前言:
本文章是原创50篇时开启的纪念作,之前的文章基本5000字,而本篇约4.5万字,真一篇顶九篇。
窗口函数作为Mysql 8的新特性以及面试笔试的重点,掌握并且进行来练习是非常有必要的。本文章详细介绍窗口函数的方方面面,包含知识点梳理,简单案例,题目解析和面试实战,阅读需要约一定的时间,建议收藏后食用。
其中在解题部分更是包含了题目分析和要求梳理,解体解答和答案总和,题目由易到难,更包含牛客会员类型题目,其中解体解答花费了很大心思。毫不夸张地说,弄懂本篇文章,可以应付基本所有的面试笔试,尤其是数据开发岗和数据分析岗。
如果是刚开始学习窗口函数、补知识点或者练习窗口函数的题目,从头到尾读完本篇文章相信可以有一定的收获。
另外文章包含窗口函数的题目十余道,每一题都有解体解答,中间产生的图片N个,非常细致(自夸)。由于都是牛客上大部分免费的题目,读者可以亲自复习和验证。
本文章包含比较经典问题的解法,比如销量累计和,次日留存率,新增用户数,分组排名前三名,下一次出现的日期,中位数等等。
本文章间断写了个把月,中间一度感觉麻烦想要暂停,尤其是在解体解答的过程中要截数次图,不过还是坚持下来了,可以的话点个赞来个收藏是对博主的最大支持,希望您看的开心。
另外,本文中有些题目案例为方便理解是博主自己出题,虽有一定的sql基础,但可能会有些笔误或者不了解的地方,希望多多保函,有错误也会进行改正。
一.窗口函数基础知识点
1. 窗口函数的引入
先来看一个经典的题目,牛客SQL136 每类试卷得分前3名:
现有试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):

试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):
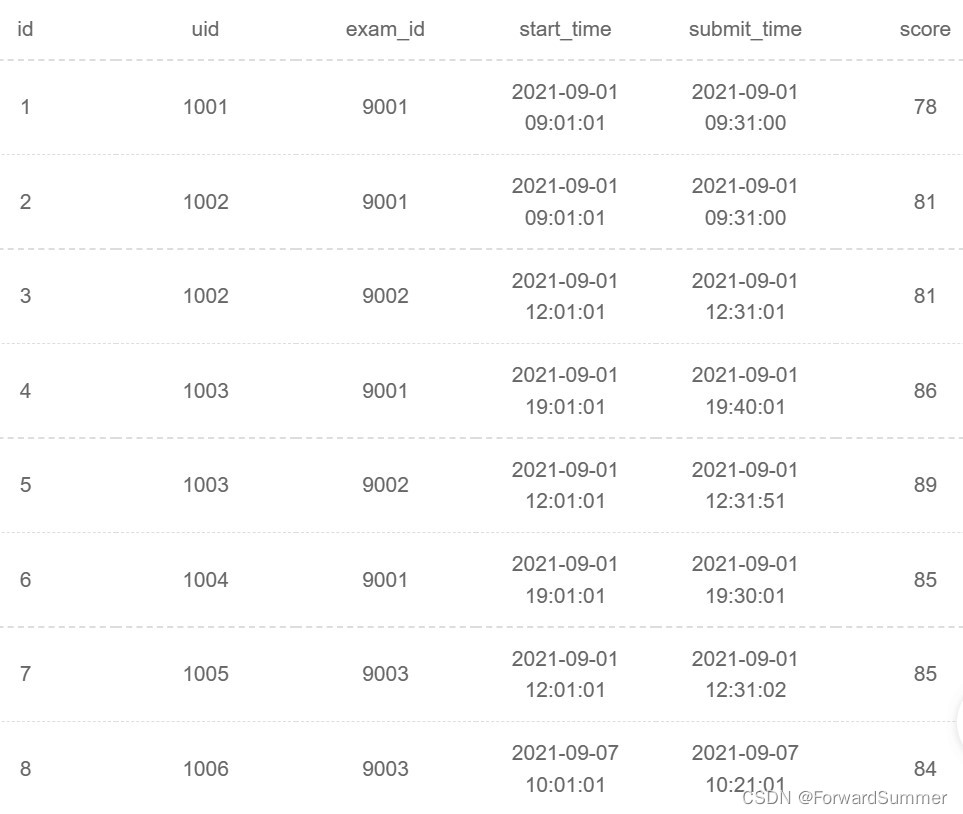
找到每类试卷得分的前3名,如果两人最大分数相同,选择最小分数大者,如果还相同,选择uid大者。由示例数据结果输出如下:

解释:有作答得分记录的试卷tag有SQL和算法,SQL试卷用户1001、1002、1003、1004有作答得分,最高得分分别为81、81、89、85,最低得分分别为78、81、86、40,因此先按最高得分排名再按最低得分排名取前三为1003、1004、1002。
抛开“如果两人最大分数相同,选择最小分数大者,如果还相同,选择uid大者” 这一条件不谈,光是求得每类试卷得分的前3名这一要求就不简单,按照别的解法会很复杂。
而Mysql8.0新增的窗口函数,对于这种需求可谓是正好对口。
2. 窗口函数简单介绍
MySQL从8.0版本开始支持窗口函数,可以当作8.0的新特性,还是比较重要的新特性。窗口函数的作用类似于在查询中对数据进行分组,不同的是,分组 操作会把分组的结果聚合成一条记录,而窗口函数是将结果置于每一条数据记录中。
窗口函数可以分为 静态窗口函数 和 动态窗口函数 。 静态窗口函数的窗口大小是固定的,不会因为记录的不同而不同; 动态窗口函数的窗口大小会随着记录的不同而变化。【1】
官方网址:mysql.com/doc
总体上,需要用到分组统计的结果对每一条记录进行计算的场景下,使用窗口函数更方便。
3. 窗口函数的语法
总体上语法格式
总体上,窗口函数的语法大同小异,先给出总体语法
窗口函数() over(partition by 分组 order by 排序目标 desc/asc)或者是【1】
函数 over 窗口名 … WINDOW 窗口名 as ([partition by 字段名 order by 字段名 asc/desc])
具体的函数语法
(1)排序类窗口函数语法都一样,包括 rank,row_number,dense_rank:
rank() over(partition by 分组 order by 排序目标 desc/asc)(2)聚合类窗口函数,包括 max,min,avg,sum,count:
sum(目标数据) over(partition by 分组 order by 排序目标 desc/asc)(3)推迟延后窗口函数,包括lead和lag:
lead(需要提前的目标数据,N(提前的数量)) over(partition by 分组 order by 排序目标 desc/asc)(4)分布函数,包括percent_rank和cume_dist:
percent_rank() over(partition by 分组 order by 排序目标 desc/asc)(5)首尾函数,包括first_value和last_value:
first_value(目标数据) over(partition by 分组 order by 排序目标 desc/asc)具体的详细用法呈现在下个章节。
4. 窗口函数分类以及简单案例实战
4.1 排序窗口函数 rank,row_number,dense_rank
排序窗口函数是最为重要也是最容易在面试笔试中遇到的,掌握三个排序窗口函数:
rank,row_number,dense_rank,
那么它们的主要区别是:
row_number,从1开始,按照顺序,生成分组内记录的序列
rank,生成数据项在分组中的排名,排名相等会在名次中留下空位
dense_rank,生成数据项在分组中的排名,排名相等会在名次中不会留下空位
那么一个排序结果来说:
row_number:1,2,3,4,5,6
rank:1,1,3,4,5,6
dense_rank:1,1,2,3,4,5
在牛客上,使用SQL136每类试卷得分前3名为案例,做出具体排序:
原题语句:
drop table if exists examination_info,exam_record;
CREATE TABLE examination_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
exam_id int UNIQUE NOT NULL COMMENT '试卷ID',
tag varchar(32) COMMENT '类别标签',
difficulty varchar(8) COMMENT '难度',
duration int NOT NULL COMMENT '时长',
release_time datetime COMMENT '发布时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9001, 'SQL', 'hard', 60, '2021-09-01 06:00:00'),
(9002, 'SQL', 'hard', 60, '2021-09-01 06:00:00'),
(9003, '算法', 'medium', 80, '2021-09-01 10:00:00');
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2021-09-01 09:01:01', '2021-09-01 09:31:00', 78),
(1001, 9001, '2021-09-01 09:01:01', '2021-09-01 09:31:00', 81),
(1002, 9002, '2021-09-01 12:01:01', '2021-09-01 12:31:01', 81),
(1003, 9001, '2021-09-01 19:01:01', '2021-09-01 19:40:01', 86),
(1003, 9002, '2021-09-01 12:01:01', '2021-09-01 12:31:51', 89),
(1004, 9001, '2021-09-01 19:01:01', '2021-09-01 19:30:01', 85),
(1005, 9003, '2021-09-01 12:01:01', '2021-09-01 12:31:02', 85),
(1006, 9003, '2021-09-07 10:01:01', '2021-09-07 10:21:01', 84),
(1003, 9003, '2021-09-08 12:01:01', '2021-09-08 12:11:01', 40),
(1003, 9002, '2021-09-01 14:01:01', null, null);(1)rank()
只使用exam_record表并对score排序,不区分类别
select uid,exam_id,score,rank() over(order by score)
from exam_record结果:

可以看到相应的排序,并且,排名7的有两个,并且略过排名8
分值降序操作:

(2)row_number()
row_number()是三个排序窗口函数中使用次数最多的。和上述rank一样,只使用exam_record表并对score排序,不区分类别,那么结果为:
select uid,exam_id,score,row_number() over(order by score)
from exam_record 
上述rank用过了降序,不再重复,一样使用。那么提出新需求,想要知道每个tag下的,也就是不同试卷下的分数的排名,也就是类似于我们考试中的分科排名
select e2.uid,tag,row_number() over(partition by tag order by score)
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id那么有了上面的基础也是比较简单,在over中进行分区,分区标准就是tag
产生的结果如下:
(3)dense_rank()
那么,dense_rank的用法和上面一样,不再赘述,直接贴出使用exam_record表并对score排序,不区分类别,那么结果为:
select uid,exam_id,score,dense_rank() over(order by score)
from exam_record 
4.2 聚合窗口函数 max,min,avg,sum,count
此节介绍一些常用的聚合窗口函数,那么,还是以使用SQL136每类试卷得分前3名为案例。
(1). max()函数
需求:在exam_record中每个记录后添加所有用户得分的最大值,其实本需求也不是非要使用窗口函数,那么是为了展示用法,更好的应用案例可参照nowcoder SQL142,也就是本文第五题。
select uid,exam_id,max(score) over() from exam_record结果如下:

再进一步,求得每个类别(exam_id)的最大值,添加到原表之后
select uid,exam_id,max(score) over(partition by exam_id) from exam_record
那么在进一步,求个每个tag的最大值,就需要两个表的连接了,并且可以根据求得的最大值做归一化,更多可以参考案例nowcoder SQL142 对试卷得分做min-max归一化,也就是文章的第五题。
(2). min()函数
min()函数的用法和max一样,不再赘述,给出求个每个tag的最小值作为案例:
select uid,e1.exam_id,min(score) over(partition by tag) from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
(3). avg()函数
avg()函数的用法一样,这里给出每个exam_id试卷的平均分作为案例:

(4). sum()函数
sum()函数在聚合函数中是比较重要的,因为经常被用来求累计量,比如,求得每个月得累计销量,那么在3月份就要求1,2,3月得销量之和,而,4月份就要求得1,2,3,4月得销量之和,在面试笔试中经常容易问道。
那么在这边以nowcoder SQL144 每月及截止当月的答题情况 为案例,求得每个月的累计答题量。
原sql语句:
drop table if exists exam_record;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2020-01-01 09:01:01', '2020-01-01 09:21:59', 90),
(1002, 9001, '2020-01-20 10:01:01', '2020-01-20 10:10:01', 89),
(1002, 9001, '2020-02-01 12:11:01', '2020-02-01 12:31:01', 83),
(1003, 9001, '2020-03-01 19:01:01', '2020-03-01 19:30:01', 75),
(1004, 9001, '2020-03-01 12:01:01', '2020-03-01 12:11:01', 60),
(1003, 9001, '2020-03-01 12:01:01', '2020-03-01 12:41:01', 90),
(1002, 9001, '2020-05-02 19:01:01', '2020-05-02 19:32:00', 90),
(1001, 9002, '2020-01-02 19:01:01', '2020-01-02 19:59:01', 69),
(1004, 9002, '2020-02-02 12:01:01', '2020-02-02 12:20:01', 99),
(1003, 9002, '2020-02-02 12:01:01', '2020-02-02 12:31:01', 68),
(1001, 9002, '2020-02-02 12:01:01', '2020-02-02 12:43:01', 81),
(1001, 9002, '2020-03-02 12:11:01', null, null);求解分析:
首先要求解每个月的答题量,肯定以月份进行分类,然后利用sum()窗口函数进行累计求和,思路还是很简单明确的。(这里忽略了分值为null的部分,只要开始就算一次答题)
select date_format(start_time,'%Y%m') mon, count(1)
from exam_record
group by mon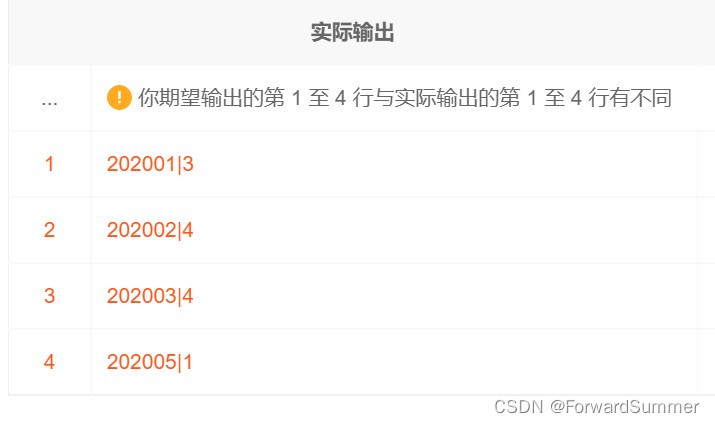
select mon,sum(ct) over(order by mon) from (
select date_format(start_time,'%Y%m') mon, count(1) ct
from exam_record
group by mon
)t1
这样就大功告成了,如果想要以不同科目来进行求解,只要在over中添加partition by 科目就可以了。
(5). count()函数
细心的朋友发现了,基本上所有的常见的聚合函数都可以进行窗口函数的使用,count也可以。那么count的案例如下,就是简单求表中的总数,好处是可以避免mysql 的经典错误:only flull group by
select score,count(*) over() ct,row_number() over(order by score) rk
from exam_record
where score is not null
4.3 推迟提前函数 lead,lag
其实从英文上也能窥探函数用法一二,lead 和 lag函数可以推迟或者延后表中的数据,那么还是以SQL136每类试卷得分前3名为案例,这里着重用lead()函数示范,lag的用法一毛一样就不再赘述。
案例一:请求得用户下一次作答试卷的时间
select uid,start_time,
lead(start_time,1) over(partition by uid order by start_time) '下一次出现的时间'
from exam_record
案例二:请求得用户相邻两次作答的差值(下一次减去上一次)
select uid,(next_score - score) diff_score from (
select uid,score,
lead(score,1) over(partition by uid order by start_time) next_score
from exam_record
)t1
当然,为None的数据可以另行赋值,标记为没有下一次的score,此处不再转换。 lag的函数用法也是一样的。另外,利用推迟延后函数可以用来求用户留存率,在第二大部分常用技巧第5小节有介绍。
4.4 分布函数
分布函数percent_rank和cume_dist使用的较少,那么直接在一个案例中呈现,还是SQL136每类试卷得分前3名为案例。
select uid,
exam_id,
score,
percent_rank() over(partition by exam_id order by score),
cume_dist() over(partition by exam_id order by score)
from exam_record
where score is not null
percent_rank()函数是等级值百分比函数。按照如下方式进行计算【1】:
其中,rank的值为使用RANK()函数产生的序号,rows的值为当前窗口的总记录数【1】。
cume_dist()函数主要用于查询小于或等于某个值的比例【1】。
可以看出来,percent_rank()和cume_dist()都和排名比例相关,而不是和具体的score值相关,percent_rank()从0开始,到1.00结束,而cume_dist()从0.25开始,到1.00结束,从exam_id为9001的四个案例能显著看出来差别。
另外在本文章的第三大部分的第十一题SQL140 未完成率较高的50%用户近三个月答卷情况中涉及到了percent_rank()函数,建议阅读。
4.5 首尾函数
首尾函数主要包括first_value和last_value,用法都是一样的,只是关注的值不同,一个关注尾值一个关注首值,那么直接在一个案例中呈现用法,还是SQL136每类试卷得分前3名为案例,并且排除掉score是null的。
案例一: partition by exam_id
select uid,
exam_id,
score,
first_value(score) over(partition by exam_id),
last_value(score) over(partition by exam_id)
from exam_record
where score is not null
当以 exam_id作为分组时,看可以看到last_value和first_value就是分组当中的第一个和最后一个,比如9001中的78和85.
案例二:order by score
select uid,
exam_id,
score,
first_value(score) over(order by score),
last_value(score) over(order by score)
from exam_record
where score is not null 
当以 score进行排序而没有partition时,看可以看到first_value就是分组当中的正序第一个分值40,last_value是逐渐增大的,随着分值越来越大,因为是正序最大值就是自己。
如果倒叙desc:
select uid,
exam_id,
score,
first_value(score) over(order by score desc),
last_value(score) over(order by score desc)
from exam_record
where score is not null 
当以 score进行降序排序而没有partition时,看可以看到first_value就是分组当中的倒序第一个分值40,last_value是逐渐减小的,随着分值越来越小,可以理解为截止到目前为止的最后一个值。
案例三:partition by exam_id order by score
select uid,
exam_id,
score,
first_value(score) over(partition by exam_id order by score),
last_value(score) over(partition by exam_id order by score)
from exam_record
where score is not null
当以 score进行降序排序而有partition时,情况只是进行了分组,首值还是最小的那个,最大值随着score变大而改变。
二.常用技巧
1. 排序技巧
有些题目会让求最大值,比如得分最大的用户信息,但是,得分最大的用户可能是两个或者三个,他们得分都是最大值,此时可以利用dense_rank对分数排序,设为rk,把rk=1的用户信息提取出来就可以了。
实际案例一
nowcoder SQL196 查找入职员工时间排名倒数第三的员工所有信息
如果直接用这样的查询,是不对的,因为倒数第三的入职那天可能有多人
select * from employees order by hire_date desc limit 2,1用窗口函数的话:
select emp_no,birth_date,first_name,last_name
,gender,hire_date from (
select emp_no,birth_date,first_name,last_name
,gender,hire_date,
dense_rank() over(order by hire_date desc) rk
from employees
)t1
where rk = 3也可以换个思路,求出倒数第三那天入职的天数,然后把那天入职所有的人查出来【4】
select * from employees
where hire_date = (
select distinct hire_date from employees order by hire_date desc limit 2,1
)
实际案例二
SQL212 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
方法一:使用窗口函数
select emp_no, salary, last_name, first_name from (
select emp_no, salary, last_name, first_name , dense_rank() over(order by salary desc) rk from
employees e1 join salaries s1 on e1.emp_no = e2.emp_no
)t1
where rk = 2但是题目明确说了不能使用窗口函数
方法二:使用max函数
select e1.emp_no ,salary, last_name, first_name from
employees e1 join salaries s1 on
e1.emp_no = s1.emp_no
where salary =( select max(salary) from salaries
where salary != (select max(salary) from salaries))先选出最大值,再选出不是最大值的最大值即是第二大的值
方法三:使用自连接
select e.emp_no,s.salary,e.last_name,e.first_name
from
employees e
join
salaries s on e.emp_no=s.emp_no
and s.salary =
(
select s1.salary
from
salaries s1
join
salaries s2 on s1.salary<=s2.salary
group by s1.salary
having count(distinct s2.salary)=2
)
此方法避免了多层的嵌套,可求任意第几大小的工资
2. 在sum窗口函数中进行统计
在sum窗口函数中,可以使用if函数来进行过滤统计,比如在本文的第三大部分第十一题,SQL140 未完成率较高的50%用户近三个月答卷情况:
sum(if(score is null,1,0)) over(partition by u1.uid)那么,其他聚合函数也是一样的道理,可以根据实际需求在窗口函数中添加条件。
3. 下一次出现的日期
在许多题目中,需要求解事件 下次/上次 出现的时间,这时候可以使用lag和lead函数。详见第一部分的4.3章节 推迟提前函数 lead,lag和第三部分 案例实战和题目解析 中的第五题。
一般模板就是简单的lead函数:
select 主键,date,lead(date,1) over(partition by 分组 order by date) lead1date
from 原表4. 求新增用户数
在许多题目中,经常会遇到求新增用户数的题目,例如本文章的第三章节案例实战和题目解析中的题目,第七题,也就是nowcoder上SQL144每月及截止当月的答题情况,下方为题目连接:
nowcoder SQL144每月及截止当月的答题情况
利用row_number()可以进行求解新增用户数,详细请看第三章节案例实战和题目解析中的题目第七题。
简单用模板来说,就是利用row_number()对用户进行分组,利用时间排序,然后把rk=1的用户当作新用户来处理,具体请看第七题:
select 时间分类, count(if(rn=1, uid, null)) as 时间分类的新增 from (
select uid, 时间,
row_number() over(partition by uid order by 时间) as rn
from exam_record
)tm
group by 时间5. 求用户留存率
在许多场景中,会让求用户留存率,比如经典的次日留存率,用窗口函数的解法来看,先求得下一次目标数据出现的时间,然后两个时间做差,为1的就是符合目标的时间,然后求得所有符合标准的数据的和和总体作比较就是次日留存率。那么,七日留存率和月留存率是一样的解法,把时间之差变换就可以了。
模板为
select avg(if(datediff(lead_1_date,date) = N,1,0)) from (
#N确定了间隔时间 如次日留存率就是1 此处1只代表次日,若等于2并不能说明中间的一天是否登陆,要结合lead当中的日期M一起使用
select 用户/设备,date,lead(date,M) over(partition by 用户/设备 order by date) lead_1_date
#M为延后的时间 为1 证明下一次出现的时间
from (
select distinct 用户/设备,date
#添加distinct一般是因为用户和设备等的次日留存率只需要计算一个
#即相同用户或者设备算作一个,即使在一天和第二天访问多次也算一个
from 原表
)t1
)t2此处建议结合第三大部分的第五小题一起食用。
三.案例实战和题目解析
1.nowcoderVQ25 查询每天刷题通过数最多的前二名用户id和刷题数
(1) 原题呈现
现有牛客刷题表`questions_pass_record`,请查询每天刷题通过数最多的前二名用户id和刷题数,输出按照日期升序排序,查询返回结果名称和顺序为
date|user_id|pass_count
drop table if exists questions_pass_record;
CREATE TABLE `questions_pass_record` (
`user_id` int NOT NULL,
`question_type` varchar(32) NOT NULL,
`device` varchar(14) NOT NULL,
`pass_count` int NOT NULL,
`date` date NOT NULL);
INSERT INTO questions_pass_record VALUES(101, 'java', 'app', 2, '2020-03-01');
INSERT INTO questions_pass_record VALUES(102, 'sql', 'pc', 15,'2020-03-01');
INSERT INTO questions_pass_record VALUES(102, 'python', 'pc', 9, '2021-04-09');
INSERT INTO questions_pass_record VALUES(202, 'python', 'pc', 11, '2021-04-09');
INSERT INTO questions_pass_record VALUES(104, 'python', 'app', 3,'2021-04-09');
INSERT INTO questions_pass_record VALUES(105, 'sql', 'pc', 60, '2018-08-15');
INSERT INTO questions_pass_record VALUES(104, 'sql', 'pc', 20, '2018-08-15');
INSERT INTO questions_pass_record VALUES(304, 'sql', 'pc', 10, '2018-08-15');输出:
date|user_id|pass_count
2018-08-15|105|60
2018-08-15|104|20
2020-03-01|102|15
2020-03-01|101|2
2021-04-09|202|11
2021-04-09|102|9(2) 题目分析和要求梳理:
请查询每天刷题通过数最多的前二名用户id和刷题数,输出按照日期升序排序,查询返回结果名称和顺序为 date|user_id|pass_count
1.每天刷题通过数最多
2.前二名用户id和刷题数
3.按照日期升序排序
分组排序类,前N名,很适合用row_number来进行排序。
(3) 解体解答:
第一步,用row_number来进行排序,
select user_id, pass_count, date, row_number() over(partition by date order by pass_count desc) rk
from questions_pass_record效果:

第二步,选出rk<=2的,
select date,user_id,pass_count from (
select user_id, pass_count, date, row_number() over(partition by date order by pass_count desc) rk
from questions_pass_record
)t1
where rk <=2
效果:

(4) 答案总和:
第二步即是答案总和了,比较简单。
select date,user_id,pass_count from (
select user_id, pass_count, date, row_number() over(partition by date order by pass_count desc) rk
from questions_pass_record
)t1
where rk <=2

(5) 题目小结:
此题比较简单,按照日期分类,排序按照通过题目数,用row_number排序后很容易得到结果,值得注意的是此种类型的题目往往是面试最爱考的,不可轻视,要注意其细节。
2.nowcoderVQ26 查询用户刷题日期和下一次刷题日期
(1) 原题呈现
现有牛客刷题记录表`questions_pass_record` ,请查询用户user_id,刷题日期date (每组按照date降序排列)和该用户的下一次刷题日期nextdate(若是没有则为None),组之间按照user_id升序排序,每组内按照date升序排列,查询返回结果名称和顺序为
user_id|date|nextdate
drop table if exists questions_pass_record;
CREATE TABLE `questions_pass_record` (
`user_id` int NOT NULL,
`question_type` varchar(32) NOT NULL,
`device` varchar(14) NOT NULL,
`question_id` int NOT NULL,
`date` date NOT NULL);
INSERT INTO questions_pass_record VALUES(101, 'java', 'app', 2, '2020-03-01');
INSERT INTO questions_pass_record VALUES(102, 'sql', 'pc', 15,'2021-07-07');
INSERT INTO questions_pass_record VALUES(102, 'python', 'pc', 9, '2021-04-09');
INSERT INTO questions_pass_record VALUES(102, 'python', 'app', 3,'2022-03-17');
INSERT INTO questions_pass_record VALUES(103, 'sql', 'pc', 60, '2018-08-15');
INSERT INTO questions_pass_record VALUES(104, 'sql', 'pc', 20, '2019-05-15');
INSERT INTO questions_pass_record VALUES(105, 'sql', 'pc', 550, '2022-07-25');
INSERT INTO questions_pass_record VALUES(105, 'sql', 'pc', 299, '2020-05-16');
INSERT INTO questions_pass_record VALUES(106, 'java', 'pc', 17, '2021-04-15');
INSERT INTO questions_pass_record VALUES(106, 'java', 'pc', 20, '2021-04-15');
输出:
user_id|date|nextdate
101|2020-03-01|None
102|2021-04-09|2021-07-07
102|2021-07-07|2022-03-17
102|2022-03-17|None
103|2018-08-15|None
104|2019-05-15|None
105|2020-05-16|2022-07-25
105|2022-07-25|None
106|2021-04-15|2021-04-15
106|2021-04-15|None(2) 题目分析和要求梳理:
请查询用户user_id,刷题日期date (每组按照date降序排列)和该用户的下一次刷题日期nextdate(若是没有则为None),组之间按照user_id升序排序,每组内按照date升序排列,
1.查询用户user_id,刷题日期date (每组按照date降序排列)和该用户的下一次刷题日期nextdate
2.组之间按照user_id升序排序
3.每组内按照date升序排列
(3) 解体解答:
略
(4) 答案总和:
select user_id,date,lead(date,1) over(partition by user_id order by date) nextdate
from questions_pass_record效果:

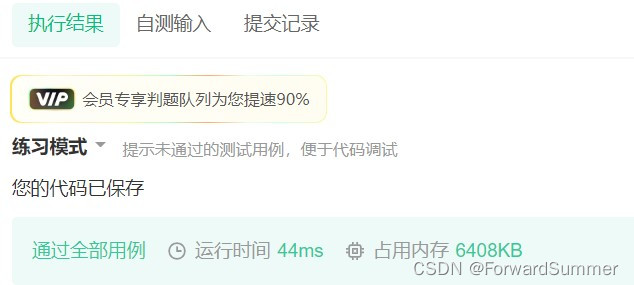
(5) 题目小结:
此题目算是lead函数的直接使用,没有什么难度,就是用lead函数找下一个日期,组之间按照user_id升序排序,这是默认的,每组内按照date升序排列,order by date asc,asc可省略。
3.nowcoderSQL136 每类试卷得分前3名
(1) 原题呈现
现有试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):

试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):

找到每类试卷得分的前3名,如果两人最大分数相同,选择最小分数大者,如果还相同,选择uid大者。由示例数据结果输出如下:
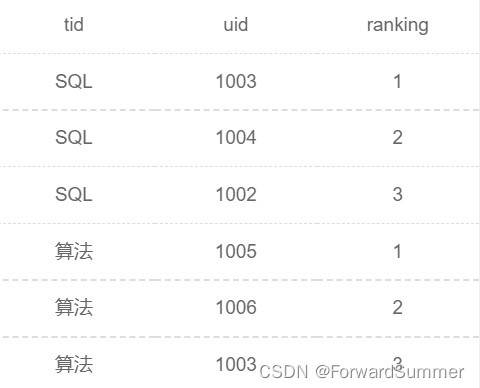
解释:有作答得分记录的试卷tag有SQL和算法,SQL试卷用户1001、1002、1003、1004有作答得分,最高得分分别为81、81、89、85,最低得分分别为78、81、86、40,因此先按最高得分排名再按最低得分排名取前三为1003、1004、1002。
drop table if exists examination_info,exam_record;
CREATE TABLE examination_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
exam_id int UNIQUE NOT NULL COMMENT '试卷ID',
tag varchar(32) COMMENT '类别标签',
difficulty varchar(8) COMMENT '难度',
duration int NOT NULL COMMENT '时长',
release_time datetime COMMENT '发布时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9001, 'SQL', 'hard', 60, '2021-09-01 06:00:00'),
(9002, 'SQL', 'hard', 60, '2021-09-01 06:00:00'),
(9003, '算法', 'medium', 80, '2021-09-01 10:00:00');
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2021-09-01 09:01:01', '2021-09-01 09:31:00', 78),
(1001, 9001, '2021-09-01 09:01:01', '2021-09-01 09:31:00', 81),
(1002, 9002, '2021-09-01 12:01:01', '2021-09-01 12:31:01', 81),
(1003, 9001, '2021-09-01 19:01:01', '2021-09-01 19:40:01', 86),
(1003, 9002, '2021-09-01 12:01:01', '2021-09-01 12:31:51', 89),
(1004, 9001, '2021-09-01 19:01:01', '2021-09-01 19:30:01', 85),
(1005, 9003, '2021-09-01 12:01:01', '2021-09-01 12:31:02', 85),
(1006, 9003, '2021-09-07 10:01:01', '2021-09-07 10:21:01', 84),
(1003, 9003, '2021-09-08 12:01:01', '2021-09-08 12:11:01', 40),
(1003, 9002, '2021-09-01 14:01:01', null, null);SQL|1003|1
SQL|1004|2
SQL|1002|3
算法|1005|1
算法|1006|2
算法|1003|3(2) 题目分析和要求梳理:
找到每类试卷得分的前3名,如果两人最大分数相同,选择最小分数大者,如果还相同,选择uid大者
1.每类试卷得分的前3名
2.两人最大分数相同,选择最小分数大者
3.如果还相同,选择uid大者
(3) 解体解答:
第一步,用row_number来进行分组排序
select tag,uid,row_number() over(partition by tag order by score desc) rk
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id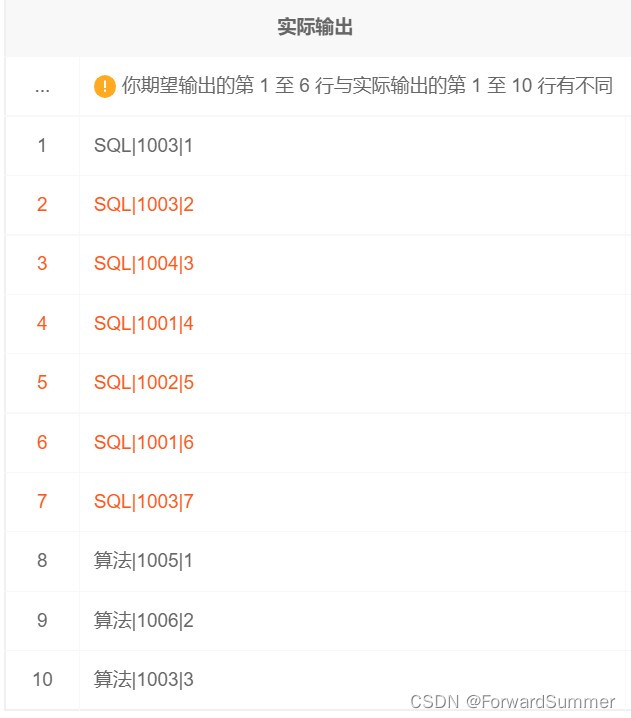
第二步,选出rk<=3的即可
select tag,uid,rk from(
select tag,uid,row_number() over(partition by tag order by score desc) rk
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
)t1
where rk <= 3
但是,麻烦的事情出现了,在上述的解答中,对于分组排序中相同的部分,是没有考虑的,在题目要求中,“如果两人最大分数相同,选择最小分数大者,如果还相同,选择uid大者,”成了此题的关键点。
那直接在窗口函数中使用max,min函数可以吗
select tag,uid,rk from(
select tag,uid,row_number() over(partition by tag order by max(score) desc,min(score) desc,uid desc) rk
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
)t1
where rk <= 3
不行的,使用了聚合函数必须有个东西进行分组,进行group by,那么在表的连接下方进行group by,同时这里也要加上uid,要不会出现以下错误,因为使用聚合函数时,必须把聚合函数前面的所有字段包含在group by中

