1、字符集基础知识
- 计算机底层不可以直接存储字符的。计算机中底层只能存储二进制(0、1)
- 二进制是可以转换成十进制的
- 结论:计算机底层可以表示十进制编号。计算机可以给人类字符进行编号存储,这套编号规则就是字符集。
2、ASCII字符集
- ASCII(American Standard Code Information Interchange,美国信息交换标准代码):包括了数字、英文、符号。
- ASCII使用 一个字节存储一个字符 ,一个字节是8位,总共可以表示128个字符信息,对于英文,数字来说是够用的。
- 01100001 = 97 => a
- 01100010 = 98 => b
3、GBK
- window系统默认的码表。兼容ASCII码表,也包含了几万个汉字,并支持繁体汉字以及部分日韩文字。
- 注意:GBK是中国的码表,一个中文以两个字节的形式存储。但不不包含世界上所有国家的文字。
4、Unicode码表
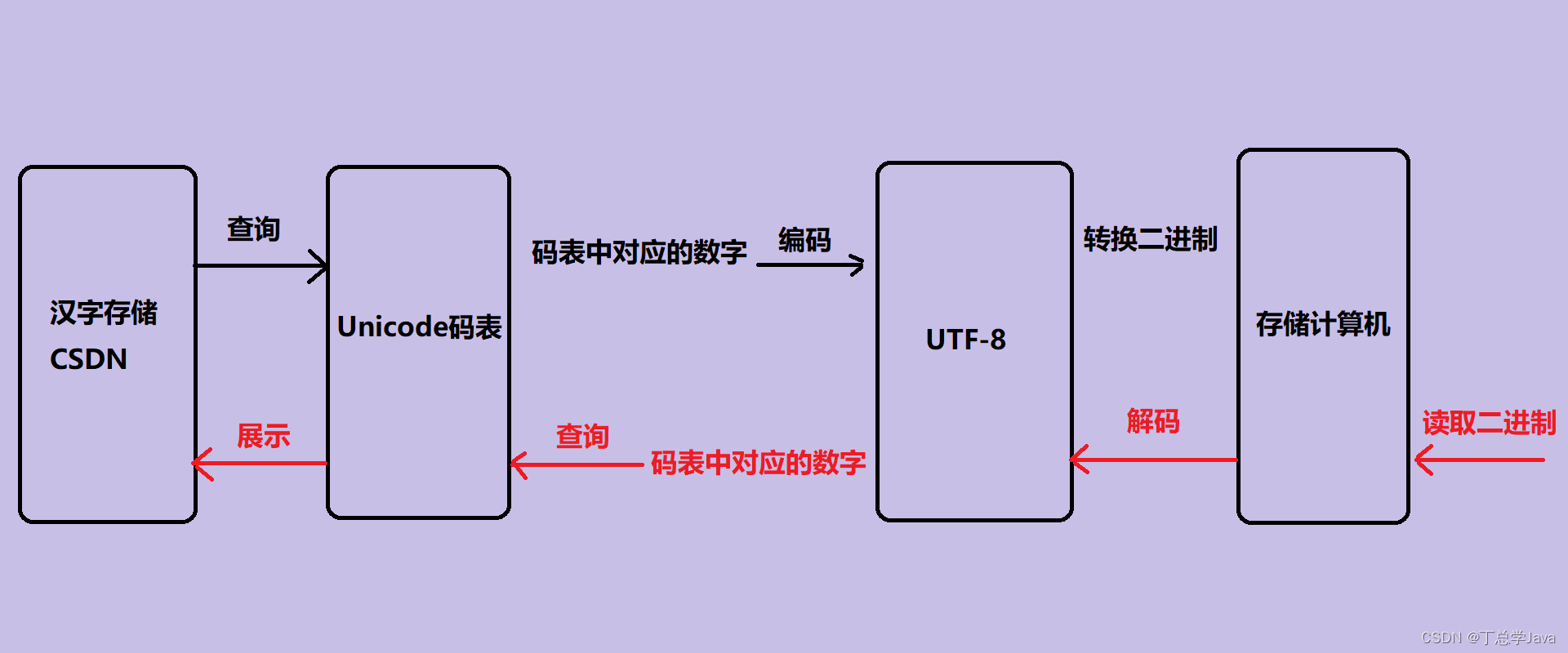
- unicode(又称统一码、万国码、单一码)是计算机科学领域里的一项业界字符编码标准。
- 容纳世界上大多数国家的所有常见字符和符号。
- 由于Unicode会先通过UTF-8,UTF-16,以及UTF-32 的编码成二进制后再存储到计算机,其中最为常见的就是UTF-8。
5、注意
- Unicode是万国码,以UTF-8编码后一个中文一般以 三个字节 的形式存储
- UFT-8也要兼容ASCII编码表。
- 技术人员都应该使用UTF-8的字符集编码。
- 编码前和编码后的字符集需要一致,否则会出现中文乱码。
6、字符串常见和字符底层组成是什么样的?
