定义
信息提取任务是从一组非结构化自然语言文本中的每个文本中识别有关实体、关系或事件的预定义类的信息,并通过以下任一方式以结构化形式记录此信息:
• 注释源文本,使用 XML 标签
• 填写与文本分开的数据结构,例如模板或数据库记录或对峙注释stand-off annotation
例如:从金融新闻专线报道中识别那些处理管理继任事件的人,并从中提取组织和个人的详细信息,担任或撤职等
然后将生成的结构化数据源用于其他目的:
• 使用常规数据库查询进行搜索或分析
• 数据挖掘;生成摘要(可能用另一种语言)
• 在源文本中/内部/之间构建索引
信息检索 Information Retrieval
信息检索是:给定:文档集合和用户查询 返回:与用户查询相关的(排序的)文档列表
他的优势:
• 可以非常快速地搜索大量文档集合
• 对文本的类型和领域不敏感 实施起来相对简单
• 挑战缩放到巨大的动态文档集合,例如Web
他的弱点
• 返回的文档不是信息/答案,因此
• 用户必须进一步阅读文本以提取信息
• 输出是非结构化的,因此直接数据挖掘/进一步处理的可能性有限 经常不够区分
对比信息提取和信息检索
信息提取是给定:文档集合和一组预定义的实体、关系和/或事件 返回:指定实体、关系和/或事件的所有提及的结构化表示
优势:
• 从文本中提取事实,而不仅仅是从文本中提取文本集合
• 可以为其他强大的应用程序(数据库、语义索引引擎、数据挖掘工具)提供支持
弱点
• 系统往往是特定于流派/领域的,移植到新的流派和领域可能很耗时/需要专业知识
• 准确性有限
• 计算要求高,因此存在性能问题在非常大的集合上
Entity Extraction 实体提取
IE 系统处理的实体类型包括:
Named individuals • 组织、人员、地点、书籍、电影、船舶、餐馆。
Named Kinds • 蛋白质、化合物/药物、疾病、飞机部件。
Times • 时间表达日期、一天中的时间
Measures • 货币表达、距离/大小、重量。
指代同一现实世界实体的不同文本表达被称为 共指 corefer
Coreference Task 共指任务是将所有文本引用链接到同一个现实世界实体,无论表面形式是否是名称
信息提取方法
IE 方法可分为四类:
• 知识工程方法 Knowledge Engineering Approaches
用手动编写的规则进行标记
• 监督学习方法 Supervised Learning Approaches
监督学习系统被赋予带有手动注释实体+关系的文本,为每个实体/关系创建一个训练实例,接着以特征表示的训练实例
算法包括:覆盖算法、HMM、SVM
• 自举方法 Bootstrapping Approaches
一种只需要最少的关系抽取技术。
系统被赋予种子元组 seed tuples(例如 Microsoft, Redmond )或者 种子模式 seed patterns (例如 [X]ORG 位于 [Y]LOC)
系统在大型语料库中搜索出现的种子元组,然后提取与种子元组上下文相匹配的模式,匹配从中获取新元组的种子模式
假定新元组处于所需的关系中,并被添加到元组存储中,反复迭代直至收敛。
• 远程监督方法Distant Supervision Approaches
有时也称为弱标记 weakly labelled 方法
假设一个(半)结构化数据源,它包含处于感兴趣关系中的实体元组,理想情况下是指向源文本的指针
来自数据源的元组用于标记与其相关联的文本,如果没有则用网络上的可用文档
标记数据用于训练一个标准的受监督命名实体或关系提取系统
评估方法
正确答案,称为键 keys,是为每个提取任务(填充模板或 SGML 注释文本)手动生成的
系统结果的评分,称为响应esponses,根据键自动完成。
至少部分答案是由不同的人多次生成的,因此 interannotator agreement figures 注释者间协议数字 可以被计算
主要指标:Precision 精度(系统返回的正确率)Recall 召回率(系统返回正确率的多少)F-measure(精度和召回率的加权组合)
Named Entity Recognition 命名实体识别
命名实体识别 (NER) 是一项核心 IE 技术,目前已相对成熟并处于“可用”性能水平, NER 旨在检测和分类给定文本中给定实体类型集的命名实体的所有提及
Lexical Processing 词法处理
许多基于规则的 NER 系统广泛使用专有名称的专门词典,例如地名词典 gazetteers——地名列表
不用更大地名词典的原因:许多 NE 出现在多个类别中 – 词典越大,歧义越大:
例如 • Ford – 公司 vs Ford – 人 vs Ford – 地方
名称列表永远不会完整,因此需要某种机制来在任何情况下键入看不见的 NE
主要词汇处理步骤:
标记化 Tokenisation、句子拆分 sentence splitting、词法分析 morphological analysis
词性标注 Part-of-speech tagging 将已知的专有名词词和未知的大写首字母词标记为专有名词(NNP、NNPS)
