MySQL使用C语言链接
- MySQL connect
- 接口介绍
- mysql_init
- mysql_real_connect
- mysql_query
- mysql_store_result\mysql_use_result()
- mysql_num_rows
- mysql_num_fields
- mysql_fetch_fields
- mysql_fetch_row
- mysql_close
MySQL connect
使用C语言来连接数据库,本质上就是利用一些函数接口来操作数据库,而这些函数接口是由MySQL官方为我们提供的,如果我们想要使用这些接口,我们需要去官方手动下载动态库或者静态库,然后将头文件和动态库或静态库添加到系统默认搜索路劲下或环境变量里面;
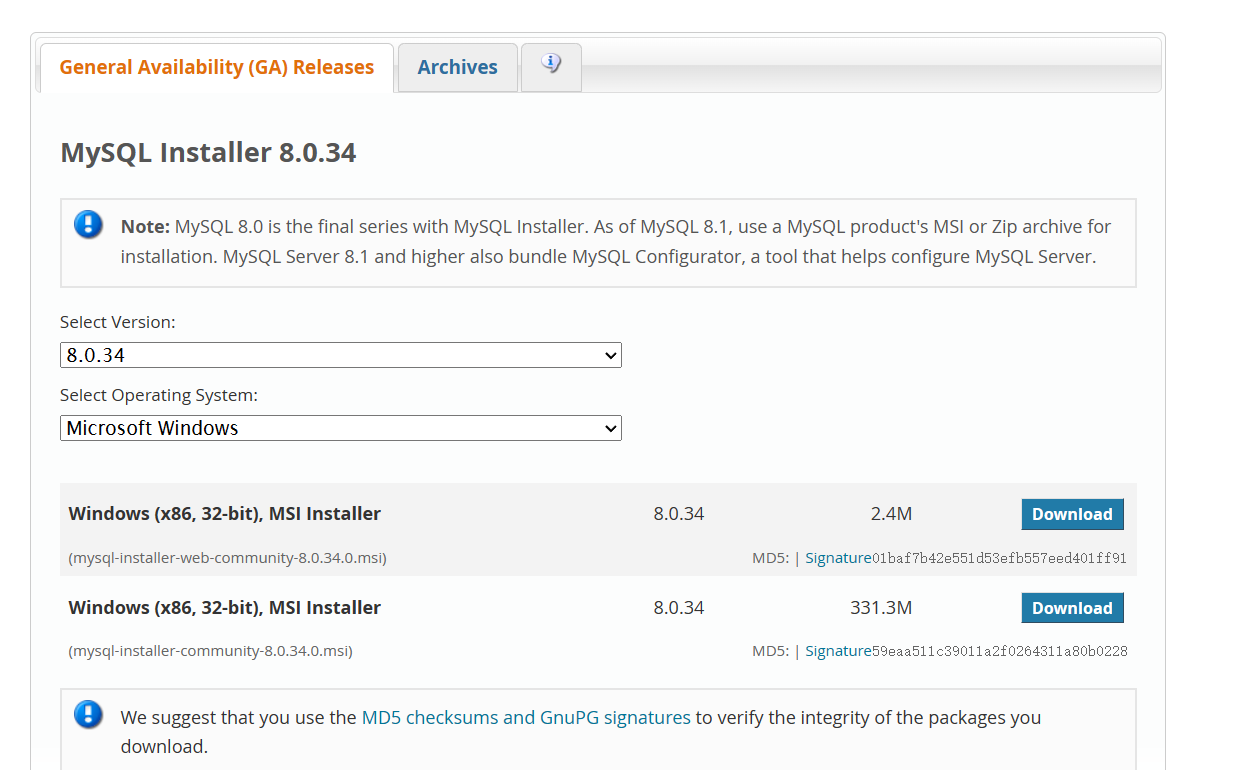
https://dev.mysql.com/downloads/installer/
在以上连接中,我们可以下载对应版本的MySQL库;
如果是在Linux服务器上使用yum安装的MySQL服务,那么在安装的时候会默认将MySQL库资源安装好,我们直接使用就好了:
但是这种情况下,我们可能会在/usr/include/目录下找不到mysql的头文件,只在/usr/lib64/mysql/目录下找到了mysql的库,我们只需要执行一下sudo yum install -y mysql-community-devel.x86_64 就可以了;
