目录
编辑
一、Hive分区
1.1 分区产生的背景
1.2 动态分区
1.2.1 hive的动态分区介绍
1.2.2 动态分区配置
1.2.2.1 动态分区开启
1.2.2.2 动态分区模式
1.2.2.3 一个mr节点上,设置动态分区的最大数量
1.2.2.4 所有mr节点上,设置所有动态分区的最大数量
1.2.2.5 设置所有mr job 允许创建的文件的最大数量
1.2.3 动态分区实操
1.2.3.1 动态分区语法
1.2.3.2 实践案例
1.3 静态分区
1.3.1 静态分区介绍
1.3.2 静态分区实操
1.3.2.1 静态分区语法
1.3.2.2 单分区
1.3.2.3 多分区
1.3.2.4 修复分区
1.3.2.4.1 在hdfs创建目录并上传文件
1.3.2.4.2 创建外部表
1.3.2.4.3 查询结果(没有数据)
1.3.2.4.4 修复分区
1.3.2.4.5 查询结果(有数据)
1.4 多重分区
1.4.1 多重分区介绍
1.4.2 多重分区实操
1.4.2.1 多重分区语法
1.4.2.2 实践案例
1.5 静态分区和动态分区的区别
1.6 分区表的注意事项
二、Hive分桶
2.1 分桶的介绍
2.1.1 创建分桶表
2.1.2 分桶表导入数据的方式
2.1.2.1 load方式
2.1.2.2 insert 方式
2.1.3 分桶抽样查询
2.1.4 分区表和分桶表的结合使用
2.1.4.1 创建分区、分桶表
2.1.4.2 插入数据
2.1.4.3 查询数据
一、Hive分区
1.1 分区产生的背景
随着系统运行时间的增加,表的数据量会越来越大,而Hive查询数据的数据的时候通常使用的是「全表扫描」,这样将会导致大量不必要的数据进行扫描,从而查询效率会大大的降低。 从而Hive引进了分区技术,使用分区技术,「避免Hive全表扫描,提升查询效率」
1.2 动态分区
1.2.1 hive的动态分区介绍
hive的静态分区需要用户在插入数据的时候必须手动指定hive的分区字段值,但是这样的话会导致用户的操作复杂度提高,而且在使用的时候会导致数据只能插入到某一个指定分区,无法让数据散列分布,因此更好的方式是当数据在进行插入的时候,根据数据的某一个字段或某几个字段值动态的将数据插入到不同的目录中,此时,引入动态分区。
1.2.2 动态分区配置
1.2.2.1 动态分区开启
set hive.exec.dynamic.partition=true;默认值是true;
1.2.2.2 动态分区模式
set hive.exec.dynamic.partition.mode=nostrict;默认:strict(至少有一个分区列是静态分区)
1.2.2.3 一个mr节点上,设置动态分区的最大数量
每一个执行mr节点上,允许创建的动态分区的最大数量
set hive.exec.max.dynamic.partitions.pernode;默认值是100。
1.2.2.4 所有mr节点上,设置所有动态分区的最大数量
所有执行mr节点上,允许创建的所有动态分区的最大数量
set hive.exec.max.dynamic.partitions;默认值是1000。
1.2.2.5 设置所有mr job 允许创建的文件的最大数量
所有的mr job允许创建的文件的最大数量
set hive.exec.max.created.files;默认值是100000。
1.2.3 动态分区实操
1.2.3.1 动态分区语法
分区的字段值是基于查询结果自动推断出来的。核心语法就是insert+select。
1.2.3.2 实践案例
1.3 静态分区
1.3.1 静态分区介绍
在涉及分区的DML/DDL中,这些分区列的值在编译时已知(由用户在创建表时给出)。静态分区分为单分区、多分区。
1.3.2 静态分区实操
1.3.2.1 静态分区语法
#分区关键字partitioned by(gender string........)
create table test_table
(
xxxx
)
partitioned by(gender string)
row format delimited;
1.3.2.2 单分区
create table psn5
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(gender string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';1.3.2.3 多分区
create table psn6
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(gender string,age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';提示:多分区和单分区的差别在于分区字段的数量,单分区只有一个分区字段,多分区有多个分区字段
1.3.2.4 修复分区
在使用hive外部表的时候,可以先将数据上传到hdfs的某一个目录中,然后再创建外部表建立映射关系,如果在上传数据的时候,参考分区表的形式也创建了多级目录,那么此时创建完表之后,是查询不到数据的,原因是分区的元数据没有保存在mysql中,因此需要修复分区,将元数据同步更新到mysql中,此时才可以查询到元数据.
