1. 几款数据库特性及如何选型
1.MySQL:一种常用的开源关系型数据库管理系统,可以快速访问大量数据,并支持多用户同时访问。其最大的优点在于成本低,易于安装和配置,因此被广泛应用于各种中小型企业和网站。支持读写分离、分库分表、事务、索引。
适用场景:Web网站系统、日志记录系统、数据仓库系统、嵌入式系统
2.Oracle:全球最大的商业数据库软件公司之一,提供各种可扩展的解决方案,适用于从小型应用到大型企业级应用。它具有很高的可靠性、安全性和性能优化能力,但价格较高。
3.SQL Server:微软推出的关系型数据库管理系统,具有高可用性和可扩展性,并集成了很多BI和分析工具。适用于大型企业和中小型企业。
4.MongoDB:一种NoSQL数据库,非常适合处理大量非结构化数据。具有高可扩展性、高性能和易于部署的优点,被广泛应用于互联网领域。MongoDB最大的特点是表结构灵活可变,字段类型可以随时修改,MongoDB不需要定义表结构这个特点给表结构的修改带来了极大的方便,但是也给多表查询、复杂事务等高级操作带来了阻碍。
使用场景:MongoDB很适合那些表结构经常改变,数据的逻辑结构没又没那么复杂不需要多表查询操作,数据量又比较大的应用场景。例如游戏中存储用户信息。
5.Redis:一种开源的NoSQL数据库,以其高速读写性能和卓越的可靠性而闻名。适用于实时数据处理和高速缓存。
6.PostgreSQL:一种开源的关系型数据库管理系统,具有丰富的功能和高度可靠性,被广泛应用于大型企业级应用。
7.Cassandra:一个开源分布式NoSQL数据库系统,被广泛应用于分布式环境中的大数据应用,具有高度可扩展性和高度可用性。
8.Amazon Redshift:AWS提供的云数据仓库,适用于大规模数据分析。具有高度可扩展性和高度可用性,并支持广泛的数据集成。
9.HBase:HBase继承了Hadoop项目的最大优点,那就是对海量数据的支持,以及极强的横向(存储容量)扩展能力。
使用场景:用于解决大数据场景的海量存储问题。HBase的列式存储特点带来了对海量数据的容纳能力,因此非常适合数据量极大,查询条件简单,列与列之间联系不大的轻查询应用场景。最典型的比如搜索引擎所使用的网页数据库。HBase不适合数据结构复杂,且需要复杂查询的应用场景
10.ES:ES的特点,正如其名,那就是搜索。严格的说,ES不是一个数据库,而是一个搜索引擎,ES的方方面面也都是围绕搜索设计的。 ES支持全文搜索。ES也有很多的短处,最明显的就是字段类型无法修改、写入性能较低延迟高和高硬件资源消耗。ES的全文搜索特性使它成为构建搜索引擎的利器。除此之外,ES很好的支持了复杂聚合查询这一特点还使得ES非常适合拿来作数据分析使用,配套ELK,可以提供从日志收集到数据可视化分析的一条龙服务。
总结:
- 如果你是一家中小型企业,需要存放各种关系型数据,会有频繁的增删改查和聚合查询,需要事务的支持,那么首选MySql。
- 如果你对数据的读写要求极高,并且你的数据规模不大,也不需要长期存储,选redis;
- 如果你的数据规模较大,对数据的读性能要求很高,数据表的结构需要经常变,有时 还需要做一些聚合查询,选MongoDB;
- 如果你需要构造一个搜索引擎或者你想搞一个看着高大上的数据可视化平台,并且你的数据有一定的分析价值或者你的老板是土豪,选ElasticSearch;
- 如果你需要存储海量数据,连你自己都不知道你的数据规模将来会增长多么大,那么选HBase。
参考:大数据时代MongoDB、ES、Redis、HBase这四种数据库你应该懂
2. 几款缓存特性及如何选型
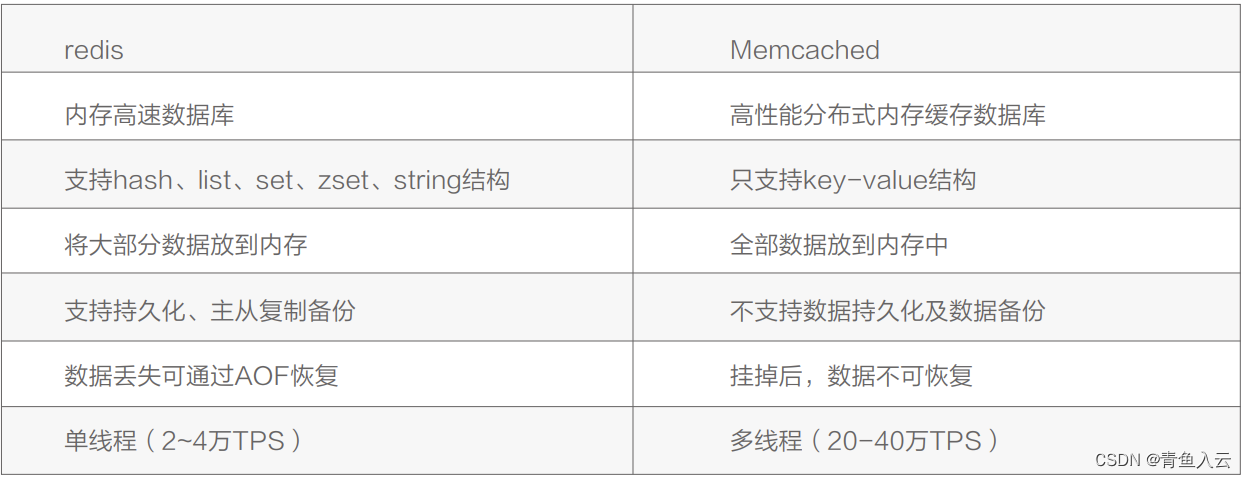
redis支持5种数据类型,支持持久化,支持m/s数据备份等。
memcache内容放在内存中,只支持简单k/v数据。
使用场景:
- 如果有持久方面的需求或对数据类型和处理有要求的应该选择redis。
- 如果简单的key/value 存储应该选择memcached。
3. 几款消息中间件特性及如何选型