- 英文和数字等在任何国家的字符集中都占1个字节
- GBK字符中一个中文字符占 2 个字节
- UTF-8 编码中一个中文 一般占 3 个字节
7、编码前的字符集和编码后的字符集有什么要求?
- 必须一致,否则会出现中文字符乱码
- 英文和数字在任何国家的编码中都不会乱码
8、字符集的编码、解码操作
8.1、String编码
方法名称 说明 byte [ ] getBytes() 使用平台的默认字符集该String编码为一些列字节,将结果存储到新的字节数组中 byte [ ] getBytes (String charsetName) 使用指定的字符集将该String编码为一系列字节,将结果存储到新的字符数组中 8.2、String解码
构造器 说明 String(byte [ ] bytes) 通过使用平台的默认字符集解码指定的字节数组来构造新的String String(byte [ ] bytes,String charsetName) 通过指定的字符集解码指定的字节数组来构造新的String package com.csdn.d1_file; import java.io.UnsupportedEncodingException; import java.util.Arrays; /** * 目标:学会自己进行文字的编码和解码,为以后可能用到的场景做准备。 */ public class Charset { public static void main(String[] args) throws UnsupportedEncodingException { //1.编码:把文字转换成字节(使用指定的编码) String name = "csdn很牛逼";//13个字节 //默认 UTF-8 一个中文 占 3 个 字节 byte[] encodeUtf = name.getBytes(); System.out.println(encodeUtf.length);//13 System.out.println(Arrays.toString(encodeUtf));//[99, 115, 100, 110, -27, -66, -120, -25, -119, -101, -23, -128, -68] //GBK 一个中文 占 2 个字节 byte[] encodeGbk = name.getBytes("GBK"); System.out.println(encodeGbk.length);//10 System.out.println(Arrays.toString(encodeGbk));//[99, 115, 100, 110, -70, -36, -59, -93, -79, -58] //2.解码:把字节转换成对应的中文形式(编码前 和 编码后 的字符集必须一致,否则乱码) String decodeUtf = new String(encodeUtf); System.out.println(decodeUtf.length());//7 System.out.println(decodeUtf);//csdn很牛逼 String decodeGbk = new String(encodeUtf, "GBK"); System.out.println(decodeGbk.length());//9 System.out.println(decodeGbk);//csdn寰堢墰閫� } }
字符集(ASCII、GBK、Unicode、UTF-8)
news2026/3/30 17:55:27
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1024871.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
如何像微信一样扫码自由?
