推荐:使用 NSDT场景编辑器快速搭建3D应用场景
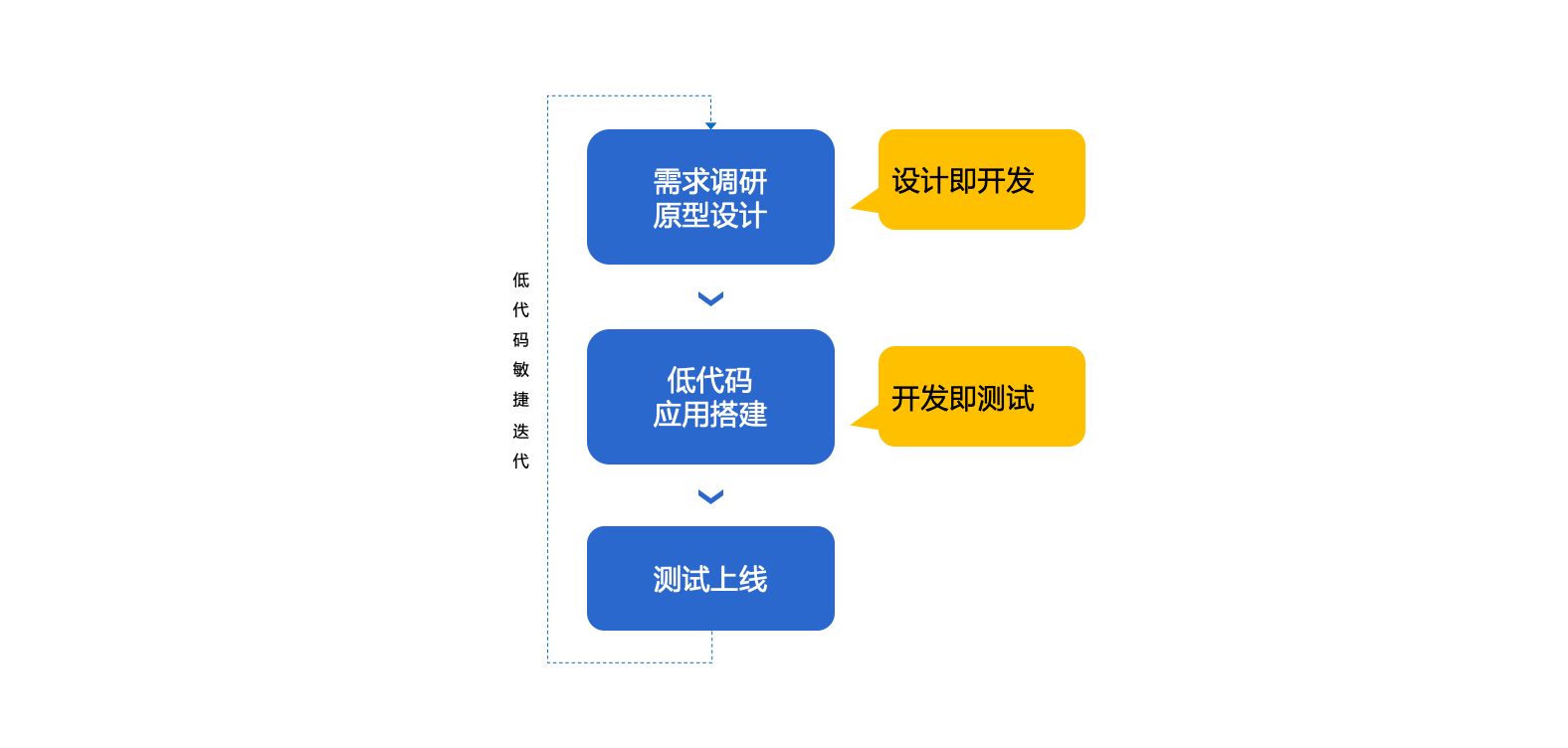
本文详细演示了风车动画的制作过程:
当然,这非常容易硬编码(有两个对象,一个静态的,一个旋转的)。但是,我计划稍后添加更多动画,因此我决定实施一个适当的解决方案。
以前,我对模型和动画使用了蹩脚的临时二进制格式,但最近由于多种原因,我切换到了glTF 模型:
- 易于解析:JSON 元数据 + 原始二进制顶点数据
- 它易于渲染:模型以直接映射到图形API的格式存储
- 它足够紧凑(繁重的东西 - 顶点数据 - 以二进制形式存储)
- 它是广泛和可扩展的
- 它支持骨骼动画
使用 glTF 模型意味着其他人可以轻松扩展游戏(例如,创作模组)。
不幸的是,使用 glTF 找到一个关于骨骼动画的好资源似乎是不可能的。所有教程都涵盖了一些较旧的格式,而glTF规范大多非常冗长和精确,在动画数据的解释方面异常简洁。我想这对专家来说应该是显而易见的,但我不是其中之一,如果你也不是——这是一篇适合你的文章:)
顺便说一句,我最终在他的 Vulkan + glTF 示例渲染器中对 Sascha Willems 的动画代码进行了逆向工程,以弄清楚如何正确执行此操作。
glTF 模型骨骼动画
如果您已经知道什么是骨骼动画,则可以安全地跳过本节:)
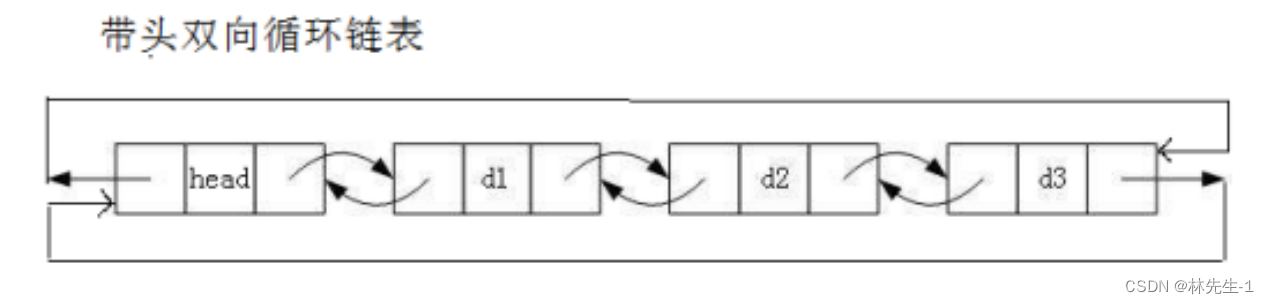
glTF 模型骨骼动画是迄今为止最流行的3D模型动画方法。这在概念上非常简单:你不是对实际模型进行动画处理,而是对模型的虚拟高度简化的骨架进行动画处理,模型本身被粘在这个骨架上,就像肉粘在骨头上一样。大致是这样看的:
以下是模型的顶点如何粘附到不同的骨骼上(红色是很多胶水,蓝色是没有胶水):
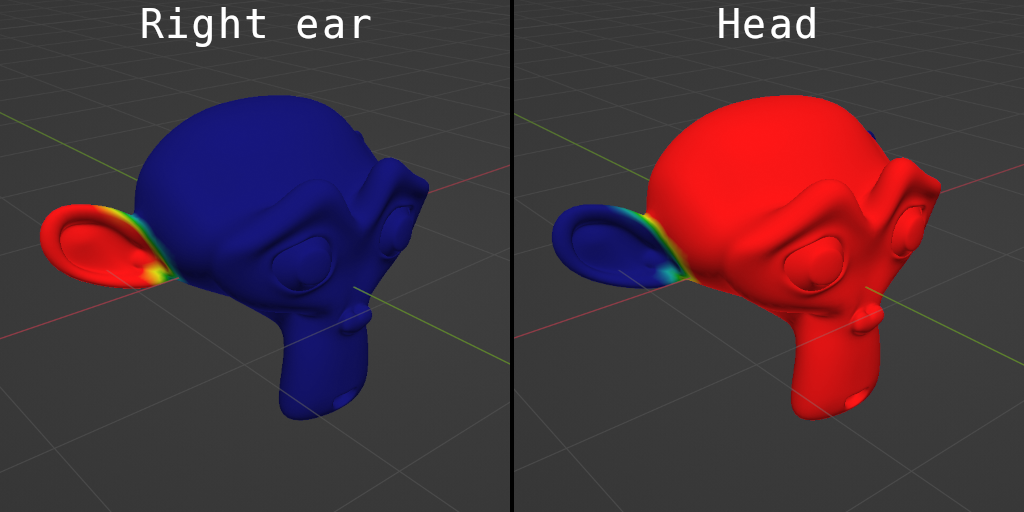
通常,每个网格顶点都粘附到具有不同权重的多个骨骼上,以提供更平滑的动画,并且顶点的最终转换在这些骨骼之间插值。如果将每个顶点仅粘合到单个骨骼上,则模型不同部分(例如通常是人类肩膀、肘部和膝盖)之间的过渡在动画时会出现令人不快的伪影:
这种方法的另一个关键部分是分层的:骨骼形成一棵树,子骨骼继承其父骨骼的转换。在此示例模型中,两块骨骼是骨骼的子项,骨骼是骨架的根。只有骨骼明确地上下旋转;从骨骼继承这种旋转。earheadheadearshead
