编写这个笔记,希望能记录下学习TiDB时候的知识点。
目录
第一章
1.事务
1.1 SQL-92标准:
1.2 事务的隔离级别
2.在TiDB学习 SQL 语句
第二章
第三章
第一章
1.事务
事务的特性(ACID)
atomicity原子性、consistency一致性、isolation隔离性、durability持久性
1.1 SQL-92标准:
Dirty read脏读、Nonrepeatable read不可重复读、Phantom read幻读
| Dirty read脏读 | Nonrepeatable read不可重复读 | Phantom read幻读 |
|---|---|---|
| 即A读B的未提交/uncommit的数据。 | A读到B的已提交/commit的数据。导致A第一次和第二次读的内容不一致。 | 与不可重复读的区别在于“更新” |
| 脏读:读到其他事务还没有提交的数据。 | 不可重复读:对某数据进行读取,发现两次读取的结果不同,也就是说没有读到相同的内容。这是因为有其他事务对这个数据同时进行了修改或删除。 | 幻读:事务A根据条件查询得到N条数据,但此时事务B更改或者增加M条符合事务A查询条件的数据,这样当事务A再次进行查询的时候发现会有N+M条数据,产生了幻读。 |
1.2 事务的隔离级别
事务的隔离级别
SQL-92标准的四种级别:读未提交、读已提交、可重复读、可串行化
| 隔离级别 | 解释 |
|---|---|
| 读未提交 | 允许读到未提交的数据,这种情况下查询是不会使用锁的,可能会产生脏读、不可重复读、幻读等情况 |
| 读已提交 | 只能读到已经提交的内容,可以避免脏读,属于 RDBMS 中常见的默认隔离级别(比如说 Oracle 和 SQL Server),但如果想要避免不可重复读或者幻读,就需要我们在 SQL 查询的时候编写带加锁的 SQL 语句(我会在进阶篇里讲加锁)。 |
| 可重复读 | 保证一个事务在相同查询条件下两次查询得到的数据结果是一致的,可以避免脏读和不可重复读,但无法避免幻读。MySQL 默认的隔离级别就是可重复读。 |
