中,threads被组成了warps(32个threads为一组)。一个warp内的threads可以通过快速shuffle指令进行通信或者合作执行矩阵乘法。在每个thread block内部,warps可以通过读取/写入共享内存进行通信。每个kernel从HBM加载数据到寄存器和SRAM中,进行计算,最后将结果写回HBM中。
FlashAttention V2
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
FlashAttention利用GPU非匀称的存储器层次结构,实现了显著的内存节省(从平方增加转为线性增加)和计算加速(提速2-4倍),而且计算结果保持一致。但是,FlashAttention仍然不如优化的矩阵乘法(GEMM)操作快,只达到理论最大FLOPs/s的25-40%。作者观察到,这种低效是由于GPU对不同thread blocks和warps工作分配不是最优的,造成了利用率低和不必要的共享内存读写。因此,本文提出了FlashAttention-2以解决这些问题。
虽然相比标准Attention,FlashAttention快了24倍,节约了1020倍内存,但是离设备理论最大throughput和flops还差了很多。本文提出了FlashAttention-2,它具有更好的并行性和工作分区。实验结果显示,FlashAttention-2在正向传递中实现了约2倍的速度提升,达到了理论最大吞吐量的73%,在反向传递中达到了理论最大吞吐量的63%。在每个A100 GPU上的训练速度可达到225 TFLOPs/s。
本文主要贡献和创新点为:减少了non-matmul FLOPs的数量(消除了原先频繁rescale)。虽然non-matmul FLOPs仅占总FLOPs的一小部分,但它们的执行时间较长,这是因为GPU有专用的矩阵乘法计算单元,其吞吐量高达非矩阵乘法吞吐量的16倍。因此,减少non-matmul FLOPs并尽可能多地执行matmul FLOPs非常重要。
提出了在序列长度维度上并行化。该方法在输入序列很长(此时batch size通常很小)的情况下增加了GPU利用率。即使对于单个head,也在不同的thread block之间进行并行计算。
在一个attention计算块内,将工作分配在一个thread block的不同warp上,以减少通信和共享内存读/写。
Causal masking是attention的一个常见操作,特别是在自回归语言建模中,需要对注意力矩阵S应用因果掩码(即任何S ,其中 > 的条目都设置为−∞)。
由于FlashAttention和FlashAttention-2已经通过块操作来实现,对于所有列索引都大于行索引的块(大约占总块数的一半),我们可以跳过该块的计算。这比没有应用因果掩码的注意力计算速度提高了1.7-1.8倍。
不需要对那些行索引严格小于列索引的块应用因果掩码。这意味着对于每一行,我们只需要对1个块应用因果掩码。

并行处理
FlashAttention在batch和heads两个维度上进行了并行化:使用一个thread block来处理一个attention head,总共需要thread block的数量等于batch size × number of heads。每个block被调到到一个SM上运行,例如A100 GPU上有108个SMs。当block数量很大时(例如≥80),这种调度方式是高效的,因为几乎可以有效利用GPU上所有计算资源。
但是在处理长序列输入时,由于内存限制,通常会减小batch size和head数量,这样并行化成都就降低了。因此,FlashAttention-2还在序列长度这一维度上进行并行化,显著提升了计算速度。此外,当batch size和head数量较小时,在序列长度上增加并行性有助于提高GPU占用率。
Forward pass. FlashAttention算法有两个循环,K,V在外循环,Q,O在内循环。FlashAttention-2将Q移到了外循环i,K,V移到了内循环j,由于改进了算法使得warps之间不再需要相互通信去处理Qi,所以外循环可以放在不同的thread block上。这个交换的优化方法是由Phil Tillet在Triton[17]提出并实现的。
转载于:https://zhuanlan.zhihu.com/p/645376942