接口介绍
对于MySQL的各种接口,官方也给我们提供了文档来查看,我们可以去官网进行查询;
mysql_init
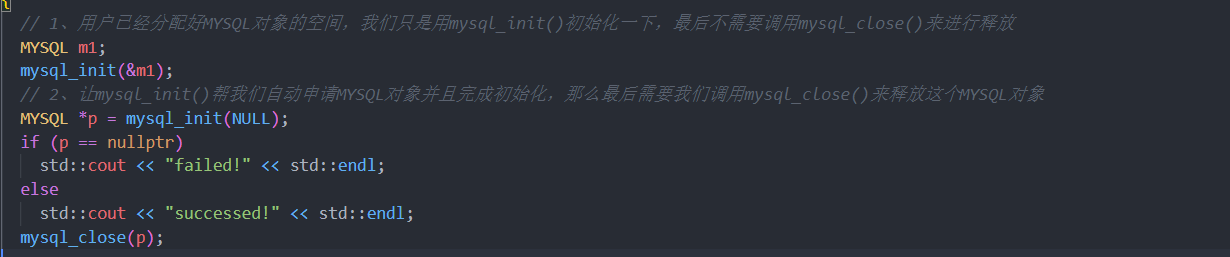
MYSQL *mysql_init(MYSQL *mysql)
描述:
分配或初始化与mysql_real_connect()相适应的MYSQL对象。如果mysql是NULL指针,该函数将分配、初始化、并返回新对象。否则,将初始化对象,并返回对象的地址。如果mysql_init()分配了新的对象,当调用mysql_close()来关闭连接时。将释放该对象。一个MYSQL对象代表一个连接;
返回值:
如果mysql参数为null,那么当返回值为null的时候表示mysql_init()出错,否则mysql_init()成功;
eg:
mysql_real_connect
MYSQL *mysql_real_connect(MYSQL *mysql, const char *host, const char *user, const char *passwd, const char *db, unsigned int port, const char *unix_socket, unsigned long client_flag)