https://github.com/devilsen/CZXing
我在使用zxing的总是想扫码的时候怎么才能够快速校准,多个二维码扫描的时候怎么才能指定二维码呢。于是我在Github上找到了CZxing这个控件。在使用的时候发现了有些小问题。
扫码结果没有回调。 回调没有反应;是因…

二维码智慧门牌管理系统:提升城市管理效率与服务水平
文章目录 前言一、系统原理及特点二、系统的优势与应用 前言
在当今快速发展的信息化时代,如何有效地管理城市地址信息成为了各大城市面临的重要问题。传统的门牌管理系统已经无法满足现代城市的需求,而二维码智慧门牌管理系统作为全新的解决方案&#…
数据库开发-MySQL
数据库设计-DDL
下面我们就正式的进入到SQL语句的学习,在学习之前先给大家介绍一下我们要开发一个项目,整个开发流程是什么样的,以及在流程当中哪些环节会涉及到数据库。 项目开发流程 需求文档:
在我们开发一个项目或者项目当中…
Linux文件内容显示练习
1.新建2个文件b1.txt b2.txt ,使用vim打开b1.txt 输入“Hello World”字符串,将b1.txt硬链接到b2.txt 查看2个文件的硬连接数 [rootserver ~]# vim b1.txt [rootserver ~]# ln b1.txt b2.txt #建立硬链接 [rootserver ~]# stat b2.txt [rootserver ~]# stat b1.txt [r…

现货黄金的价格如何变动
现货黄金每天的交易时间很长,价格几乎全天24小时都处于波动之中,由于受到各种政治、经济因素的影响,价格波动有时可以来得十分迅猛,在一小时就可以波动二、三十美元,但有时却可以连续几天都维持在数美元的区间内波动。…
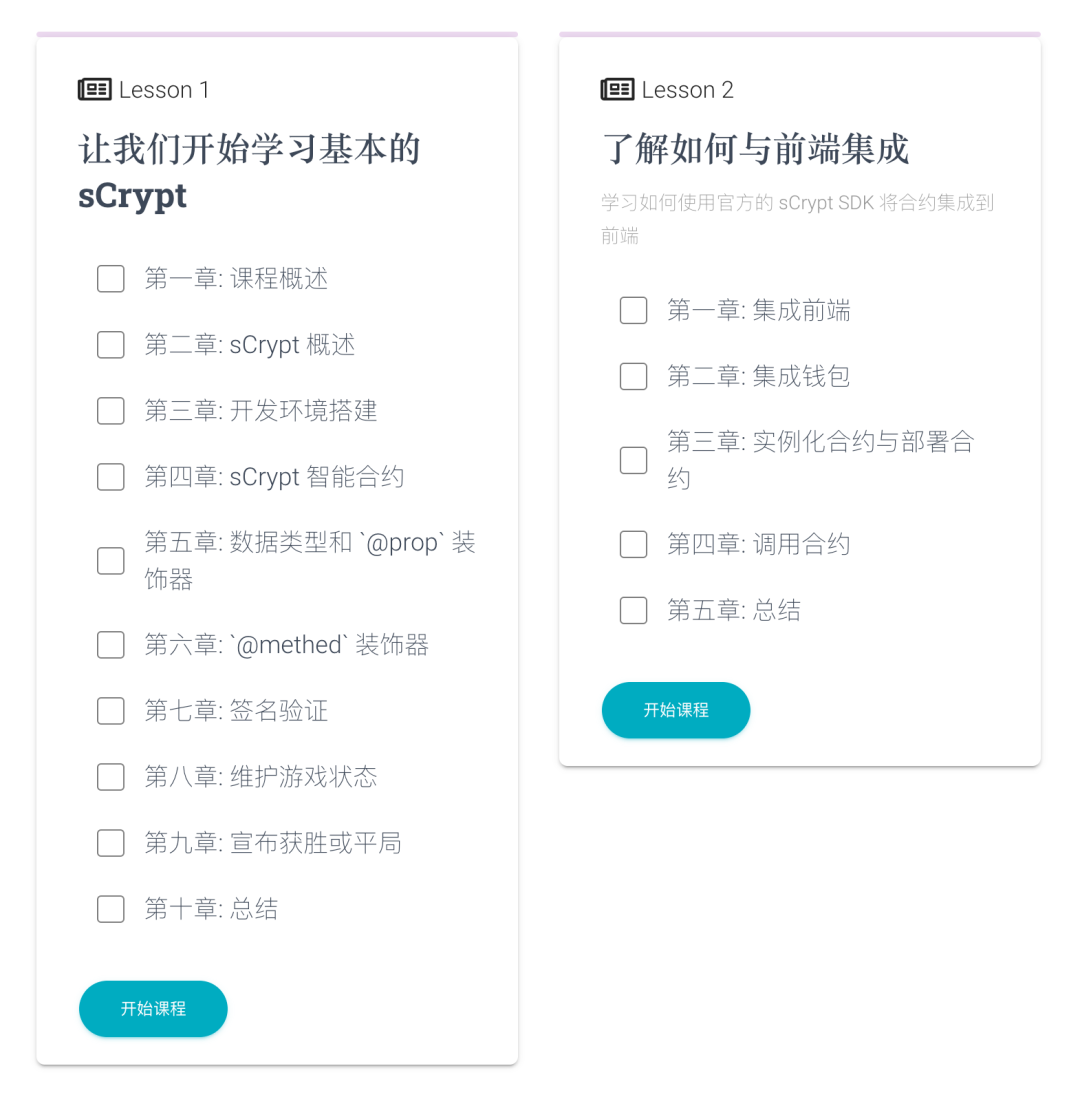
《使用 sCrypt 构建井字游戏》课程上线
《使用 sCrypt 构建井字游戏》课程上线 Learn sCrypt。Learn sCrypt 是一个交互式学习网站,旨在帮助开发者更快、更轻松地学习和掌握比特币智能合约开发语言 sCrypt。
井字游戏非常简单,就是使用两个玩家(分别是 Alice 和 Bob)的比特币地址初始化合约&a…

Spring框架——介绍与基本概念!
