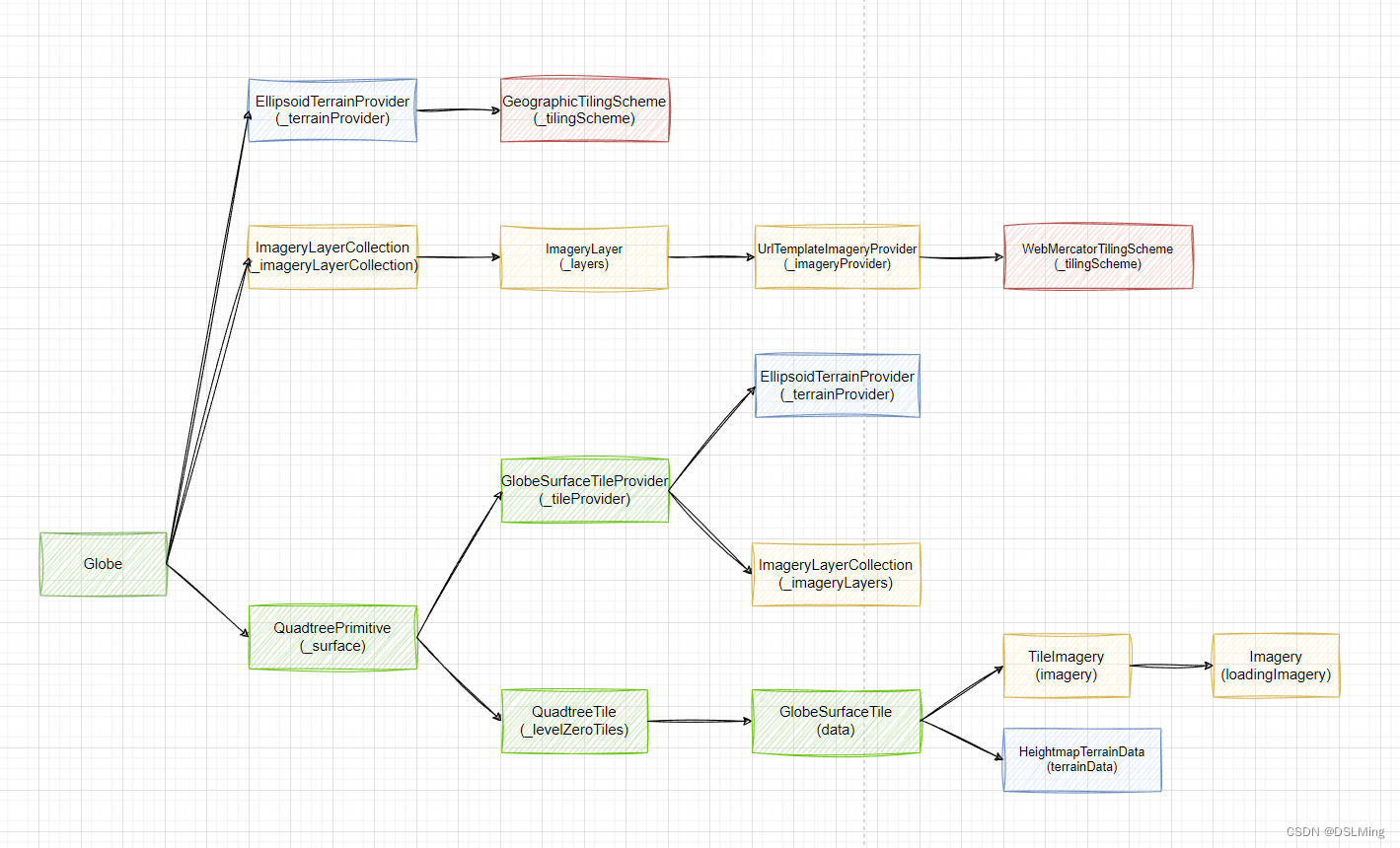
定义: 使用方法:给训练数据或者测试数据进行降维处理
给训练数据降维 给测试数据降维:这里1就要用transform,而不是fit_transform,因为之前训练数据降维时特征已经确定,测试数据提取的特征要和训练数据保持一致。 概念:每次进行数据划分都是随机的,所以没法保证稳定的模型精确度 方法一:k折交叉验证(将所有数据划分成k份,每次训练用1/k作为测试数据,其余数据作为训练数据),使用方式是先通过sklearn库中的model_selection导入KFold,然后设定好KFold的n_splits参数,之后通过模型的split方法划分训练数据和测试数据,返回的是一个生成器,其中会按照数据的下标划分好数据,使用时可以通过数组索引的方式(数组[数组])。 方法二:StratifiedKFold(分层KFold):相对于方法一,挑着分,分的更细了,使用方法类似K折交叉验证。 举例:SVM模型选择最优惩罚因子C和最优高斯核函数对应的参数gamma(gamma参数只有核函数为高斯时才有)
import numpy as np
import pandas as pd
from sklearn. datasets import load_iris
from sklearn. model_selection import GridSearchCV
from sklearn. svm import SVC
data, target = load_iris( return_X_y= True )
'''
网格交叉验证参数说明:
estimator:模型对象,不需要带参数,只需要输入模型对象即可
param_grid:网格参数,通过字典形式(键为模型参数名字符串,值为可能的数值列表)输入,每个参数需要提供多个值,会选择最优组合
n_job:多进程,-1表示适用所有处理器CPU
cv:默认分成5份,分的方法类似k折交叉验证,属于内部操作
'''
svc = SVC( )
param_grid = {
'C' : [ 0.1 , 1 , 10 , 15 ] ,
'gamma' : [ 0.01 , 0.05 , 0.1 , 0.5 , 1 ]
}
gv = GridSearchCV( estimator= svc, param_grid= param_grid, n_jobs= - 1 , cv= 5 )
gv. fit( data, target)
gv. best_score_, gv. best_params_, gv. best_estimator_