一、冒泡排序
冒泡排序的原理是:从左到右,相邻元素进行比较。每次比较一轮,就会找到序列中最大的一个或最小的一个。这个数就会从序列的最右边冒出来。
以从小到大排序为例,第一轮比较后,所有数中最大的那个数就会浮到最右边;第二轮比较后,所有数中第二大的那个数就会浮到倒数第二个位置……就这样一轮一轮地比较,最后实现从小到大排序。
代码如下:
void BubbleSort(int* a, int n)
{
for (size_t j = 0; j < n; j++)
{
int exchange = 0;
for (size_t i = 1; i < n-j; i++)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
{
break;
}
}
}冒泡排序时间复杂度
如果待排序序列的初始状态恰好是我们希望的排序结果(如升序或降序),一趟扫描即可完成排序。
所需的关键字比较次数C和记录移动次数M均达到最小值:
冒泡排序最好的时间复杂度为O(n)。
如果待排序序列是反序(如我们希望的结果是升序,待排序序列是降序)的,需要进行n-1趟排序。每趟排序要进行n-i次关键字的比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:
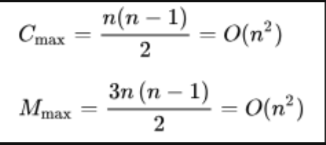
冒泡排序的最坏时间复杂度为O(N^2)
综上,因此冒泡排序总的平均时间复杂度为O(N^2)冒泡排序是稳定的排序
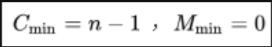
二、选择排序
选择排序的工作原理是:第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,继续放在起始位置知道未排序元素个数为0。
选择排序的步骤:
1>首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
2>再从剩余未排序元素中继续寻找最小(大)元素,然后放到未排序序列的起始位置。
3>重复第二步,直到所有元素均排序完毕。
选择排序代码实现:
//交换两个数据
void Swap(int* a, int* b)
{
int temp = *a;
*a = *b;
*b = temp;
}
//选择排序
void SelectSort(int* arr, int size)
{
int i = 0;
for (i = 0; i < size-1; i++)
{
int min = i;
int j = 0;
for (j = i+1; j < size; j++)
{
if (arr[j] < arr[min])
{
min = j;
}
}
Swap(&arr[i], &arr[min]);
}
}
思路优化:
以上算法是每次找出最小的放在指定位置,一共要找n-1次,如果我们每次不但找到最小的,还找到最大的,将最小的与左端交换,最大的与右端交换,那么就少了一半的遍历次数,从而提高效率。