描述:
mysql_real_connect()尝试与运行在主机上的MySQL数据库引擎建立连接。在你能够执行需要有效MySQL连接句柄结构的任何其他API函数之前,mysql_real_connect()必须成功完成。
简而言之就是用来链接数据库的!
mysql:就是之前我们使用mysql_init()初始化的MYSQL对象;
host:MySQL服务器所在主机ip;
user:以哪个用户的身份进行登录;
passwd:登录用户的密码;
db:要链接那个数据库;
port:服务器所在端口号;
unix_socket: 不太关心,常设null;
clientflag: 通常设置为:CLIENT_MULTI_STATEMENTS
返回值:
如果连接成功,返回MYSQL*连接句柄。如果连接失败,返回NULL。对于成功的连接,返回值与第1个参数的值相同。
eg:


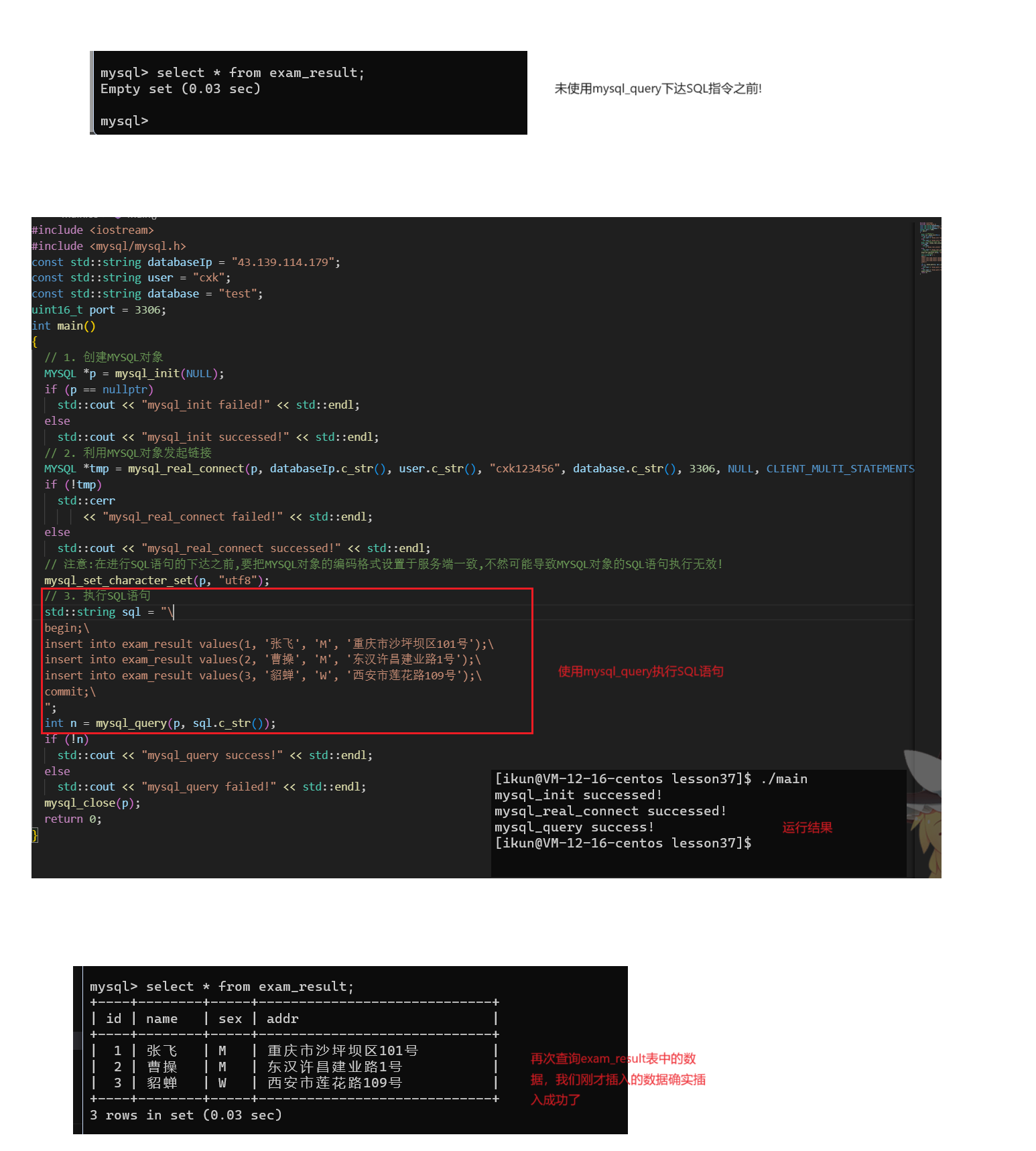
mysql_query
int mysql_query(MYSQL *mysql, const char *q)
描述:
正常情况下,字符串必须包含1条SQL语句,而且不用为语句添加终结分号(‘;’)或“\g”,当然你非要添加也是没有问题的。如果允许多语句执行,字符串可包含多条由分号隔开的语句;
