GO-日志分析
log包简介
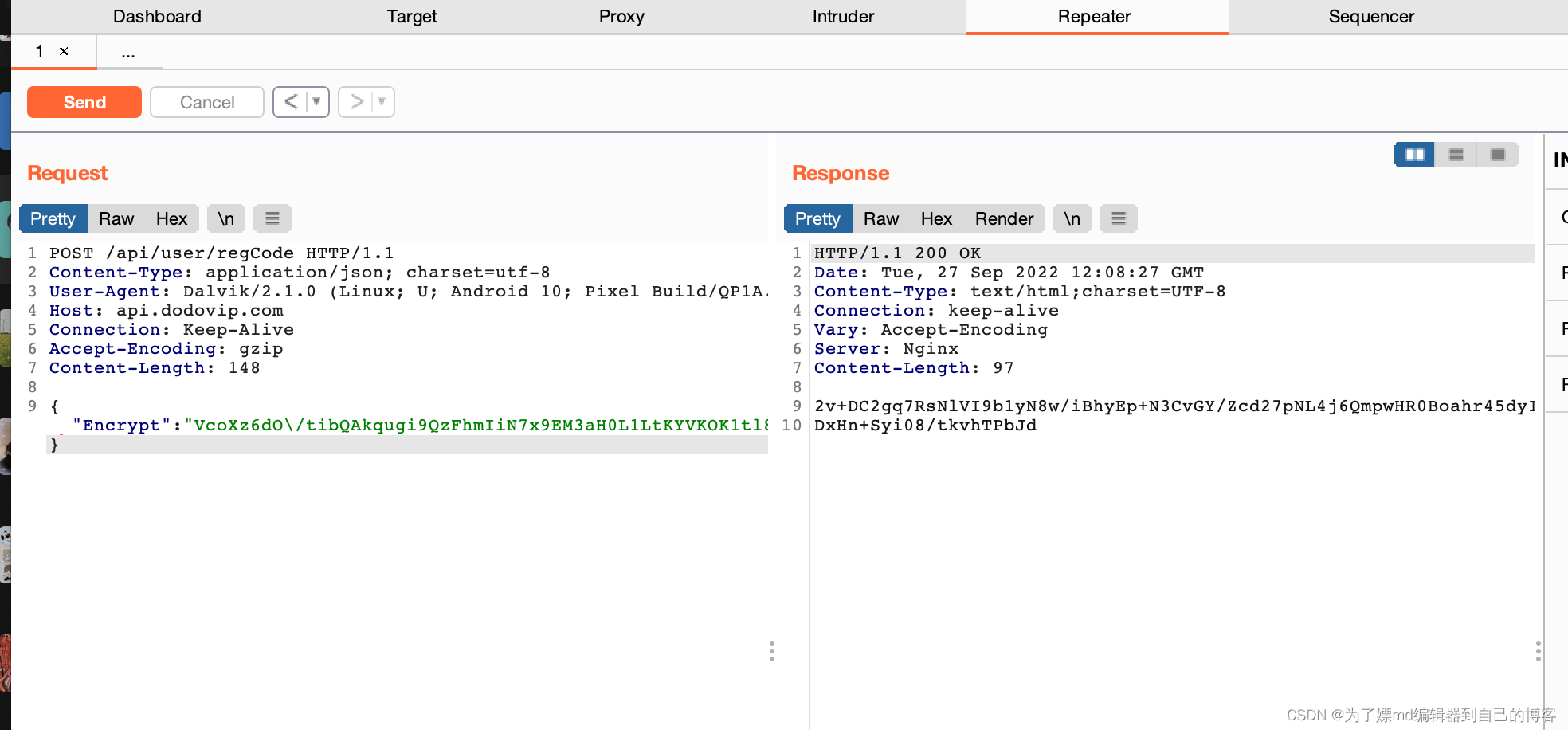
Go提供了logger包来做日志记录。使用方式如下所示
package main
import (
"log"
"os"
)
func main() {
// 创建一个新的日志文件.默认是stdOut
file, err := os.Create("app.log")
if err != nil {
log.Fatal(err)
}
defer file.Close()
// 设置日志输出的目标为文件
log.SetOutput(file)
// 设置日志的前缀
log.SetPrefix("LOG: ")
// 设置日志的标志,例如显示日期和时间
log.SetFlags(log.LstdFlags | log.Llongfile) // 默认是LstdFlags
// 记录日志
log.Println("This is a log message")
log.Printf("This is a formatted log message: %s", "hello world")
}
使用起来很简单,并且理解起来很容易。但有下面的几个问题
- 不支持日志级别,并且提供的方法不是常规的使用日志的方式,比如info,debug,error 等。
- 性能问题。日志在项目中使用的场景很多,日志不应该成为性能瓶颈。(日志得快)
- 输出日志不是格式化的。
- 不支持滚动日志。
下面介绍一下zap
zap包简介
官网:https://github.com/uber-go/zap
zap在很多开源的库中使用,比如etcd,dubbo-go等中。
zap的优点
- 支持完整的日志级别
- 速度快
- 结构性日志
zap的使用很简单,在使用的时候的流程如下:
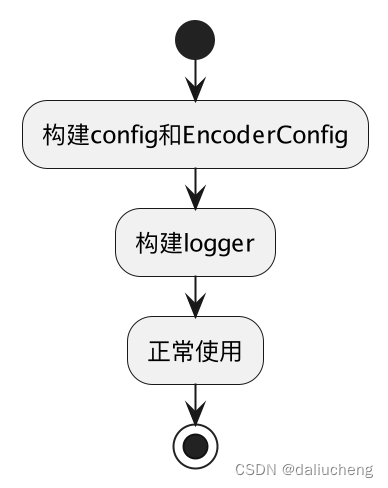
代码如下:
package main
import (
"go.uber.org/zap"
"time"
)
func main() {
url := "http://example.com"
// 创建一个生产环境的config
config := zap.NewProductionConfig()
// 设置输出到标准输出和文件,这里不支持滚动日志
config.OutputPaths = []string{"stdout", "zap.log"}
// 构建logger
logger, _ := config.Build()
defer logger.Sync() // flushes buffer, if any
sugar := logger.Sugar()
sugar.Infow("failed to fetch URL",
// Structured context as loosely typed key-value pairs.
"url", url,
"attempt", 3,
"backoff", time.Second,
)
sugar.Infof("Failed to fetch URL: %s", url)
}
并且他已经提供了几个成熟的配置,方便学习和使用。
- NewDevelopment
- NewProduction
- NewExample
这三种方式,只是帮我们构建好了config和EncoderConfig,当然,我们也可以自己做,也可以在他们的基础上继续做。
它提供了两种logger对象
-
SugaredLogger
