🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+

目录
一、Python分析文本数据的优点
二、Python分析文本常用的第三方库
三、词频分析
四、词云图分析
五、文末推荐与福利
一、Python分析文本数据的优点
-
广泛的库和工具支持:Python拥有丰富的文本分析库,如NLTK(自然语言工具包)、spaCy、TextBlob、Gensim等,这些库提供了各种文本处理和分析功能,使得文本分析任务更容易实现。
-
易于学习和使用:Python是一门容易学习的编程语言,因此即使是初学者也可以快速上手文本分析任务。Python的简洁语法和清晰的代码结构有助于更好地理解和维护分析代码。
-
社区支持:Python拥有庞大的开发者社区,这意味着可以轻松找到答案、解决问题,并获得有关文本分析的支持和建议。
-
跨平台性:Python是一种跨平台的编程语言,可以在Windows、Linux和Mac等操作系统上运行,因此非常适合各种不同环境中的文本分析。
-
数据处理能力:Python拥有强大的数据处理和操作库,如NumPy和Pandas,这些库使得数据清洗、转换和分析变得更加容易。
-
可视化能力:Python中的库,如Matplotlib、Seaborn和Plotly,可以用于生成各种数据可视化,帮助用户更好地理解和展示文本数据的分析结果。
-
机器学习和深度学习支持:Python在机器学习和深度学习方面表现出色,因此可以使用各种机器学习和深度学习模型来进行文本分类、情感分析、命名实体识别等任务。
-
开源和免费:Python是一种开源的编程语言,可以免费使用,这意味着无需额外费用就可以进行文本分析。
-
丰富的文档和教程:有大量的在线文档、教程和示例代码可用于帮助用户学习和实践文本分析。
二、Python分析文本常用的第三方库
-
NLTK(Natural Language Toolkit):NLTK是一款广泛用于自然语言处理的库,提供了文本分词、词性标注、命名实体识别、语法分析等功能,以及大量的语料库和数据集。
-
spaCy:spaCy是一个高度优化的自然语言处理库,具有出色的性能和功能,支持分词、命名实体识别、词性标注等任务,并支持多语言。
-
TextBlob:TextBlob是一个简单而易于使用的库,用于执行各种文本分析任务,包括情感分析、文本分类、词性标注等。
-
Gensim:Gensim是一个用于主题建模和文本向量化的库,特别适用于处理大型文本语料库和文本文档集合。
-
Scikit-learn:虽然Scikit-learn主要用于机器学习,但它也提供了文本特征提取、文本分类和聚类等文本分析的工具和算法。
-
Word2Vec:Word2Vec是一个用于词嵌入(word embedding)的库,可以将词汇转换为向量表示,以便进行文本分析和自然语言处理任务。
-
Pattern:Pattern是一个用于文本挖掘和自然语言处理的库,支持词性标注、情感分析、信息提取等任务。
-
Spacy-transformers:这是spaCy的一个扩展库,使其能够使用预训练的Transformer模型(如BERT、GPT-2)进行文本分析。
-
TfidfVectorizer:TfidfVectorizer是Scikit-learn的一部分,用于将文本数据转换为TF-IDF(Term Frequency-Inverse Document Frequency)特征表示,常用于文本分类和信息检索。
-
NLTK和TextBlob的情感分析模块:这些库提供了用于情感分析的功能,可用于判断文本的情感倾向,如积极、消极或中性。
-
Matplotlib、Seaborn和Plotly:这些库用于可视化文本数据分析结果,可以生成各种图表和图形,帮助更好地理解文本数据。
三、词频分析
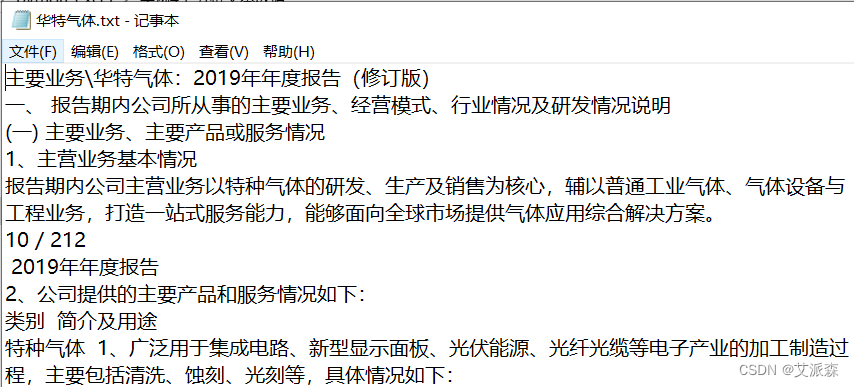