mysql_query:默认情况下是只允许包含一条SQL语句的,如果想要mysql_query支持包含多条SQL语句,那么我们们在使用对应MYSQL对象建立连接时,需要使用mysql_real_connect函数将clientflag参数设置为:CLIENT_MULTI_STATEMENTS
返回值:
如果查询成功,返回0。如果出现错误,返回非0值。
eg:
注意在使用mysql_query下达SQL语句的时候,需要使用mysql_set_character_set(MYSQL *mysql, char *csname)接口来将我们当前连接的编码格式设置与服务端一致,不然可能会导致后续我们使用mysql_query下达SQL语句,但是数据库却没有反应的情况,或者我们客户端输入的是正常的数据到服务端显示出来的就是乱码;
eg:
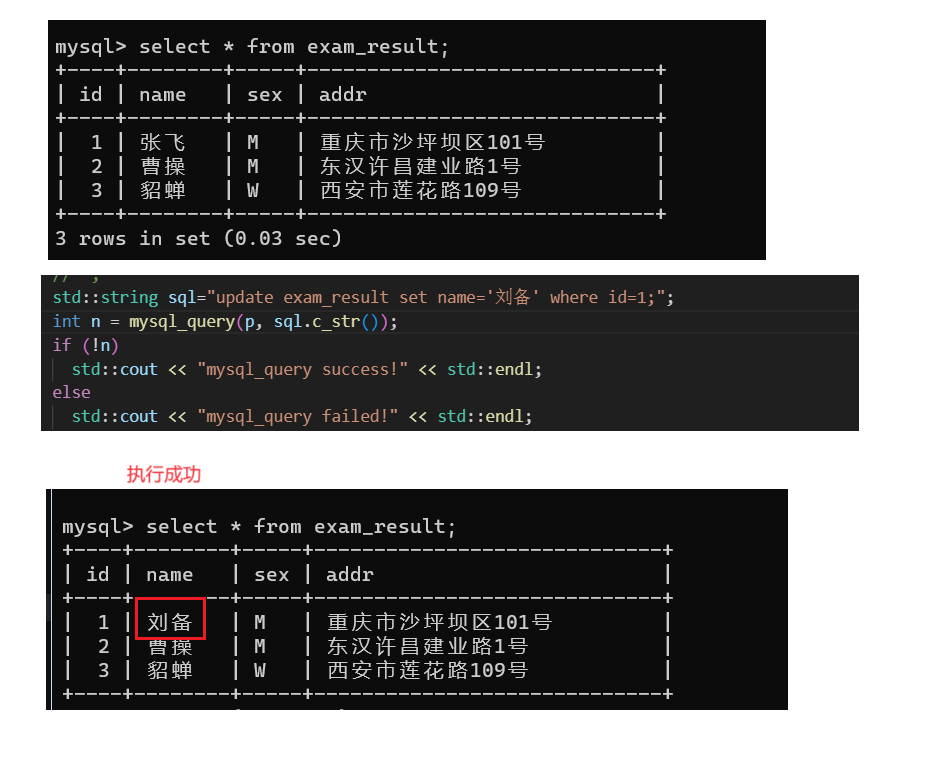
同理:我们也可以下达update语句,比如,我们想要修改id=1的数据的名字:
同理,我们也可以删除id=2的人:
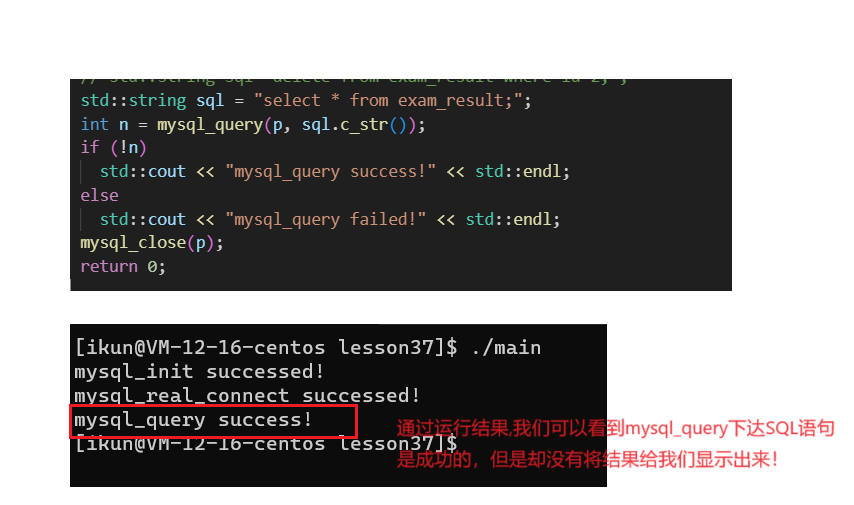
现在增、改、查都演示了一遍,那么读呢?
读还不简单,直接向mysql_query下达select语句不就完了?
我们不是成功执行了select语句吗,那么为什么最后的结果没有给我们显示出来?