一、Spring框架概述
1.什么是Spring
Spring是一个轻量级的Java 开发开源框架,用于构建企业级应用程序。它提供了一组广泛使用的技术和API,包括依赖注入、AOP、数据访问、事务管理、Web开发和集成测试等。它是为了解决企业应用开发的复杂性而创建的。框…
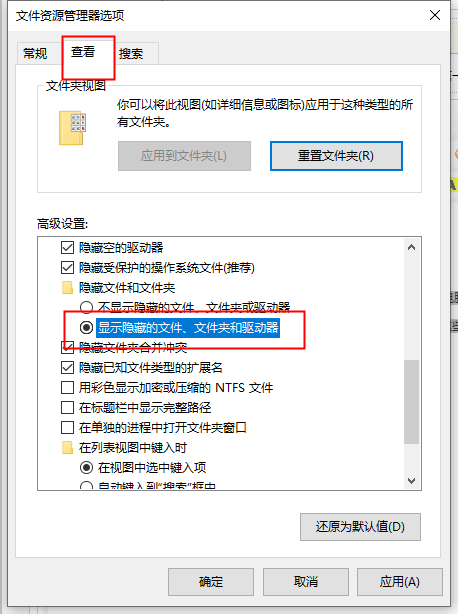
c盘中temp可以删除吗?appdata\local\temp可以删除吗?
http://www.win10d.com/jiaocheng/22594.html C盘AppData文件夹是一个系统文件夹,里面存储着临时文件,各种应用的自定义设置,快速启动文件等。近期有用户发现appdata\local\temp占用了大量的空间,那么该文件可以删除吗?…

Java 21 发布,带来诸多新特性又一次创新的飞跃
一、引言
2023年9月19日,Oracle公司正式发布了JDK 21,这是按照六个月发布周期准时交付的第12个功能版本。 这种可预测性让开发者能够轻松地管理他们对创新的采用,感谢稳定的改进流。JDK 21不仅包含了数千个性能、稳定性和安全性更新…
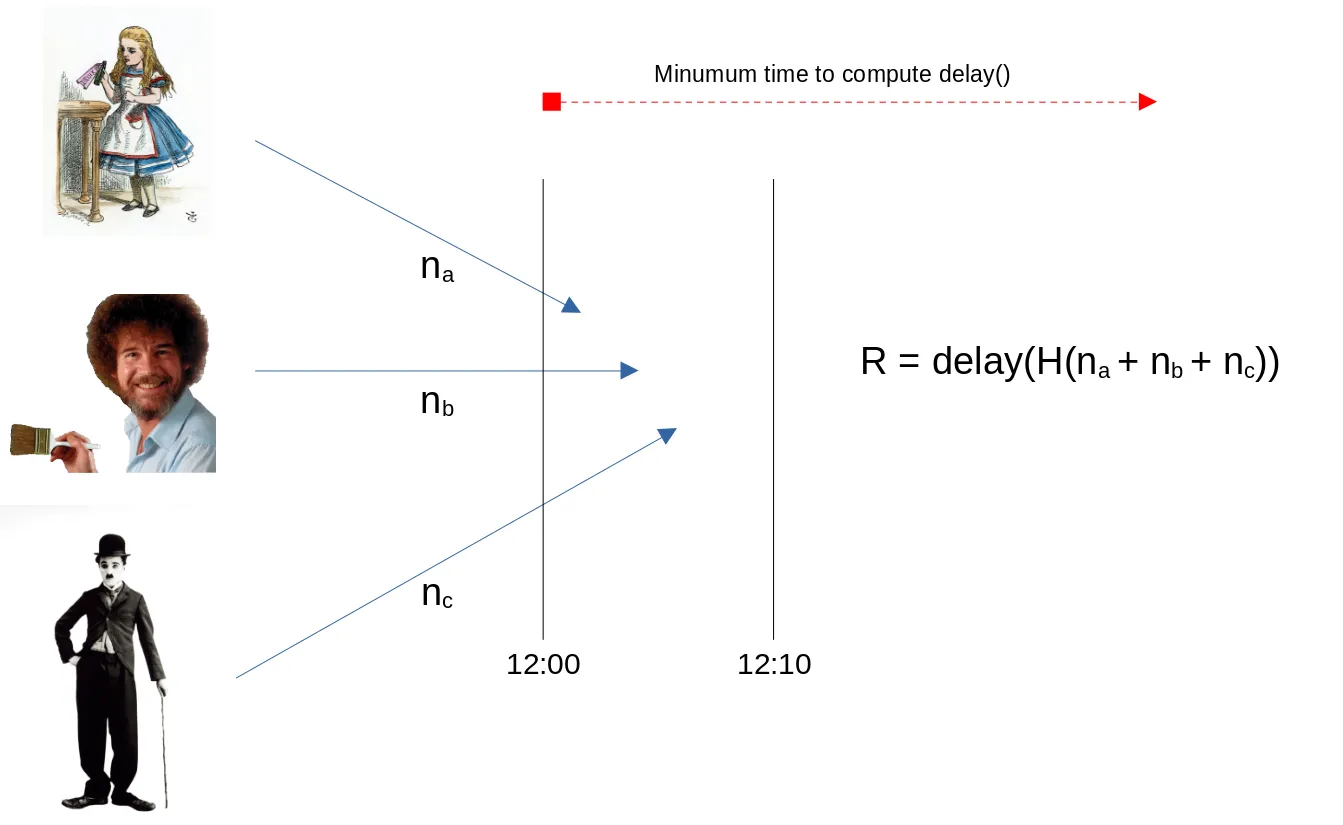
比特币上的可验证延迟函数
可验证延迟函数 (VDF) 是一种需要大量 顺序计算 来评估但可以快速验证的函数。我们首次在比特币上实现了它。VDF 作为密码学技术可用于构建大量新应用程序,例如公共随机信标、计算时间戳和数据复制证明。 VDF 场景
链上随机信标
在区块链中很难实现随机性…

php生成二维码合成文字、背景图并保存本地图片
目录
1、实现效果,二维码二维码合成文字、背景图
2、下载并引入qrcode