- 变量
begin和变量end是数组的两端,min和max分别找小和大的下标- 先交换
min与begin位置的数值,再交换max与end位置的数值begin右移,end左移,继续找大找小,继续交换- 重复上述操作,直到遍历完所有数组
排序优化后问题
若是max的位置与begin重合,则begin先与min的位置交换,此时max位置的最大值被交换走,导致end与max交换的数值是错误的。
问题解决:
当max与begin重合时,begin与min交换后导致max指向的不再是最大值,所以当我们对begin交换后,就要对max进行一个修正,让max指向最大值,然后完成end的交换
1、max与
begin重合,并且begin此时完成了交换,此时最大值已经交换到了min所指向的位置2、对
max进行修正并完成与end的交换
优化后代码:
//交换两个数据
void Swap(int* a, int* b)
{
int temp = *a;
*a = *b;
*b = temp;
}
//选择排序
void SelectSort(int* arr, int size)
{
int begin = 0;
int end = size - 1;
while (begin < end)
{
int max = begin;
int min = begin;
int i = 0;
for (i = begin+1; i <= end; i++)
{
if (arr[i] < arr[min])
{
min = i;
}
if (arr[i] > arr[max])
{
max = i;
}
}
Swap(&arr[begin], &arr[min]);
if (begin == max) //修正max
{
max = min;
}
Swap(&arr[end], &arr[max]);
begin++;
end--;
}
}
选择排序时间复杂度:
时间复杂度:O(n^2)
空间复杂度:O ( 1 )
选择排序是不稳定的排序
三、插入排序
直接插入排序是一种简单的插入排序法,对数组进行一个遍历,每次都对待排的数据按照大小顺序插入到一个有序数组中的特定位置,直到所有的数据全部插入完毕,就得到一个有序数列。
插入排序的算法非常简单,依次对每一个元素进行单趟排序就行了,由于要前一个数比较则只需要从1开始遍历n-1次

当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的
元素顺序后移
插入排序代码:
void InsertSort(int* arr, int size)
{
int i = 0;
for (i = 1; i < size; i++)
{
int end = i;
int temp = arr[end]; //记录待排数值
while (end > 0)
{
if (arr[end-1] > temp) //若前一个数大于待排数值,则后移一位
{