性能和使用平衡的一个日志对象(一般直接使用它就已经ok了)
-
logger
对性能要求很高的情况下使用的日志对象
为了搞清楚也方便理解,从源码开始分析(go官方的log包这里就不分析了,内容很简单,看一下就行)
zap源码分析
日志需要下面的几个要素
- 日志写到哪里?如何抽象?
- 日志的级别怎么处理?
- 如何提高速度?
- 日志如何编码?
- 如果做到线程安全?
- 日志输出中包含哪些关键字,如何拓展?用户可以自己添加一些关键字
从config开始看,看有哪些可配置的,从而发现蛛丝马迹,来回答上面的问题,理解zap的设计
config解析
type Config struct {
// 日志级别
Level AtomicLevel `json:"level" yaml:"level"`
// 开发模式
Development bool `json:"development" yaml:"development"`
DisableCaller bool `json:"disableCaller" yaml:"disableCaller"`
DisableStacktrace bool `json:"disableStacktrace" yaml:"disableStacktrace"`
// 采样器的配置
Sampling *SamplingConfig `json:"sampling" yaml:"sampling"`
// 编码方式
Encoding string `json:"encoding" yaml:"encoding"`
// 编码的配置
EncoderConfig zapcore.EncoderConfig `json:"encoderConfig" yaml:"encoderConfig"`
// 日志输出的位置
OutputPaths []string `json:"outputPaths" yaml:"outputPaths"`
// 错误输出的位置,这只是设置的zap内部的错误输出的位置
ErrorOutputPaths []string `json:"errorOutputPaths" yaml:"errorOutputPaths"`
// 可配置的字段
InitialFields map[string]interface{} `json:"initialFields" yaml:"initialFields"`
}
sink
sink就是抽象出来的日志文件的写入源。
zap支持多个sink,可以同时在多个文件中写,比如可以在标准输出和文件中同时写
对应的源码在Config#openSinks
func open(paths []string) ([]zapcore.WriteSyncer, func(), error) {
writers := make([]zapcore.WriteSyncer, 0, len(paths))
closers := make([]io.Closer, 0, len(paths))
close := func() {
for _, c := range closers {
c.Close()
}
}
var openErr error
for _, path := range paths {
// 重点是在这里,通过不同的path来创建不同的sink
sink, err := _sinkRegistry.newSink(path)
if err != nil {
