说明:
1.Hadoop版本:3.1.3
2.阅读工具:IDEA 2023.1.2
3.源码获取:Index of /dist/hadoop/core/hadoop-3.1.3 (apache.org)
4.工程导入:下载源码之后得到hadoop-3.1.3-src.tar.gz压缩包,在当前目录打开PowerShell,使用tar -zxvf指令解压即可,然后使用IDEA打开hadoop-3.1.3-src文件夹,要注意配置好Maven或Gradle仓库,否则jar包导入会比较慢
5.参考课程:www.bilibili.com/video/BV1Qp…
HDFS上传

一个简单的上传代码:
public void test() throws IOException {
FSDataOutputStream fos = fs.create(new Path("/input"));
fos.write("hello world".getBytes());
}可以看到,首先创建了一个
FSDataOutputStream,然后向其中写数据; 接下来就分为 create创建过程 和 write上传过程 分别进行源码阅读解析
create创建过程
1.客户端向NN发送创建请求
首先进入create方法中,来到FileSystem.java:

找到create方法,继续进入,直到找到静态方法create:

因此返回到该静态方法的调用:
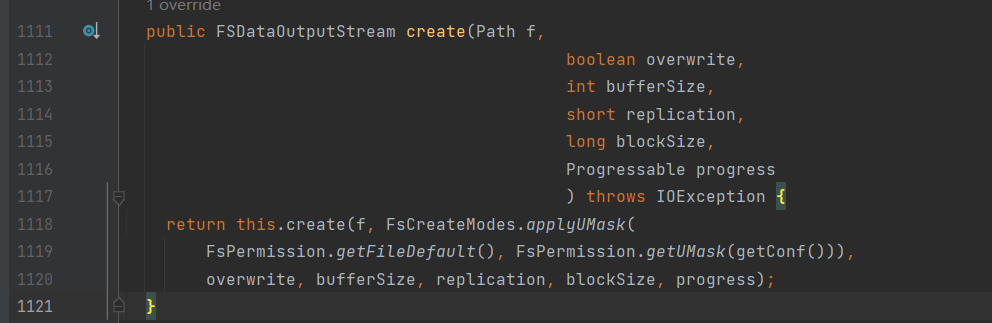
ctrl+alt+B查找该静态方法的实现类:
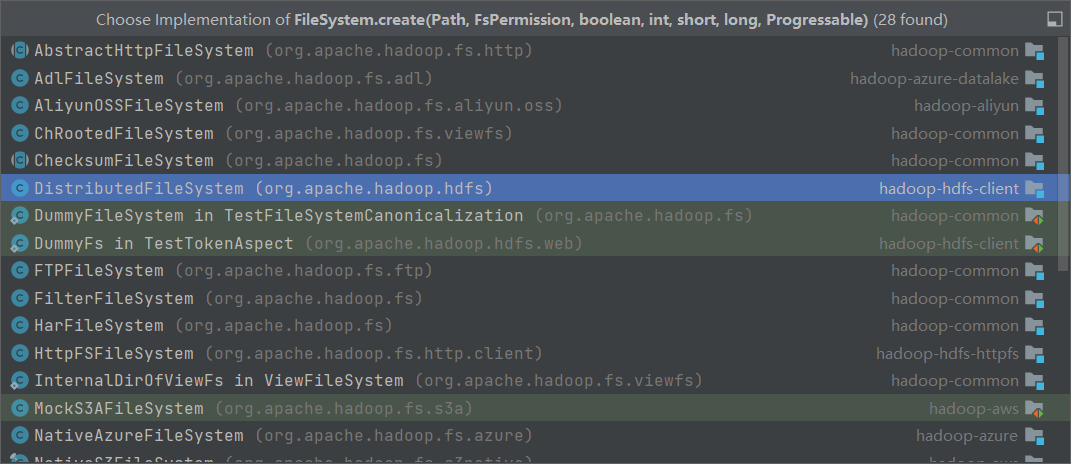
进入DistributedFileSystem中:

继续向下查找:

可以看到在doCall方法中创建了一个输出流对象;
继续进入create方法,来到DFSClient.java中:

不断向下查找,找到newStreamForCreate方法:
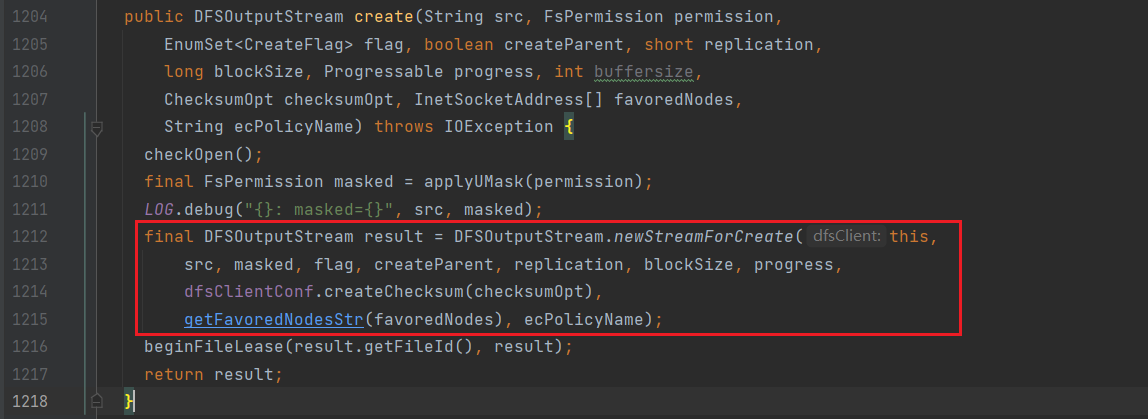
进入newStreamForCreate方法,来到DFSOutputStream.java

这里客户端将创建请求通过RPC通信发送给NN进行处理
开启线程
2.NN处理来自客户端的创建请求
newStreamForCreate方法中进入create方法,来到ClientProtocol.java:

查找其实现类:

进入NameNodeRpcServer,create方法如下:
@Override // ClientProtocol
public HdfsFileStatus create(String src, FsPermission masked,
String clientName, EnumSetWritable<CreateFlag> flag,
boolean createParent, short replication, long blockSize,
CryptoProtocolVersion[] supportedVersions, String ecPolicyName)
throws IOException {
checkNNStartup(); //检查NN是否启动
String clientMachine = getClientMachine();
if (stateChangeLog.isDebugEnabled()) {
stateChangeLog.debug("*DIR* NameNode.create: file "
+src+" for "+clientName+" at "+clientMachine);
}
if (!checkPathLength(src)) { //检查路径长度
throw new IOException("create: Pathname too long. Limit "
+ MAX_PATH_LENGTH + " characters, " + MAX_PATH_DEPTH + " levels.");
}
namesystem.checkOperation(OperationCategory.WRITE);
CacheEntryWithPayload cacheEntry = RetryCache.waitForCompletion(retryCache, null);
if (cacheEntry != null && cacheEntry.isSuccess()) { //缓存相关检查
return (HdfsFileStatus) cacheEntry.getPayload();
}
HdfsFileStatus status = null;
try {
PermissionStatus perm = new PermissionStatus(getRemoteUser()
.getShortUserName(), null, masked);
//开启文件(重要)
status = namesystem.startFile(src, perm, clientName, clientMachine,
flag.get(), createParent, replication, blockSize, supportedVersions,
ecPolicyName, cacheEntry != null);
} finally {
RetryCache.setState(cacheEntry, status != null, status);
}
metrics.incrFilesCreated();
metrics.incrCreateFileOps();
return status;
}接下来进入startFile方法,来到FSNamesystem.java:
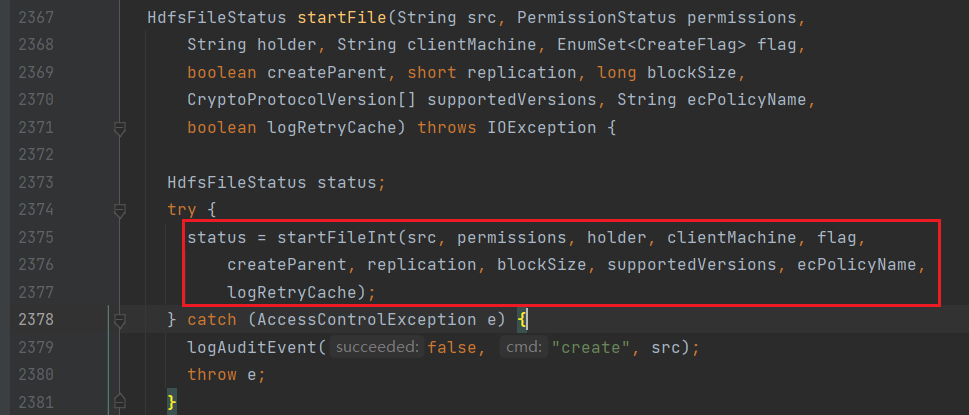
进入startFileInt:

将src(文件路径)封装到INodesInPath中;
对于INodesInPath类的解释:Contains INodes information resolved from a given path.
首先我们需要明确INodes类的概念:
INodes是一个抽象类,官方对于其的解释如下:

简单来说一个基本的INode类是一种保留在内存中的文件/块层次结构的表示形式,包含文件和目录索引节点的公共字段
可以看到INodes是最底层的一个类,保存一些文件目录共有的属性,而INodesInPath类则保存了从给定的路径解析出的INode信息;
接下来定位到startFile:

进入startFile
- 首先对文件路径是否存在进行校验:
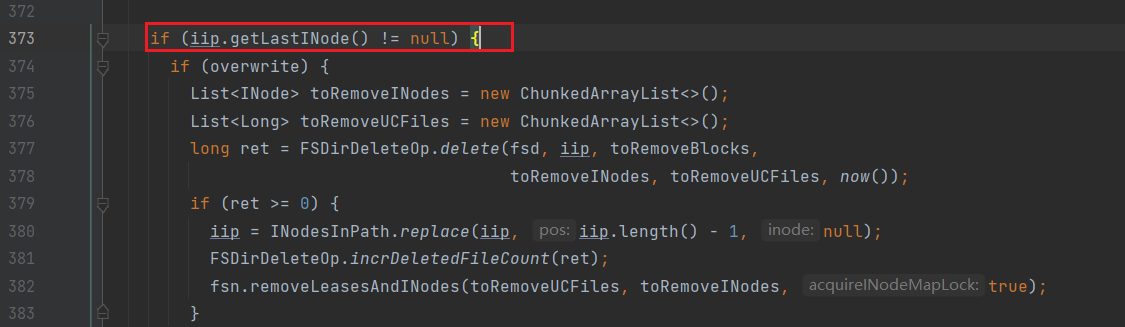
进入getLastINode:

进入getINode:

可以看到,i=-1时,return inodes[inodes.length-1];
也就是说,获取最后位置上的inode,如果有,说明文件路径已经存在;
接下来再判断是否允许覆写:

如果不允许覆写,则会抛出异常,告知文件路径已存在,不允许重复上传文件;
- 然后判断是否存在父目录:

如果父目录存在,则向其中添加文件元数据信息(addFile方法)
进入addFile方法:

进入addINode:
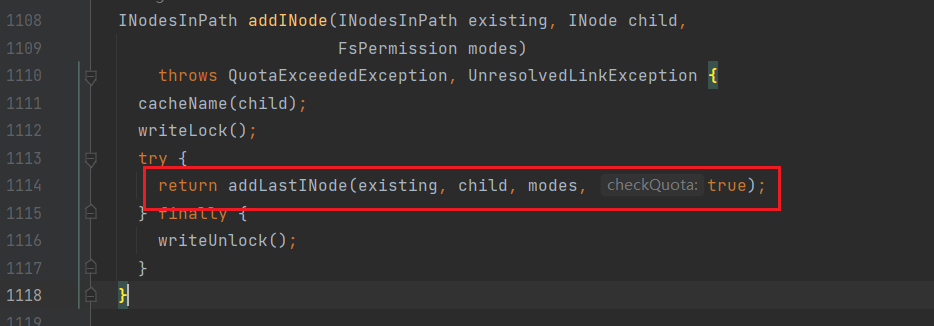
将数据写入到INode的目录树中;至此文件目录创建完毕
3.DataStreamer启动流程
NN处理完成后,再次回到客户端,启动相应线程;
打开DFSOutputStream.java,找到newStreamForCreate方法,NN完成创建请求后,进行输出流的创建:

定位到DFSOutputStream:
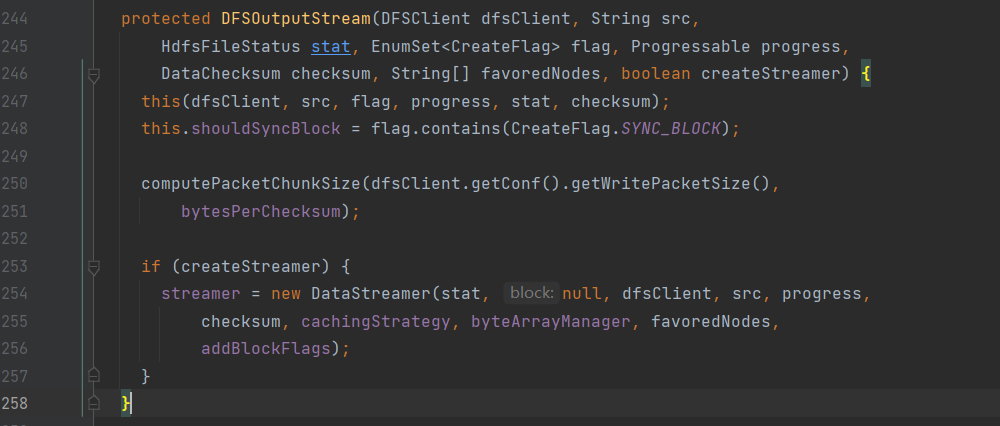
计算chunk大小(Directory => File => Block(128M) => packet(64K) => chunk(chunk 512byte + chunksum 4byte))
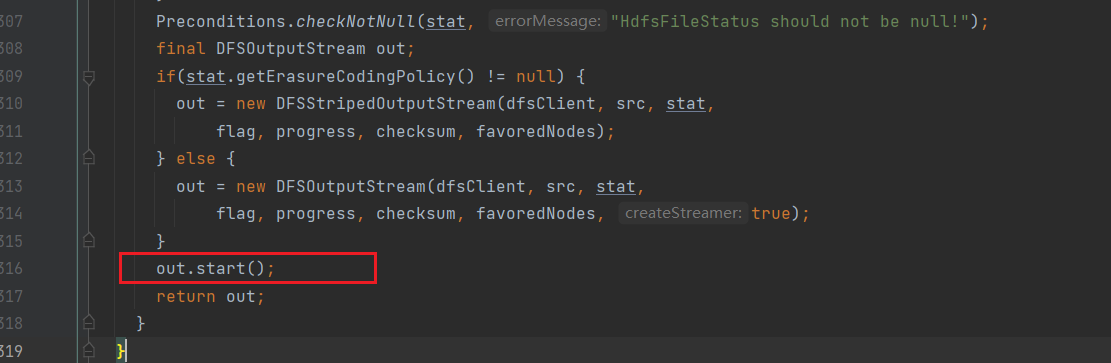
返回到newStreamForCreate方法,进入out.start()

继续进入:

继续进入DataStreamer:

进入Daemon:

可以看到,out.start方法开启了一个线程,因此回到DataStreamer,搜索run方法:

如果dataQueue中没有数据,代码会进行阻塞;
如果dataQueue不为空,则从其中取出packet
write上传过程
1.向DataStreamer的队列里面写数据
create阶段启动了DataStreamer,在write阶段向其中写数据;
进入write方法,到FilterOutputStream.java中:

一直前进,直到抽象方法write:
![]()
ctrl+alt+B查找其实现类:

进入FSOutputSummer.java,定位到write方法:

进入flushBuffer方法,顾名思义即为刷写缓冲区:

进入writeChecksumChunks方法:

进入writeChunk方法(将chunk写入数据队列):

是一个抽象方法,因此查找其实现类:

进入DFSOutputStream.java,查看writeChunk方法的具体实现逻辑,如下:
@Override
protected synchronized void writeChunk(byte[] b, int offset, int len,
byte[] checksum, int ckoff, int cklen) throws IOException {
writeChunkPrepare(len, ckoff, cklen);
currentPacket.writeChecksum(checksum, ckoff, cklen); //往packet里面写chunk的校验和 4byte
currentPacket.writeData(b, offset, len); // 往packet里面写一个chunk 512byte
// 记录写入packet中的chunk个数,累计到127个chuck,这个packet就满了
currentPacket.incNumChunks();
getStreamer().incBytesCurBlock(len);
//如果packet已经满了,则将其放入队列等待传输
if (currentPacket.getNumChunks() == currentPacket.getMaxChunks() ||
getStreamer().getBytesCurBlock() == blockSize) {
enqueueCurrentPacketFull();
}
}进入enqueueCurrentPacketFull方法:
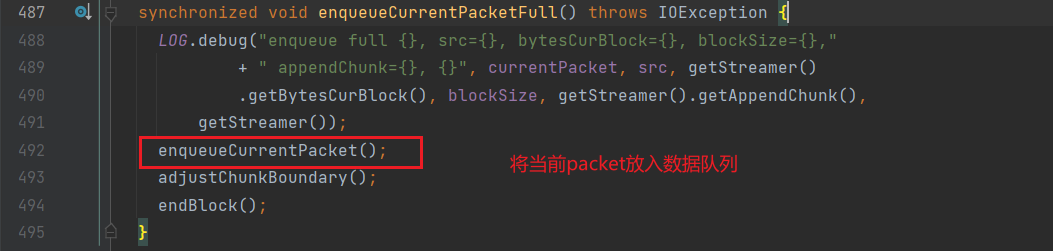
进入enqueueCurrentPacket方法:

进入waitAndQueuePacket方法:
void waitAndQueuePacket(DFSPacket packet) throws IOException {
synchronized (dataQueue) {
try {
// 如果队列满了,则等待
boolean firstWait = true;
try {
while (!streamerClosed && dataQueue.size() + ackQueue.size() >
dfsClient.getConf().getWriteMaxPackets()) {
if (firstWait) {
Span span = Tracer.getCurrentSpan();
if (span != null) {
span.addTimelineAnnotation("dataQueue.wait");
}
firstWait = false;
}
try {
dataQueue.wait(); //等待队列有充足的空间
} catch (InterruptedException e) {
// If we get interrupted while waiting to queue data, we still need to get rid
// of the current packet. This is because we have an invariant that if
// currentPacket gets full, it will get queued before the next writeChunk.
//
// Rather than wait around for space in the queue, we should instead try to
// return to the caller as soon as possible, even though we slightly overrun
// the MAX_PACKETS length.
Thread.currentThread().interrupt();
break;
}
}
} finally {
Span span = Tracer.getCurrentSpan();
if ((span != null) && (!firstWait)) {
span.addTimelineAnnotation("end.wait");
}
}
checkClosed();
//如果队列没满,则向队列中添加数据
queuePacket(packet);
} catch (ClosedChannelException ignored) {
}
}
}进入queuePacket方法(向队列中添加数据的逻辑),来到DataStreamer.java中:

2.建立管道
2.1机架感知(确定block的存储位置)
Ctrl + n全局查找DataStreamer,搜索run方法:
@Override
public void run() {
long lastPacket = Time.monotonicNow();
TraceScope scope = null;
while (!streamerClosed && dfsClient.clientRunning) {
// if the Responder encountered an error, shutdown Responder
if (errorState.hasError()) {
closeResponder();
}
DFSPacket one;
try {
// process datanode IO errors if any
boolean doSleep = processDatanodeOrExternalError();
final int halfSocketTimeout = dfsClient.getConf().getSocketTimeout()/2;
//步骤一:等待要发送的packet到来
synchronized (dataQueue) {
// wait for a packet to be sent.
long now = Time.monotonicNow();
while ((!shouldStop() && dataQueue.size() == 0 &&
(stage != BlockConstructionStage.DATA_STREAMING ||
now - lastPacket < halfSocketTimeout)) || doSleep) {
long timeout = halfSocketTimeout - (now-lastPacket);
timeout = timeout <= 0 ? 1000 : timeout;
timeout = (stage == BlockConstructionStage.DATA_STREAMING)?
timeout : 1000;
try {
//如果dataQueue中没有数据,代码会阻塞在这里
dataQueue.wait(timeout);
} catch (InterruptedException e) {
LOG.warn("Caught exception", e);
}
doSleep = false;
now = Time.monotonicNow();
}
if (shouldStop()) {
continue;
}
// 获取要发送的数据包
if (dataQueue.isEmpty()) {
one = createHeartbeatPacket();
}
else {
try {
backOffIfNecessary();
} catch (InterruptedException e) {
LOG.warn("Caught exception", e);
}
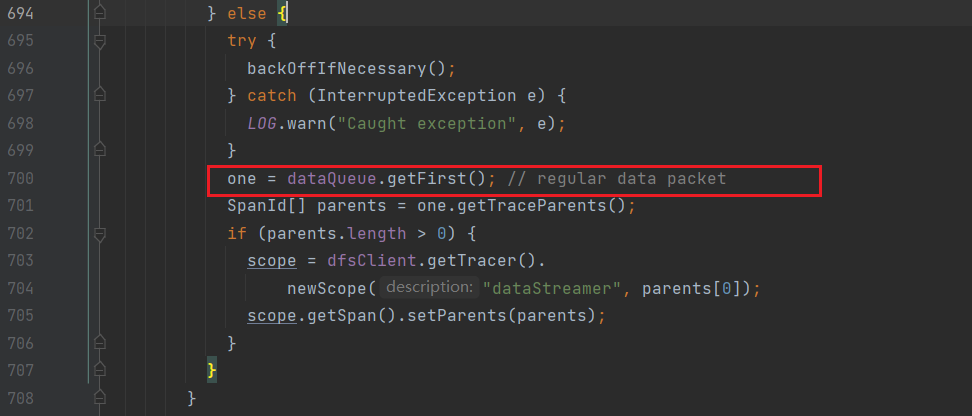
//如果数据队列不为空,则从其中取出packet
one = dataQueue.getFirst();
SpanId[] parents = one.getTraceParents();
if (parents.length > 0) {
scope = dfsClient.getTracer().
newScope("dataStreamer", parents[0]);
scope.getSpan().setParents(parents);
}
}
}
//步骤二:从NN获取新的block
if (LOG.isDebugEnabled()) {
LOG.debug("stage=" + stage + ", " + this);
}
if (stage == BlockConstructionStage.PIPELINE_SETUP_CREATE) {
LOG.debug("Allocating new block: {}", this);
//向NN申请block并建立数据管道(Pipeline)
setPipeline(nextBlockOutputStream());
//启动ResponseProcessor用来监听packet发送是否成功
initDataStreaming();
} else if (stage == BlockConstructionStage.PIPELINE_SETUP_APPEND) {
LOG.debug("Append to block {}", block);
setupPipelineForAppendOrRecovery();
if (streamerClosed) {
continue;
}
initDataStreaming();
}
long lastByteOffsetInBlock = one.getLastByteOffsetBlock();
if (lastByteOffsetInBlock > stat.getBlockSize()) {
throw new IOException("BlockSize " + stat.getBlockSize() +
" < lastByteOffsetInBlock, " + this + ", " + one);
}
if (one.isLastPacketInBlock()) {
// wait for all data packets have been successfully acked
synchronized (dataQueue) {
while (!shouldStop() && ackQueue.size() != 0) {
try {
// wait for acks to arrive from datanodes
dataQueue.wait(1000);
} catch (InterruptedException e) {
LOG.warn("Caught exception", e);
}
}
}
if (shouldStop()) {
continue;
}
stage = BlockConstructionStage.PIPELINE_CLOSE;
}
// 步骤三:发送packet
SpanId spanId = SpanId.INVALID;
synchronized (dataQueue) {
// move packet from dataQueue to ackQueue
if (!one.isHeartbeatPacket()) {
if (scope != null) {
spanId = scope.getSpanId();
scope.detach();
one.setTraceScope(scope);
}
scope = null;
dataQueue.removeFirst(); //从dataQueue 把要发送的这个packet 移除出去
ackQueue.addLast(one); //ackQueue 里面添加这个packet
packetSendTime.put(one.getSeqno(), Time.monotonicNow());
dataQueue.notifyAll();
}
}
LOG.debug("{} sending {}", this, one);
// 步骤四:向DN中写数据
try (TraceScope ignored = dfsClient.getTracer().
newScope("DataStreamer#writeTo", spanId)) {
one.writeTo(blockStream); //写出数据
blockStream.flush();
} catch (IOException e) {
// HDFS-3398 treat primary DN is down since client is unable to
// write to primary DN. If a failed or restarting node has already
// been recorded by the responder, the following call will have no
// effect. Pipeline recovery can handle only one node error at a
// time. If the primary node fails again during the recovery, it
// will be taken out then.
errorState.markFirstNodeIfNotMarked();
throw e;
}
lastPacket = Time.monotonicNow();
// update bytesSent
long tmpBytesSent = one.getLastByteOffsetBlock();
if (bytesSent < tmpBytesSent) {
bytesSent = tmpBytesSent;
}
if (shouldStop()) {
continue;
}
// Is this block full?
if (one.isLastPacketInBlock()) {
// wait for the close packet has been acked
synchronized (dataQueue) {
while (!shouldStop() && ackQueue.size() != 0) {
dataQueue.wait(1000);// wait for acks to arrive from datanodes
}
}
if (shouldStop()) {
continue;
}
endBlock();
}
if (progress != null) { progress.progress(); }
// This is used by unit test to trigger race conditions.
if (artificialSlowdown != 0 && dfsClient.clientRunning) {
Thread.sleep(artificialSlowdown);
}
} catch (Throwable e) {
// Log warning if there was a real error.
if (!errorState.isRestartingNode()) {
// Since their messages are descriptive enough, do not always
// log a verbose stack-trace WARN for quota exceptions.
if (e instanceof QuotaExceededException) {
LOG.debug("DataStreamer Quota Exception", e);
} else {
LOG.warn("DataStreamer Exception", e);
}
}
lastException.set(e);
assert !(e instanceof NullPointerException);
errorState.setInternalError();
if (!errorState.isNodeMarked()) {
// Not a datanode issue
streamerClosed = true;
}
} finally {
if (scope != null) {
scope.close();
scope = null;
}
}
}
closeInternal();
}进入nextBlockOutputStream(第68行):

进入locateFollowingBlock:

进入addBlock:

进入addBlock,来到ClientProtocol类:

因此可以判断,该方法是通过NN的客户端代理来实现的
查找其实现类:

进入NameNodeRpcServer,定位到addBlock:

进入getAdditionalBlock:

选择block的存储位置;
进入chooseTargetForNewBlock:

进入chooseTarget4NewBlock:

进入chooseTarget:

继续进入chooseTarget:
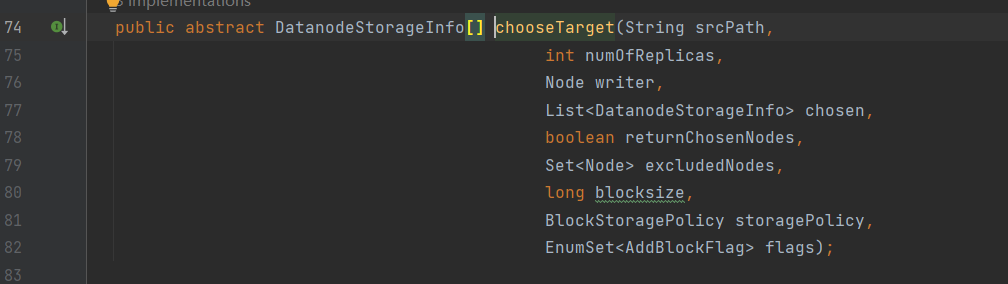
可以看到其是一个抽象类,因此查找其实现类:

进入BlockPlacementPolicyDefault.java:

进入chooseTarget:

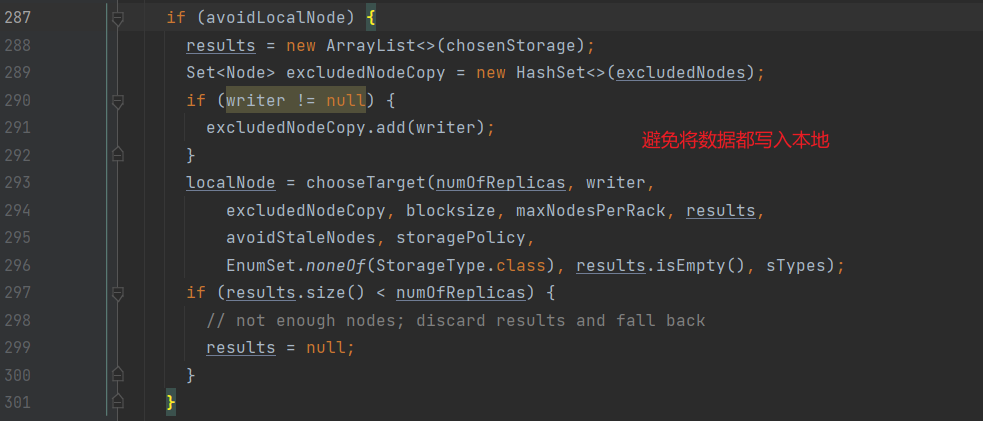

进入chooseTarget:

进入chooseTargetInOrder,即机架感知的逻辑:
protected Node chooseTargetInOrder(int numOfReplicas,
Node writer,
final Set<Node> excludedNodes,
final long blocksize,
final int maxNodesPerRack,
final List<DatanodeStorageInfo> results,
final boolean avoidStaleNodes,
final boolean newBlock,
EnumMap<StorageType, Integer> storageTypes)
throws NotEnoughReplicasException {
final int numOfResults = results.size();
if (numOfResults == 0) {
//第一个block存储在当前节点
DatanodeStorageInfo storageInfo = chooseLocalStorage(writer,
excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes,
storageTypes, true);
writer = (storageInfo != null) ? storageInfo.getDatanodeDescriptor()
: null;
if (--numOfReplicas == 0) {
return writer;
}
}
final DatanodeDescriptor dn0 = results.get(0).getDatanodeDescriptor();
if (numOfResults <= 1) {
//第二个block存储在另外一个机架
chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
if (--numOfReplicas == 0) {
return writer;
}
}
if (numOfResults <= 2) {
final DatanodeDescriptor dn1 = results.get(1).getDatanodeDescriptor();
if (clusterMap.isOnSameRack(dn0, dn1)) {
//如果第一个和第二个在同一个机架,那么第三个放在其他机架
chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
} else if (newBlock){
//如果是新块,和第二个块存储在同一个机架
chooseLocalRack(dn1, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
} else {
//如果不是新块,放在当前机架
chooseLocalRack(writer, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
}
if (--numOfReplicas == 0) {
return writer;
}
}
chooseRandom(numOfReplicas, NodeBase.ROOT, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, storageTypes);
return writer;
}2.2 socket发送
回到nextBlockOutputStream:

进入createBlockOutputStream:

从注释可以看出,该方法的主要功能是和管道中的第一个DN建立连接;
boolean createBlockOutputStream(DatanodeInfo[] nodes,
StorageType[] nodeStorageTypes, String[] nodeStorageIDs,
long newGS, boolean recoveryFlag) {
if (nodes.length == 0) {
LOG.info("nodes are empty for write pipeline of " + block);
return false;
}
String firstBadLink = "";
boolean checkRestart = false;
if (LOG.isDebugEnabled()) {
LOG.debug("pipeline = " + Arrays.toString(nodes) + ", " + this);
}
// persist blocks on namenode on next flush
persistBlocks.set(true);
int refetchEncryptionKey = 1;
while (true) {
boolean result = false;
DataOutputStream out = null;
try {
assert null == s : "Previous socket unclosed";
assert null == blockReplyStream : "Previous blockReplyStream unclosed";
//和DN创建socket连接
s = createSocketForPipeline(nodes[0], nodes.length, dfsClient);
long writeTimeout = dfsClient.getDatanodeWriteTimeout(nodes.length);
long readTimeout = dfsClient.getDatanodeReadTimeout(nodes.length);
//输出流,用于写数据到DN
OutputStream unbufOut = NetUtils.getOutputStream(s, writeTimeout);
//输入流,用于读取写数据到DN的结果
InputStream unbufIn = NetUtils.getInputStream(s, readTimeout);
IOStreamPair saslStreams = dfsClient.saslClient.socketSend(s,
unbufOut, unbufIn, dfsClient, accessToken, nodes[0]);
unbufOut = saslStreams.out;
unbufIn = saslStreams.in;
out = new DataOutputStream(new BufferedOutputStream(unbufOut,
DFSUtilClient.getSmallBufferSize(dfsClient.getConfiguration())));
blockReplyStream = new DataInputStream(unbufIn);
//
// Xmit header info to datanode
//
BlockConstructionStage bcs = recoveryFlag ?
stage.getRecoveryStage() : stage;
// We cannot change the block length in 'block' as it counts the number
// of bytes ack'ed.
ExtendedBlock blockCopy = block.getCurrentBlock();
blockCopy.setNumBytes(stat.getBlockSize());
boolean[] targetPinnings = getPinnings(nodes);
// 发送数据
new Sender(out).writeBlock(blockCopy, nodeStorageTypes[0], accessToken,
dfsClient.clientName, nodes, nodeStorageTypes, null, bcs,
nodes.length, block.getNumBytes(), bytesSent, newGS,
checksum4WriteBlock, cachingStrategy.get(), isLazyPersistFile,
(targetPinnings != null && targetPinnings[0]), targetPinnings,
nodeStorageIDs[0], nodeStorageIDs);
// receive ack for connect
BlockOpResponseProto resp = BlockOpResponseProto.parseFrom(
PBHelperClient.vintPrefixed(blockReplyStream));
Status pipelineStatus = resp.getStatus();
firstBadLink = resp.getFirstBadLink();
// Got an restart OOB ack.
// If a node is already restarting, this status is not likely from
// the same node. If it is from a different node, it is not
// from the local datanode. Thus it is safe to treat this as a
// regular node error.
if (PipelineAck.isRestartOOBStatus(pipelineStatus) &&
!errorState.isRestartingNode()) {
checkRestart = true;
throw new IOException("A datanode is restarting.");
}
String logInfo = "ack with firstBadLink as " + firstBadLink;
DataTransferProtoUtil.checkBlockOpStatus(resp, logInfo);
assert null == blockStream : "Previous blockStream unclosed";
blockStream = out;
result = true; // success
errorState.resetInternalError();
lastException.clear();
// remove all restarting nodes from failed nodes list
failed.removeAll(restartingNodes);
restartingNodes.clear();
} catch (IOException ie) {
if (!errorState.isRestartingNode()) {
LOG.info("Exception in createBlockOutputStream " + this, ie);
}
if (ie instanceof InvalidEncryptionKeyException &&
refetchEncryptionKey > 0) {
LOG.info("Will fetch a new encryption key and retry, "
+ "encryption key was invalid when connecting to "
+ nodes[0] + " : " + ie);
// The encryption key used is invalid.
refetchEncryptionKey--;
dfsClient.clearDataEncryptionKey();
// Don't close the socket/exclude this node just yet. Try again with
// a new encryption key.
continue;
}
// find the datanode that matches
if (firstBadLink.length() != 0) {
for (int i = 0; i < nodes.length; i++) {
// NB: Unconditionally using the xfer addr w/o hostname
if (firstBadLink.equals(nodes[i].getXferAddr())) {
errorState.setBadNodeIndex(i);
break;
}
}
} else {
assert !checkRestart;
errorState.setBadNodeIndex(0);
}
final int i = errorState.getBadNodeIndex();
// Check whether there is a restart worth waiting for.
if (checkRestart) {
errorState.initRestartingNode(i,
"Datanode " + i + " is restarting: " + nodes[i],
shouldWaitForRestart(i));
}
errorState.setInternalError();
lastException.set(ie);
result = false; // error
} finally {
if (!result) {
IOUtils.closeSocket(s);
s = null;
IOUtils.closeStream(out);
IOUtils.closeStream(blockReplyStream);
blockReplyStream = null;
}
}
return result;
}
}进入writeBlock:
![]()
进入send:

通过flush刷写数据;
2.3.socket接收
数据接收是DN的任务,因此进入DataXceiverServer.java,定位到run方法:
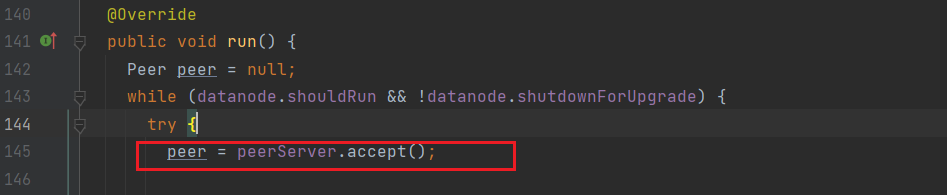
接收socket请求;