这与大多数游戏引擎使用对象层次结构的原因相同。当你在移动的运输船上的汽车里有一个男人的头盔上有蚊子时,单独定义所有这些物体的运动是非常令人厌烦和容易出错的。相反,人们会定义飞船的运动,并指定对象形成一个层次结构,子对象继承父项的运动。蚊子是头盔的孩子,头盔是男人的孩子,等等。
同样,指定人的肩膀在旋转(并且整个手臂都是肩膀的孩子)要容易得多,而不是计算每个手臂骨骼的正确旋转。
glTF 模型优点和缺点
与替代方法 - 变形目标动画相比,它存储每个动画帧的所有顶点位置 - 它具有一些优点:
- 它需要更少的存储空间——骨架比模型小得多
- 每帧需要较少的数据流(只有骨骼,而不是整个网格,尽管有一些方法可以将整个动画存储在 GPU 上)
- 对于艺术家来说,使用起来(可以说)更容易
- 它将动画与特定模型分离 - 您可以将相同的行走动画应用于具有不同顶点数的许多不同模型
- 集成到程序动画中要容易得多——比如,你想限制角色的脚不穿过地形;使用骨骼动画,您只需向几个骨骼添加约束
不过,它有几个缺点:
- 您需要正确解析/解码您正在使用的动画格式(这比听起来更难)
- 您需要为每个动画模型计算每个骨骼的转换,这可能既昂贵又棘手(尽管我猜可以使用计算着色器来做到这一点)
- 您需要以某种方式将骨骼数据传输到 GPU,这不是顶点属性,可能不适合制服
- 您需要在顶点着色器中应用骨骼转换,使此着色器比平时慢 4 倍(不过仍然比典型的片段着色器便宜得多)
不过,它并不像听起来那么糟糕。让我们深入了解如何自下而上地实现它。
glTF 模型骨骼转化
因此,我们需要以某种方式动态转换网格顶点。每个骨骼都定义了一定的转换,通常由缩放、旋转和平移组成。即使你不需要缩放和平移,你的骨骼只旋转(这对于许多现实模型来说是合理的——试着将你的肩膀移出肩窝半米!),旋转仍然可以围绕不同的旋转中心发生(例如,当手臂围绕肩膀旋转时,手也会围绕肩膀旋转,而不是围绕手骨原点旋转), 这意味着无论如何您仍然需要翻译。
支持所有这些的最通用方法是简单地存储一个3×43×4 每个骨骼的仿射变换矩阵。这种变换通常是缩放、旋转和平移(按该顺序应用)的组合,表示为齐次坐标中的矩阵(这是一种将平移表示为矩阵等的数学技巧)。