上次批量提取了上市公司主要业务信息,要分析这些文本数据,就需要做文本词频分析。由于中文不同于英文,词是由一个一个汉字组成的,而英文的词与词之间本身就有空格,所以中文的分词需要单独的库才能够实现,常用的是`jieba`。若没安装,直接运行`cmd`,然后输入`pip install jieba`安装即可。然后导入`jieba`库。我们以“华特气体”公司的主要业务进行分词,分词前如下图所示。通过`open`打开华特气体文本文件,使用读模式`r`,为避免编码错误,指定编码类型为`utf-8`。读取出来是一个大字符串,将这个大字符串存入`txt`。然后调用`jieba`进行分词。`lcut`的意思是切分词后再转换成列表("l"即表示`list`的首字母)。将切分后的词存入列表`words`。
import jieba
txt = open("华特气体.txt", "r", encoding="utf-8").read()
words = jieba.lcut(txt)
words 
结果如上,可见基本是按照我们的汉字使用习惯来区分词的,不能组成词的字则是按单独一个字符串存放的。然后我们就需要将词和对应出现的次数统计出来。先新建一个字典`wordsDict`用于储存词及其出现的次数。对于单个的字或字符不是我们想要的,所以加了一个`if`语句将其排除在外。`continue`的作用是,`if`后面的条件满足时,让程序回到`for`循环,而不执行`continue`下面的语句。也就是列表中的元素只有一个字符的时候,就马上跳到下一个而不执行任何操作。只有当元素不止一个字符的时候,才执行`else`语句,即将词及其出现的次数加入字典。此处用`setdefault`给词的出现初始值设置为0,每重复出现一次,自动加1。然后我们根据此出现的次数,降序排序,并查看前20个词的情况。
wordsDict = {} #新建字典用于储存词及词频
for word in words:
if len(word) == 1: #单个的字符不作为词放入字典
continue
else:
wordsDict.setdefault(word, 0) #设置词的初始出现次数为0
wordsDict[word] +=1 #对于重复出现的词,每出现一次,次数增加1
wordsDict_seq = sorted(wordsDict.items(),key=lambda x:x[1], reverse=True) #按字典的值降序排序
wordsDict_seq[:15] 
可以看到,有些词并不是我们想要的,比如“公司”、“行业”、“000”。因此需要把这些意义不大的词删除。先定义一个储存要排除的词的列表`stopWords`,将想排除的词放进去,一般是放出现次数较多,但意义不大的词,可根据实际需要调整。然后遍历这个字典,在检查这些词是否在目标字典`wordsDict`中,如果在,就将字典中这个词对应的数据删除。
stopWords = ["公司","行业","000","用于","情况","方面","一种","要求","对于","进行","一般","212","实现","处理","通过","投入","随着"]
for word in stopWords:
if word in wordsDict:
del wordsDict[word] #删除对应的词
wordsDict_seq = sorted(wordsDict.items(),key=lambda x:x[1], reverse=True) #按字典的值降序排序
wordsDict_seq[:15] 
然后将筛选后的数据转换成DataFrame,并增加列名“词”和“次数”,然后导出为Excel文件。
df = pd.DataFrame(wordsDict_seq,columns=['词','次数'])
df.to_excel("华特气体-词频.xlsx",index = False) #存为Excel时去掉index索引列
df.head(10)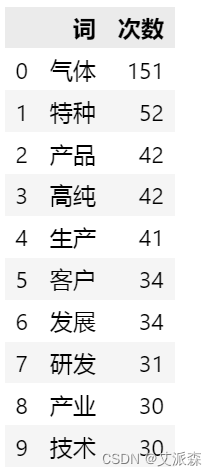
以上,搞定了一个文件的词频收集,那批量操作呢?请看下面分解。
import os
path='主要业务' #文件所在文件夹