那么加上group by之后:
select tag,uid,rk from(
select tag,uid,row_number() over(partition by tag order by max(score) desc,min(score) desc,uid desc) rk
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
group by tag,uid
)t1
where rk <= 3(4) 答案总和:
select tag,uid,rk from(
select tag,uid,row_number() over(partition by tag order by max(score) desc,min(score) desc,uid desc) rk
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
group by tag,uid
)t1
where rk <= 3
(5) 题目小结:
此题的关键在于排序的要求,特别的【2】:
坑1:每类试卷得分的前3名,因此不包含一个用户独占一科前几名的情况,例如1003的SQL考试分别是89分和86分,只取分高的那条数据。本质就是对比某科目每个用户的最高分。
坑2:如果最高分一样,那就对比最低分:order by max(score) desc,min(score) desc,uid desc
4.nowcoder SQL143 每份试卷每月作答数和截止当月的作答总数
(1) 原题呈现
现有试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):
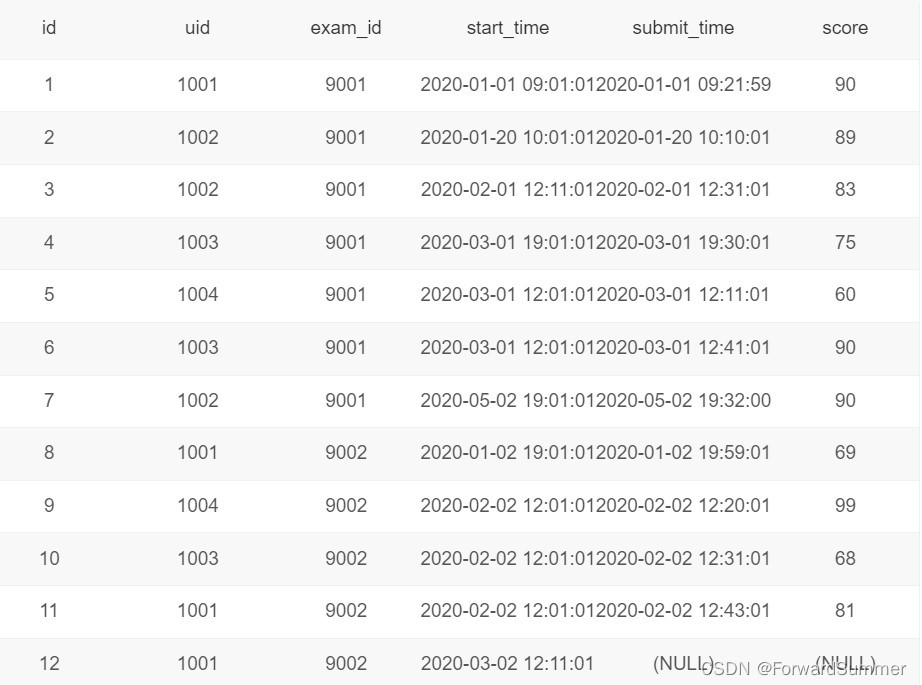
请输出每份试卷每月作答数和截止当月的作答总数。
由示例数据结果输出如下:
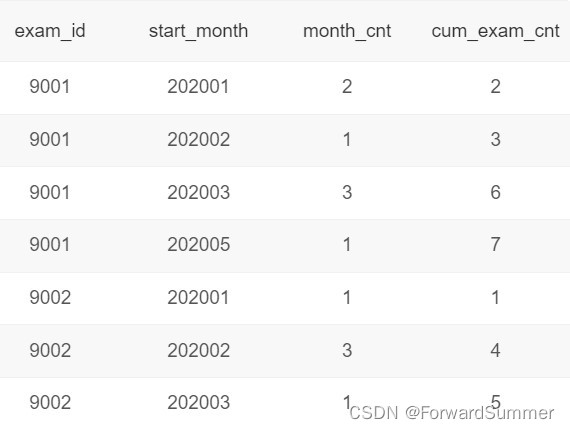
解释:试卷9001在202001、202002、202003、202005共4个月有被作答记录,每个月被作答数分别为2、1、3、1,截止当月累积作答总数为2、3、6、7。
(2) 题目分析和要求梳理:
请输出每份试卷每月作答数和截止当月的作答总数。
1.每月作答数
2.截止当月的作答总数。
截止类累计求和,典型的窗口函数求和问题,不再赘述。
(3) 解体解答:
第一步,求出每个月的作答数量,用group by聚合
select exam_id ,date_format(start_time,'%Y%m') start_month, count(start_time) ct
from exam_record
group by exam_id,date_format(start_time,'%Y%m')
第二步,使用窗口函数进行累计求和
select exam_id, start_month, ct, sum(ct) over(partition by exam_id order by start_month) cum_exam_cnt from
(
select exam_id ,date_format(start_time,'%Y%m') start_month, count(start_time) ct
from exam_record
group by exam_id,date_format(start_time,'%Y%m')
)t1

partition by exam_id 给作答分类,order by start_month进行时间累计的作用,如果没有了order by start_month,那么结果是这样子的:

(4) 答案总和:
略~
(5) 题目小结:
此类问题是sum窗口函数的典型应用,不再赘述,简单但是重要,应用较多,必须掌握。
特别的:
坑1:count(start_time) 是聚合作答起始时间而不是分数,有点怪,无伤大雅。
5.nowcoder 计算用户的平均次日留存率
(1) 原题呈现
题目:现在运营想要查看用户在某天刷题后第二天还会再来刷题的平均概率。请你取出相应数据。

根据示例,你的查询应返回以下结果:

(2) 题目分析和要求梳理:
现在运营想要查看用户在某天刷题后第二天还会再来刷题的平均概率。
题目要求很简单,没什么别的湾湾。
(3) 解体解答:
第一步首先选出所有的用户,第二部选出下一次出现的日期,比较简单,两步就合在一起:
select device_id,date,lead(date,1) over(partition by device_id order by date) lead_1_date
from (
select distinct device_id,date
from question_practice_detail
)t1 
第二步,做平均值分析,这里直接使用avg函数
select avg(if(datediff(lead_1_date,date) = 1,1,0)) from (
select device_id,date,lead(date,1) over(partition by device_id order by date) lead_1_date
from (
select distinct device_id,date
from question_practice_detail
)t1
)t2 
此处使用了avg函数,符合题目条件的(两者日期相差为1,即第二天出现了记录的设备)就算一个,不符合就算0,最后计算平均值,即是留存率。
这里也给出非窗口函数解法【5】:
select count(date2) / count(date1) as avg_ret
from (
select
distinct qpd.device_id,
qpd.date as date1,
uniq_id_date.date as date2
from question_practice_detail as qpd
left join(
select distinct device_id, date
from question_practice_detail
) as uniq_id_date
on qpd.device_id=uniq_id_date.device_id
and date_add(qpd.date, interval 1 day)=uniq_id_date.date
) as id_last_next_date(4) 答案总和:
略
(5) 题目小结:
本题目是非常经典的题目,求用户留存率,借助lead函数可以比较简单地实现,相较于left join的方法要容易理解得多。
6.nowcoder SQL142 对试卷得分做min-max归一化
(1) 原题呈现
现有试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):

试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):

在物理学及统计学数据计算时,有个概念叫min-max标准化,也被称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数为:
请你将用户作答高难度试卷的得分在每份试卷作答记录内执行min-max归一化后缩放到[0,100]区间,并输出用户ID、试卷ID、归一化后分数平均值;最后按照试卷ID升序、归一化分数降序输出。(注:得分区间默认为[0,100],如果某个试卷作答记录中只有一个得分,那么无需使用公式,归一化并缩放后分数仍为原分数)。
由示例数据结果输出如下:

解释:高难度试卷有9001、9002、9003;
作答了9001的记录有3条,分数分别为68、89、90,按给定公式归一化后分数为:0、95、100,而后两个得分都是用户1001作答的,因此用户1001对试卷9001的新得分为(95+100)/2≈98(只保留整数部分),用户1003对于试卷9001的新得分为0。最后结果按照试卷ID升序、归一化分数降序输出。
drop table if exists examination_info,exam_record;
CREATE TABLE examination_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
exam_id int UNIQUE NOT NULL COMMENT '试卷ID',
tag varchar(32) COMMENT '类别标签',
difficulty varchar(8) COMMENT '难度',
duration int NOT NULL COMMENT '时长',
release_time datetime COMMENT '发布时间'
)CHARACTER SET utf8 COLLATE utf8_bin;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9001, 'SQL', 'hard', 60, '2020-01-01 10:00:00'),
(9002, 'C++', 'hard', 80, '2020-01-01 10:00:00'),
(9003, '算法', 'hard', 80, '2020-01-01 10:00:00'),
(9004, 'PYTHON', 'medium', 70, '2020-01-01 10:00:00'),
(9005, 'WEB', 'hard', 80, '2020-01-01 10:00:00'),
(9006, 'PYTHON', 'hard', 80, '2020-01-01 10:00:00'),
(9007, 'web', 'hard', 80, '2020-01-01 10:00:00'),
(9008, 'Web', 'medium', 70, '2020-01-01 10:00:00'),
(9009, 'WEB', 'medium', 70, '2020-01-01 10:00:00'),
(9010, 'SQL', 'medium', 70, '2020-01-01 10:00:00');
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2020-01-01 09:01:01', '2020-01-01 09:21:59', 90),
(1003, 9002, '2020-01-01 19:01:01', '2020-01-01 19:30:01', 75),
(1004, 9002, '2020-01-01 12:01:01', '2020-01-01 12:11:01', 60),
(1003, 9002, '2020-01-01 12:01:01', '2020-01-01 12:41:01', 90),
(1002, 9002, '2020-01-02 19:01:01', '2020-01-02 19:32:00', 90),
(1003, 9001, '2020-01-02 12:01:01', '2020-01-02 12:31:01', 68),
(1001, 9002, '2020-01-02 12:01:01', '2020-01-02 12:43:01', 81),
(1001, 9005, '2020-01-02 12:11:01', null, null),
(1001, 9001, '2020-01-02 10:01:01', '2020-01-02 10:31:01', 89),
(1002, 9002, '2020-01-01 12:11:01', '2020-01-01 12:31:01', 83),
(1002, 9004, '2021-09-06 12:01:01', null, null),
(1002, 9002, '2021-05-05 18:01:01', null, null);输出
1001|9001|98
1003|9001|0
1002|9002|88
1003|9002|75
1001|9002|70
1004|9002|0(2) 题目分析和要求梳理:
请你将用户作答高难度试卷的得分在每份试卷作答记录内执行min-max归一化后缩放到[0,100]区间,并输出用户ID、试卷ID、归一化后分数平均值;最后按照试卷ID升序、归一化分数降序输出。
要求梳理
1.高难度试卷
2.执行min-max归一化
3.输出用户ID、试卷ID、归一化后分数平均值
4.按照试卷ID升序、归一化分数降序输出
整体思路
1.求出一个exam_id的最大值和最小值
2.根据公式求出avg_new_score
3.选出来然后降序排序
4.score不为null且为hard
(3) 解体解答:
第一步,用窗口函数求出exam_id的最大值和最小值,其中score不为null且为hard
select uid,e1.exam_id,score,
max(score) over(partition by exam_id) max_score,
min(score) over(partition by exam_id) max_score
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
where score is not null && difficulty = 'hard' 
第二步,进行归一化
select uid,exam_id,(score-min_score)/(max_score-min_score) max_min
from(
select uid,e1.exam_id,score,
max(score) over(partition by exam_id) max_score,
min(score) over(partition by exam_id) min_score
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
where score is not null && difficulty = 'hard'
)t1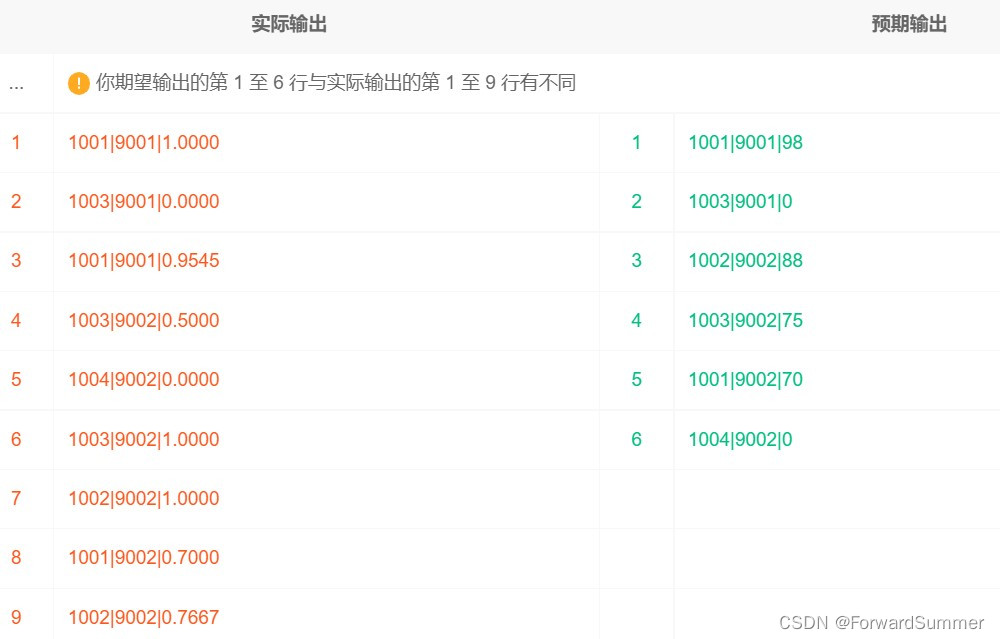
可以发现归一化的数值肯定不能作为实际的结果,要*100,除此之外,还有一个重要的因素,就是题目中所说的,“如果某个试卷作答记录中只有一个得分,那么无需使用公式”,那么要再加上一个if判断,即max_score=min_score,即答案记录只有一个。
select uid,exam_id,if(min_score = max_score,score,(score-min_score)*100/(max_score-min_score)) max_min
from(
select uid,e1.exam_id,score,
max(score) over(partition by exam_id) max_score,
min(score) over(partition by exam_id) min_score
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
where score is not null && difficulty = 'hard'
)t1
第三步,求平均值,并进行排序
select uid,exam_id,round(sum(max_min)/count(max_min),0) avg_new_score from (
select uid,exam_id,if(min_score = max_score,score,(score-min_score)*100/(max_score-min_score)) max_min
from(
select uid,e1.exam_id,score,
max(score) over(partition by exam_id) max_score,
min(score) over(partition by exam_id) min_score
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
where score is not null && difficulty = 'hard'
)t1
)t2
group by uid,exam_id
order by exam_id,avg_new_score desc 
(4) 答案总和:
select uid,exam_id,round(sum(max_min)/count(max_min),0) avg_new_score from (
select uid,exam_id,if(min_score = max_score,score,(score-min_score)*100/(max_score-min_score)) max_min
from(
select uid,e1.exam_id,score,
max(score) over(partition by exam_id) max_score,
min(score) over(partition by exam_id) min_score
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
where score is not null && difficulty = 'hard'
)t1
)t2
group by uid,exam_id
order by exam_id,avg_new_score desc
(5) 题目小结:
本题整体思路不难,用窗口函数求出最大值最小值添加到后面很容易求解,坑点主要有:
(1)归一化要乘以100
(2)答案只有一个的情况的判断,用min_score = max_score
(3)求和换成avg函数也是可以的
select uid,exam_id,round(avg(max_min),0) avg_new_score from (
select uid,exam_id,if(min_score = max_score,score,(score-min_score)*100/(max_score-min_score)) max_min
from(
select uid,e1.exam_id,score,
max(score) over(partition by exam_id) max_score,
min(score) over(partition by exam_id) min_score
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
where score is not null && difficulty = 'hard'
)t1
)t2
group by uid,exam_id
order by exam_id,avg_new_score desc7.nowcoder SQL137 第二快/慢用时之差大于试卷时长一半的试卷
(1) 原题呈现
现有试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):

试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):
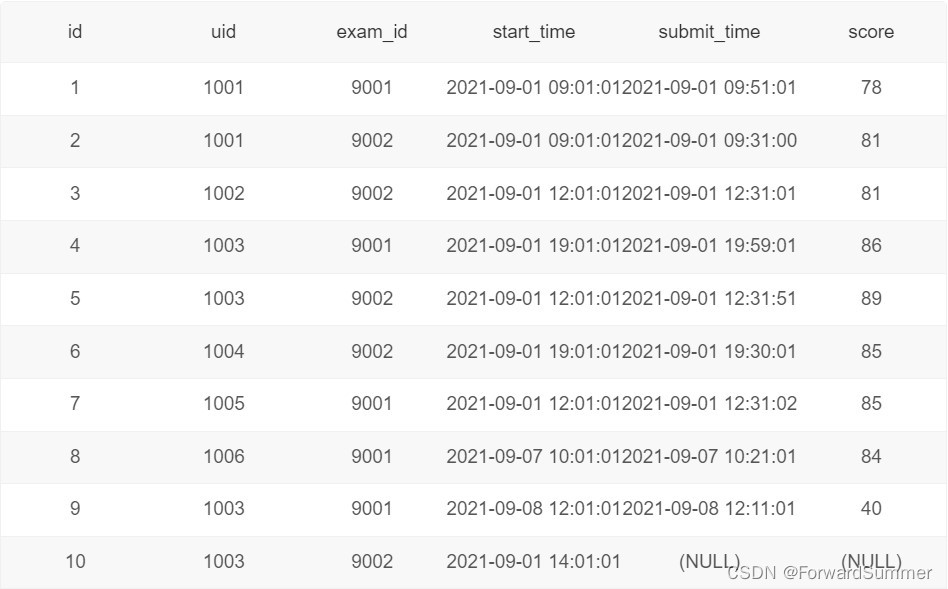
找到第二快和第二慢用时之差大于试卷时长的一半的试卷信息,按试卷ID降序排序。由示例数据结果输出如下:
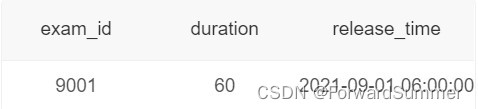
解释:试卷9001被作答用时有50分钟、50分钟、30分1秒、11分钟、10分钟,第二快和第二慢用时之差为50分钟-11分钟=39分钟,试卷时长为60分钟,因此满足大于试卷时长一半的条件,输出试卷ID、时长、发布时间。
drop table if exists examination_info,exam_record;
CREATE TABLE examination_info (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
exam_id int UNIQUE NOT NULL COMMENT '试卷ID',
tag varchar(32) COMMENT '类别标签',
difficulty varchar(8) COMMENT '难度',
duration int NOT NULL COMMENT '时长',
release_time datetime COMMENT '发布时间'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO examination_info(exam_id,tag,difficulty,duration,release_time) VALUES
(9001, 'SQL', 'hard', 60, '2021-09-01 06:00:00'),
(9002, 'C++', 'hard', 60, '2021-09-01 06:00:00'),
(9003, '算法', 'medium', 80, '2021-09-01 10:00:00');
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2021-09-01 09:01:01', '2021-09-01 09:51:01', 78),
(1001, 9002, '2021-09-01 09:01:01', '2021-09-01 09:31:00', 81),
(1002, 9002, '2021-09-01 12:01:01', '2021-09-01 12:31:01', 81),
(1003, 9001, '2021-09-01 19:01:01', '2021-09-01 19:59:01', 86),
(1003, 9002, '2021-09-01 12:01:01', '2021-09-01 12:31:51', 89),
(1004, 9002, '2021-09-01 19:01:01', '2021-09-01 19:30:01', 85),
(1005, 9001, '2021-09-01 12:01:01', '2021-09-01 12:31:02', 85),
(1006, 9001, '2021-09-07 10:01:01', '2021-09-07 10:12:01', 84),
(1003, 9001, '2021-09-08 12:01:01', '2021-09-08 12:11:01', 40),
(1003, 9002, '2021-09-01 14:01:01', null, null),
(1005, 9001, '2021-09-01 14:01:01', null, null),
(1003, 9003, '2021-09-08 15:01:01', null, null);输出:
9001|60|2021-09-01 06:00:00(2) 题目分析和要求梳理:
找到第二快和第二慢用时之差大于试卷时长的一半的试卷信息,按试卷ID降序排序。
1.由第二快和第二慢很容易想到进行排序,经常使用的row_number,rank,dense_rank
2.大于试卷时长的一半的试卷信息,很明显要进行两个表的连接
3.按试卷ID降序排序
(3) 解体解答:
1.求出所有试卷的时长,灰常简单,直接给出
select uid,exam_id,timestampdiff(minute,start_time,submit_time) diff_time
from exam_record
where score is not null注意过滤为null的值,产生结果如下:

图来自牛客我的账号题解,不再截新图凑合着看,源地址
2.对试卷时长进行排序,用row_number
select uid,exam_id,diff_time,row_number() over(partition by exam_id order by diff_time) rk
from(
select uid,exam_id,timestampdiff(minute,start_time,submit_time) diff_time
from exam_record
where score is not null
)t1产生结果如下:

3.找到自己各自最大的序号(为啥找最大的从第4步比较好想)
select uid,exam_id,diff_time,rk,max(rk) over(partition by exam_id) max_rk
from (
select uid,exam_id,diff_time,row_number() over(partition by exam_id order by diff_time) rk
from(
select uid,exam_id,timestampdiff(minute,start_time,submit_time) diff_time
from exam_record
where score is not null
)t1
)t2产生结果如下:
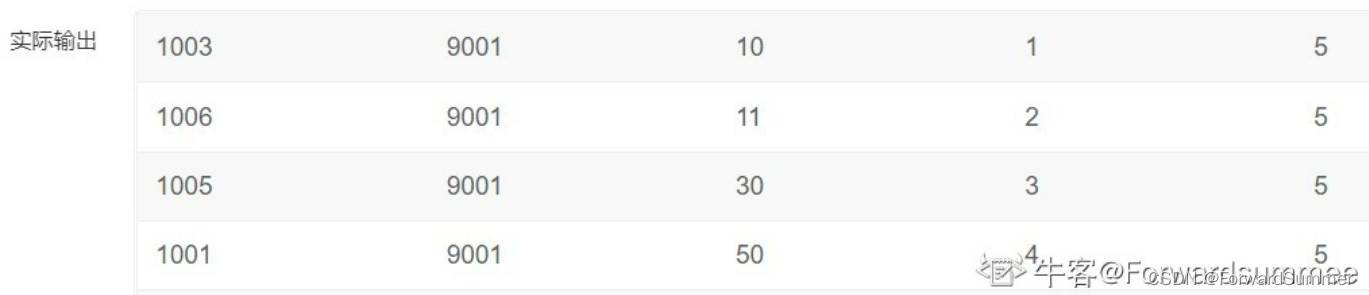
4.把最大值和最小值选出来,注意此时过滤掉rk=max(rk)和rk==1的,就是剩下的第二快和第二慢的
select exam_id,(max(diff_time)- min(diff_time)) diff
from (
select uid,exam_id,diff_time,rk,max(rk) over(partition by exam_id) max_rk
from (
select uid,exam_id,diff_time,row_number() over(partition by exam_id order by diff_time) rk
from(
select uid,exam_id,timestampdiff(minute,start_time,submit_time) diff_time
from exam_record
where score is not null
)t1
)t2
) t3
where rk != 1 && rk != max_rk
group by exam_id
(4) 答案总和:
with t4 as(
select exam_id,(max(diff_time)- min(diff_time)) diff
from (
select uid,exam_id,diff_time,rk,max(rk) over(partition by exam_id) max_rk
from (
select uid,exam_id,diff_time,row_number() over(partition by exam_id order by diff_time) rk
from(
select uid,exam_id,timestampdiff(minute,start_time,submit_time) diff_time
from exam_record
where score is not null
)t1
)t2
) t3
where rk != 1 && rk != max_rk
group by exam_id
)
select e1.exam_id,duration,release_time
from t4 join examination_info e1
on t4.exam_id = e1.exam_id
where diff >= duration/2
order by e1.exam_id desc
(5) 题目小结:
此题目思路不难,就是具体执行步骤比较繁琐,从简单的步骤慢慢向难处累计比较好做。
8.nowcoder SQL144 每月及截止当月的答题情况
(1) 原题呈现
现有试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):