我们可以单独存储一个平移向量(12 个浮点数)、一个旋转四元数(3 个浮点数)以及可能的均匀(4 个浮点数)或非均匀(1 个浮点数)缩放向量,而不是使用矩阵(即 3 个浮点数),总共给出 7、8 或 10 个浮点数。但是,正如我们稍后将看到的:,如果组件总数是 4 的倍数,则更容易将这些转换传递给着色器。因此,我最喜欢的选项是平移 + 旋转 + 均匀比例(8 个浮点数)或成熟的矩阵(12 个浮点数)。
无论如何,这些转换也应该已经考虑了父级的转换(我们稍后会这样做。我们称它们为全局转换,而不是不考虑父级的局部转换。所以,我们有一个这样的递归公式:
globalTransform(bone)=globalTransform(parent)⋅localTransform(bone)
全局变换(骨骼)=全局转换(父)⋅本地变换(骨骼)
如果骨骼没有父项,则与 .我们将在本文后面讨论这些 s 的来源。globalTransformlocalTransformlocalTransform
glTF 模型组合转换
顺便说一下,上面的等式可能有点误导。如果我们将变换存储为矩阵,我们如何乘以二3×43×4矩阵?这违反了矩阵乘法的规则!如果我们将它们存储为(平移、旋转、缩放)三元组,我们如何组成它们?
在矩阵的情况下,使用3×43×4矩阵实际上是一种优化。我们真正需要的是4×44×4矩阵,易于相乘。碰巧的是,仿射变换总是形式
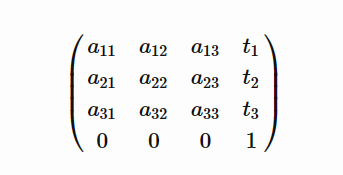
因此,实际存储第 4 行是没有意义的,但我们需要在进行计算时恢复它。事实上,可逆仿射变换是所有可逆矩阵组的一个子组。
矩阵的配方如下:附加一个(0001)(0001)行,乘以结果4×44×4矩阵,丢弃结果的最后一行,这也将是(0001)(0001).通过将左矩阵显式应用于右矩阵的列,有一些方法可以更有效地执行此操作,但通用公式仍然相同。
现在,将转换显式存储为平移、旋转和缩放是怎么回事,我们如何将它们相乘?好吧,只有一个公式!让我们将我们的转换表示为(T,R,S)– 平移向量、旋转运算符和比例因子。此转换对点的影响p是(T,R,S)⋅p=T+R⋅(S⋅p).让我们看看如果我们组合两个这样的转换会发生什么:

我使用了均匀缩放与旋转交换的事实。事实上,它可以与任何东西通勤!
