目录
前言
链式栈
操作方式
1.存储结构
2.初始化
3.创建节点
4.判断是否满栈
5.判断是否空栈
6.入栈
7.出栈
8.获取栈顶元素
9.遍历栈
10.清空栈
完整代码
前言
前面我们学习过了数组栈的相关方法,(链接:线性表-----栈(栈的初始化、建立、入栈、出栈、遍历、清空等操作)_灰勒塔德的博客-CSDN博客)那么今天我们就开始学习新的结构栈---链式栈,顾名思义就是通过链表的结构来实现栈的相关方法操作,包括创建、判断空满、出栈、入栈、遍历和清空等操作,下面就一起来看看吧!

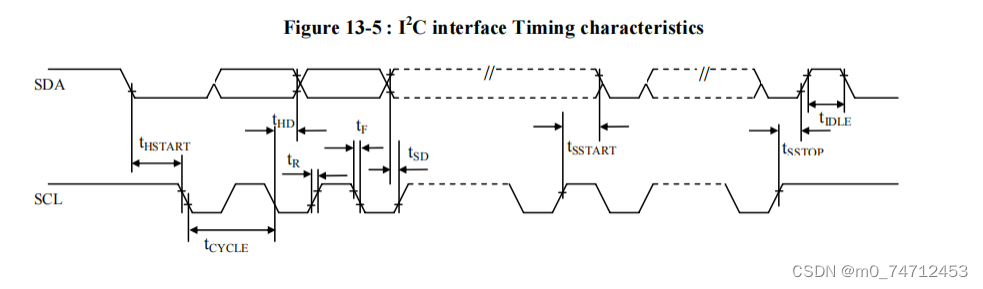
链式栈
图示如下:

操作方式
#include<stdio.h>
#include<stdlib.h>
#define Maxsize 20 //设置最大节点数量
create_node(ElemType data);//创建节点
stack_init(Stack* top);//初始化
isFull(Stack* top);//判断是否满栈
isEmpty(Stack* top);//判断是否空栈
push(Stack* top, ElemType data);//入栈
pop(Stack* top);//入栈
get_stacktop(Stack* top);//获取栈顶元素
show_stack(Stack* top);//遍历栈
clear_stack(Stack* top);//清空栈
1.存储结构
今天实现的是栈的链式储存,也就是俗称“链栈”。由于之前实现过单链表,对于栈的链式存储,二者原理是一样的,只不过在操作上链栈是受限的——仅能在栈顶进行插入和删除!话不多说,先看链栈的存储结构
//数据类型
typedef struct datatype {
int age;
char name[10];
int num;
}ElemType;
//节点
typedef struct node {
ElemType data;
struct node* next;
}Node;
//栈顶指示
typedef struct stack {
int count; //计数
Node* point;
}Stack;2.初始化
初始化就让头指针指向的位置为NULL,节点计数为0
//初始化
void stack_init(Stack* top) {
top->count = 0;
top->point = NULL;
}3.创建节点
创建节点就通过链表的方式去创建节点,然后把数据值赋予给这个节点
//创建节点
Node* create_node(ElemType data) {
Node* new_node = (Node*)malloc(sizeof(Node));
if (new_node) {
new_node->data = data;
new_node->next = NULL;
return new_node;
}
else
{
printf("ERROR\n");
}
}4.判断是否满栈
判断是否满栈只需要看此时计数是否达到最大容量节点数量即可
//判断是否满
int isFull(Stack* top) {
if (top->count > Maxsize) {
printf("The stack is full\n");
return 1;
}
return 0;
}5.判断是否空栈
这时候只需要看计数是否为0就行了
//判断是否为空
int isEmpty(Stack* top) {
if (top->count == 0) {
printf("The stack is empty\n");
return 1;
}
return 0;
}6.入栈
进行入栈的操作类似于链表的成链操作,也就是说把创建好的节点连起来即可,不同的是此时每放入一个节点的时候,栈顶指针top要往栈顶依次往上移动,计数也要+1,代码如下所示:
//入栈
void push(Stack* top, ElemType data) {
Node* new_node = create_node(data);
if (new_node&&!isFull(top)) {
top->count++;
if (top->count == 1) {//如果入栈是第一个节点的话
top->point = new_node;
}
else
{
//以下两个步骤不能调过来!
new_node->next = top->point;
top->point = new_node;
}
}
else
return;
}7.出栈
出栈时,先获取到此时栈顶指针指向的位置pop_node,再把栈顶指针向下移动一位,计数减一,然后返回这个元素pop_node即可:
//出栈
Node* pop(Stack* top) {
Node* pop_node=NULL;
if (!isEmpty(top)) {
pop_node = top->point;
top->point = pop_node->next;
pop_node->next = NULL;
top->count--;
}
return pop_node;
}8.获取栈顶元素
获取栈顶元素不需要出栈,只需要返回栈顶元素即可:
//获取栈顶元素
Node* get_stacktop(Stack* top) {
return top->point;
}9.遍历栈
遍历栈,从栈顶开始,依次往下遍历输出数据即可:
//遍历栈
void show_stack(Stack* top) {
Node* cur = top->point;
while (cur) {
printf("%d %s %d\n", cur->data.age, cur->data.name, cur->data.num);
cur = cur->next;
}
printf("Print over!\n");
}10.清空栈
清空栈,就要去依次把每一个节点的空间给释放掉,然后栈顶往下移动,直到移动到最初始的位置。
//清空栈
void clear_stack(Stack* top) {
Node* cur;
while (top->point) {
cur = top->point;
top->point = cur->next;
free(cur);
}
printf("Clear successfully!\n");
}完整代码
#include<stdio.h>
#include<stdlib.h>
#define Maxsize 20 //设置最大节点数量
//链表栈
//数据类型
typedef struct datatype {
int age;
char name[10];
int num;
}ElemType;
//节点
typedef struct node {
ElemType data;
struct node* next;
}Node;
//栈顶指示
typedef struct stack {
int count; //计数
Node* point;
}Stack;
//创建节点
Node* create_node(ElemType data) {
Node* new_node = (Node*)malloc(sizeof(Node));
if (new_node) {
new_node->data = data;
new_node->next = NULL;
return new_node;
}
else
{
printf("ERROR\n");
}
}
//初始化
void stack_init(Stack* top) {
top->count = 0;
top->point = NULL;
}
//判断是否满
int isFull(Stack* top) {
if (top->count > Maxsize) {
printf("The stack is full\n");
return 1;
}
return 0;
}
//判断是否为空
int isEmpty(Stack* top) {
if (top->count == 0) {
printf("The stack is empty\n");
return 1;
}
return 0;
}
//入栈
void push(Stack* top, ElemType data) {
Node* new_node = create_node(data);
if (new_node&&!isFull(top)) {
top->count++;
if (top->count == 1) {//如果入栈是第一个节点的话
top->point = new_node;
}
else
{
new_node->next = top->point;
top->point = new_node;
}
}
else
return;
}
//出栈
Node* pop(Stack* top) {
Node* pop_node=NULL;
if (!isEmpty(top)) {
pop_node = top->point;
top->point = pop_node->next;
pop_node->next = NULL;
top->count--;
}
return pop_node;
}
//获取栈顶元素
Node* get_stacktop(Stack* top) {
return top->point;
}
//遍历栈
void show_stack(Stack* top) {
Node* cur = top->point;
while (cur) {
printf("%d %s %d\n", cur->data.age, cur->data.name, cur->data.num);
cur = cur->next;
}
printf("Print over!\n");
}
//清空栈
void clear_stack(Stack* top) {
Node* cur;
while (top->point) {
cur = top->point;
top->point = cur->next;
free(cur);
}
printf("Clear successfully!\n");
}
int main() {
Stack top;
stack_init(&top);//初始化
ElemType data[4] = { {15,"Jack",01},{16,"Leimu",02},{17,"Lamu",03},{18,"Ajx",04} };
for (int i = 0; i < 4; i++) {
push(&top, data[i]);//入栈操作
}
show_stack(&top);//遍历栈
Node* out_data=pop(&top);//出栈操作
printf("%d %s %d\n", out_data->data.age, out_data->data.name, out_data->data.num);
clear_stack(&top);//清空栈
}

以上就是本期的内容,喜欢的给个关注吧!我们下一次再见!