客户端每发送一个block,都启动一个DataXceiver去处理block
进入DataXceiver,定位到run方法:
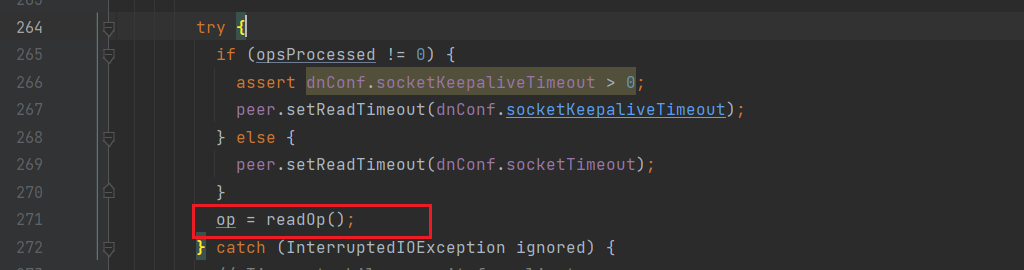
读取数据的操作类型;
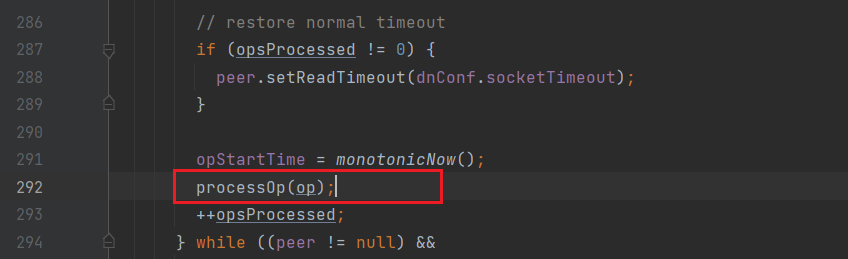
根据操作类型处理数据;
进入processOp:
可以看到不同的操作类型
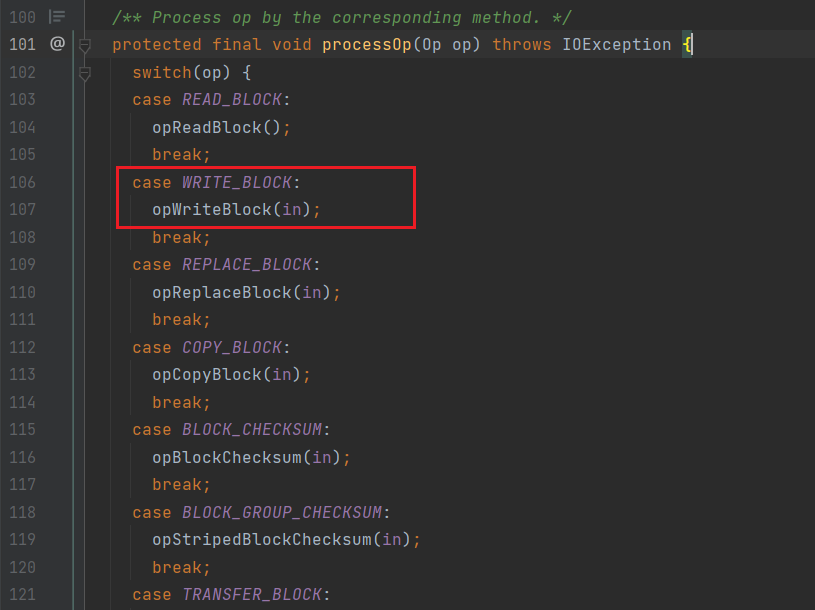
进入opWriteBlock(写数据):
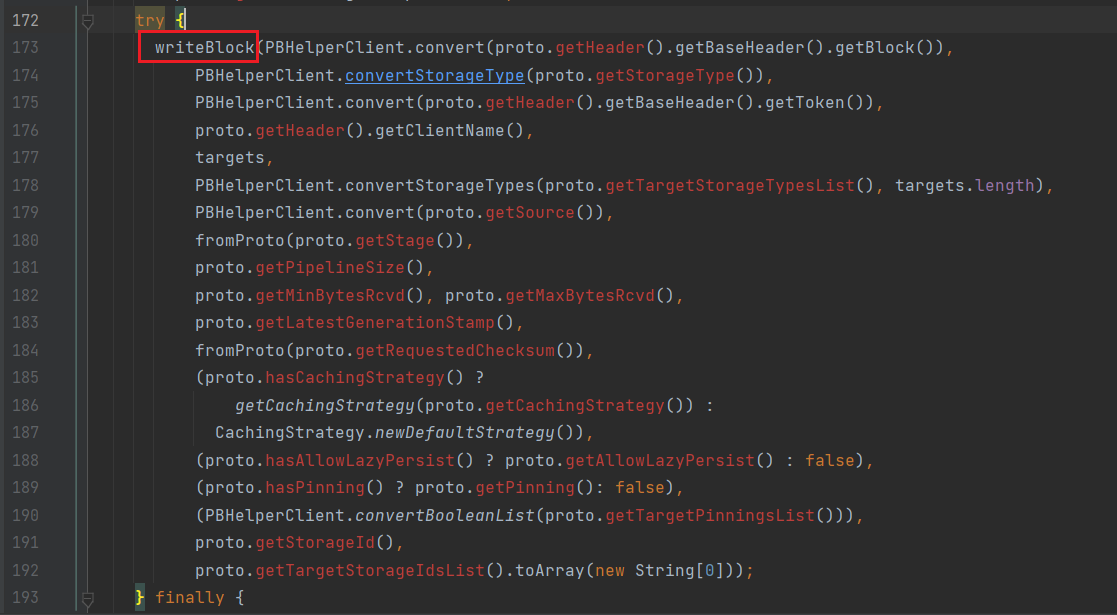
Ctrl +alt +b 查找writeBlock的实现类,进入DataXceiver.java:
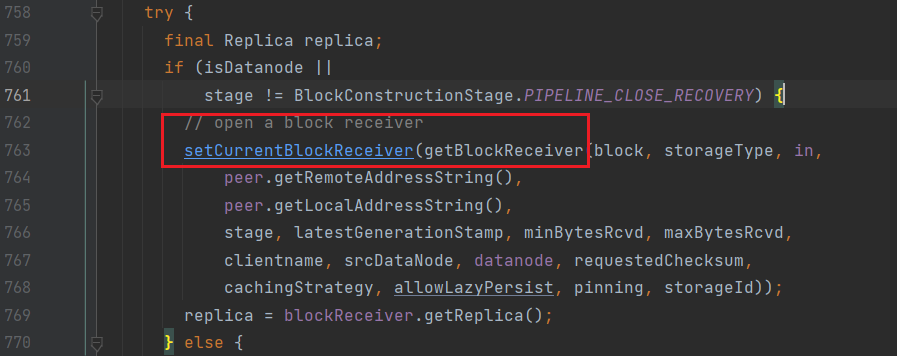
创建一个BlockReceiver;

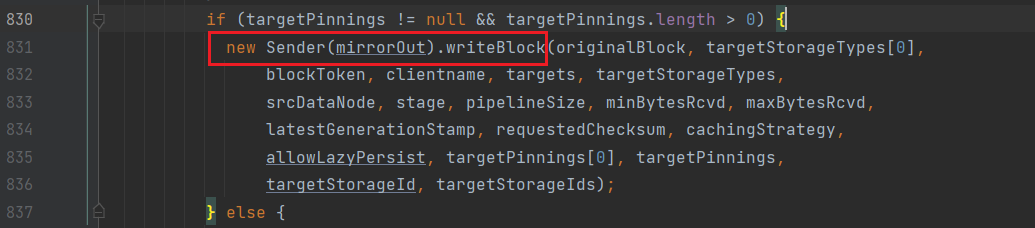
向下游socket中发送数据
接下来进入getBlockReceiver:

进入BlockReceiver:
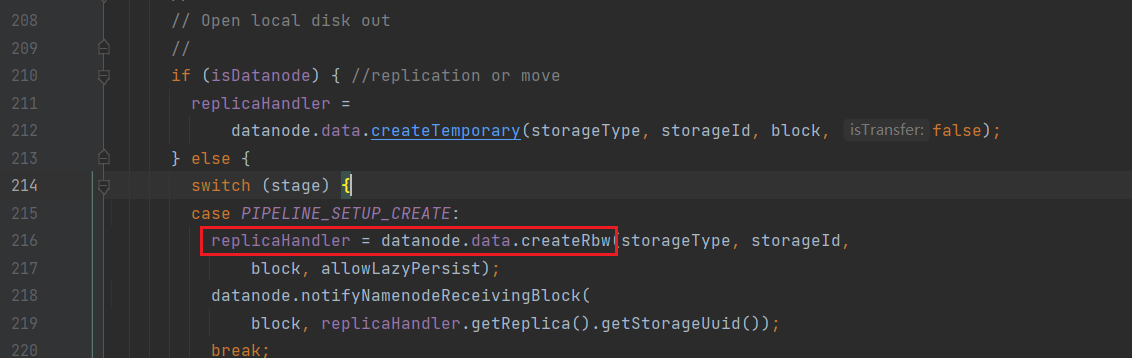
创建管道;
进入createRbw:

进入FsDatasetImpl.java:

进入createRbw:
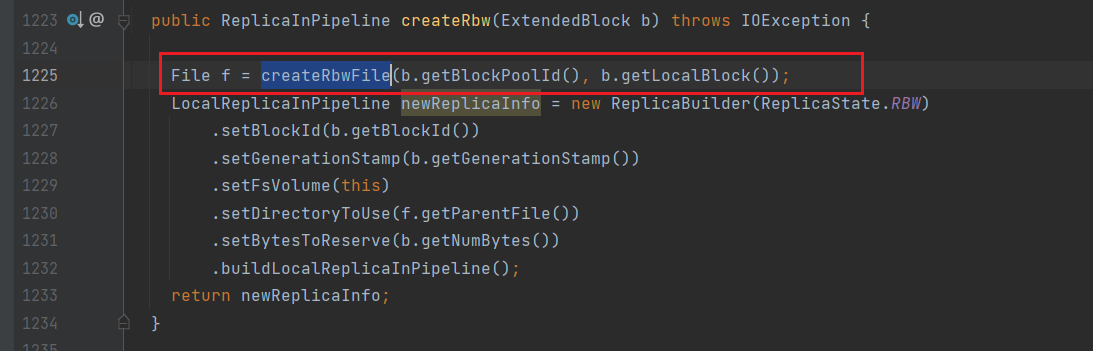
通过createRbwFile创建file
3.客户端接收DN的应答
回到DataStreamer.java,定位到run:

通过initDataStreaming方法来启动ResponseProcessor,用于监听packet发送是否成功;
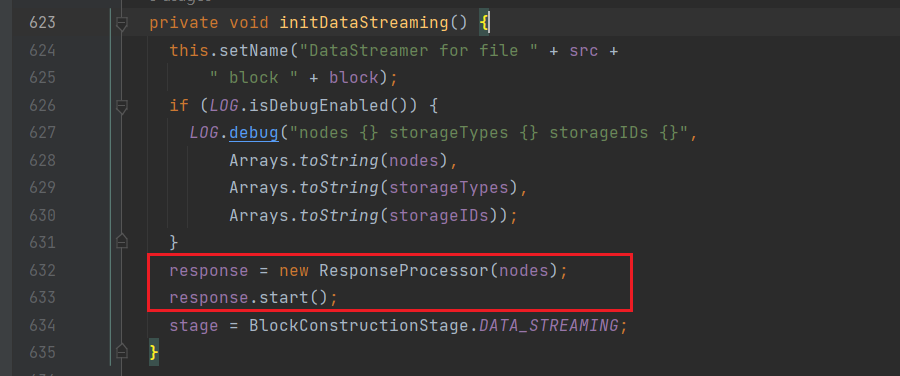
创建ResponseProcessor并启动线程;
进入ResponseProcessor,定位到run:
@Override
public void run() {
setName("ResponseProcessor for block " + block);
PipelineAck ack = new PipelineAck();
TraceScope scope = null;
while (!responderClosed && dfsClient.clientRunning && !isLastPacketInBlock) {
// 处理来自DN的应答
try {
// 从管道中读取一个ack
ack.readFields(blockReplyStream);
if (ack.getSeqno() != DFSPacket.HEART_BEAT_SEQNO) {
Long begin = packetSendTime.get(ack.getSeqno());
if (begin != null) {
long duration = Time.monotonicNow() - begin;
if (duration > dfsclientSlowLogThresholdMs) {
LOG.info("Slow ReadProcessor read fields for block " + block
+ " took " + duration + "ms (threshold="
+ dfsclientSlowLogThresholdMs + "ms); ack: " + ack
+ ", targets: " + Arrays.asList(targets));
}
}
}
if (LOG.isDebugEnabled()) {
LOG.debug("DFSClient {}", ack);
}
long seqno = ack.getSeqno();
// processes response status from datanodes.
ArrayList<DatanodeInfo> congestedNodesFromAck = new ArrayList<>();
for (int i = ack.getNumOfReplies()-1; i >=0 && dfsClient.clientRunning; i--) {
final Status reply = PipelineAck.getStatusFromHeader(ack
.getHeaderFlag(i));
if (PipelineAck.getECNFromHeader(ack.getHeaderFlag(i)) ==
PipelineAck.ECN.CONGESTED) {
congestedNodesFromAck.add(targets[i]);
}
// Restart will not be treated differently unless it is
// the local node or the only one in the pipeline.
if (PipelineAck.isRestartOOBStatus(reply)) {
final String message = "Datanode " + i + " is restarting: "
+ targets[i];
errorState.initRestartingNode(i, message,
shouldWaitForRestart(i));
throw new IOException(message);
}
// node error
if (reply != SUCCESS) {
errorState.setBadNodeIndex(i); // mark bad datanode
throw new IOException("Bad response " + reply +
" for " + block + " from datanode " + targets[i]);
}
}
if (!congestedNodesFromAck.isEmpty()) {
synchronized (congestedNodes) {
congestedNodes.clear();
congestedNodes.addAll(congestedNodesFromAck);
}
} else {
synchronized (congestedNodes) {
congestedNodes.clear();
lastCongestionBackoffTime = 0;
}
}
assert seqno != PipelineAck.UNKOWN_SEQNO :
"Ack for unknown seqno should be a failed ack: " + ack;
if (seqno == DFSPacket.HEART_BEAT_SEQNO) { // a heartbeat ack
continue;
}
// 标志成功传输的ack
DFSPacket one;
synchronized (dataQueue) {
one = ackQueue.getFirst();
}
if (one.getSeqno() != seqno) {
throw new IOException("ResponseProcessor: Expecting seqno " +
" for block " + block +
one.getSeqno() + " but received " + seqno);
}
isLastPacketInBlock = one.isLastPacketInBlock();
// Fail the packet write for testing in order to force a
// pipeline recovery.
if (DFSClientFaultInjector.get().failPacket() &&
isLastPacketInBlock) {
failPacket = true;
throw new IOException(
"Failing the last packet for testing.");
}
// update bytesAcked
block.setNumBytes(one.getLastByteOffsetBlock());
synchronized (dataQueue) {
scope = one.getTraceScope();
if (scope != null) {
scope.reattach();
one.setTraceScope(null);
}
lastAckedSeqno = seqno;
pipelineRecoveryCount = 0;
ackQueue.removeFirst(); //从ack队列中移除
packetSendTime.remove(seqno);
dataQueue.notifyAll(); //通知dataQueue应答处理完毕
one.releaseBuffer(byteArrayManager);
}
} catch (Exception e) {
if (!responderClosed) {
lastException.set(e);
errorState.setInternalError();
errorState.markFirstNodeIfNotMarked();
synchronized (dataQueue) {
dataQueue.notifyAll();
}
if (!errorState.isRestartingNode()) {
LOG.warn("Exception for " + block, e);
}
responderClosed = true;
}
} finally {
if (scope != null) {
scope.close();
}
scope = null;
}
}
}至此,客户端成功收到DN的应答后,上传过程完成