files = [path+"\\"+i for i in os.listdir(path)] #获取文件夹下的文件名,并拼接完整路径
files 
以上,先获取到所有待分析文件的路径。然后逐个进行分析。稍微修改一下上面的程序,很快分析完成。结果如下。
import jieba
import pandas as pd
for file in files:
txt = open(file, "r", encoding="utf-8").read()
words = jieba.lcut(txt)
wordsDict = {} #新建字典用于储存词及词频
for word in words:
if len(word) == 1: #单个的字符不作为词放入字典
continue
else:
wordsDict.setdefault(word, 0) #设置词的初始出现次数为0
wordsDict[word] +=1 #对于重复出现的词,每出现一次,次数增加1
stopWords = ["2019","不断","持续","主要","企业","产品","业务","公司","行业","000","用于","情况","方面","一种","要求","对于","进行","一般","212","实现","处理","通过","投入","随着"]
for word in stopWords:
if word in wordsDict:
del wordsDict[word] #删除对应的词
wordsDict_seq = sorted(wordsDict.items(),key=lambda x:x[1], reverse=True) #按字典的值降序排序
df = pd.DataFrame(wordsDict_seq,columns=['词','次数'])
df.to_excel("词频//{}.xlsx".format(file.split("\\")[1][:-4]),index = False) #存为Excel时去掉index索引列四、词云图分析
如果要将上面做好的词频分析可视化,“词云图”是一个很好的选择。它的原理是,将词频高的词显示得相对更大一些。而且可以自定义背景图,让词云显示成个性化的形状。今天我们就来将上次获取的10家上市公司的“主要业务”词频文件批量生成词云图,这样一看词云图就大致了解这家公司的主要业务是什么了,放在PPT里展示也显得高大上。首先,我们导入需要用到库。若显示导入不成功,则需要用`pip install + 库名`进行安装。
import numpy as np # numpy数据处理库
import wordcloud # 词云库
from PIL import Image # 图像处理库,用于读取背景图片
import matplotlib.pyplot as plt # 图像展示库,以便在notebook中显示图片
from openpyxl import load_workbook #读取词频Excel文件
import os #获取词频Excel文件路径然后获取所有的Excel词频表路径,以便后续逐一读取,并传入词云库生成词云图。再定义词频背景图,`np.array(Image.open())`打开图片后转为数组,存入`maskImage`变量。需要注意词频背景图中想要的形状的背景需要是白色的,不然无法得到想要的词云图形状。比如如下背景图片,左边的图片因为猴子的背景不是白色,做出的词云图会占满整个图片,即是一个矩形的词云图;右边的图片中,猴子的背景是白色的,做出的词云图看起来就是一只猴子的形状。

然后用`for`循环遍历所有待处理的Excel文件,逐个打开,提取其中的词和词频,存入字典`wordFreq`。然后通过`wordcloud.WordCloud()`定义词云样式。这个函数有很多参数,具体如下。我们只需要关注常用的几个即可,其它可作为了解。
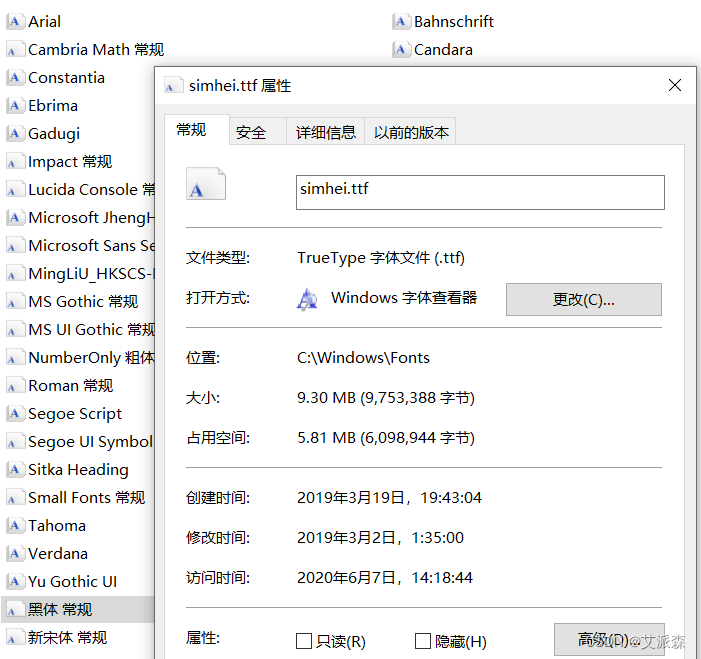
