目录
一.引言
二.FastAPI Server 构建
1.get - read_items
2.post - create_item
3.uvicorn - run_app
三.Postman 请求
1.post - create_item
2.get - read_items
四.Requests 请求
1.post - create_item
2.get - read_items
五.总结
一.引言
前面介绍了 LLM 的相关知识,从样本加载、模型加载到后面的模型训练与模型推理,我们经历的完整的 LLM LoRA 微调与推理流程。基于前面的预训练模型,我们尝试使用 FastAPI 构建接口服务,本文主要介绍最基本的 FastAPI get、post 用法,后续介绍完整的 server 部署。
二.FastAPI Server 构建
下面我们构建一个 API 服务,共包含两个方法:
◆ read_items - 将 items 数组的元素打印出来
◆ create_item - 向 items 数组添加一个元素
1.get - read_items
get 方法是 HTTP 请求的一种类型,通常用语从服务器获取数据。由于 read_items 方法是从服务器获取 items 数组,所以其对应 get 请求。get 请求通常没有请求体,所有参数都放在 URL 的查询字符串中,所以存在一定的安全性问题。
# -*- coding: utf-8 -*-
from fastapi import FastAPI, Form
app = FastAPI()
# 示例数据
items = []
# GET 请求
@app.get("/items")
async def read_items():
return items2.post - create_item
post 方法是区别于 get 的另一种 HTTP 请求类型,通常用于向服务器发送数据。post 通常包含一个请求体,传输的参数不需要通过 '?' 显式的体现在请求的 URL 中,而是可以通过 JSON 对象传递,相对 get 方法更加安全。与 get 相比,post 操作不是幂等的,其每次执行完可能得到不同的结果,而 get 操作则通常认为是幂等的,这意味着多次执行 get 得到的结果应该是相同的。
# POST 请求
@app.post("/items")
async def create_item(item: str = Form(None)):
items.append(item)
return {"message": "Item created successfully: {}".format(str(item))}这里 Post 请求成功后会有成功的提示并打印成功添加的 item。
3.uvicorn - run_app
uvicorn.run(app, host="192.XXX.XXX", port=8001) 方法是 uvicorn 的命令行接口。其中,app 是你想要运行的应用对象,对应我们上面的 FastAPI 的 get 与 post 对应的方法,host 和 port 则是服务将要监听的 IP 地址和端口。该方法会启动一个 ASGI 服务器,以指定的 host 和 port 为你的应用提供服务。后续的 HTTP 请求的 URL 也是基于上面的 host 和 port 组成。下面我们在本机起一个 FastAPI 服务。
if __name__ == '__main__':
import uvicorn
uvicorn.run(app, host='0.0.0.0', port=7788)运行主函数后出现如下提示代表 Server 启动成功,我们后续对应的 HTTP 请求 URL 为图中蓝色链接 http://0.0.0.0:7788:

三.Postman 请求
针对上面构建的 HTTP 服务,我们可以通过显示的 App 例如 postman 进行 get 和 post 请求。
1.post - create_item

打开 postman 选择 POST 命令,输入对应的 URL + 函数对应的路径,上面 get 和 post 请求对应的路径都是 URL + items,在对应 form-data 处传递要添加的 item,注意这里 key 要和函数定义的参数名称完全对应,否则会报错。执行 send 按钮发送 Http 请求,从返回的 Body 中我们看到成功添加 python 到 items 列表中。后面我们修改 value 为 'java' 和 'c++' 并依次发送 post 指令。

