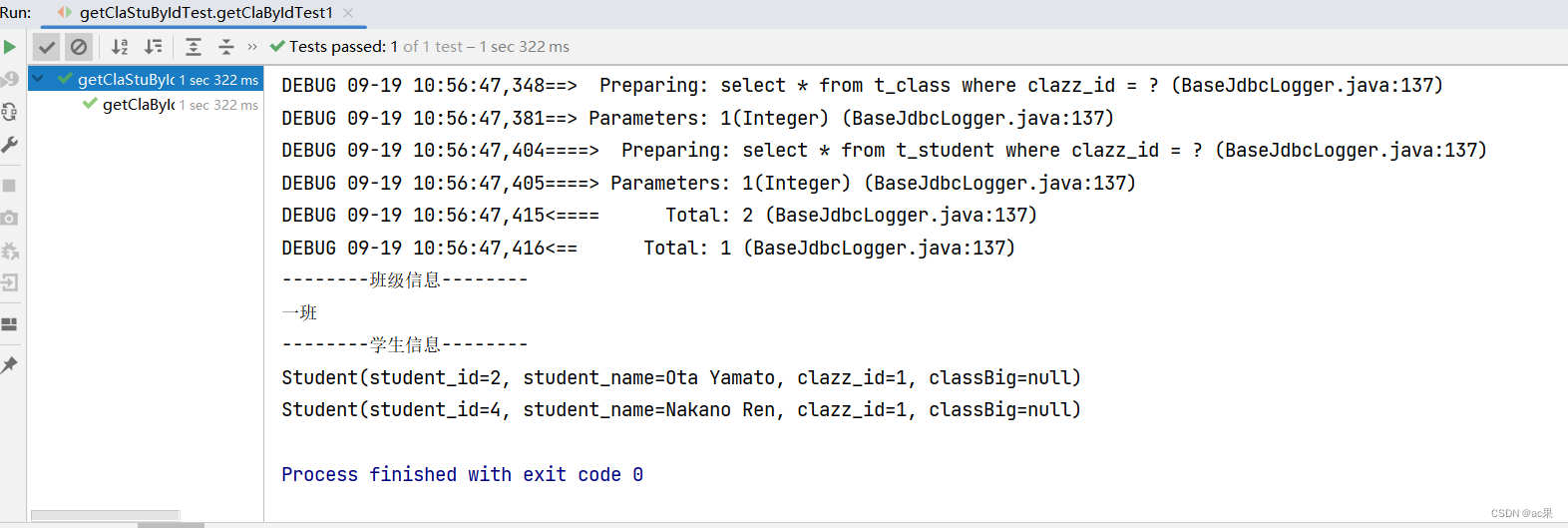
2023 年7月,Meta发布了其最新版本LLaMA 2,其中 LLama2 的注意力机制使用了GQA,那么什么是GQA呢?和标准的MHA有什么区别呢?关于 LLM 更多信息,可参考笔者文章:AIGC入门 - LLM信息概览
本文将介绍以下 内容:
- MHA: Multi Head Attention
- MQA:Multi Query Attention
- GQA:Grouped Query Attention
一、MHA(Multi Head Attention)
Google 的团队在 2017 年提出的一种 NLP 经典模型:Attention Is All You Need ,首次提出并使用了 Self-Attention 机制,也就是 Multi Head Attention。
关于 Multi Head Attention 内容可参考笔者之前文章:Transformer模型总体架构和理论,此处不再赘述。
二、MQA(Multi Query Attention)
1、论文
MQA(Multi Query Attention)最早是出现在2019年谷歌的一篇论文 《Fast Transformer Decoding: One Write-Head is All You Need》,之所以没有关注到,是因为之前很少做文本生成,解码序列长度也没有现阶段大模型的要求那么高。
2、原理
MQA的思想其实比较简单,论文中给出的描述如下:
Multi-query attention is identical except that the different heads share a single set of keys and values.