**姓名列表 Name List /地名词典 Gazetter 查找和标记(**组织、地点、人员、公司代号、人员头衔)
触发词标记 Trigger Word Tagging :多词名称中的某些词起触发词的作用,允许对名称进行分类
Named Entity Parsing 命名实体解析
词法处理之后进行命名实体解析
Discourse Interpretation
Coreference Resolution 共指消解
当先行词(照应词)的名称类别已知时,建立共指允许建立照应词(先行词)的名称类别
规则ORGAN NP --> NAMES NP ‘&’’ NAMES NP 的意思是:如果一个未分类的专有名称 (NAMES NP) 后面跟着 '& 和另一个未分类的专有名称,那么它就是一个组织名称。例如。 Marks & Spencer 和American Telephone & Telegraph
语义类型推断
关于某些句法关系中参数的语义类型信息用于进行允许 PN 分类的推断:
名词-名词限定 noun-noun qualification: when an unclassified PN qualifies an organisation-related object then the PN is classified as an organisation
所有格 possessives: when an unclassified PN stands in a possessive relation to an organisation post, then the PN is classified as an organisation
并列 apposition: when an unclassified PN is apposed with a known orgnisation post, the former name is classified as a person name
口头辩论 verbal arguments: when an unclassified PN names an entity playing a role in a verbal frame where the semantic type of the argument position is known, then the name is classified according
知识工程方法:
优势 • 高性能 - 仅落后于人工注释者几分 • 透明 - 易于理解系统在做什么/为什么
劣势 • 移植到另一个领域需要大量的规则重新设计 • 获取领域特定词典 • 编写规则需要高水平的专业知识
监督学习方法:
监督学习方法旨在解决知识工程 NER 中固有的可移植性问题
系统不是手动编写规则,而是从带注释的示例中学习
转移到新领域只需要领域中的注释数据——可以由领域专家提供,而不需要专家计算语言学家
已经尝试了多种监督学习技术,包括:
Hidden Markov models
Decision Trees
Maximum Entropy
Support Vector Machines
Conditional Random Fields
AdaBoost
Deep Learning
Sequence Labelling:
系统可以学习
匹配提取目标分类器的模式
这些分类器将标记标记为标签类型的开始/内部/外部
Most work in recent years has followed the latter approach – called 序列标记
在 NER 的序列标记中,每个标记都被赋予三种标签类型之一 BIO序列标记
BType if the token is at the beginning of a named entity of type = Type (here, e.g., Type ∈ {ORG , PER, LOC }).
IType if the token is inside a named entity of type = Type
O if the token is outside any named entity
给定 BIO 类型编码,每个训练实例(令牌)通常表示为一组特征。
NER 序列标记方法的主要步骤:
收集代表性文献集,人工标注,注释文档, 特征提取和IOB编码,训练数据,训练分类器执行序列标记( HMMs, SVMs, CRFs, MEMMs),获得NER 系统
Entity Linking
IE 的一个重要应用是知识库填充knowlege base population (KBP)——从开放访问 Web 源收集事实并用于构建结构化信息存储库。为了使 KBP 工作,不仅必须检测到实体,而且如果要正确组装事实,还必须将它们链接到 KB 中的适当条目
这导致了实体链接任务:给定一个在该文本中提到 NE 的文本和一个知识库 (KB),例如维基百科,如果有的话,将 NE 链接到 KB 中的匹配条目,否则创建一个条目
至今已经开发了许多方法。
简单方法:给定包含 NE 提到 m 的文本 T 并使用维基百科作为KB,但是这不是很有效
更成功的方法考虑联合消除所有 NE 的歧义