wordcloud.WordCloud(font_path=None, width=400, height=200, margin=2, ranks_only=None, prefer_horizontal=0.9, mask=None, scale=1, color_func=None, max_words=200, min_font_size=4, stopwords=None, random_state=None, background_color='black', max_font_size=None, font_step=1, mode='RGB', relative_scaling='auto', regexp=None, collocations=True, colormap=None, normalize_plurals=True, contour_width=0, contour_color='black', repeat=False, 'include_numbers=False', 'min_word_length=0', 'collocation_threshold=30')`font_path`:字体路径。字体存在`C:\Windows\Fonts`目录,在想要的字体上点右键,选择“属性”可查看其名称,然后连同路径复制,赋给font_path即可。比如本例使用的黑体。需要注意的是,若是中文词云,需要选中文字体。
`width,height`:画布的宽度和高度,单位为像素。若没设置`mask`值,才会使用此默认值400*200。
`margin`:词间距。
`ranks_only`:文档未说明。
`prefer_horizontal`:词语横排显示的概率(默认为90%,则竖排显示概率为10%)
`mask`:用于设定绘制模板,需要是一个`nd-array`(多维数组),所以在用`Image.open()`读取图片后,需要用`np.array`转换成数组。另外`mask`参数有设定的话,画布的大小会由词频背景图的大小决定。这个经常使用,因为我们更倾向于自定义模板。
`scale`:比例尺,用于放大画布的尺寸。一般使用默认值。
`color_func`:颜色函数,一般不用。
`max_words`:词云图中最多显示词的字数,设定一个值,可让那些出现次数极少的词不显示出来。
`min_font_size`:字号最小值。
`stopwords`:设置不想显示的词。
`random_state`:文档未说明。
`background_color`:词云图背景色,默认为黑色。可根据需要调整。
`max_font_size`:字号最大值。
`font_step`:字体的步长,一般使用默认。大于1的时候可提升运算速度,但匹配较差。
`mode`:当设置为"RGBA" 且`background_color`设置为"None"时可产生透明背景。
`relative_scaling`:词频对字体大小的影响度,一般使用默认。
`regexp`:正则表达式分割输入的字符。一般是先处理好才给到wordcloud,所以基本不用。
`collocations`:是否包含两个词的搭配,若使用了`generate_from_frequencies`方法则忽略此参数。一般不用。
`colormap`:每个词对应的颜色,若设置了`color_func`则忽略此参数。
`normalize_plurals`:是否移除英文复数单词末尾的s ,比如可将word和words视同为一个词,并将词频算到word头上。如果使用了`generate_from_frequencies`方法则忽略此参数。
`contour_width`:如果`mask`有设置,且`contour_width`>0,将会绘制`mask`轮廓。
`contour_color`:`mask`轮廓的颜色,默认为黑色。
`repeat`:当词不足以满足设定的`max_words`时,是否重复词或短语以使词云图上的词数量达到`max_words`
`include_numbers`:是否将数字作为词。
`min_word_length`:设置一个词包含的最少字母数量。