理解翻译内容:MQA 与 MHA 不同的是,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头正常的只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
3、MHA 和 MQA 对比
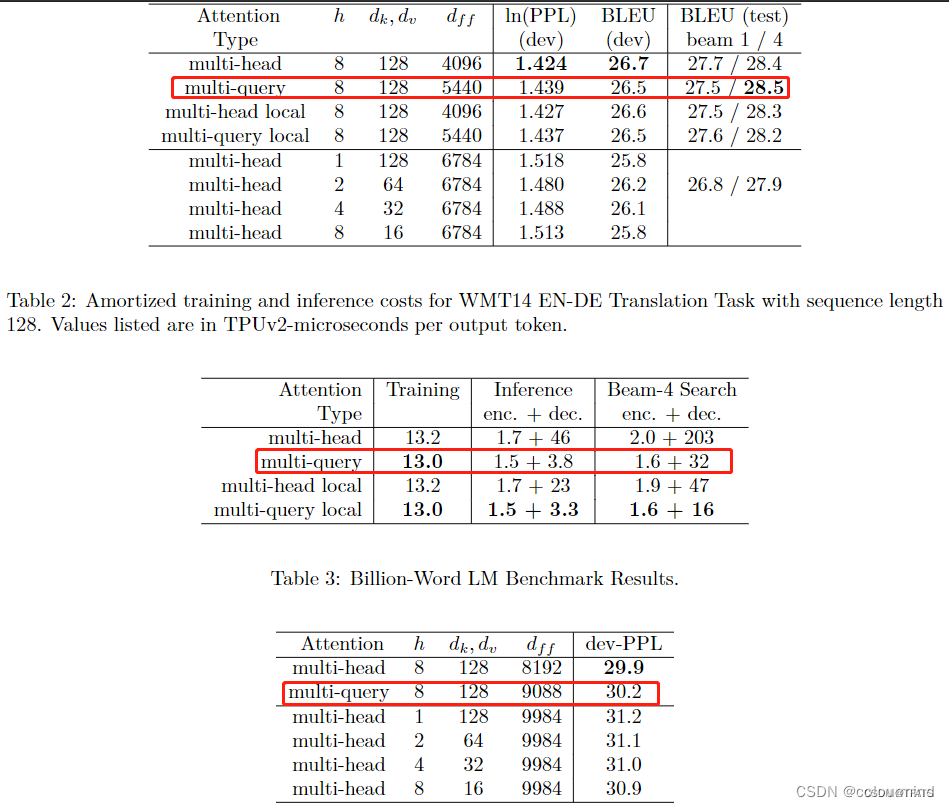
推理速度上生成一个 token 时 MHA 和 MQA 的 encoder 分别耗时1.7us和1.5us,而 decoder 分别46us和3.8us,说明 decoder 上 MQA 比 MHA 快很多。另外在效果上 MQA 的 PPL (越小越好)有所上升,BLEU(越大越好)有所下降,换句话说就是效果有所下降。
4、改进
如上对比,在 Multi-Query Attention 方法中只会保留一个单独的key-value头,这样虽然可以提升推理的速度,但是会带来精度上的损失。《Multi-Head Attention:Collaborate Instead of Concatenate 》这篇论文的第一个思路是基于多个 MQA 的 checkpoint 进行 finetuning,来得到了一个质量更高的 MQA 模型。这个过程也被称为 Uptraining。
具体分为两步:
- 对多个 MQA 的 checkpoint 文件进行融合,融合的方法是: 通过对 key 和 value 的 head 头进行 mean pooling 操作,如下图。
- 对融合后的模型使用少量数据进行 finetune 训练,重训后的模型大小跟之前一样,但是效果会更好
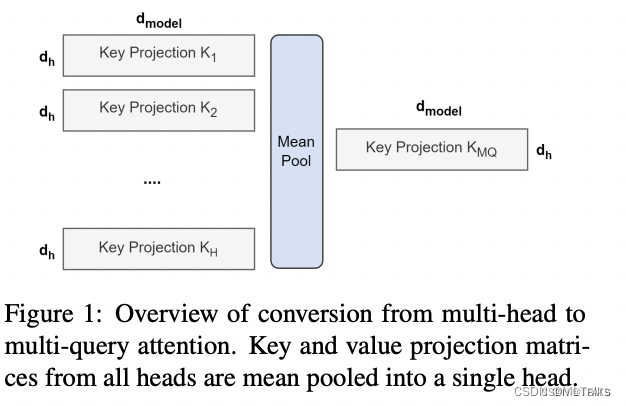
三、GQA(Grouped Query Attention)
1、论文
Google 在 2023 年发表的一篇 《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》的论文,整体论文写的清晰易读。
2、原理
如下图所示,在 MHA(Multi Head Attention)中,每个头有自己单独的 key-value 对;在 MQA(Multi Query Attention)中只会有一组 key-value 对;在 GQA(Grouped Query Attention)中,会对 attention 进行分组操作,query 被分为 N 组,每个组共享一个 Key 和 Value 矩阵。GQA-N 是指具有 N 组的 Grouped Query Attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。而GQA-H具有与头数相等的组,等效于MHA。
在基于 Multi-head 多头结构变为 Grouped-query 分组结构的时候,也是采用跟上图一样的方法,对每一组的 key-value 对进行 mean pool 的操作进行参数融合。融合后的模型能力更综合,精度比 Multi-query 好,同时速度比 Multi-head 快。

3、MHA、MQA、GQA 对比
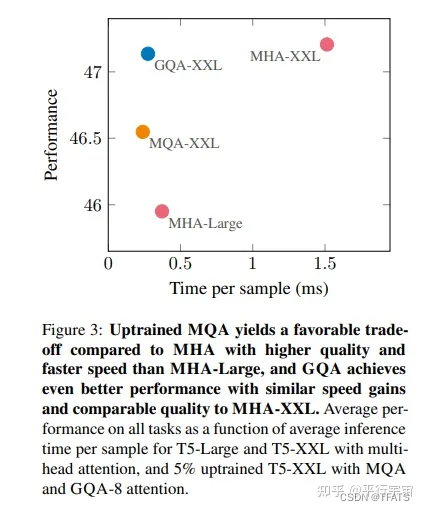
GQA 综合 MHA 和 MQA ,既不损失太多性能,又能利用 MQA 的推理加速。不是所有 Q 头共享一组 KV,而是分组一定头数 Q 共享一组 KV,比如上图中就是两组 Q 共享一组 KV。
参考:
- 具体可以参考【Andy Yang:为什么现在大家都在用 MQA 和 GQA?】