我们来验证一下。
1.3.2.4.1 在hdfs创建目录并上传文件
hdfs dfs -mkdir /ning
hdfs dfs -mkdir /ning/age=10
hdfs dfs -mkdir /ning/age=20
hdfs dfs -put /root/data/data /ning/age=10
hdfs dfs -put /root/data/data /ning/age=201.3.2.4.2 创建外部表
create external table psn11
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/ning';
1.3.2.4.3 查询结果(没有数据)
select * from psn11;
1.3.2.4.4 修复分区
msck repair table psn11;1.3.2.4.5 查询结果(有数据)
select * from psn11;
1.4 多重分区
1.4.1 多重分区介绍
通过建表语句中关于分区的相关语法可以发现,Hive支持多个分区字段:PARTITIONED BY (partition1 data_type, partition2 data_type,….)。
多重分区下,分区之间是一种递进关系,可以理解为在前一个分区的基础上继续分区。从HDFS的角度来看就是文件夹下继续划分子文件夹。
提示:其实和上一节说的静态分区中的多分区是一个东西,只是把它单独拎出来做了说明。
1.4.2 多重分区实操
1.4.2.1 多重分区语法
PARTITIONED BY (partition1 data_type, partition2 data_type,….)。
1.4.2.2 实践案例
create table psn6
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(gender string,age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';查询:
select * from psn6 where gender='男' and age=10;
1.5 静态分区和动态分区的区别
1)加载数据的方式:静态分区可以通过load命令,向不同的分区加载数据,加载数据时要指定分区的值;静态分区只能通过select加载数据,并且不需要指定分区的名字,而是根据伪列的值,动态的确定分区值
2)确定分区值的方式:两者在创建表的时候命令完全一致,只是在确定分区值的时候不同,静态分区需要手动指定分区值,而动态分区会自动识别伪列的属性,动态生成分区值
1.6 分区表的注意事项
1)分区表不是建表的必要语法规则,是一种优化手段表,可选;
2)分区字段不能是表中已有的字段,不能重复;
3)分区字段是虚拟字段,其数据并不存储在底层的文件中;
4)分区字段值的确定来自于用户价值数据手动指定(静态分区)或者根据查询结果位置自动推断(动态分区)
5)Hive支持多重分区,也就是说在分区的基础上继续分区,划分更加细粒度
二、Hive分桶
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。 分桶是将数据集分解成更容易管理的若干部分的另一个技术。 分区针对的是数据的存储路径;分桶针对的是数据文件。
分区提供了一个隔离数据和优化查询的可行方案,但是并非所有的数据集都可以形成合理的分区,分区的数量也不是越多越好,过多的分区条件可能会导致很多分区上没有数据。同时 Hive 会限制动态分区可以创建的最大分区数,用来避免过多分区文件对文件系统产生负担。鉴于以上原因,Hive 还提供了一种更加细粒度的数据拆分方案:分桶表 (bucket Table)。
分桶表会将指定列的值进行哈希散列,并对 bucket(桶数量)取余,然后存储到对应的 bucket(桶)中。
2.1 分桶的介绍
2.1.1 创建分桶表
create external table psn17
(
id int,
name string,
likes array<string>,
address map<string,string>