实际上,mysqld确实是帮我们成功执行了查询语句,但是最后的查询结果是还保存在mysqld服务器缓冲区中的,如果我们用户需要打印查询成功过后的数据的话,需要我们自己从服务器中获取结果集,然后自己打印;
而从服务器获取查询结果的接口有:
mysql_use_result()、mysql_store_result;

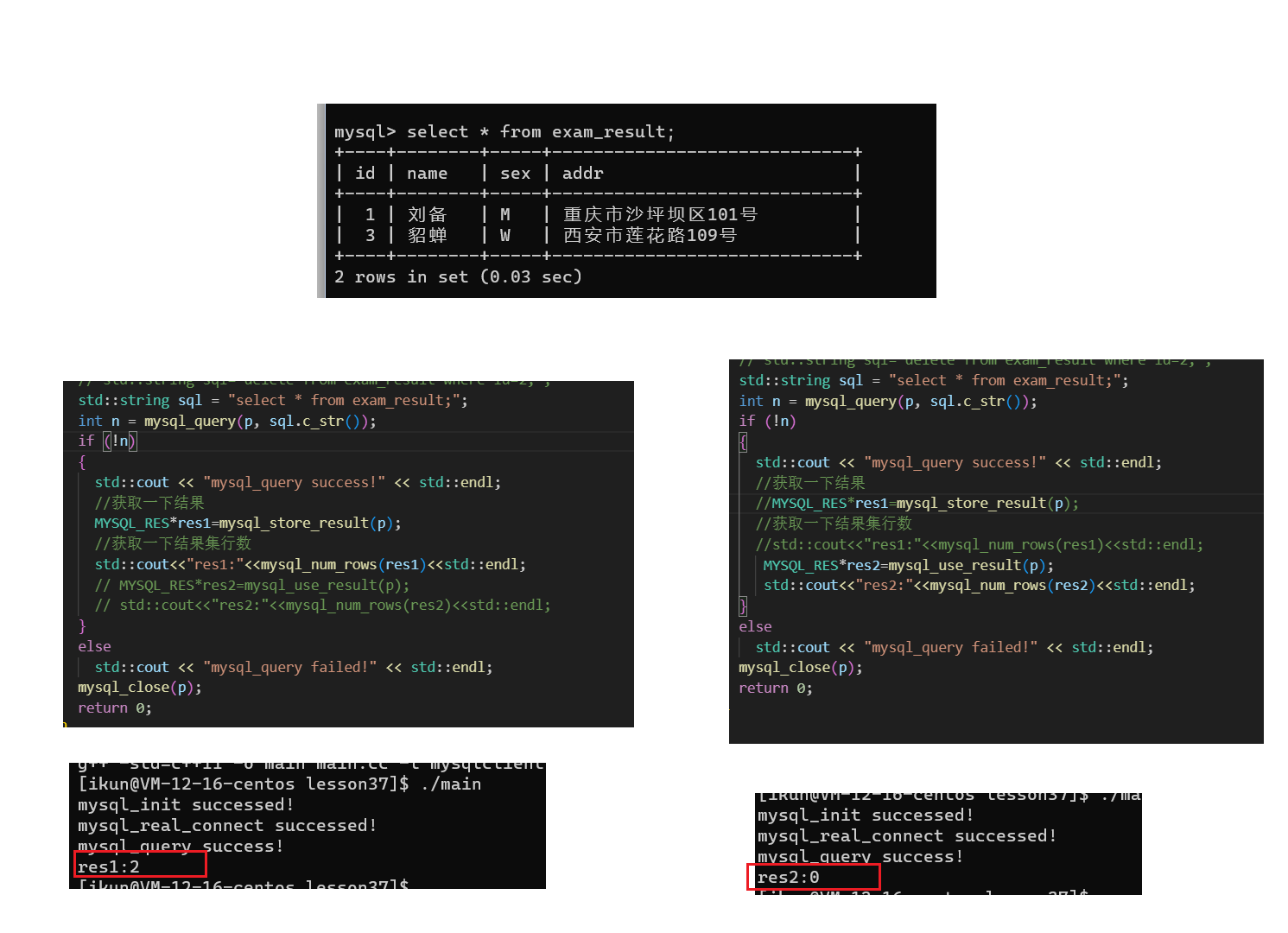
mysql_store_result\mysql_use_result()
MYSQL_RES *mysql_store_result(MYSQL *mysql)
MYSQL_RES *mysql_use_result(MYSQL *mysql)
描述:
mysql_store_result:该接口是从服务器缓冲区中一次性将查询结果读取到用户内存中;适合查询结果比较小的结果集,对于过大的查询结果集,不建议使用,有可能因为内存不足而导致获取失败!通常配合mysql_fetch_row接口使用,该接口会自动从内存中获取下一行数据;
mysql_use_result: 这个函数会初始化结果集的检索,但是并不会立即从服务器读取所有的结果,然后,每次调用mysql_fetch_row()函数时,它都会从服务器读取下一行的数据
mysql_store_result与mysql_use_result的区别:
- mysql_store_result适合结果集比较小的查询,而mysql_use_result更适合结果集比较大的查询;
- 使用mysql_store_result获取的查询结果集,在以后使用上效率是肯定会更快一些的,因为之后的查询都是在内存中进行的,我们只用一次IO就将数据全部读取到内存中了;而反观mysql_use_result在之后的使用上效率肯定会比较低一点,因为对于使用mysql_use_result获取的结果集,我们在想要查询下一行数据时,还需要先从网络中进行获取,然后才能进行读取,IO次数相比于mysql_store_result获取的结果集增多了;
- mysql_store_result获取的结果集是支持随机查询的,而mysql_use_result获取的查询结果集是只能按照顺序查询;
- mysql_store_result获取的结果集所占内存是比较大的,但是mysql_use_result获取的结果集内存消耗是比较少的;
- 无论是mysql_store_result还是mysql_use_result都是从服务器缓存中获取查询结果,具体使用那个接口,根据具体业务场景而定;
在我们执行完查询语句过后,我们应该使用mysql_store_result或者mysql_use_result来获取查询结果,必然这些查询结果会一置消耗着服务器的缓存资源,增加服务器开销!