| 可串行化 | 将事务进行串行化,也就是在一个队列中按照顺序执行,可串行化是最高级别的隔离等级,可以解决事务读 |
2.在TiDB学习 SQL 语句
官网的课程是【在 TiDB 上学习 SQL 语句 [TiDB v6.x](201.2)】
| 目的 | 命令 |
|---|---|
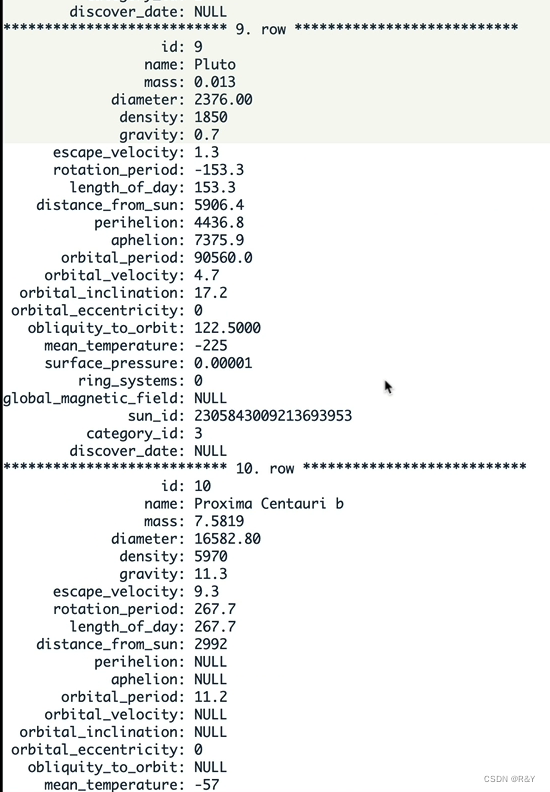
| 查看表的结构 | DESC <schema_name>.<table_name> |
| select的基本用法 | clause 分句 从句
|
| 投射-无过滤查询 | select col1,distinct col2 from table
|
| 过滤-使用where |
|
| 排序 |
select name,ring_systems from table order by 2;表示根据列号,即第二列ring_system升序排列。 |
| 控制查询返回的记录数 |
分页
limit 0,3 从第0行开始取3行。
可见分页挺好用,但效率不高。还是要全表取9行,再拿第9行。 |
| Like的转义字符 |
escape '#' 就是让 # 成为了转义符号
|











2.N 小技巧
| 目的 | |
|---|---|
| 小技巧 |
(1) \G 的效果
(4)paper less -S |
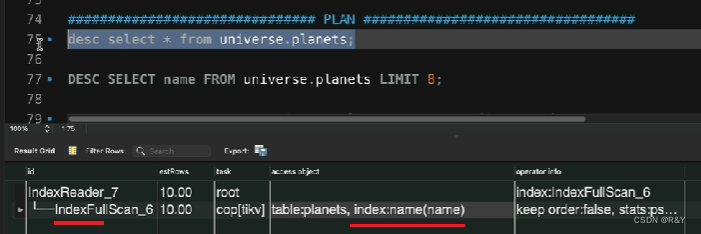
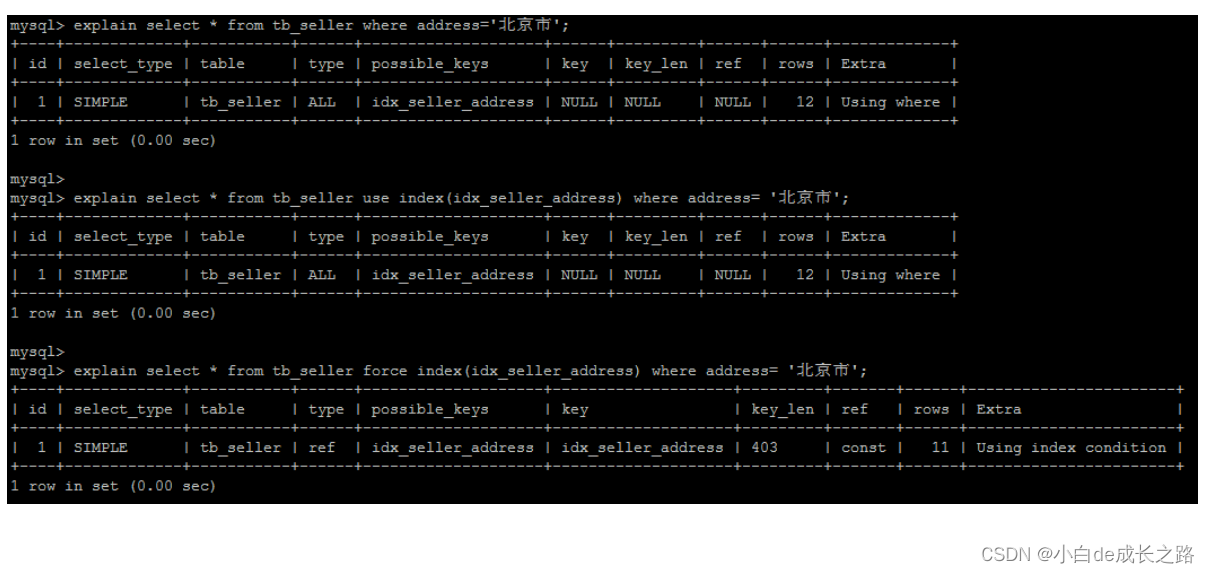
| 查看执行计划 | 口诀:从上往下,靠右先执行。 desc 不会真正执行。
|
| keyset seeker 优化分页 |
...就是索引。 就是先创建索引,然后order by 索引字段,然后自己找到分页后关键点的值,通过where 大于小于找到,写在where 中 题外话:索引不是寄生在表上,而是拷贝出来单独存储。就是用空间换时间。查索引小表再找大表。
如下就是解决分页消耗大的办法。
|