)
clustered by(id)
into 4 buckets
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
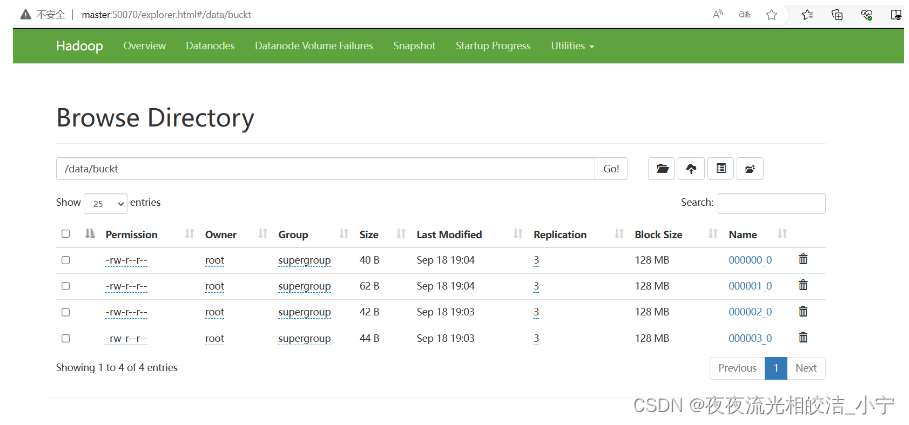
location '/data/buckt/';2.1.2 分桶表导入数据的方式
2.1.2.1 load方式
load data local inpath 'opt/module/datas/stu.txt' into table psn17;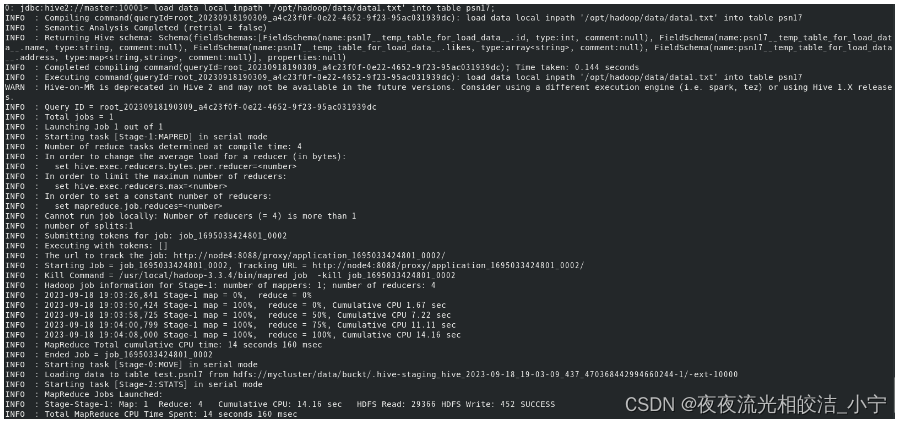
查询分桶表数据:
select * from psn17;
2.1.2.2 insert 方式
insert into table psn18 select * from psn17; 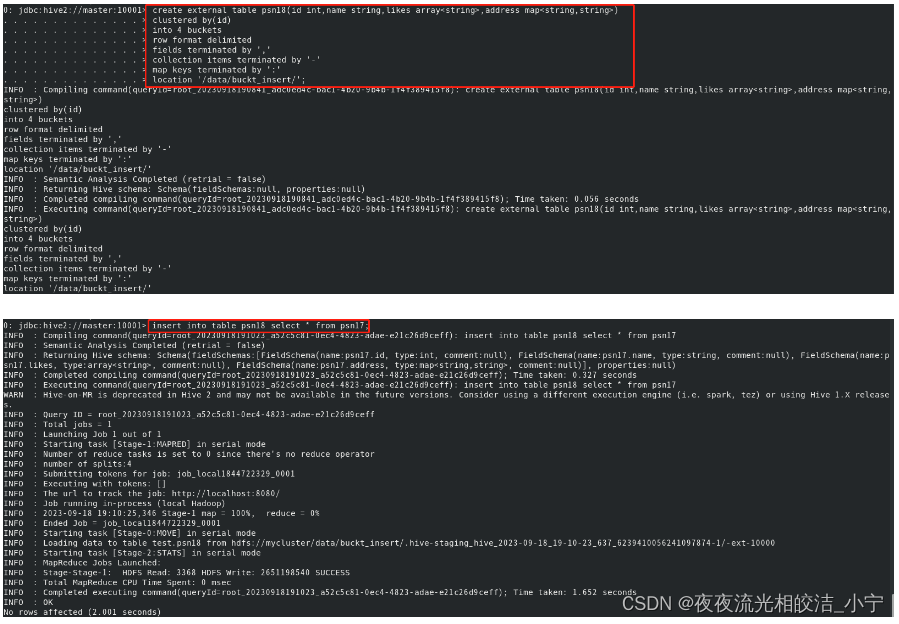
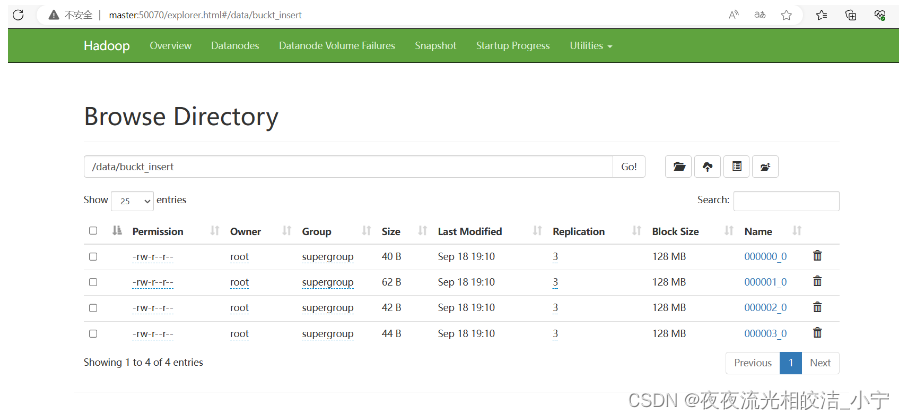
2.1.3 分桶抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive 可以通过对表进行抽样来满足这个需求。 语法: TABLESAMPLE(BUCKET x OUT OF y) 查询分桶表中的数据。
select * from psn18 tablesample(bucket 1 out of 4 on id);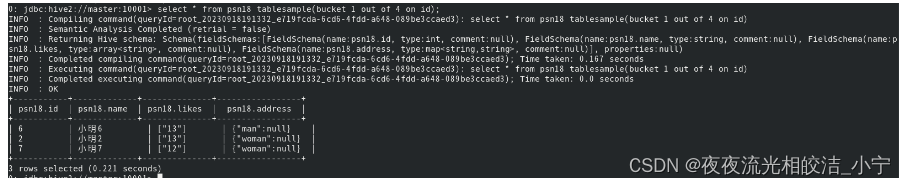
x表示从哪个bucket开始抽取。 例如,table总bucket数为4,bucket 4 out of 4,表示总共抽取(4/4=)1个bucket的数据, 抽取第4个bucket的数据。
hive根据y的大小,决定抽样的比例。 例如,table总共分了4份(4个bucket), 当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据。