openErr = multierr.Append(openErr, fmt.Errorf("open sink %q: %w", path, err))
continue
}
writers = append(writers, sink)
closers = append(closers, sink)
}
if openErr != nil {
close()
return nil, nil, openErr
}
return writers, close, nil
}
WriteSyncer是zap自己封装的writer接口,增加Sync方法
上面在通过path从_sinkRegistry中获取不同的sink,这用的是简单工厂模式(其实也可以是策略,策略偏重的是行为,简单工厂偏重的是创建,这里用简单工厂比较合适)
sink源码:https://github.com/uber-go/zap/blob/master/sink.go
sink的接口定义
type Sink interface {
zapcore.WriteSyncer
io.Closer
}
创建sink
func (sr *sinkRegistry) newSink(rawURL string) (Sink, error) {
// URL parsing doesn't work well for Windows paths such as `c:\log.txt`, as scheme is set to
// the drive, and path is unset unless `c:/log.txt` is used.
// To avoid Windows-specific URL handling, we instead check IsAbs to open as a file.
// filepath.IsAbs is OS-specific, so IsAbs('c:/log.txt') is false outside of Windows.
if filepath.IsAbs(rawURL) {
return sr.newFileSinkFromPath(rawURL)
}
// 解析path,通过不同的scheme来做
u, err := url.Parse(rawURL)
if err != nil {
return nil, fmt.Errorf("can't parse %q as a URL: %v", rawURL, err)
}
if u.Scheme == "" {
u.Scheme = schemeFile
}
sr.mu.Lock()
// 简单工厂模式,
factory, ok := sr.factories[u.Scheme]
sr.mu.Unlock()
if !ok {
return nil, &errSinkNotFound{u.Scheme}
}
return factory(u)
}
func (sr *sinkRegistry) newFileSinkFromPath(path string) (Sink, error) {
// 处理标准输入和输出,
switch path {
case "stdout":
return nopCloserSink{os.Stdout}, nil
case "stderr":
return nopCloserSink{os.Stderr}, nil
}
// 创建文件,这里返回的是File对象,File对象也实现了Sink接口,这就是go中的接口的正交性