请输出自从有用户作答记录以来,每月的试卷作答记录中月活用户数、新增用户数、截止当月的单月最大新增用户数、截止当月的累积用户数。结果按月份升序输出。
由示例数据结果输出如下:
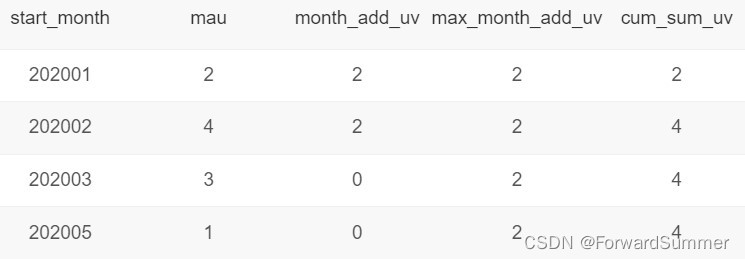
由上述矩阵可以看出,2020年1月有2个用户活跃(mau=2),当月新增用户数为2;
2020年2月有4个用户活跃,当月新增用户数为2,最大单月新增用户数为2,当前累积用户数为4。
(2) 题目分析和要求梳理:
请输出自从有用户作答记录以来,
1.每月的试卷作答记录中月活用户数、
2.新增用户数、
3.截止当月的单月最大新增用户数、
4.截止当月的累积用户数。
结果按月份升序输出。
(3) 解体解答:
刚开始接触此题目,想的比较复杂,且把新增用户数和每个月截至最大的用户数搞混,导致做了数小时,写出来满足样例的答案,但是提交后实际的所有案例执行没有一个通过:
select start_month,mau,month_add_uv,max(month_add_uv) over(order by start_month) max_month_add_uv,cum_sum_uv from (
select start_month,mau,if(diff_cum is null,cum_sum_uv,cum_sum_uv-diff_cum) month_add_uv,cum_sum_uv from (
select start_month,mau,cum_sum_uv,lag(cum_sum_uv,1) over(order by start_month) diff_cum from (
select start_month,mau,max(mau) over(order by start_month) cum_sum_uv
from (
select date_format(start_time,'%Y%m') start_month,count(distinct uid) mau
from exam_record
group by date_format(start_time,'%Y%m')
)t1
)t2
)t3
)t4关键原因就是把新增用户数和截止每月最大活跃用户数搞混了,简单的把每月活跃用户数用lag函数相减来当作新增用户数处理。
参考于 【3】,利用row_number()排序进行求解每个月的新增用户。
第一步,求解每个用户在每个月的排序
select uid, date_format(start_time, '%Y%m') as start_month,
row_number() over(partition by uid order by start_time) as rn
from exam_record结果如下:

第二步,求解每个月的mau,非常简单,直接给出:
select start_month,count(distinct uid) mau from (
select uid, date_format(start_time, '%Y%m') as start_month,
row_number() over(partition by uid order by start_time) as rn
from exam_record
)tm
group by start_month 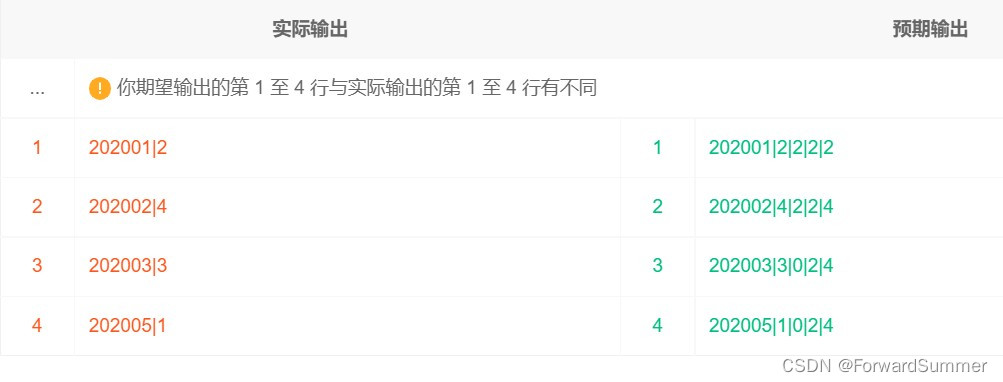
第三步,求解每个月的新增,利用第一步中的排序,当rn为1时,可以算作一个计数
select start_month,count(if(rn=1, uid, null)) as month_add_uv from (
select uid, date_format(start_time, '%Y%m') as start_month,
row_number() over(partition by uid order by start_time) as rn
from exam_record
)tm
group by start_month 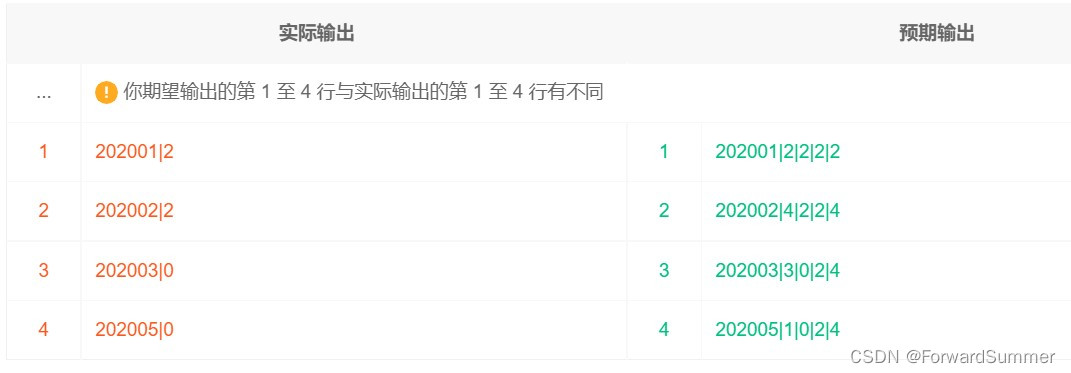
第四步,求解累计每月新增最大以及相应的累计和
select start_month,max(month_add_uv) over(order by start_month) max_month_add_uv, sum(month_add_uv) over(order by start_month) from(
select start_month,count(if(rn=1, uid, null)) as month_add_uv from (
select uid, date_format(start_time, '%Y%m') as start_month,
row_number() over(partition by uid order by start_time) as rn
from exam_record
)tm
group by start_month
)ts
(4) 答案总和:
select start_month,mau,month_add_uv,
max(month_add_uv) over(order by start_month) max_month_add_uv,
sum(month_add_uv) over(order by start_month) from(
select start_month,count(distinct uid) as mau, count(if(rn=1, uid, null)) as month_add_uv from (
select uid, date_format(start_time, '%Y%m') as start_month,
row_number() over(partition by uid order by start_time) as rn
from exam_record
)tm
group by start_month
)ts 
(5) 题目小结:
刚开始求解新增用户数还是挺困难的,但是掌握方法之后就比较简单了,此题目设计了多个窗口函数,非常适合拿来做案例,尤其是要掌握如何求解新增用户数。
9.nowcoder SQL138 连续两次作答试卷的最大时间窗
(1) 原题呈现
现有试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):

请计算在2021年至少有两天作答过试卷的人中,计算该年连续两次作答试卷的最大时间窗days_window,那么根据该年的历史规律他在days_window天里平均会做多少套试卷,按最大时间窗和平均做答试卷套数倒序排序。由示例数据结果输出如下:

解释:用户1006分别在20210901、20210906、20210907作答过3次试卷,连续两次作答最大时间窗为6天(1号到6号),他1号到7号这7天里共做了3张试卷,平均每天3/7=0.428571张,那么6天里平均会做0.428571*6=2.57张试卷(保留两位小数);
用户1005在20210905做了两张试卷,但是只有一天的作答记录,过滤掉。
备注:按最大时间窗和平均做答试卷套数倒序排序,保留两位小数
(2) 题目分析和要求梳理:
请计算在2021年至少有两天作答过试卷的人中,计算该年连续两次作答试卷的最大时间窗days_window,那么根据该年的历史规律他在days_window天里平均会做多少套试卷,按最大时间窗和平均做答试卷套数倒序排序。
1.2021年
2.至少两天作答
3.连续两次作答试卷的最大时间窗
4.最大时间窗内平均会做多少试卷
5.按照最大时间窗口和作答试卷倒排
按照题目要求,首先,要求得最大时间窗口,这比较容易,直接用lead求解即可,关键是弄懂如何让求最大时间窗内平均会做多少试卷,是要用最大得时间减去最小的时间乘上最大时间窗口内的平均答题数,说白了就是
最大时间窗口做题平均值*整个时间(从头到尾)
即用能代表整个时间的最大时间窗口去估量整个时间。过滤条件为2021年和至少两天作答,排序都是降序,很容易。
(3) 解体解答:
第一步,用lead函数求得下一次题目出现的时间
select uid,start_time,
lead(start_time,1) over(partition by uid order by start_time ) next_date
from exam_record
where year(start_time) = 2021
第二步,求最大时间窗口以及整个时间窗口的最大值,最小值和以及答题数量
select uid,
max(datediff(next_date,start_time))+1 max_datediff,
max(start_time) max_date,
min(start_time) min_date,
count(*) ct_all,
count(distinct date_format(start_time,'%Y%m%d')) ct
from (
select uid,start_time,
lead(start_time,1) over(partition by uid order by start_time ) next_date
from exam_record
where year(start_time) = 2021
)t1
group by uid
having ct > 1max_date:最大日期
min_date:最小日期
他们的差值即是整个时间窗口
坑一:max_datediff最后的值需要加一,因为日期上间隔一天相当于一共两天
坑二:ct_all是整个答题数量,ct是不同天的答题数量,例如案例中的1005一天答题两次,但是算一天,利用having ct > 1即可过滤1005的情况

第三步,求解最大时间窗内平均会做多少试卷
select uid,max_datediff days_window,round(max_datediff*ct_all/(datediff(max_date,min_date)+1),2) avg_exam_cnt
from t2
order by days_window desc, avg_exam_cnt desc注意t2即为第二步中的表