例如:在消除提到 A 和 B 的文本歧义时,提到的 A 很可能在 B,而 B 很可能是包含 A 的地方。e.g., Alhelbawy and Gaizauskas (2014)
Relation Extraction 关系提取
任务:给定文本 T 和一组关系 R,识别 T 中 R 的所有关系断言,在实体提取中识别的实体之间保持。 R中的关系通常是二进制的, R 中关系参数的实体类型被假定为实体提取过程中识别的那些实体类型的子集。
可以分为两个子任务:
关系检测 Relation detection:找到存在关系的实体对
关系分类 Relation classification :对于存在关系的实体对,确定该关系是什么
关系抽取的方法
关系提取旨在检测和分类给定文本中指定实体类型之间的一组给定关系的所有提及。
关系抽取是一项非常困难的核心 IE 技术,因为关系可以用自然语言表达的方式多种多样
知识工程方法
这些系统使用手动编写的规则,可以分为
Shallow浅层——为 IE 任务设计的系统,通常使用模式动作规则

Pattern: $Person, $Position of $Organization
Action: add-relation(is-employed-by( $ Person,$Organization))
deep深层——受语言启发的语言理解系统,通常使用广泛覆盖的 NL 解析器解析输入以识别关键语法关系,如主语和宾语。使用转换规则从解析器输出中提取感兴趣的关系。解析器输出的提取规则允许捕获比单独使用正则表达式的单词和 NE 标记更广泛的表达式集。
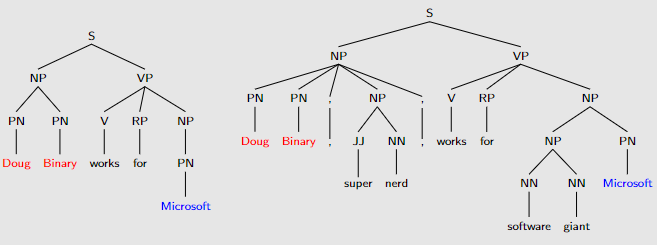
示例显示了多个表面形式如何共享底层句法结构:这里都有形式 主语= PER,宾语 = ORG 和动词 = works for
优点 :高精度 ,系统行为是人类可以理解的
缺点 :规则的编写没有止境 ,每个新领域都需要新规则(浅层方法的模式动作规则;深层方法的转换规则)
监督学习方法
与 NER 一样,可分为检测和分类阶段:
分类器 1(二元)确定给定句子是否表达了一组感兴趣的关系(关系检测)
分类器 2(多路)确定分类器 1 的正输出, 哪个关系成立(关系分类)
训练二元分类器,当应用于包含关系成立的实体类型实例的句子时,如果关系在此实例中成立,则返回 1, 如果关系在此实例中不成立,则返回 0
优点:无需为每个领域编写广泛/复杂的规则集 ,如果提供训练数据,同一系统可以直接适应任何新领域 。
缺点:关系提取的质量取决于训练数据的质量和数量,这可能很困难,也很耗时消耗生成。并且开发特征提取器可能很困难,而且可能有噪音(例如解析器),从而降低整体性能
Bootstrapping approaches
减少构建系统所需的手动标记示例的数量
关键思想:从文档集合 D 开始,有一组可信元组 T(例如,已知存在于相关关系中的实体对) 或者有一组可信模式 P(即,已知可提取给定实体对的模式与高精度的关系)
then find tuples from T in sentences S in D, extract patterns from context of sentences in S, add patterns to P and then use P to find new tuples in D and add to T; repeat until convergence
或者
then match patterns from P in sentences S in D, extract tuples from pattern matches in sentences in S, add tuples to T and then use tuples in T to find new patterns in D and add to P; repeat until convergence
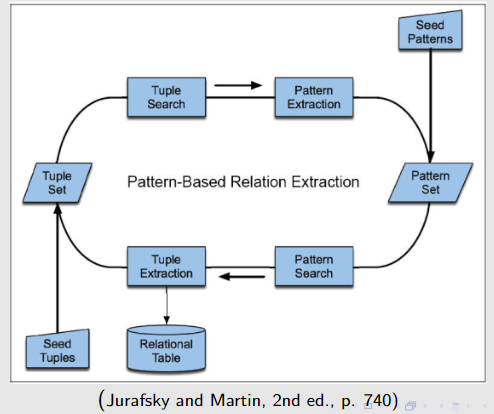
优势:消除了对手动标记训练数据的需求
弱点:可能遭受语义漂移semantic drift ——当错误的模式引入错误的元组,而错误的元组又导致错误的模式时 。
为模式和元组引入置信度度量可以在一定程度上缓解这个问题,当特定元组的断言和使用特定模式来表达关系时存在大量冗余时效果很好。同一对实体之间存在多个关系时容易出问题。
远程监督方法
与bootstrapping方法一样,远程监督方法旨在减少/消除对手动标记训练数据的需求
假设我们有一个大型文档集合 D 加上一个结构化数据源(例如数据库)R,其中包含感兴趣关系的许多实例,例如关系表。然后我们可以在 D 中搜索包含出现在 R 中的关系实例(元组)中的实体对的句子,将这些句子标记为关系实例的positive occurrence 。使用标记的句子作为训练数据来训练标准的监督关系提取器。
远程监督假设:如果两个实体参与关系,则包含这两个实体的任何句子都可能表达该关系,同一个关系在不同的句子中可能有不同的表达方式,所以还需要负实例。
优势:消除了对手动标记训练数据的需求,可以非常快速地获得广泛关系的提取器
劣势:精度仍然落后于最好的知识工程/直接监督学习方法,只有在结构化数据的良好供应可用于利益关系