return sr.openFile(path, os.O_WRONLY|os.O_APPEND|os.O_CREATE, 0666)
}
zap支持多个sink,为了方便调用,需要建多个sink聚合为一个对象,之后对这个对象操作。这用到了装饰器模式。
可以通过不同的scheme来做拓展,比如我们可以自己实现sink接口,直接让日志文件写在mq中去。(这个操作不难,规定scheme,比如rocketmq://top,然后实现sink,做mq的写操作就好了)
具体实现是:让此对象也实现相同接口,在对象中用列表保存sink,所有的操作遍历就好了
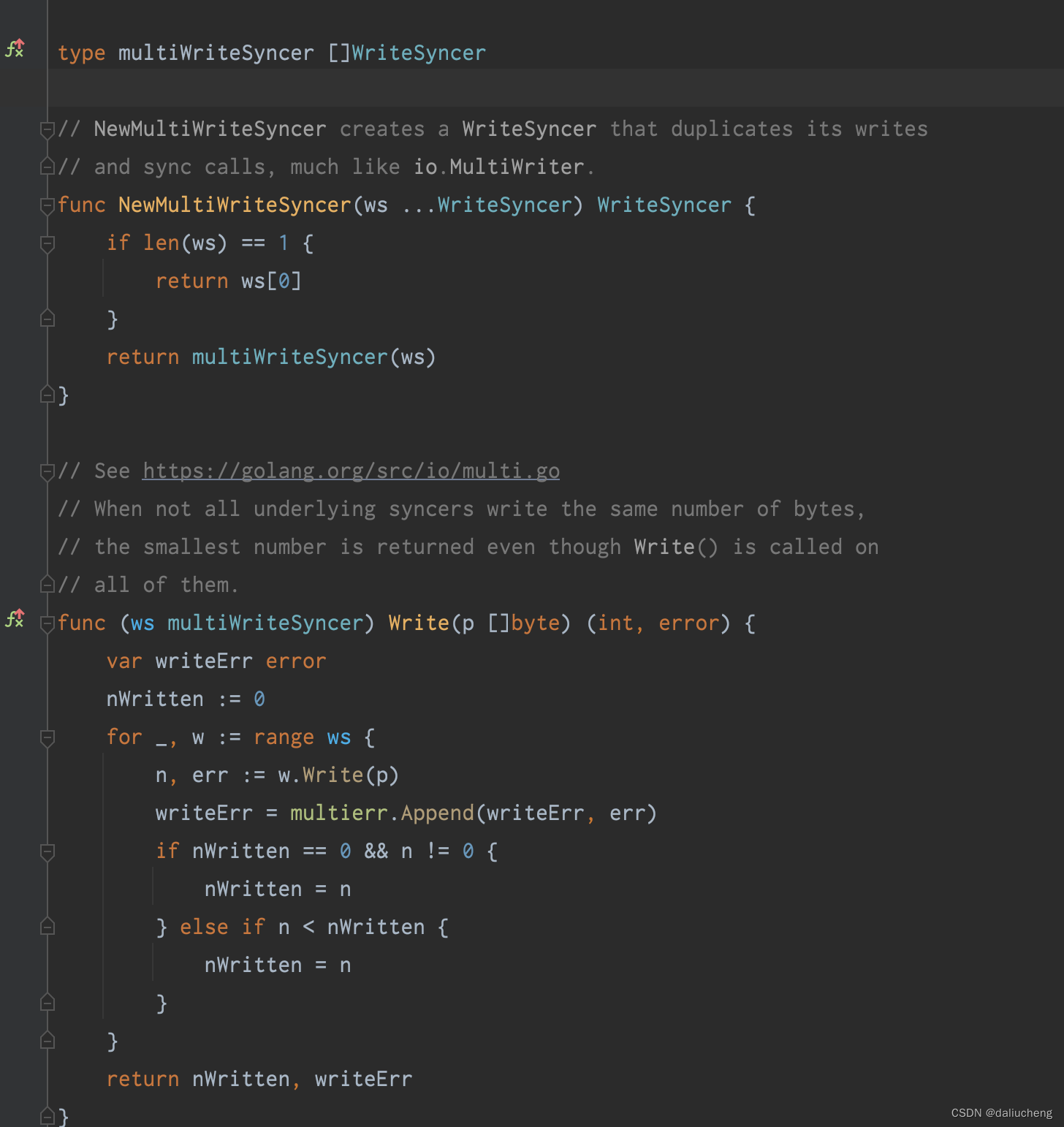
日志级别如何处理
跳出zap。日志级别简单来说输出日志的时候if以下就行了。if的位置有两种
-
在写日志的时候,自己手动先if以下
if (logger.isDebug()){ logger.debug() // } -
将if操作写在日志方法中
logger.Debug()
zap采用的是第二种。
这其实没什么可说的,就是将日志级别放在logger对象中,打印日志的时候判断一下就好了。我们来看一下他的设计
接口:
type leveledEnabler interface {
LevelEnabler
Level() Level
}
type LevelEnabler interface {
Enabled(Level) bool
}
有两个实现的结构体
-
Level
支持的level
type Level int8 const ( // DebugLevel logs are typically voluminous, and are usually disabled in // production. DebugLevel Level = iota - 1 // InfoLevel is the default logging priority. InfoLevel // WarnLevel logs are more important than Info, but don't need individual // human review. WarnLevel // ErrorLevel logs are high-priority. If an application is running smoothly, // it shouldn't generate any error-level logs. ErrorLevel // DPanicLevel logs are particularly important errors. In development the // logger panics after writing the message. DPanicLevel // PanicLevel logs a message, then panics. PanicLevel // FatalLevel logs a message, then calls os.Exit(1). FatalLevel ) -
AtomicLevel
type AtomicLevel struct { l *atomic.Int32 }对level包装了一层,提供了原子操作。为了并发安全
为了上面这些,只需要在logger输出的时候调用他的enabled就好了。
如何提高速度?
减少对象的分配,尽量复用对象。在go中本身就提供了sync.pool。只需要将整个操作期间的重对象池化,重用对象。
那么问题来了,哪些对象需要放在里面呢?