arr[end] = arr[end-1];
end--;
}
else
{
break;
}
}
// arr[end-1] = temp;是之前的错误,现已修正
arr[end] = temp; //将数据放入插入位置
}
}
插入排序的时间复杂度:
1. 元素集合越接近有序,直接插入排序算法的时间效率越高
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1),它是一种稳定的排序算法
4. 稳定性:稳定
四、希尔排序
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有记录分成个组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工作。当到达=1时,所有记录在统一组内排好序。
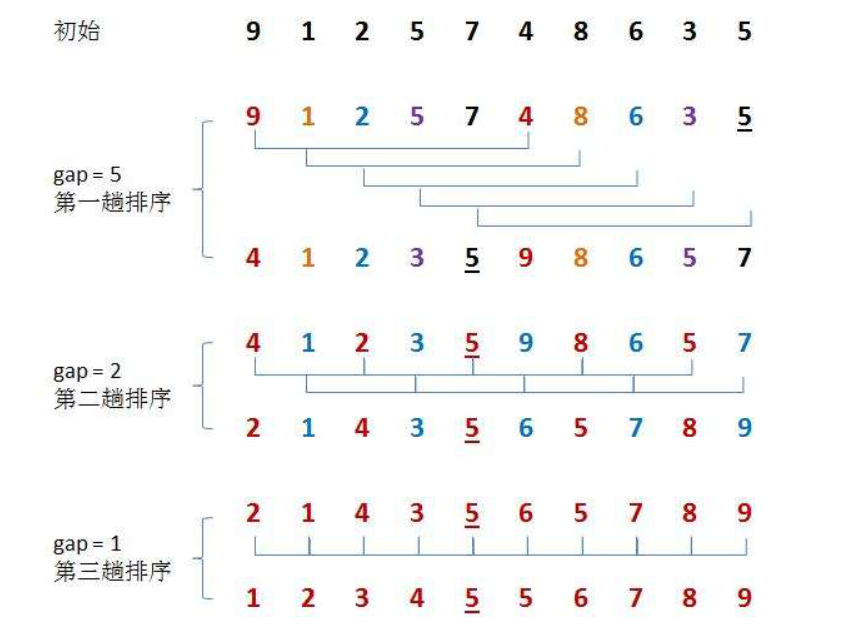
1. 希尔排序是对直接插入排序的优化。
2. 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
3. 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的
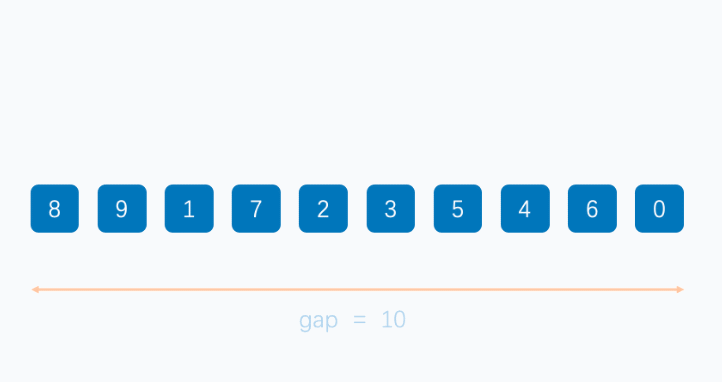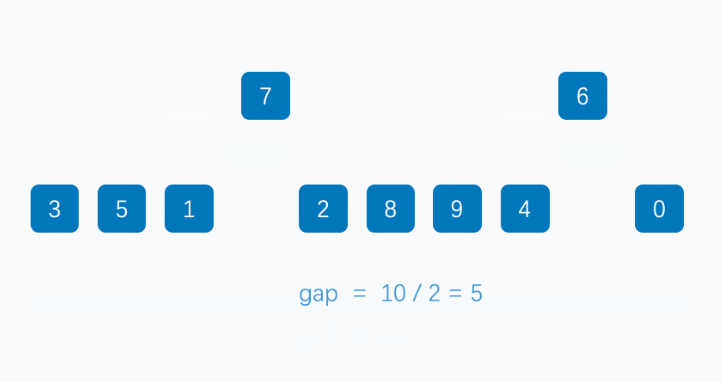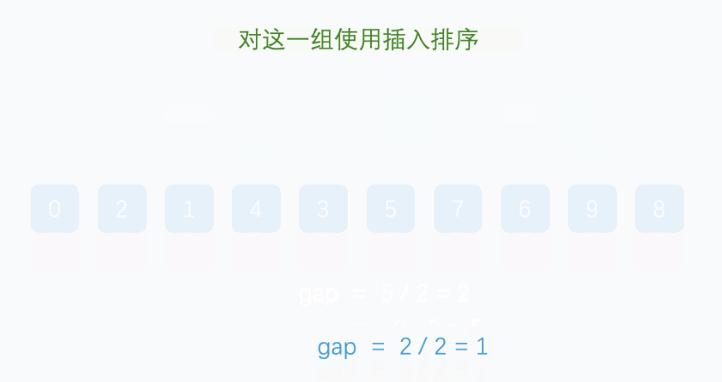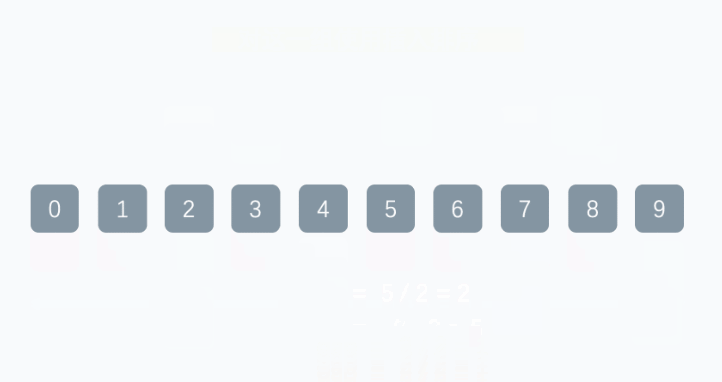
希尔排序代码实现:
void ShellSort(int* arr, int size)
{
int gap = size;
while (gap > 1)
{
gap = gap / 2; //调整希尔增量
int i = 0;
for (i = 0; i < size - gap; i++) //从0遍历到size-gap-1
{
int end = i;
int temp = arr[end + gap];
while (end >= 0)
{
if (arr[end] > temp)
{
arr[end + gap] = arr[end];
end -= gap;
}
else
{
break;
}
}
arr[end + gap] = temp; //以 end+gap 作为插入位置
}
}
}
希尔排序的时间复杂度:
希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些书中给出的希尔排序的时间复杂度都不固定:
时间复杂度:O(n^1.3)
稳定性:不稳定









![[游戏开发][Shader]ShaderToy通用模板转Unity-CG语言](https://img-blog.csdnimg.cn/ce5f304e24774d27811ced9f0b8a8d81.png)