因此,以这种形式将两个变换相乘的公式是

请注意,R是旋转运算符,而不是旋转四元数。对于旋转四元数Q,旋转的组成不会改变,但它作用于矢量的方式会发生变化:

另请注意,此技巧不适用于非均匀缩放:本质上,如果R是一个旋转和S是比例不均,没有办法表达产品S⋅R作为类似的东西R′⋅S′对于其他一些轮换R′和不均匀缩放S′
.在这种情况下,只使用矩阵更简单。
顶点着色器
这简直是一口解释!让我们来看看一些真正的代码,特别是顶点着色器。我将使用 GLSL,但特定的语言或图形 API 在这里并不重要。
假设我们已经以某种方式将每骨骼全局转换传递到着色器中(我们将在一分钟内讨论它)。我们还需要一些方法来判断哪个顶点连接到哪个骨骼以及重量。这通常使用两个额外的顶点属性来完成:一个用于骨骼 ID,一个用于骨骼权重。通常,每个模型不需要超过 256 个骨骼,并且权重也不需要那么高的精度,因此可以将整数属性用于 ID,对权重使用规范化属性。由于属性在大多数图形 API 中最多是 4 维的,因此我们通常只允许将顶点粘附到 4 个或更少的骨骼上。例如,如果一块骨头只粘在 2 块骨头上,我们只需附加两个权重为零的随机骨骼 ID,然后调用它一天。uint8uint8
说得够多了:
// somewhere: mat4x3 globalBoneTransform[]
uniform mat4 uModelViewProjection;
layout (location = 0) in vec3 vPosition;
// ...other attributes...
layout (location = 4) in ivec4 vBoneIDs;
layout (location = 5) in vec4 vWeights;
void main() {
vec3 position = vec3(0.0);
for (int i = 0; i < 4; ++i) {
mat4x3 boneTransform = globalBoneTransform[vBoneIDs[i]];
position += vWeights[i] * (boneTransform * vec4(vPosition, 1.0));
}
gl_Position = uModelViewProjection * vec4(position, 1.0);
}在 GLSL 中,对于向量 v,v[0] 与 v.x 相同,v[1] 是 v.y 等。
我们在这里做的是
- 迭代顶点附加到的 4 个骨骼
- 读取骨骼的 ID 并获取其全局转换
vBoneIDs[i] - 将全局变换应用于齐次坐标 vec4(vPosition, 1.0) 中的顶点位置
- 将加权结果添加到生成的折点
position - 将通常的
MVP矩阵应用于结果
整个过程也称为蒙皮,或者更具体地说是线性混合蒙皮。
在 GLSL 中,matNxM 表示 N 列和 M 行,因此 mat4x3 实际上是一个 3x4 矩阵。我喜欢标准。
如果你不确定你的权重总和是1,我们也可以最后除以它们的总和(尽管你最好确保它们的总和是1!
position /= dot(vWeights, vec4(1.0));如果 weigts 的总和不等于 1,则会得到失真。从本质上讲,您的顶点将更接近或远离模型原点(取决于总和是< 1 还是> 1)。这与透视投影有关,也与仿射变换不形成线性空间,但它们确实形成仿射空间这一事实有关。
如果我们也有法线,它们也需要变换。唯一的区别是位置是一个点,而法线是一个向量,因此它在齐次坐标中具有不同的表示形式(我们将 0 作为 w 坐标而不是附加 1)。我们可能还想在之后对其进行规范化,以考虑缩放:
// somewhere: mat4x3 globalBoneTransform[]
uniform mat4 uModelViewProjection;
layout (location = 0) in vec3 vPosition;
layout (location = 1) in vec3 vNormal;
// ...other attributes...
layout (location = 4) in ivec4 vBoneIDs;
layout (location = 5) in vec4 vWeights;
vec3 applyBoneTransform(vec4 p) {
vec3 result = vec3(0.0);
for (int i = 0; i < 4; ++i) {
mat4x3 boneTransform = globalBoneTransform[vBoneIDs[i]];
result += vWeights[i] * (boneTransform * p);
}
return result;
}
void main() {
vec3 position = applyBoneTransform(vec4(vPosition, 1.0));
vec3 normal = normalize(applyBoneTransform(vec4(vNormal, 0.0)));
// ...