-
buffer
byte数组,大小为1kb,承担一些转换的操作,比如调用站格式化的时候需要用到string和byte,利用buffer来做,减少内存的分配
-
jsonEncoder
json的编解码器,将日志格式为json,这里面有两个buffer
- jsonEncoder自己的buffer
- jsonEncoder在编解码过程中用的到byte数组
-
stacktrace
栈
-
entry
一个日志条目,代表一条日志。此对象并不会占用太多的内存,并且也会及时的gc掉,但这里复用的目的是在于 日志在一个日志系统中会出现很多很多的。复用此对象会减少对象的分配。从而提高速度
type Entry struct { Level Level Time time.Time LoggerName string Message string Caller EntryCaller Stack string }
日志如何编码?
支持两种编码方式
- jsonEncoder
- consoleEncoder
zap提供了Encoder接口
type ObjectEncoder interface {
// Logging-specific marshalers.
AddArray(key string, marshaler ArrayMarshaler) error
AddObject(key string, marshaler ObjectMarshaler) error
// Built-in types.
AddBinary(key string, value []byte) // for arbitrary bytes
AddByteString(key string, value []byte) // for UTF-8 encoded bytes
AddBool(key string, value bool)
AddComplex128(key string, value complex128)
AddComplex64(key string, value complex64)
AddDuration(key string, value time.Duration)
AddFloat64(key string, value float64)
AddFloat32(key string, value float32)
AddInt(key string, value int)
AddInt64(key string, value int64)
AddInt32(key string, value int32)
AddInt16(key string, value int16)
AddInt8(key string, value int8)
AddString(key, value string)
AddTime(key string, value time.Time)
AddUint(key string, value uint)
AddUint64(key string, value uint64)
AddUint32(key string, value uint32)
AddUint16(key string, value uint16)
AddUint8(key string, value uint8)
AddUintptr(key string, value uintptr)
// AddReflected uses reflection to serialize arbitrary objects, so it can be
// slow and allocation-heavy.
AddReflected(key string, value interface{}) error
// OpenNamespace opens an isolated namespace where all subsequent fields will
// be added. Applications can use namespaces to prevent key collisions when
// injecting loggers into sub-components or third-party libraries.
OpenNamespace(key string)
}
type Encoder interface {
ObjectEncoder
// Clone copies the encoder, ensuring that adding fields to the copy doesn't
// affect the original.
Clone() Encoder
// EncodeEntry encodes an entry and fields, along with any accumulated
// context, into a byte buffer and returns it. Any fields that are empty,
// including fields on the `Entry` type, should be omitted.
EncodeEntry(Entry, []Field) (*buffer.Buffer, error)
}
这些Encoder,会将一个Entry和Field数组变为一个buffer返回。JsonEncoder和ConsoleEncoder的区别是格式不同。
Zap会将我们日志中的参数推测为zap种定义的类型,然后不同的格式,调用不同的Add方法,添加到Encoder中去,从而Encoder可以执行自己的操作。
源码:
https://github.com/uber-go/zap/blob/master/zapcore/json_encoder.go
https://github.com/uber-go/zap/blob/master/zapcore/console_encoder.go
如果做到线程安全?
加锁,和正常的写一样,实现WriteSyncer接口,用代理模式给Write方法增加了同步的能力
type lockedWriteSyncer struct {
sync.Mutex
ws WriteSyncer
}
如何拓展
用的是简单工厂模式
实现:
func RegisterEncoder(name string, constructor func(zapcore.EncoderConfig) (zapcore.Encoder, error)) error {
_encoderMutex.Lock()
defer _encoderMutex.Unlock()
if name == "" {
return errNoEncoderNameSpecified
}
if _, ok := _encoderNameToConstructor[name]; ok {
return fmt.Errorf("encoder already registered for name %q", name)
}
_encoderNameToConstructor[name] = constructor
return nil
}
有哪些拓展点?
