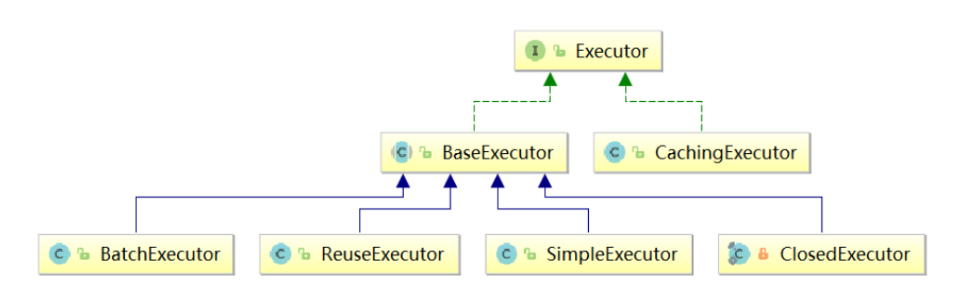
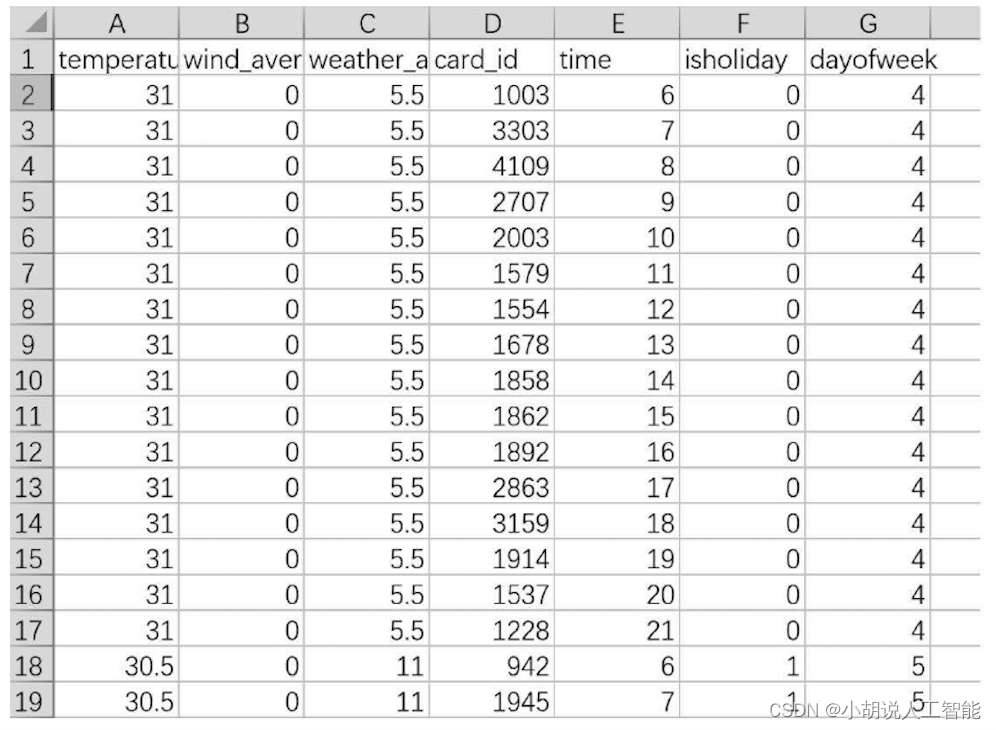
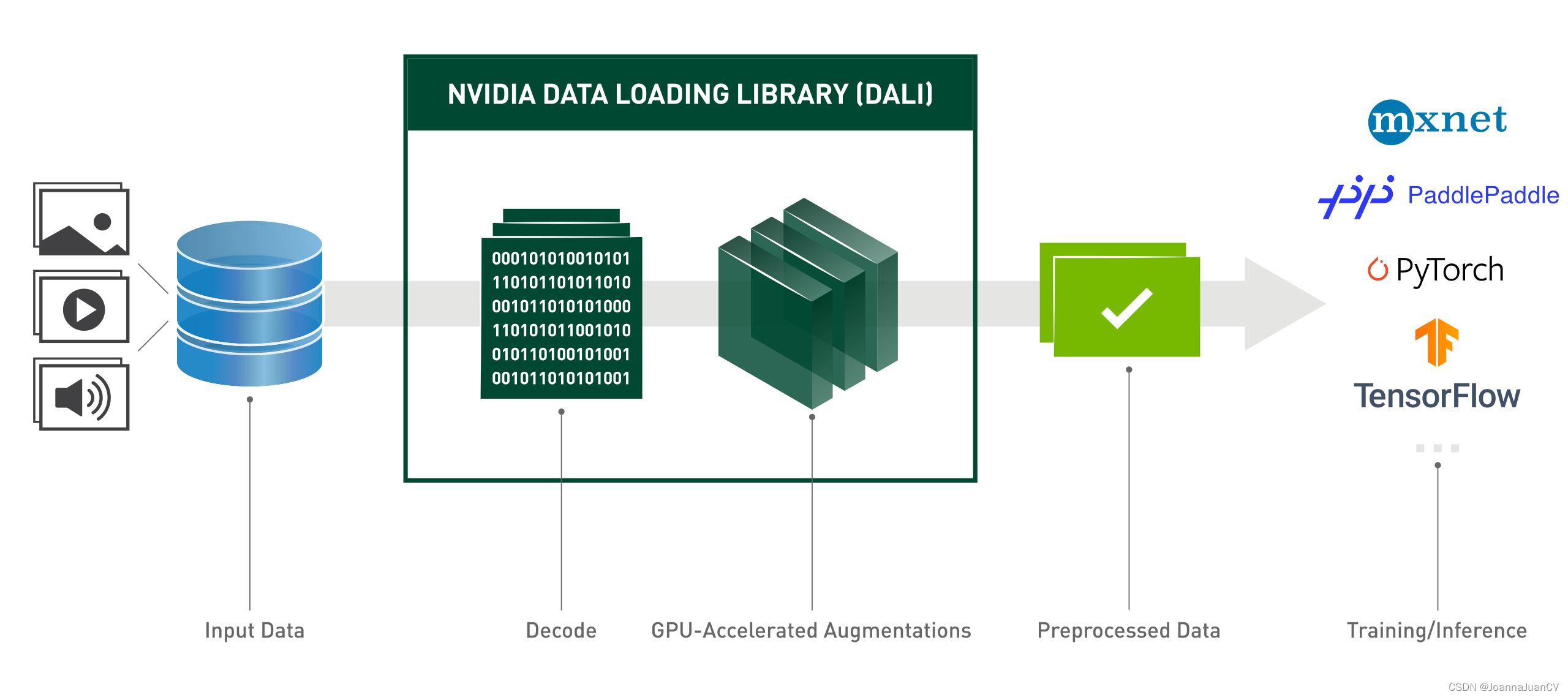
DALI的工作流, 如下图:
- 读取数据
- 图像解码和变换,可以放到GPU上进行,也是加速的关键
- 生成处理好的数据, 导出给计算引擎
测试用例
import ctypes
import numpy as np
import nvidia.dali.fn as fn
import nvidia.dali.types as types
# import pycuda.driver as cuda
from nvidia.dali.backend import TensorGPU, TensorListGPU
from nvidia.dali.pipeline import Pipeline
import cv2
class ExternalInputIterator(object):
def __init__(self, batch_size, image_dir=''):
self.batch_size = batch_size
self.files = []
self.image_dir = image_dir
def __iter__(self):
self.i = 0
self.n = self.batch_size
return self
def feed(self, inputs):
# print('feed: %d' % len(inputs))
self.files.extend(inputs)
# print('files: %d' % len(self.files))
def __next__(self):
batch = []
# print('files: %d' % len(self.files))
if len(self.files) < self.batch_size:
raise StopIteration()
for _ in range(self.batch_size):
jpeg_filename = self.files.pop()
# print(self.image_dir + jpeg_filename)
f = open(self.image_dir + jpeg_filename, 'rb')
batch.append(np.frombuffer(f.read(), dtype=np.uint8))
return batch
class DaliPipeline(object):
def __init__(self, batch_size, device_id, stream=None):
self.batch_size = batch_size
self.device_id = device_id
self.stream = stream
self.pipe = None
self.eii = ExternalInputIterator(batch_size)
def load(self, inputs):
if self.pipe is None:
# create pipeline
pipe = Pipeline(batch_size=self.batch_size, num_threads=1, device_id=self.device_id,
exec_pipelined=False, exec_async=False)
with pipe:
# jpegs = fn.external_source(source=self.eii, num_outputs=1, device="gpu", cuda_stream=self.stream)
jpegs = fn.external_source(source=self.eii, device="cpu")
decode = fn.decoders.image(jpegs, device="mixed", output_type=types.BGR)
out = fn.resize(decode, device="gpu", resize_shorter=224,
interp_type=types.INTERP_TRIANGULAR)
pipe.set_outputs(out)
pipe.build()
self.pipe = pipe
# feed data
self.eii.feed(inputs)
pipe_out = self.pipe.run()
return pipe_out
def test_pipeline(pipe, imgpathlist, count=1):
# from tqdm import tqdm
# bar = tqdm(total=count, ncols=60)
batchsize = len(imgpathlist)
start = time.time()
for i in range(count):
output_tensor, = pipe.load(imgpathlist)
# output = output_tensor.as_cpu().as_array()
# for img in output:
# cv2.imwrite("out.jpg", img)
# bar.update(1)
end = time.time()
# bar.close()
# report speed
v = count * batchsize / (end - start)
print('Time: %.3f Speed=%.3f img/sec' % (end - start, v))
return v
if __name__ == '__main__':
import time
import os
batchsize = 8
device_id = 0
img_paths = ['img/building.jpg', 'img/lena.jpg', 'img/dog.png']
for img_path in img_paths:
imgpathlist = []
for i in range(batchsize):
imgpathlist.append(img_path)
# test
pipe = DaliPipeline(batchsize, device_id)
v1 = test_pipeline(pipe, imgpathlist)