(4) 答案总和:
with t2 as(
select uid,
max(datediff(next_date,start_time))+1 max_datediff,
max(start_time) max_date,
min(start_time) min_date,
count(*) ct_all,
count(distinct date_format(start_time,'%Y%m%d')) ct
from (
select uid,start_time,
lead(start_time,1) over(partition by uid order by start_time ) next_date
from exam_record
where year(start_time) = 2021
)t1
group by uid
having ct > 1
)
select uid,max_datediff days_window,round(max_datediff*ct_all/(datediff(max_date,min_date)+1),2) avg_exam_cnt
from t2
order by days_window desc, avg_exam_cnt desc 
(5) 题目小结:
此题目搞清楚最大事件窗口与整个时间窗口以及进行过滤作答数量就很容易求解。
10.nowcoder QL141 试卷完成数同比2020年的增长率及排名变化
(1) 原题呈现
现有试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):
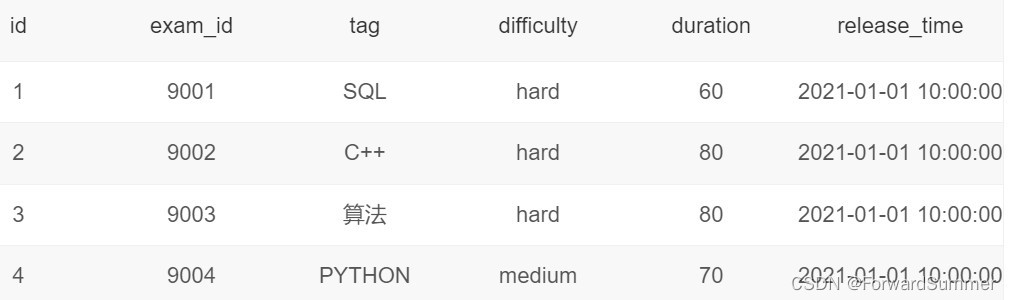
试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):

请计算2021年上半年各类试卷的做完次数相比2020年上半年同期的增长率(百分比格式,保留1位小数),以及做完次数排名变化,按增长率和21年排名降序输出。
由示例数据结果输出如下:

解释:2020年上半年有3个tag有作答完成的记录,分别是C++、SQL、PYTHON,它们被做完的次数分别是3、3、2,做完次数排名为1、1(并列)、3;
2021年上半年有2个tag有作答完成的记录,分别是算法、SQL,它们被做完的次数分别是3、2,做完次数排名为1、2;具体如下:
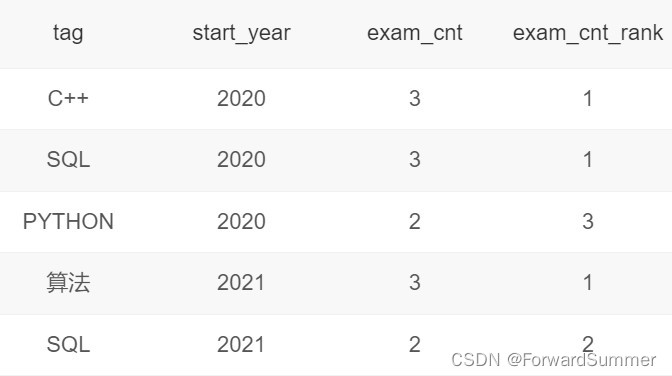
因此能输出同比结果的tag只有SQL,从2020到2021年,做完次数3=>2,减少33.3%(保留1位小数);排名1=>2,后退1名。
(2) 题目分析和要求梳理:
请计算2021年上半年各类试卷的做完次数相比2020年上半年同期的增长率(百分比格式,保留1位小数),以及做完次数排名变化,按增长率和21年排名降序输出。
明确要求:
1.2021年上半年
2.各类试卷的做完次数 相比2020年上半年同期的增长率
3.百分比格式,保留1位小数
4.做完次数排名变化
5.按增长率和21年排名降序输出
另外在题目的解释中可以发现,做完次数是并列,队排序窗口函数美敏感的同学立刻能发现这边应该用rank(),那么题目要求的隐含条件还有就是:
6.做完次数是并列的
另外,题目给出了另外的表格,如果能把表格先出来,就成功一小半来了。
(3) 解体解答:
第一步,直接求最简单的,求每个类别也就是tag2020年和2021年上半年的昨晚数量:
select tag ,year(start_time) start_year,count(score) exam_cnt
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
where month(start_time) < 7
group by tag,year(start_time)
having exam_cnt != 0难点一:上半年的数量,其实也算不上难点,直接求month(start_time) < 7就可以了
难点二:此处加上了exam_cnt != 0,是后来加上的,做完次数为0就不统计了
产生的结果如下:

第二步,利用rank()窗口函数进行排序,给出的答案中要求带着相应的排序
select tag,start_year,exam_cnt,rank() over(partition by start_year order by exam_cnt desc) rk from(
select tag ,year(start_time) start_year,count(score) exam_cnt
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
where month(start_time) < 7
group by tag,year(start_time)
having exam_cnt != 0
)t1这一步非常简单,没啥好说的

第三步,求每个类别的相较于上年的增长率,以及相应的排名,这边用个临时表
with t2 as(
select tag,start_year,exam_cnt,rank() over(partition by start_year order by exam_cnt desc) rk
from(
select tag ,year(start_time) start_year,count(score) exam_cnt
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
where month(start_time) < 7
group by tag,year(start_time)
having exam_cnt != 0
)t1
)
select t3.tag,t3.exam_cnt exam_cnt_20,
t4.exam_cnt exam_cnt_21,
(t4.exam_cnt-t3.exam_cnt)/t3.exam_cnt de,t3.rk exam_cnt_rank_20,
t4.rk exam_cnt_rank_21,
(cast(t4.rk as signed)-cast(t3.rk as signed)) rank_delta from
t2 t3 join t2 t4 on t3.tag = t4.tag
where t3.start_year!= t4.start_year && t3.start_year = 2020 && t4.start_year = 2021
order by de desc,exam_cnt_rank_21 desc难点三:怎么把相同的处于不同行的相同类别的数据连接起来,这边我使用了自连接,我认为比较好理解一点,那么在代码中就是
from t2 t3 join t2 t4 on t3.tag = t4.tag难点四:过滤条件
where t3.start_year!= t4.start_year && t3.start_year = 2020 && t4.start_year = 2021这边我写的比较复杂,但是比较通用,即在自连接的情况下,直接过滤类别两个不同时间
难点五:如果直接相减会报错,BIGINT UNSIGNED value is out of range
在此处
t4.rk-t3.rk那么使用cast就可以了
(cast(t4.rk as signed)-cast(t3.rk as signed)) 
第四步,将百分比添加上
select tag,exam_cnt_20, exam_cnt_21,concat(round(100*de,1),'%'),exam_cnt_rank_20, exam_cnt_rank_21,rank_delta from(
select t3.tag,t3.exam_cnt exam_cnt_20,t4.exam_cnt exam_cnt_21,(t4.exam_cnt-t3.exam_cnt)/t3.exam_cnt de,t3.rk exam_cnt_rank_20,t4.rk exam_cnt_rank_21,(cast(t4.rk as signed)-cast(t3.rk as signed)) rank_delta from
t2 t3 join t2 t4 on t3.tag = t4.tag
where t3.start_year!= t4.start_year && t3.start_year = 2020 && t4.start_year = 2021
order by de desc,exam_cnt_rank_21 desc
)t5
(4) 答案总和:
with t2 as(
select tag,start_year,exam_cnt,rank() over(partition by start_year order by exam_cnt desc) rk
from(
select tag ,year(start_time) start_year,count(score) exam_cnt
from examination_info e1 join exam_record e2
on e1.exam_id = e2.exam_id
where month(start_time) < 7
group by tag,year(start_time)
having exam_cnt != 0
)t1
)
select tag,exam_cnt_20, exam_cnt_21,concat(round(100*de,1),'%'),exam_cnt_rank_20, exam_cnt_rank_21,rank_delta from(
select t3.tag,t3.exam_cnt exam_cnt_20,t4.exam_cnt exam_cnt_21,(t4.exam_cnt-t3.exam_cnt)/t3.exam_cnt de,t3.rk exam_cnt_rank_20,t4.rk exam_cnt_rank_21,(cast(t4.rk as signed)-cast(t3.rk as signed)) rank_delta from
t2 t3 join t2 t4 on t3.tag = t4.tag
where t3.start_year!= t4.start_year && t3.start_year = 2020 && t4.start_year = 2021
order by de desc,exam_cnt_rank_21 desc
)t5 
(5) 题目小结:
此题的关键在于连接两个相同tag不同时期的数据
以及出现BIGINT UNSIGNED value is out of range的错误该区怎么处理
以及用round来进行百分比输出也比较经典.
11.nowcoder SQL140 未完成率较高的50%用户近三个月答卷情况
(1) 原题呈现:
现有用户信息表user_info(uid用户ID,nick_name昵称, achievement成就值, level等级, job职业方向, register_time注册时间):

试卷信息表examination_info(exam_id试卷ID, tag试卷类别, difficulty试卷难度, duration考试时长, release_time发布时间):

试卷作答记录表exam_record(uid用户ID, exam_id试卷ID, start_time开始作答时间, submit_time交卷时间, score得分):

请统计SQL试卷上未完成率较高的50%用户中,6级和7级用户在有试卷作答记录的近三个月中,每个月的答卷数目和完成数目。按用户ID、月份升序排序。
由示例数据结果输出如下:

解释:各个用户对SQL试卷的未完成数、作答总数、未完成率如下:

1001、1002、1003分别排在1.0、0.5、0.0的位置,因此较高的50%用户(排位<=0.5)为1002、1003;
1003不是6级或7级;
有试卷作答记录的近三个月为202005、202003、202002;
这三个月里1002的作答题数分别为3、2、2,完成数目分别为1、1、1。
(2) 题目分析和要求梳理:
请统计SQL试卷上未完成率较高的50%用户中,6级和7级用户在有试卷作答记录的近三个月中,每个月的答卷数目和完成数目。按用户ID、月份升序排序。
1.SQL试卷
2.完成率较高的50%用户 按照未完成率排序区前一半
3.6级和7级用户
4.有试卷作答记录的近三个月中
5.每个月的答卷数目和完成数目
6.按用户ID、月份升序排序
本题的要求其实都容易理解,但是限制条件要注意顺序,在解释中可以看出坑。
(3) 解体解答:
第一步,求出每个uid的总的答题数目和未完成的数目
select distinct u1.uid uid,
sum(if(score is null,1,0)) over(partition by u1.uid) incomplete_cnt,
count(*) over(partition by u1.uid) total_cnt
from user_info u1 join exam_record e1
on u1.uid = e1.uid join examination_info e2
on e1.exam_id = e2.exam_id
where tag = 'SQL' 
第二步,求出未完成率:
select uid,incomplete_cnt,total_cnt,incomplete_cnt/total_cnt incomplete_rate from(
select distinct u1.uid uid,
sum(if(score is null,1,0)) over(partition by u1.uid) incomplete_cnt,
count(*) over(partition by u1.uid) total_cnt
from user_info u1 join exam_record e1
on u1.uid = e1.uid join examination_info e2
on e1.exam_id = e2.exam_id
where tag = 'SQL'
)t1
第三步,求出分布率,此处用了present_rank()函数,刚开始使用的row_number函数然后排序取前一半,总是只能过2/3案例,最后排查是取前一半除了问题,在解释中明确提到了:1001、1002、1003分别排在1.0、0.5、0.0的位置,所以有意让我们使用present_rank()函数。
select uid,count(*) over() ct_all,percent_rank() over(order by incomplete_rate desc) rk from (
select uid,incomplete_cnt,total_cnt,incomplete_cnt/total_cnt incomplete_rate from(
select distinct u1.uid uid,
sum(if(score is null,1,0)) over(partition by u1.uid) incomplete_cnt,
count(*) over(partition by u1.uid) total_cnt
from user_info u1 join exam_record e1
on u1.uid = e1.uid join examination_info e2
on e1.exam_id = e2.exam_id
where tag = 'SQL'
)t1
)t2 
第四步,选出满足条件的uid
select uid from (
select uid,count(*) over() ct_all,percent_rank() over(order by incomplete_rate desc) rk from (
select uid,incomplete_cnt,total_cnt,incomplete_cnt/total_cnt incomplete_rate from(
select distinct u1.uid uid,
sum(if(score is null,1,0)) over(partition by u1.uid) incomplete_cnt,
count(*) over(partition by u1.uid) total_cnt
from user_info u1 join exam_record e1
on u1.uid = e1.uid join examination_info e2
on e1.exam_id = e2.exam_id
where tag = 'SQL'
)t1
)t2
)t3
where rk <= 0.5
第五步,选出满足条件的uid的相应的每个月的完成试卷数和总的试卷数
with t4 as(
select uid from (
select uid,count(*) over() ct_all,percent_rank() over(order by incomplete_rate desc) rk from (
select uid,incomplete_cnt,total_cnt,incomplete_cnt/total_cnt incomplete_rate from(
select distinct u1.uid uid,
sum(if(score is null,1,0)) over(partition by u1.uid) incomplete_cnt,
count(*) over(partition by u1.uid) total_cnt
from user_info u1 join exam_record e1
on u1.uid = e1.uid join examination_info e2
on e1.exam_id = e2.exam_id
where tag = 'SQL'
)t1
)t2
)t3
where rk <= 0.5
)
select u1.uid uid , date_format(start_time,'%Y%m') start_month,
count(*) total_cnt,
sum(if(score is not null,1,0)) complete_cnt
from user_info u1 join exam_record e1
on u1.uid = e1.uid join examination_info e2
on e1.exam_id = e2.exam_id
where u1.uid in (select uid from t4) && (level = 6 || level = 7)
group by u1.uid, start_month
order by u1.uid, start_month
第六步,利用row_number()对每个月进行排序
select uid,start_month,total_cnt,complete_cnt,row_number() over(partition by uid order by start_month desc) rk
from(
select u1.uid uid , date_format(start_time,'%Y%m') start_month,
count(*) total_cnt,
sum(if(score is not null,1,0)) complete_cnt
from user_info u1 join exam_record e1
on u1.uid = e1.uid join examination_info e2
on e1.exam_id = e2.exam_id
where u1.uid in (select uid from t4) && (level = 6 || level = 7)
group by u1.uid, start_month
order by u1.uid, start_month
)t5
第七步,选取rk<=3的月份,也就是最近的三个月份,最后进行排序
select uid,start_month,total_cnt,complete_cnt from (
select uid,start_month,total_cnt,complete_cnt,row_number() over(partition by uid order by start_month desc) rk
from(
select u1.uid uid , date_format(start_time,'%Y%m') start_month,
count(*) total_cnt,
sum(if(score is not null,1,0)) complete_cnt
from user_info u1 join exam_record e1
on u1.uid = e1.uid join examination_info e2
on e1.exam_id = e2.exam_id
where u1.uid in (select uid from t4) && (level = 6 || level = 7)
group by u1.uid, start_month
order by u1.uid, start_month
)t5
)t6
where rk <= 3
order by uid,start_month
(4) 答案总和:
with t4 as(
select uid from (
select uid,count(*) over() ct_all,percent_rank() over(order by incomplete_rate desc) rk from (
select uid,incomplete_cnt,total_cnt,incomplete_cnt/total_cnt incomplete_rate from(
select distinct u1.uid uid,
sum(if(score is null,1,0)) over(partition by u1.uid) incomplete_cnt,
count(*) over(partition by u1.uid) total_cnt
from user_info u1 join exam_record e1
on u1.uid = e1.uid join examination_info e2
on e1.exam_id = e2.exam_id
where tag = 'SQL'
)t1
)t2
)t3
where rk <= 0.5
)
select uid,start_month,total_cnt,complete_cnt from (
select uid,start_month,total_cnt,complete_cnt,row_number() over(partition by uid order by start_month desc) rk
from(
select u1.uid uid , date_format(start_time,'%Y%m') start_month,
count(*) total_cnt,
sum(if(score is not null,1,0)) complete_cnt
from user_info u1 join exam_record e1
on u1.uid = e1.uid join examination_info e2
on e1.exam_id = e2.exam_id
where u1.uid in (select uid from t4) && (level = 6 || level = 7)
group by u1.uid, start_month
order by u1.uid, start_month
)t5
)t6
where rk <= 3
order by uid,start_month
(5) 题目小结:
本题目要求清晰,不难解答,但是步骤繁琐,要注意在每一个表里的限制条件,是不是在应该的步骤中添加限制条件,比如:where tag = 'SQL' 和(level = 6 || level = 7)这两个限制条件选错位置那将得到不对的结果,还有就是percent_rank()函数的使用,一般用的少,刚开始想使用row_number排序来解决,但是始终不对,最后换成percent_rank()得以通过。
四.面试实战
终于到了面试环节,其实,此部分是整个窗口函数应用最为简单的部分。在上节中,可以发现个别题目绕来绕去,且需求模棱两可,有些不通过答案验证根本想不到,abnormal!
下面三个子章节的前两部分是个人秋招碰到的关于窗口函数的题目,明显可以感觉到是更简单的。在面试中,能说出解题思路其实就能拿到这题一半的应用分了,剩下的就是把具体的细节强清楚,越清楚给人的印象越好。
第四个子章节是个人在leetcode或者牛客等上看到过的面经,这里也整理一下,持续更新,可以的话点个赞,Thanks!
1.某想 大数据开发岗 面试
原题呈现
现在有2019-2022年的每天电脑的销售量,求2021年一月到十二月累计销量数码产品
参考解答
select mon,sum(sum_mon) over(order by mon) from(
select date_format(给定日期,'%Y%m') mon, sum(每天的销售量) sum_mon
from 原表
where year(给定日期) = 2021
group by mon
)t1题目小结
本题目是sum窗口函数的简单应用,可惜当时面试窗口函数忘得干干净净,只说了大致思路,在手撕代码时写的乱七八糟,虽然过了一面,但二面之后就被发了感谢信,由此催生了本篇博客,算是一点补救,也是对知识的回顾。
我时常在想,如果此道面试题写的不错,是不是两面之和的分数可以进行三面或者hr面,可惜人生没有如果,只有慢慢的积累和慢慢的成长。机会来到时,总是猝不及防,准备的好的人握着枪拿着刀迎面而上,准备不好的人落荒而逃。
2.某子科技 数据开发 面试
原题呈现
求班级里每个学科考试分数的前三名同学
参考解答
select 同学 from (
select 同学,row_number() over(partition by 学科 order by 分数) rk
from 班级成绩表格
)
where rk <= 3题目小结
此题也是比较简单的,用最基础的排序函数就可以解决。此外,在秋招中海遇到了其他的关于窗口函数的问题但都是属于比较简单的问题,没有结合实际的案例,其他的问题可以看看第三部分。
3.某华财险 大数据开发 笔试
原题呈现
求num_set表中 num的中位数
参考解答【7】
select avg(num) from(
select num,count(*) over() ct,row_number() over(order by num) rk
from num_set
)t1
where rk in (floor(ct/2)+1,if(mod(ct,2)=0,floor(ct/2),floor(ct/2)+1))还是以SQL136每类试卷得分前3名为案例,求出表exam_record中有成绩的同学的中位数。
select avg(score) from(
select score,count(*) over() ct,row_number() over(order by score) rk
from exam_record
where score is not null
)t1
where rk in (floor(ct/2)+1,if(mod(ct,2)=0,floor(ct/2),floor(ct/2)+1))结果生成:
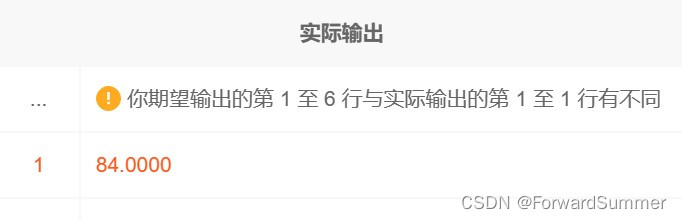
用窗口函数再实际检验一下:
select score,count(*) over() ct,row_number() over(order by score) rk
from exam_record
where score is not null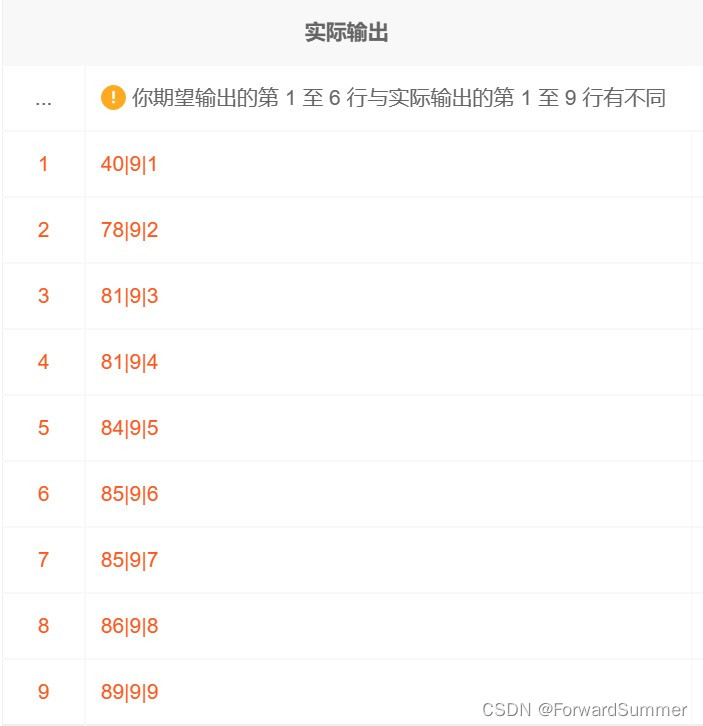
可以看到84确实位于中间那个,那么ct(总数)为偶数的情况,读者可以自行验证。
题目小结
求中位数是个比较经典的题目,利用排序窗口函数进行排序,整体上分奇偶情况,选出需要的一个或者那两个数据进行求平均数就可得出。
4.秋招面试、笔试中 其他关于窗口函数的
(1)某望数码面:说说你对窗口函数的了解
(2)某手机厂商*ppo一面:了解的窗口函数
在面试中,不涉及题目具体解答一般都是问了解的窗口函数,相信看完本篇文章,已经不是了解的程度了吧 ^-^.
参考来源:
【1】bilibili 尚硅谷 康师傅 Mysq8.0
【2】nowcoder 盐咸咸 题解 | #每类试卷得分前3名#
【3】nowcoder 打孩子的酱油
【4】nowcoder nomico271
【5】nowcoder webary 计算用户的平均次日留存率
【6】nowcoder (≧∇≦)三玖 SQL212 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
【7】CSDN IT农民工1 SQL笔面试题:如何求取中位数?

![[附源码]计算机毕业设计Python高校商铺管理系统论文(程序+源码+LW文档)](https://img-blog.csdnimg.cn/1775b28cef8f4e96801aa314c9f592c7.png)