消息队列的选型主要侧重以下几点:
HA:自身的高可用性保障,避免消息队列的引入而影响整体服务的可用性
高吞吐:在面对海量数据写入能否保持一个相对稳定、高效的数据处理能力
功能丰富性:是否支持延迟消息、事务消息、死信队列、优先级队列等
消息广播:是否支持将消息广播给消费者组或者一组消费者
消息堆积能力:在数据量过大时,是否允许一定消息堆积到broker
数据持久性:数据持久化策略的采用,也决定着数据在宕机恢复后是否会丢失数据
重复消费:是否支持ack机制,在消费者未正确处理消息时,支持重新消费
消息顺序性:针对顺序消费的场景保证数据按写入时间的顺序性
(一)Kafka
优点:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
- 可扩展性:kafka集群支持热扩展;
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
- 容错性:允许集群中节点故障,一个数据多个副本,少数机器宕机,不会丢失数据;
- 高并发:支持数千个客户端同时读写。
缺点:
- 分区有序:仅在同一分区内保证有序,无法实现全局有序;
- 无延时消息:消费顺序是按照写入时的顺序,不支持延时消
- 重复消费:消费系统宕机、重启导致offset未提交;
- Rebalance:Rebalance的过程中consumer group下的所有消费者实例都会停止工作,等待Rebalance过程完成。
使用场景:
- 日志收集:大量的日志消息先写入kafka,数据服务通过消费kafka消息将数据落地。
- 消息系统:解耦生产者和消费者、缓存消息等。
- 用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到数据库。
- 运营指标:记录运营、监控数据,包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming。
(二)RabbitMQ
优点:
- 基于AMQP协议:除了Qpid,RabbitMQ是唯一一个实现了AMQP标准的消息服务器。
- 健壮、稳定、易用。
- 社区活跃,文档完善。
- 支持定时消息。
- 可插入的身份验证,授权,支持TLS和LDAP。
- 支持根据消息标识查询消息,也支持根据消息内容查询消息。
缺点:
- erlang开发源码难懂,不利于做二次开发和维护。
- 接口和协议复杂,学习和维护成本较高。
使用场景:
- erlang有并发优势,性能较好。虽然源码复杂,但是社区活跃度高,可以解决开发中遇到的问题。
- 业务流量不大的话可以选择功能比较完备的RabbitMQ。
(三)RocketMQ
优点:
- 支持发布/订阅(Pub/Sub)和点对点(P2P)消息模型。
- 顺序队列:在一个队列中可靠的先进先出(FIFO)和严格的顺序传递。
- 支持拉(pull)和推(push)两种消息模式。
- 单一队列百万消息的堆积能力。
- 支持多种消息协议,如JMS、MQTT等。
- 分布式横向扩展架构
- 满足至少一次消息传递语义。
- 提供丰富的Dashboard,包含配置、指标和监控等。
- 支持的客户端,目前是java、c++及golang。
缺点:
- 社区活跃度一般。
- 延时消息:开源版不支持任意时间精度,仅支持特定的level。
使用场景:
- 为金融互联网领域而生,对于可靠性要求很高的场景。
(四)Pulsar
Apache Pulsar是Apache软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性,被看作是云原生时代实时消息流传输、存储和计算最佳解决方案。Pulsar是一个pub-sub (发布-订阅)模型的消息队列系统。
优点:
- 灵活扩容。
- 无缝故障恢复。
- 支持延时消息。
- 内置的复制功能,用于跨地域复制,如灾备。
- 支持两种消费模型:流(独享模式)、队列(共享模式)。
参考:带你玩转消息队列和相关选型!
4. 几款注册中心特性及如何选型