`collocation_threshold`:界定英文中的`bigrams`,对于中文不适用。此例中,我们调用`wordcloud`时,设定了字体为“黑体”,使用了背景图为绘图模板,设置了最多显示词数为500,字号最大为100。然后使用`generate_from_frequencies()`从已有词频数据的字典中生成词云图。然后将词云图按公司名保存到指定路径(“词云图”文件夹)。最后用`plt.imshow()`在notebook中显示词云图。结果如下。

#将存好的Excel词频表读取成字典
path='词频' #文件所在文件夹
files = [path+"\\"+i for i in os.listdir(path)] #获取文件夹下的文件名,并拼接完整路径
maskImage = np.array(Image.open('background.png')) # 定义词频背景图
for file in files:
#将词频Excel文件读取为字典
wb = load_workbook(file)
ws = wb.active
wordFreq = {}
for i in range(2,ws.max_row+1):
word = ws["A"+str(i)].value
freq = ws["B"+str(i)].value
wordFreq[word] = freq
#定义词云样式
wc = wordcloud.WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体
mask= maskImage, # 设置背景图
max_words=500, # 最多显示词数
max_font_size=100) # 字号最大值
#生成词云图
wc.generate_from_frequencies(wordFreq) # 从字典生成词云
#保存图片到指定文件夹
wc.to_file("词云图\\{}.png".format(file.split("\\")[1][:4]))
#在notebook中显示词云图
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像五、文末推荐与福利
《巧用ChatGPT快速搞定数据分析》免费包邮送出3本!

内容简介:
本书是一本关于数据分析与ChatGPT应用的实用指南,旨在帮助读者了解数据分析的基础知识及利用ChatGPT进行高效的数据处理和分析。随着大数据时代的到来,数据分析已经成为现代企业和行业发展的关键驱动力,本书正是为了满足这一市场需求而诞生。
本书共分为8章,涵盖了从数据分析基础知识、常见的统计学方法到使用ChatGPT进行数据准备、数据清洗、数据特征提取、数据可视化、回归分析与预测建模、分类与聚类分析,以及深度学习和大数据分析等全面的内容。各章节详细介绍了运用ChatGPT在数据分析过程中解决实际问题,并提供了丰富的实例以帮助读者快速掌握相关技能。
本书适合数据分析师、数据科学家、研究人员、企业管理者、学生,以及对数据分析和人工智能技术感兴趣的广大读者阅读。通过阅读本书,读者将掌握数据分析的核心概念和方法,并学会运用ChatGPT为数据分析工作带来更高的效率和价值。
编辑推荐:
★超实用 通过30多个实际案例和操作技巧,使读者能够快速上并灵活运用数据分析和ChatGPT技术。
★巨全面 50多种ChatGPT数据分析策略,涵盖从数据预处理到高级分析的全过程。
★真好懂 以通俗易懂的语言解释数据分析和ChatGPT的原理及应用,零门槛,让职场新手也能轻松掌握。
★高回报 学习本书,利用ChatGPT在数据分析过程中的各个环节进行实践操作,可以大大提高工作效率,降低人力成本,从而为企业和个人带来更高的投资回报率。
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-09-23 20:00:00
京东购买链接:https://item.jd.com/13810483.html
当当网购买链接:http://product.dangdang.com/29606385.html
名单公布时间:2023-09-23 21:00:00