}请注意,如果您使用非均匀缩放,或者想要进行眼部空间照明,事情会变得有点复杂。
将变换传递给着色器
我主要使用 OpenGL 3.3 来制作图形内容,因此本节的详细信息是特定于 OpenGL 的,我相信一般概念适用于任何图形 API。
大多数骨骼动画教程建议使用统一数组进行骨骼转换。这是一种简单的工作方式,但可能会有点问题:
- OpenGL对制服的数量有限制。OpenGL 3.0 保证至少 1024 个组件,松散地说,这意味着我们矩阵的单个元素。因此,对于需要 12 个组件的 ,我们受每个模型的骨骼约束。这已经很多了,所以实际上可能就足够了。虽然,很多制服已经用于其他东西(矩阵、纹理等),所以我们通常没有那么多免费的制服。实际上,我们通常有 4096 到 16384 个组件。
mat4x31024/12 ~ 85 - 我们必须更新每个动画模型的统一数组,这意味着大量的OpenGL调用,没有实例化。
通过使用统一缓冲区可以在一定程度上解决此问题:
- 通过特殊化,它们有更多的可用内存,但仍然没有那么多 - 通常为 64 KB 的缓冲区。
- 我们不需要将所有骨骼转换上传到制服,而是可以一次性将所有模型的所有转换上传到缓冲区。我们仍然必须为每个模型调用 glBindBufferRange 以指定该模型的骨骼数据所在的位置,因此没有实例化。
如果您使用的是 OpenGL 4.3 或更高版本,则可以简单地将所有转换存储在着色器存储缓冲区对象中,该对象的大小基本上不受限制。否则,您可以使用缓冲区纹理,这是一种访问任意数据缓冲区的方法,将其伪装成一维纹理。缓冲区纹理本身不存储任何内容,它仅引用现有缓冲区。它的工作原理是这样的:
- 我们创建一个常用的 OpenGL 并用所有模型的骨骼变换填充它,每帧存储为例如逐行矩阵(12 个浮点数)或具有均匀缩放的 TRS 三元组(8 个浮点数)
GL_ARRAY_BUFFER - 我们创建一个 and call – 是这种纹理的像素格式,即每个像素 4 个浮点数(12 个字节)(因此每个矩阵 3 个像素或每个 TRS 三元组 2 个像素)
GL_BUFFER_TEXTUREglTexBuffer(GL_BUFFER_TEXTURE, GL_RGBA32F, bufferID);RGBA32F - 我们将纹理附加到着色器中的制服上
samplerBuffer - 我们读取着色器中的相应像素并将它们转换为骨骼变换
texelFetch
对于实例化渲染,此着色器可能如下所示:
uniform samplerBuffer uBoneTransformTexture;
uniform int uBoneCount;
mat4x3 getBoneTransform(int instanceID, int boneID) {
int offset = (instanceID * uBoneCount + boneID) * 3;
mat3x4 result;
result[0] = texelFetch(uBoneTransformTexture, offset + 0);
result[1] = texelFetch(uBoneTransformTexture, offset + 1);
result[2] = texelFetch(uBoneTransformTexture, offset + 2);
return transpose(result);
}请注意,我们将矩阵组装为 4x3 矩阵(在 GLSL 中),但从纹理中读取行并将其写入矩阵的列,然后转置它,切换行和列。这仅仅是因为 GLSL 使用列主矩阵。mat3x4
回顾
让我们回顾一下:
- 为了对模型进行动画处理,我们将每个顶点附加到虚拟骨架的最多 4 个骨骼上,具有 4 个不同的权重
- 每个骨骼定义一个需要应用于顶点的全局转换
- 对于每个顶点,我们应用它所附着的 4 个骨骼的变换,并使用权重对结果求平均值
- 我们将变换存储为 TRS 三元组或 3x4 仿射变换矩阵
- 我们将转换存储在统一数组、统一缓冲区、缓冲区纹理或着色器存储缓冲区中
我们剩下的就是这些全球转型从何而来。
全局转换
好吧,实际上,我们已经知道全局转换的来源:它们是从本地转换计算出来的:
globalTransform(bone)=globalTransform(parent)⋅localTransform(bone)全局变换(骨骼)=全局转换(父)⋅本地变换(骨骼)
计算这种方法的天真方法类似于计算所有转换的递归函数:
mat4 globalTransform(int boneID) {
if (int parentID = parent[boneID]; parentID != -1)
return globalTransform(parentID) * localTransform[boneID];
else
return localTransform[boneID];
}或同样的事情,但手动展开尾递归:
for (int boneID = 0; boneID < nodeCount; ++boneID) {
globalTransform[boneID] = identityTransform();
int current = boneID;
while (current != -1) {
globalTransform[boneID] = localTransform[current] * globalTransform[boneID];
current = nodeParent[current];
}
}这两种方法都很好,但它们计算的矩阵乘法比必要的要多得多。请记住,我们应该在每一帧、每个动画模型上都这样做!
计算全局变换的更好方法是从父级到子级:如果父级的全局变换已经计算完毕,我们需要做的就是每个骨骼进行一次矩阵乘法。
// ... somehow make sure parent transform is already computed
if (int parentID = parent[boneID]; parentID != -1)
globalTransform[boneID] = globalTransform[parentID] * localTransform[boneID];
else
globalTransform[boneID] = localTransform[boneID];为了确保父计算先于子项计算,您需要在骨骼树上进行一些 DFS 以正确排序骨骼。一个可以说更简单的解决方案是提前计算骨树的拓扑排序(骨骼的枚举,以便父母先于孩子)并在每一帧使用它。(顺便说一句,无论如何,计算拓扑排序都是使用 DFS 完成的。更简单的解决方案是确保骨骼ID有效地是拓扑排序,即始终成立。这可以通过在加载时对骨骼(和网格顶点属性!)重新排序来完成,或者要求美术师以这种方式对骨骼进行排序:)嗯,他们模特的骨头,就是这样。parent[boneID] < boneID
在后一种情况下,实现是最简单(也是最快的):
for (int boneID = 0; boneID < nodeCount; ++boneID) {
if (int parentID = parent[boneID]; parentID != -1)
globalTransform[boneID] = globalTransform[parentID] * localTransform[boneID];
else
globalTransform[boneID] = localTransform[boneID];
}但是,本地转换从何而来?