server 端也要每次请求的具体信息,status_code == 200 代表请求成功。
2.get - read_items
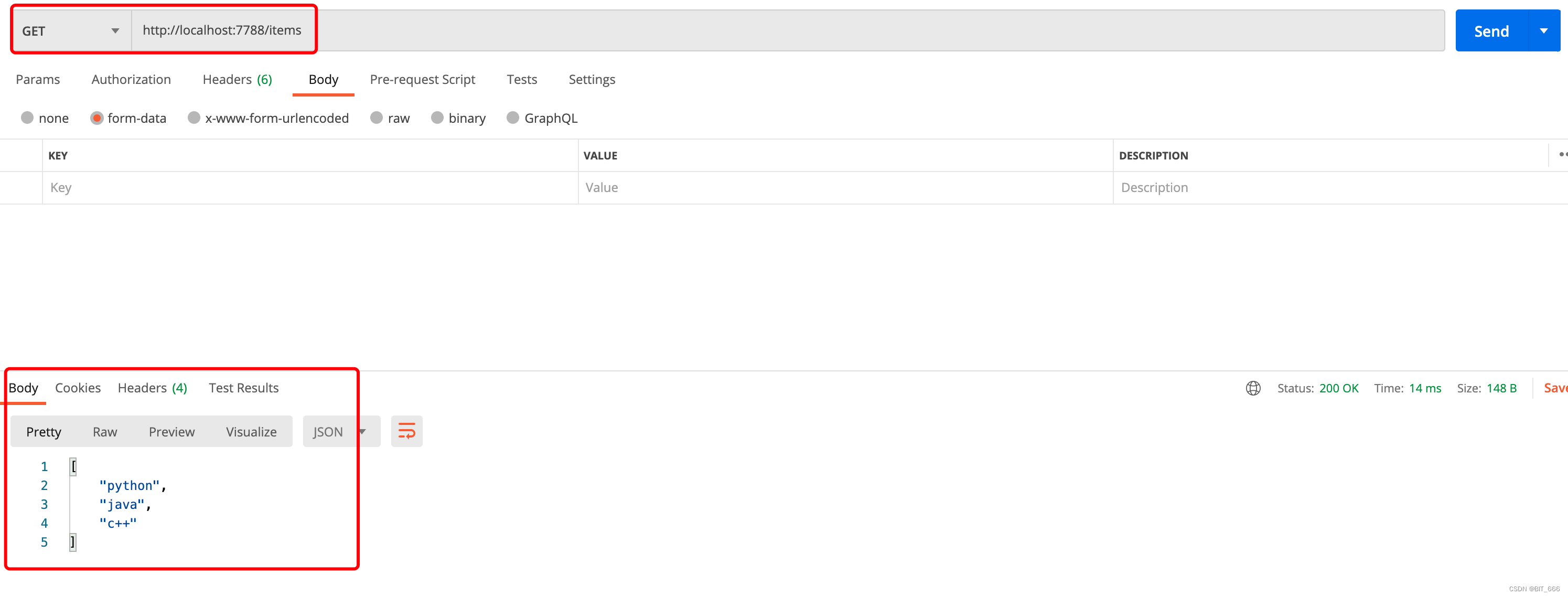
将请求模式切换为 GET,由于 get 命令未传参数,所以直接输入对应地址 Send 发送请求即可。返回的结果中包含我们上面添加的三个元素:python、java、c++。server 端也增加对应的 get 请求日志:

四.Requests 请求
上面 Postman 采用显式的页面方式向 server 发送 HTTP 请求并获取结果,更常规的做法是通过 requests 库使用代码发送请求并处理返回结果。
1.post - create_item
def post(text):
url = 'http://0.0.0.0:7788/items'
# 构建请求数据
data = {
'item': text
}
# 发送 post 请求
response = requests.post(url=url, data=data, timeout=10)
# 检查响应状态
if response.status_code == 200:
print('请求成功')
print(response.json())
else:
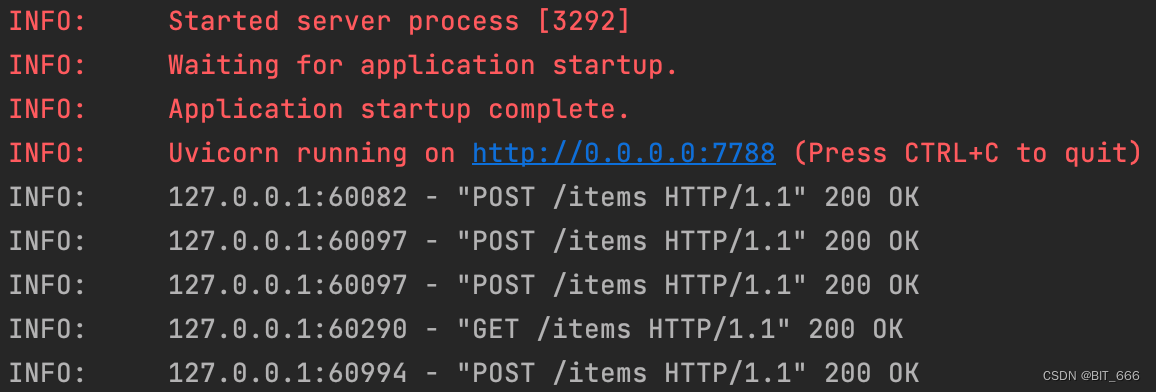
print('请求失败,状态码:', response.status_code)requests.post 添加对应 url 与 data,data 为 map 形式,其中要包含 post 函数对应的 key,结尾处会根据 status_code 判断请求是否成功。从 server 日志可以看出这一次 create_item 也执行成功了:
2.get - read_items
def get():
url = 'http://0.0.0.0:7788/items'
response = requests.get(url)
if response.status_code == 200:
data = response.json()
print('成功获取,返回:', data)
else:
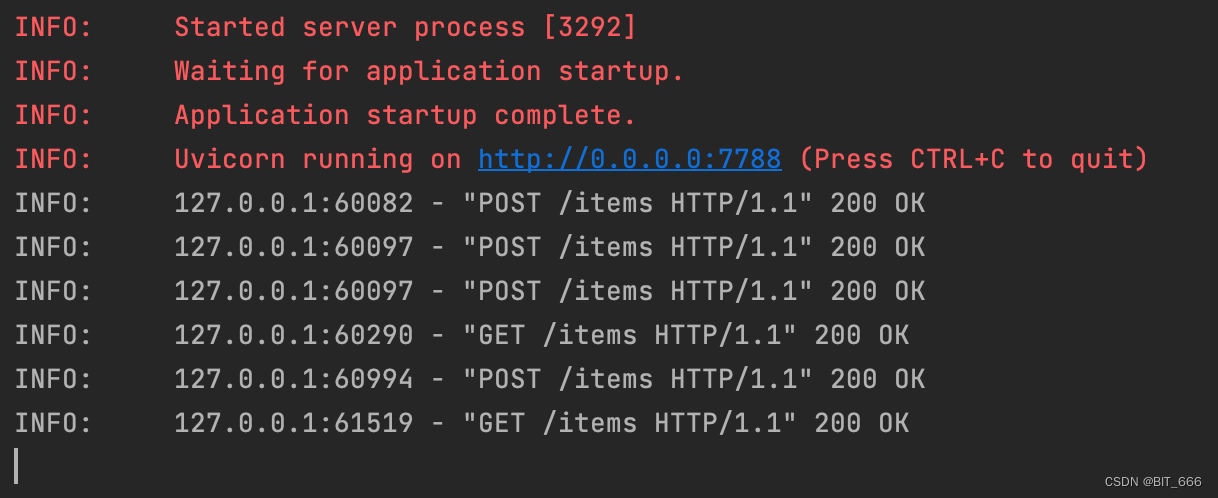
print('请求失败,状态码:', response.status_code)requests.get 直接传入对应 url 即可获取对应信息:

server 端如下日志代表本次 get 请求成功:
五.总结
上面介绍了如何使用 FastAPI 搭建简单的 Server Demo,后续基于该方法构建 LLM Server。


![[CISCN2019 华东南赛区]Web11 SSTI](https://img-blog.csdnimg.cn/48d65210517a461ea2ade83c5b3478b4.png)
![buuctf-[WUSTCTF2020]朴实无华](https://img-blog.csdnimg.cn/f594924cce334e57966cae193c136289.png)