返回值:
返回null,表示出错;
eg:
注意: 我们需要自己手动释放MYSQL_RES类型的指针,因为该结果集是mysql_use_result\mysql_store_result函数内部mallc出来的,为此我们每次使用完结果集都需要手动调一下:mysql_free_result比如上图中就是mysql_free_result(res1)(上图中我忘了free了这里手动free一下😘)
mysql_num_rows
my_ulonglong mysql_num_rows(MYSQL_RES *result)
描述:
获取结果集的行数;
返回值:
返回获取到的行数;
mysql_num_fields
unsigned int mysql_num_fields(MYSQL_RES *result)
描述:
获取结果集的列数;
返回值:
返回获取到的列数;
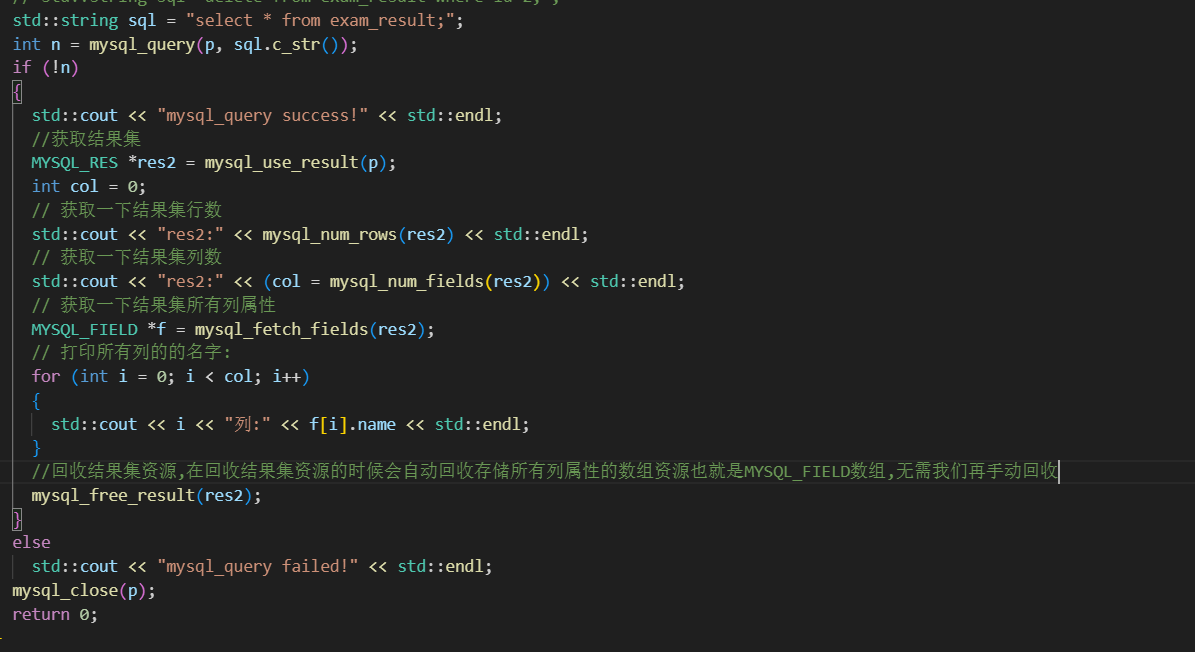
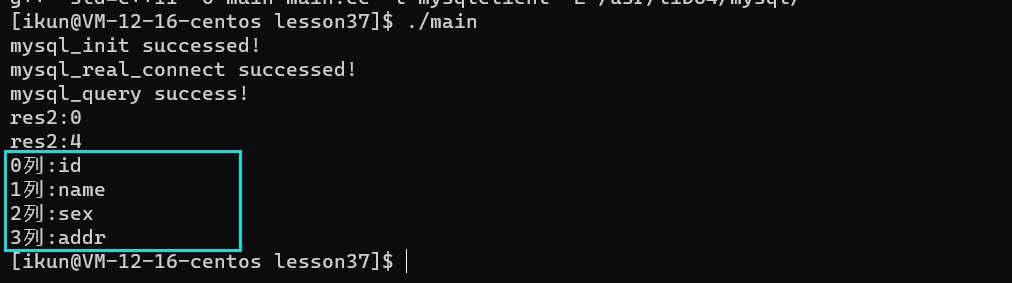
mysql_fetch_fields