3、创建static文件夹下载字体和背景图到这
4、创建test2.php,合成代码 1、实现效果,二维码二维码合成文字、背景图 2、下载并引入qrcode
1、到phpqrcpde官网下载类库…
UltraEdit 22 编辑器 for Mac
UltraEdit 是一款功能强大的文本编辑器和源代码编辑器。它具有多种功能,适用于程序员、网站开发人员和其他需要处理大量文本内容的用户。 UltraEdit 提供了正则表达式搜索和替换功能,可以快速查找和修改文本中的特定内容。它还支持多文件编辑和多窗口布局…

掌握文案新技能,拓世AI让你成为朋友圈文案达人
“人生如戏,戏如人生”,这是一句缥缈却真实的话,我们在生活中扮演着各种角色,经营自己的人生。如同美国社会学家戈夫曼提出的“拟剧论”:他将社会和人生比作一个大舞台,我们都在关心如何在众多观众面前打造…

百亿、补贴这种低价怎么控
随着电商平台流量竞争的激烈演变,越来越多的促销形式进入人们的眼球,而店铺最简单的营销就是通过价格,所以低价销售成了各平台吸引消费者的方式,百亿补贴因为其独特的属性,与平台挂钩,通过“全网最低价”的…
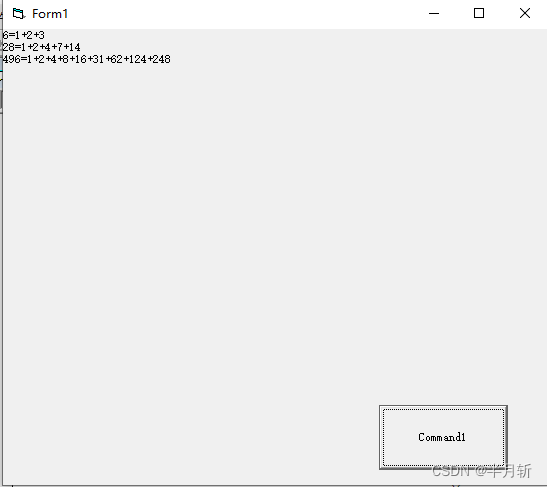
VB在窗体中显示1000以内的完数
VB在窗体中显示1000以内的完数
在窗体中显示1000以内的完数(如果一个整数的所有因子(包括1,但不包括本身)之和与该数相等,则称这个数字为完数。例如6123,所以6是一个完数)
Private Function Is…
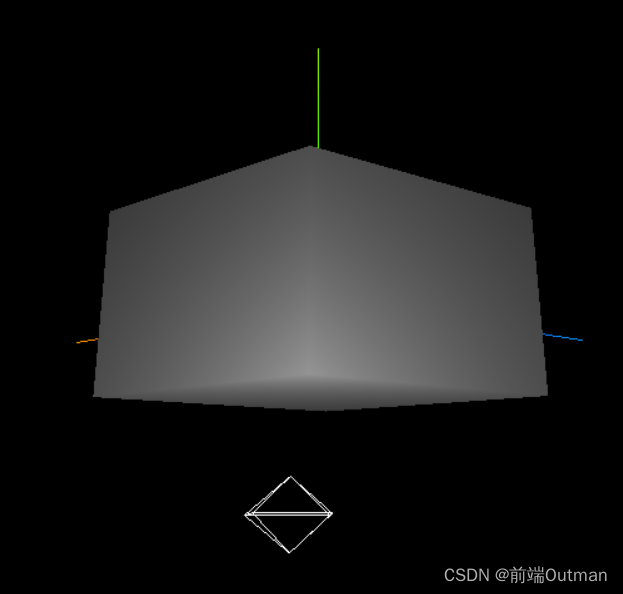
【前端知识】Three 学习日志(五)—— 点光源辅助观察
Three 学习日志(五)—— 点光源辅助观察