注意:x 的值必须小于等于 y 的值,否则
Error: Error while compiling statement: FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table psn18 (state=42000,code=10061)2.1.4 分区表和分桶表的结合使用
分区表和分桶表的本质都是将数据按照不同粒度进行拆分,从而使得在查询时候不必扫描全表,只需要扫描对应的分区或分桶,从而提升查询效率。两者可以结合起来使用,从而保证表数据在不同粒度上都能得到合理的拆分。
2.1.4.1 创建分区、分桶表
create external table psn19
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int)
clustered by(id)
into 4 buckets
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/data/buckt_parttion/';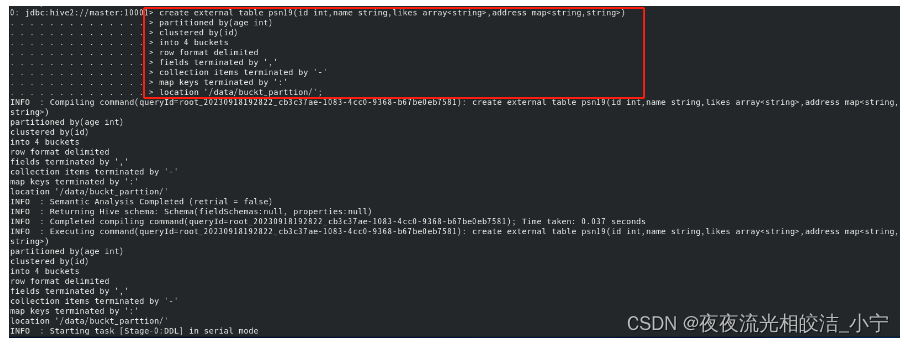
2.1.4.2 插入数据
INSERT into psn19 partition(age=10) select * from psn18 limit 4;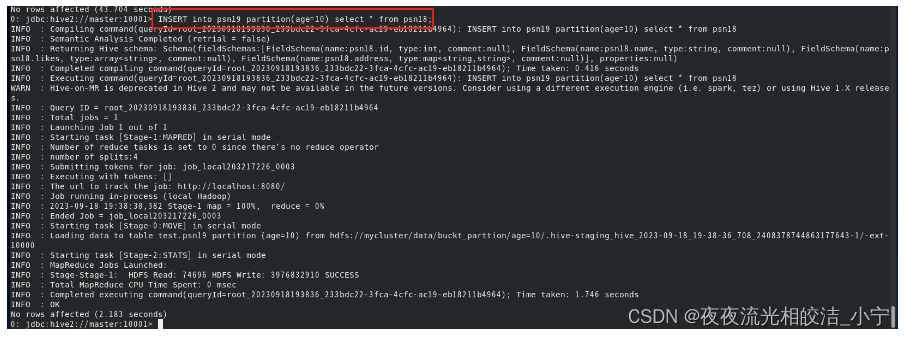
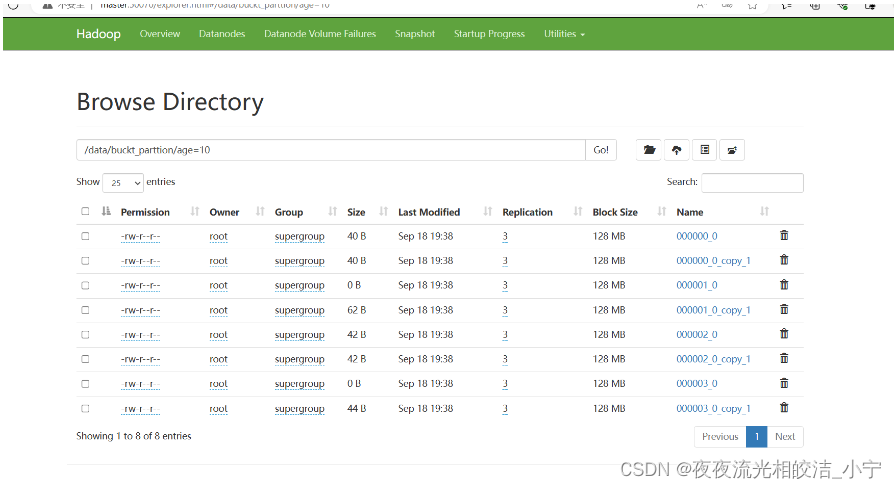
2.1.4.3 查询数据
select * from psn19 tablesample(bucket 1 out of 4 on id) where age=10;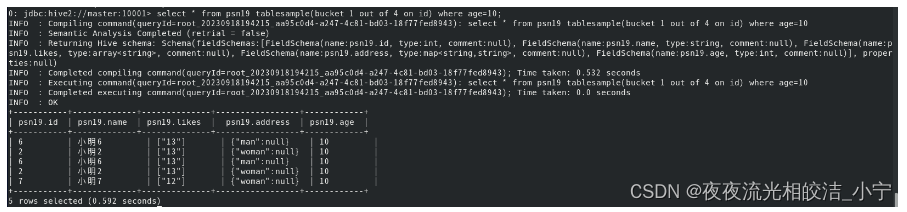
好了,今天Hive分区于分桶的相关内容就分享到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!