MYSQL_FIELD *mysql_fetch_fields(MYSQL_RES *result)
描述:
获取结果集的所有列的属性;
返回值:
返回关于结果集所有列的MYSQL_FIELD类型数组;
eg:
mysql_fetch_row
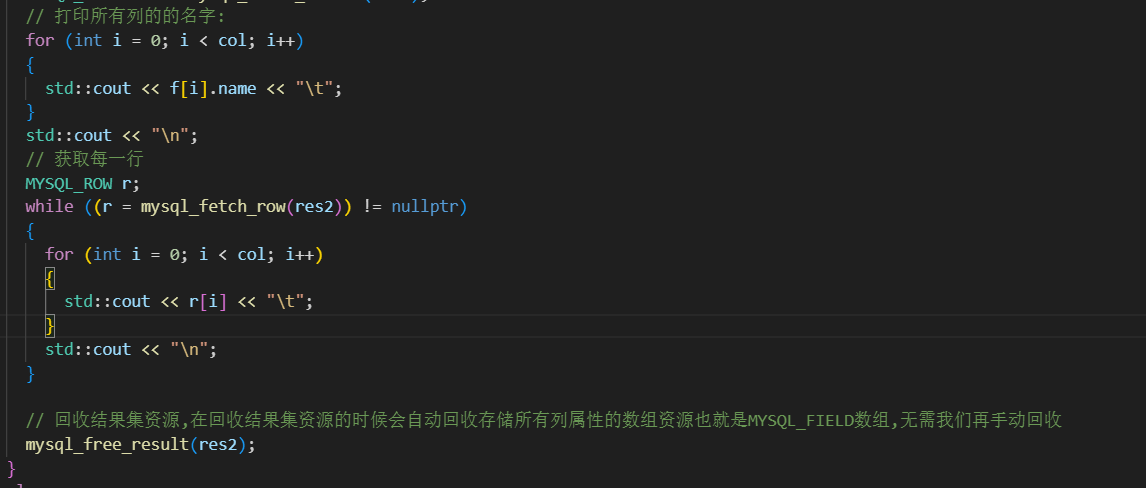
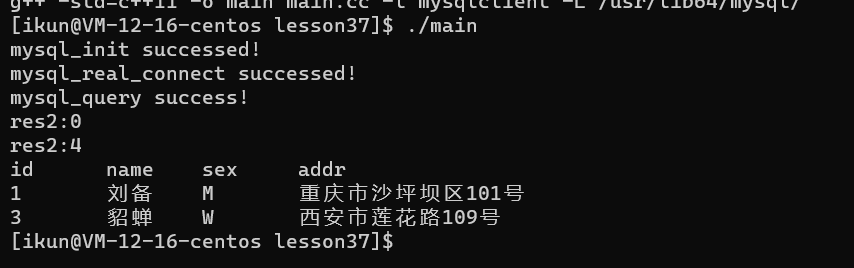
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result)
描述:
检索结果集的下一行。在mysql_store_result()之后使用时,如果没有要检索的行,mysql_fetch_row()返回NULL;在mysql_use_result()之后使用时,如果没有要检索的行或出现了错误,mysql_fetch_row()返回NULL。
返回值:
下一行的MYSQL_ROW结构。如果没有更多要检索的行或出现了错误,返回NULL。
eg:
对于MYSQL_ROW结构的理解:
通过查看MYSQL_ROW的源码我们可以看到MYSQL_ROW本质上就是一个二级指针;
我们应该如何理解这个二级指针呢?