本地转换
这就是事情变得有点古怪的地方(好像它们还没有)。您会看到,通常可以方便地在某些特殊坐标系中指定局部骨骼变换,而不是世界坐标。如果我旋转手臂,局部坐标系的原点位于旋转的中心,而不是我脚下的某个地方,这样我就不必明确解释这种平移。此外,如果我上下旋转它,就像向远处的人挥手一样,我真的希望它是围绕局部空间中的某个坐标轴(也许是 X)旋转,而不管模型在模型空间和世界空间中的方向如何。
我想说的是,我们希望每个骨骼都有一个特殊的坐标系(CS),我们希望用这个坐标系来描述骨骼局部变换。
但是,模型的顶点位于模型的坐标系中(这是此坐标系的定义)。因此,我们需要一种方法来首先将顶点转换为骨骼的局部坐标系。这被称为反向绑定矩阵,因为它听起来真的很酷。
好的,我们已经将顶点转换为骨骼的本地 CS,并在此本地 CS 中应用了动画转换(我们稍后会介绍它们)。仅此而已吗?请记住,接下来的事情是将其与父骨骼的转换相结合,母骨骼将位于它自己的坐标系中!因此,我们需要另一件事:将顶点从骨骼局部CS转换为父级的局部CS。顺便说一下,这可以使用逆绑定矩阵来完成:将顶点从骨骼的局部 CS 转换回模型 CS,然后将其转换为父级的局部 CS:
convertToParentCS(node)=inverseBindMatrix(parent)⋅inverseBindMatrix(node)−1convertToP一个rentCS(node)=我nverseB我ndM一个tr我x(p一个rent)⋅我nverseB我ndM一个tr我x(node)−1
我们也可以这样想:特定的骨骼将顶点转换为它的本地 CS,应用动画,然后将它们转换回来;然后它的父级将顶点转换为它自己的本地 CS,应用它自己的动画,然后将它们转换回来;等等。
实际上,我们实际上并不需要在glTF中显式地使用这种converToParent转换,但是考虑一下还是很有用的。
还有一件事。有时,(对于艺术家或 3D 建模软件)将顶点附加到骨骼上不是在模型的默认状态下,而是处于某种转换状态(称为绑定姿势)是很方便的。因此,我们可能需要另一个转换,对于每个骨骼,将顶点转换为该骨骼期望顶点所在的 CS。我知道,这听起来令人困惑,但请耐心等待,我们实际上不需要这种转变:)
点击查看熊

Blender使用世界空间顶点位置作为绑定姿势。如果模型距离原点沿 X 轴 20 个单位,则其原始顶点位置将在 X=20 左右,逆绑定矩阵将对此进行补偿。这有效地使从Blender导出的动画模型在没有动画的情况下无法使用。
glTF 模型转换回顾
总的来说,我们有以下一系列变换应用于顶点:
- 将其转换为模型绑定姿势
- 转换为骨骼局部 CS(逆绑定矩阵)
- 应用实际该死的动画(在本地CS中指定)
- 从骨骼局部 CS 转变回来
- 如果骨骼有父骨骼,请对父骨骼重复步骤 2-5
现在,问题是每种格式都定义了自己指定这些格式的方式。事实上,其中一些转换甚至可能不存在——它们应该包含在其他转换中。
最后来说说glTF。
glTF 模型 101
glTF是由Khronos Group开发的一种非常酷的3D场景创作格式 - OpenGL,OpenCL,Vulkan,WebGL和SPIR-V等背后的人。我已经在文章开头说过为什么我认为这是一种很酷的格式,所以让我们更多地谈谈细节。
这是glTF-2.0的规范。它非常好,只需阅读规范即可学习格式。
glTF 场景由节点组成,这些节点是抽象的,可能意味着很多事情。节点可以是渲染的网格、摄像机、光源、骨架骨骼,也可以只是其他节点的聚合父节点。每个节点都有自己的仿射变换,它定义了它相对于父节点(或世界原点,如果没有父节点)的位置、旋转和比例。
glTF 通过访问器描述所有二进制数据 – 基本上,引用一些二进制缓冲区的一部分,其中包含具有指定类型的数组(元素之间可能具有非零间隙)(例如,一个 100 的连续数组,其组件在此特定二进制文件中以字节开头,诸如此类)。vec4float326340
如果网格节点使用骨架动画,则它有一个列表,其中是指定骨架骨骼的 glTF 节点的 ID。(实际上,网格引用了一个皮肤,而皮肤又包含关节。这些关节形成一个层次结构——它们仍然是glTF节点,因此它们可以有父母和孩子。请注意,没有骨架或骨架节点——只有骨骼节点;同样,动画网格不是骨骼节点或骨架节点的子节点,而是间接引用它们(尽管导出软件可能会添加人工骨架节点,例如 Blender 这样做,但 glTF 不需要)。joints
网格的每个顶点属性(实际上是网格基元的)——位置、法线、UV 等——都是一个单独的访问器。当网格使用骨骼动画时,它还具有骨骼 ID 和权重属性,这也是一些访问器。骨骼的实际动画也存储在访问器中。
除了蒙皮网格的描述外,glTF 模型还可能包含一些实际的动画 - 本质上,有关如何更改上述列表中的第三个转换的说明。
glTF 变换
以下是 glTF 模型如何在上面的 1-5 列表中存储所有转换:
- 模型绑定姿势应该已经应用于模型,或者预乘到反向绑定矩阵。换句话说,只需忘记glTF的绑定姿势即可。
- 每骨逆绑定矩阵被指定为另一个访问器 – 一个 4x4 矩阵的数组(需要是仿射变换,因此只有前 3 行是有趣的)。
- 实际动画可以在外部定义(例如程序动画),也可以存储为关键帧样条,用于每个骨骼的旋转、平移和缩放。这里重要的是这些是...