一、引入点光源辅助观察
// 光源辅助观察
const pointLightHelper new THREE.PointLightHelper(pointLight, 10);
scene.add(pointLightHelper);二、改变点光源位置
// 点光源位置
pointLight.position.set(2…
![[补题记录] Atcoder Beginner Contest 308(C~E)](https://img-blog.csdnimg.cn/18b7257c2e6f42b0aa734ffc712f372f.png)
[补题记录] Atcoder Beginner Contest 308(C~E)
URL:https://atcoder.jp/contests/abc308 目录
C
Problem/题意
Thought/思路
Code/代码
D
Problem/题意
Thought/思路
Code/代码
E
Problem/题意
Thought/思路
Code/代码 C
Problem/题意
给出n个(a,b)数对ÿ…

短视频矩阵系统源代码开发搭建分享--代码开源SaaS
一、什么是短视频矩阵系统? 短视频矩阵系统是专门为企业号商家、普通号商家提供帐号运营从流量 到转化成交的一站式服务方案,具体包含:点赞关注评论主动私信 ,评论区回复,自动潜客户挖掘,矩阵号营销&#x…

H3C ER G2系列路由器敏感信息泄露漏洞
声明 本文仅用于技术交流,请勿用于非法用途 由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,文章作者不为此承担任何责任。
一、产品介绍 H3C ER2200G2是H3C推出的新一代高性能企业级路由器&#…