- 编码器
- sink
dubbo-go中zap的使用
-
利用私有包变量
本质还是用的是zap。但需要创建一个
Sugar,需要作为变量放在包里面,然后用包提供的方法来访问,然后日志包提供对应的方法来打印日志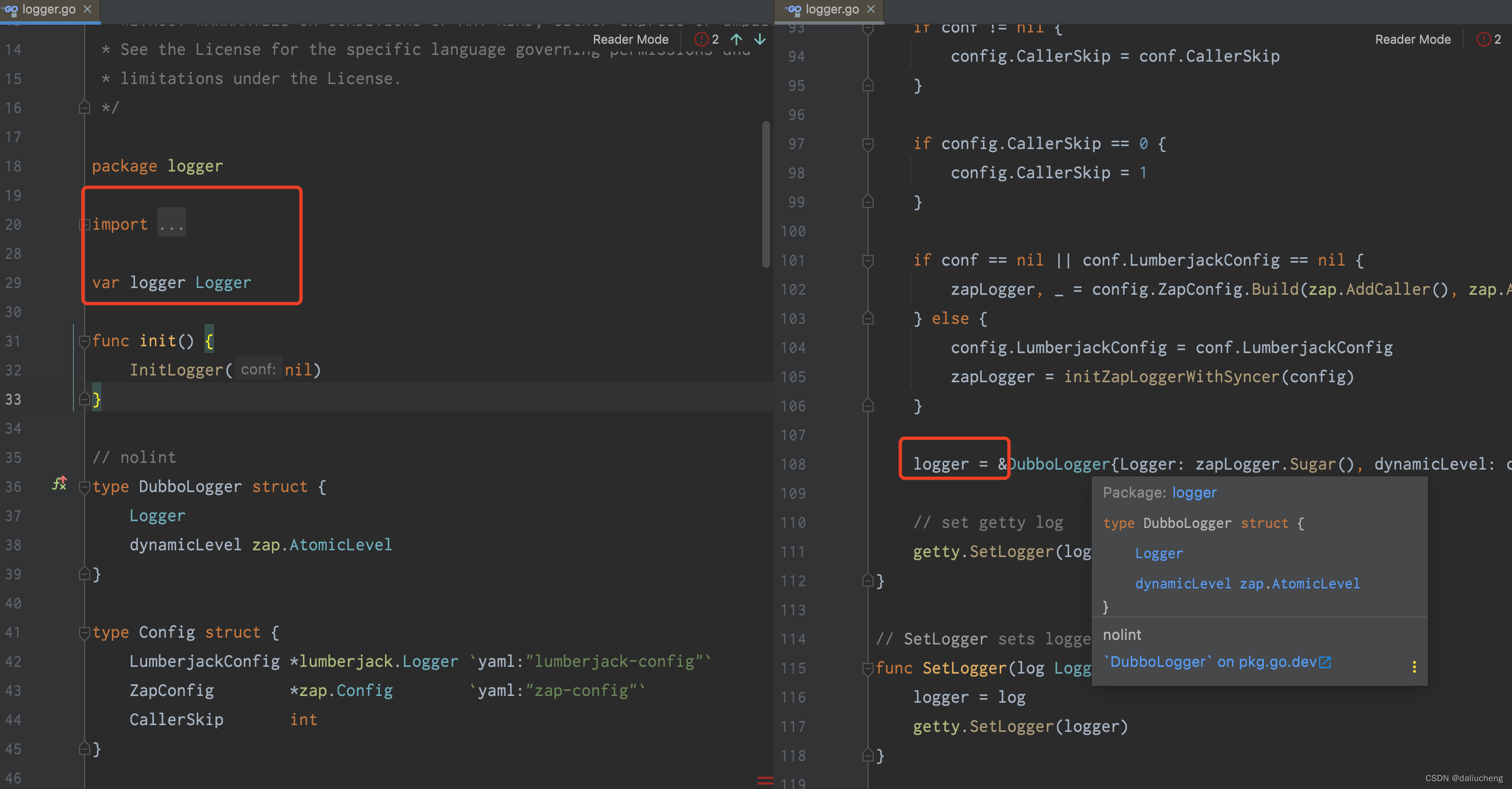
-
提供logger接口
这利用go里面的接口正交性
type Logger interface { Info(args ...interface{}) Warn(args ...interface{}) Error(args ...interface{}) Debug(args ...interface{}) Fatal(args ...interface{}) Infof(fmt string, args ...interface{}) Warnf(fmt string, args ...interface{}) Errorf(fmt string, args ...interface{}) Debugf(fmt string, args ...interface{}) Fatalf(fmt string, args ...interface{}) }这是抽象出来的接口,zap的Sugar中有这些方法,就认为已经实现了此方法。
-
提供log的配置
创建config对象,将zap中日志能配置的属性都放在自己的config中。
到此,分析结束了。