- ...结合从本地CS到父级本地CS的转变。因此,骨骼动画是结合在一起的。
convertToParent - 父级由节点层次结构定义,但由于我们已经应用了转换,因此我们不需要父级的反向绑定矩阵,因此我们只对父级重复步骤 3-5(如果有)。
convertToParent
因此,在使用 glTF 时,骨骼的全局转换如下所示
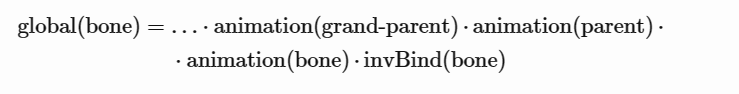
在代码中,这将是
// assuming parent[boneID] < boneID holds
// somehow compute the per-bone local animations
// (including the bone-CS-to-parent-CS transform)
for (int boneID = 0; boneID < boneCount; ++boneID) {
transform[boneID] = ???;
}
// combine the transforms with the parent's transforms
for (int boneID = 0; boneID < boneCount; ++boneID) {
if (int parentID = parent[boneID]; parentID != -1) {
transform[boneID] = transform[parentID] * transform[boneID];
}
}
// pre-multiply with inverse bind matrices
for (int boneID = 0; boneID < boneCount; ++boneID) {
transform[boneID] = transform[boneID] * inverseBind[boneID];
}此数组是上面顶点着色器中的数组。transform[]globalBoneTransform[]
毕竟没有那么复杂!只需要找出正确的顺序将一堆看似随机的矩阵相乘:)
glTF动画
最后,让我们谈谈如何应用直接存储在glTF 模型中的动画。它们被指定为关键帧样条,用于每个骨骼的旋转、缩放和平移。
每个单独的样条称为一个通道。它定义了:
- 它应用于哪个节点(例如骨架)
- 它影响哪个参数(旋转、缩放或平移)
- 关键帧时间戳的访问器
- 关键帧值的访问器(用于旋转的四元数、用于缩放或平移的矢量)
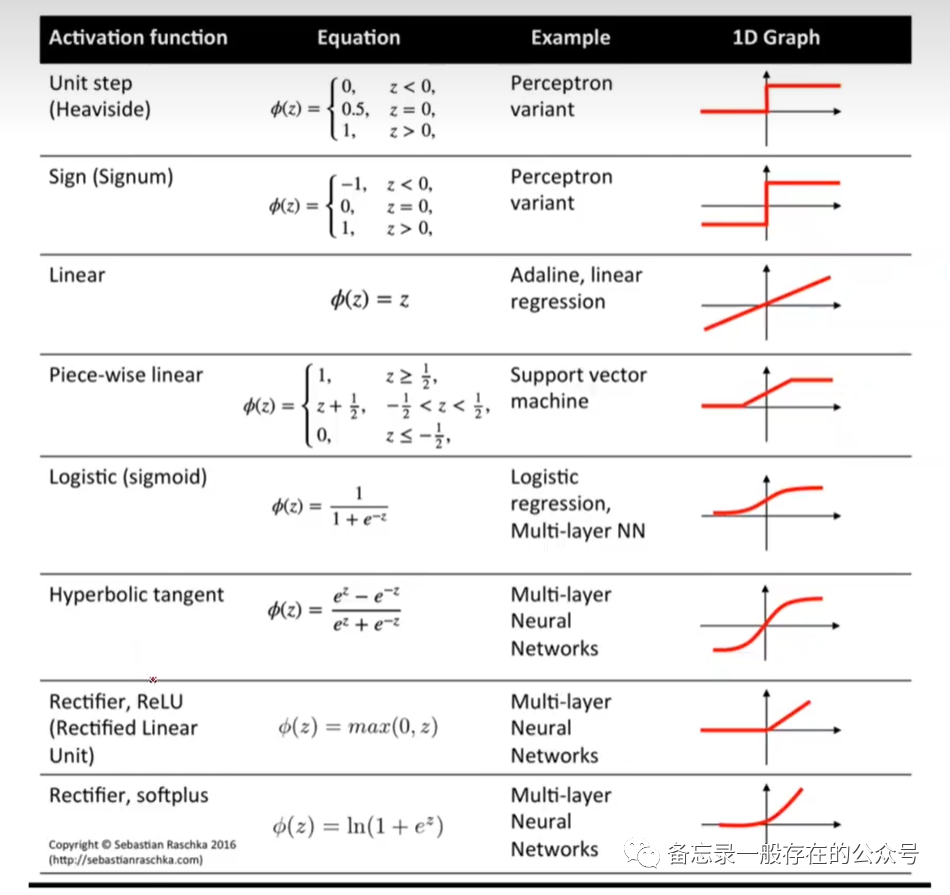
vec4vec3 - 插值方法 – 、 或
STEPLINEARCUBICSPLINE
对于旋转,LINEAR实际上意味着球形线性。 对于 CUBICSPLINE 插值,每个关键帧存储 3 个值 – 样条值和两个切向量。
因此,我们为骨骼构建局部变换的方式是:
- 对当前时刻此骨骼的旋转、平移和缩放样条进行采样
- 将它们组合在一起形成局部转换矩阵
对于矢量翻译(x,y,z)对应的矩阵为
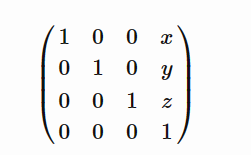
对于非均匀缩放向量(x,y,z)矩阵是
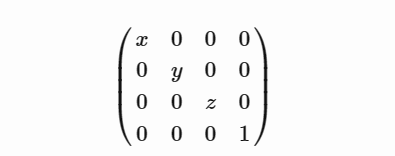
对于旋转四元数,您可以在 wiki 文章中找到矩阵 – 它将是一个 3x3 矩阵,您将其放入 4x4 矩阵的左上角,如下所示:
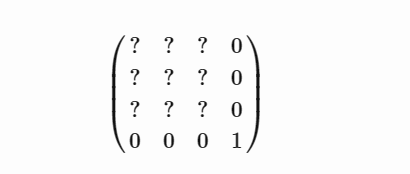
正如我们之前所讨论的,这些矩阵是 4x4,但它们实际上是仿射变换,所以有趣的事情只发生在前 3 行。
采样动画样条
为了解决最后一点 - 有效地对动画样条进行采样 - 我们可以将样条收集到如下所示的类中:
template <typename T>
struct animation_spline {
// ...some methods...
private:
std::vector<float> timestamps_;
std::vector<T> values_;
};现在,一个明显的 API 决策是创建一个在某个特定时间返回样条值的方法:
template <typename T>
T value(float time) const {
assert(!timestamps_.empty());
if (time <= timestamps_[0])
return values_[0];
if (time >= timestamps_[1])
return values_[1];
for (int i = 1; i < timestamps_.size(); ++i) {
if (time <= timestamps_[i]) {
float t = (time - timestamps_[i - 1]) / (timestamps_[i] - timestamps_[i - 1]);
return lerp(values_[i], values_[i + 1], t);
}
}
}应根据插值类型以及这是否是旋转来更改 lerp 调用。
这有效,但我们可以通过两种方式改进它。首先,我们的关键帧时间戳是保证排序的,因此对于线性搜索,我们可以进行二叉搜索:
template <typename T>
T value(float time) const {
auto it = std::lower_bound(timestamps_.begin(), timestamps_.end(), time);
if (it == timestamps_.begin())
return values_.front();
if (it == timestamps_.end())
return values_.back();
int i = it - timestamps_.begin();
float t = (time - timestamps_[i - 1]) / (timestamps_[i] - timestamps_[i - 1]);
return lerp(values_[i - 1], values_[i], t);
}其次,在播放动画时,我们总是从头到尾线性遍历它,因此我们可以通过存储当前的关键帧索引来进一步优化它。不过,这不是动画本身的属性,所以让我们创建另一个类:
template <typename T>
struct animation_spline {
// ...
private:
std::vector<float> timestamps_;
std::vector<T> values_;
friend class animation_sampler<T>;
};
template <typename T>
struct animation_sampler {
animation_spline<T> const & animation;
int current_index;
T sample(float time) {
while (current_index + 1 < animation.timestamps_.size() && time > animation.timestamps_[current_index + 1])
++current_index;
if (current_index + 1 >= animation.timestamps_.size())
current_index = 0;
float t = (time - timestamps_[current_index]) / (timestamps_[current_index + 1] - timestamps_[current_index]);
return lerp(values_[current_index], values_[current_index + 1], t);
}
};原文链接:glTF模型骨骼动画 (mvrlink.com)