首先对于每一行数据我们可以这样理解吧:

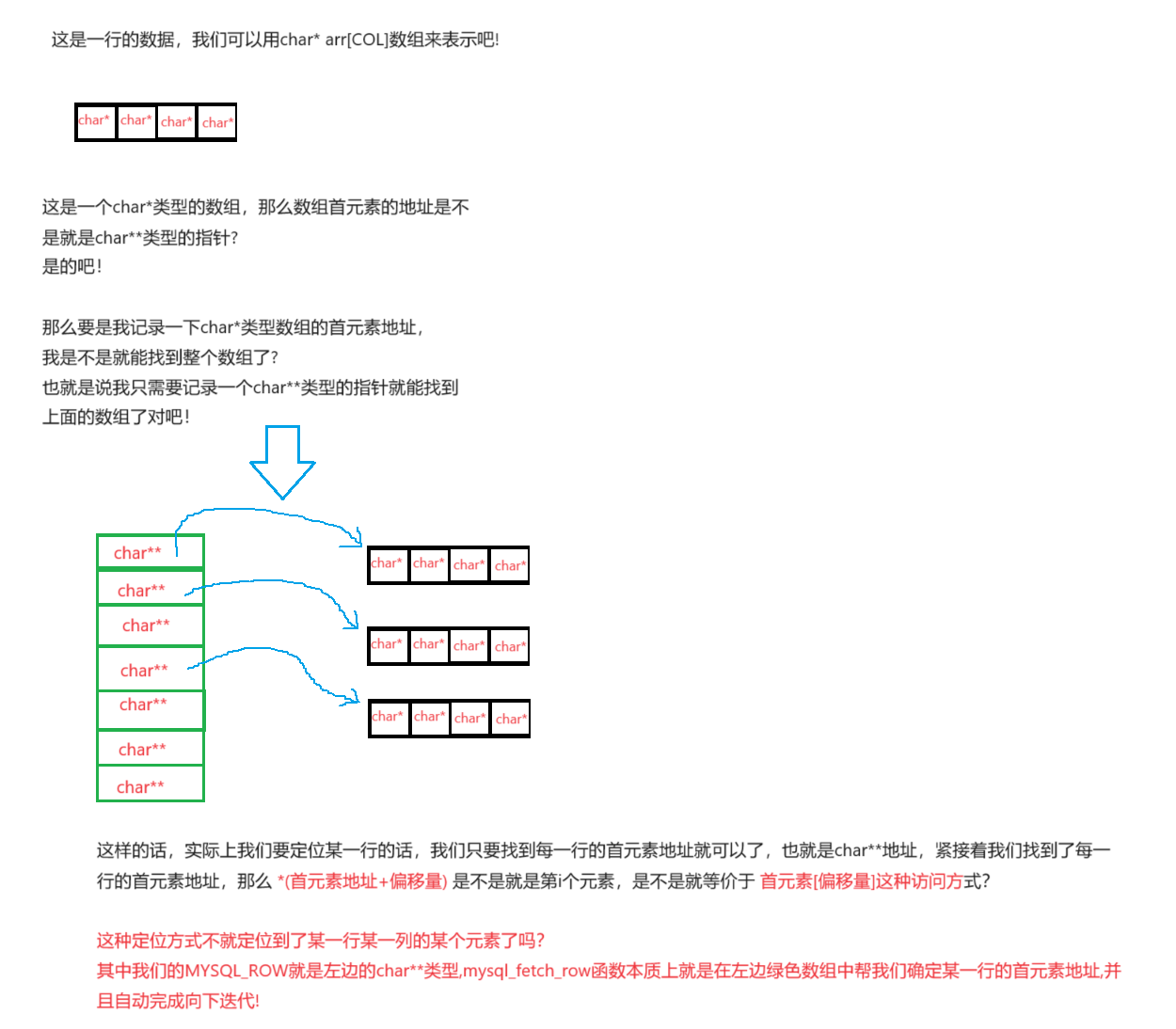
mysql_close
void mysql_close(MYSQL *mysql)
描述:
如果mysql对象是由mysql_init创建的话,则回收该资源,并且断开与数据库的连接;
返回值:
无;