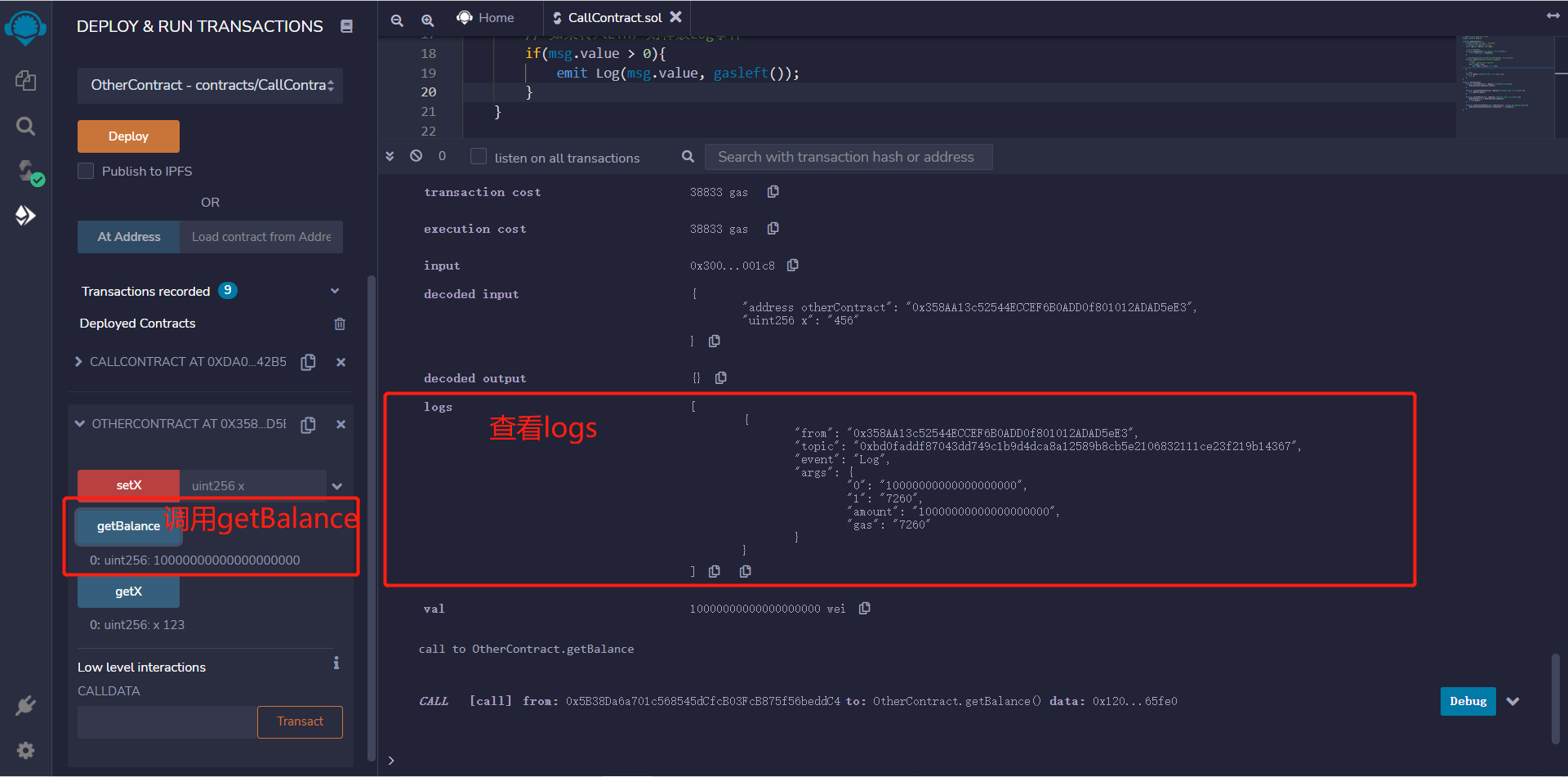
PyTorch深度学习实战(16)——面部关键点检测
- 0. 前言
- 1. 关键点检测
- 1.1 关键点检测模型分析
- 1.2 数据集分析
- 2. 面部关键点检测
- 3. 2D 和 3D 面部关键点检测
- 小结
- 系列链接
0. 前言
我们已经学习了如何解决二分类(猫狗分类)和多分类( fashionMNIST )问题。本节中,我们将学习如何解决回归问题,研究多个自变量对多个因变量的影响。假如我们需要预测面部图像上的关键点,例如眼睛、鼻子和下巴的位置,就需要采用新的策略构建模型来检测面部关键点。在本文中,我们将基于预训练 VGG16 架构提取图像特征,然后微调模型检测图像中人物面部关键点。
1. 关键点检测
1.1 关键点检测模型分析
面部关键点检测( Facial Landmark Detection )旨在自动识别并捕捉面部照片或视频中的关键点位置,例如眼睛、鼻子、嘴巴、眉毛等。通常使用深度学习算法通过对丰富的面部数据进行训练,自动提取面部特征,识别面部关键点位置,并将其标记在面部图片或视频的相应位置上。面部关键点检测可以使计算机更好地理解和学习面部图像和视频中的信息,提取面部特征,为人脸识别、表情识别和面部特征分析等应用提供基础数据。

如上图所示,面部关键点表示包含人脸的图像上的各个关键点的标记。要检测面部关键点,我们首先要解决以下问题:
- 图像具有不同的尺寸
- 调整图像尺寸以使它们具有标准图像尺寸
- 面部关键点类似于散点图上的点,但其基于某种模式散布
- 将图像尺寸调整为
224 x 224 x 3,像素介于0和224之间
- 将图像尺寸调整为
- 根据图像尺寸对因变量(面部关键点的位置)进行归一化
- 考虑它们相对于图像尺寸的位置,则关键点值介于
0和1之间 - 由于因变量值始终介于
0和1之间,因此可以在最后使用sigmoid函数来得到介于0和1之间的值
- 考虑它们相对于图像尺寸的位置,则关键点值介于
- 定义用于加载数据集的数据管道:
- 定义准备数据集的类,对输入图像进行预处理以执行迁移学习,并获取关键点相对于处理后的图像的相对位置
- 定义模型、损失函数和优化器
- 使用平均绝对误差作为损失函数,因为输出是介于
0到1之间的连续值
- 使用平均绝对误差作为损失函数,因为输出是介于
1.2 数据集分析
对于面部关键点检测任务,我们所使用的数据集可以从 Github 中下载,数据集中标注了中图片的人物面部的关键点。在此任务中,输入数据是需要在其上检测关键点的图像,输出数据是图像中人物面部关键点的 x 和 y 坐标。
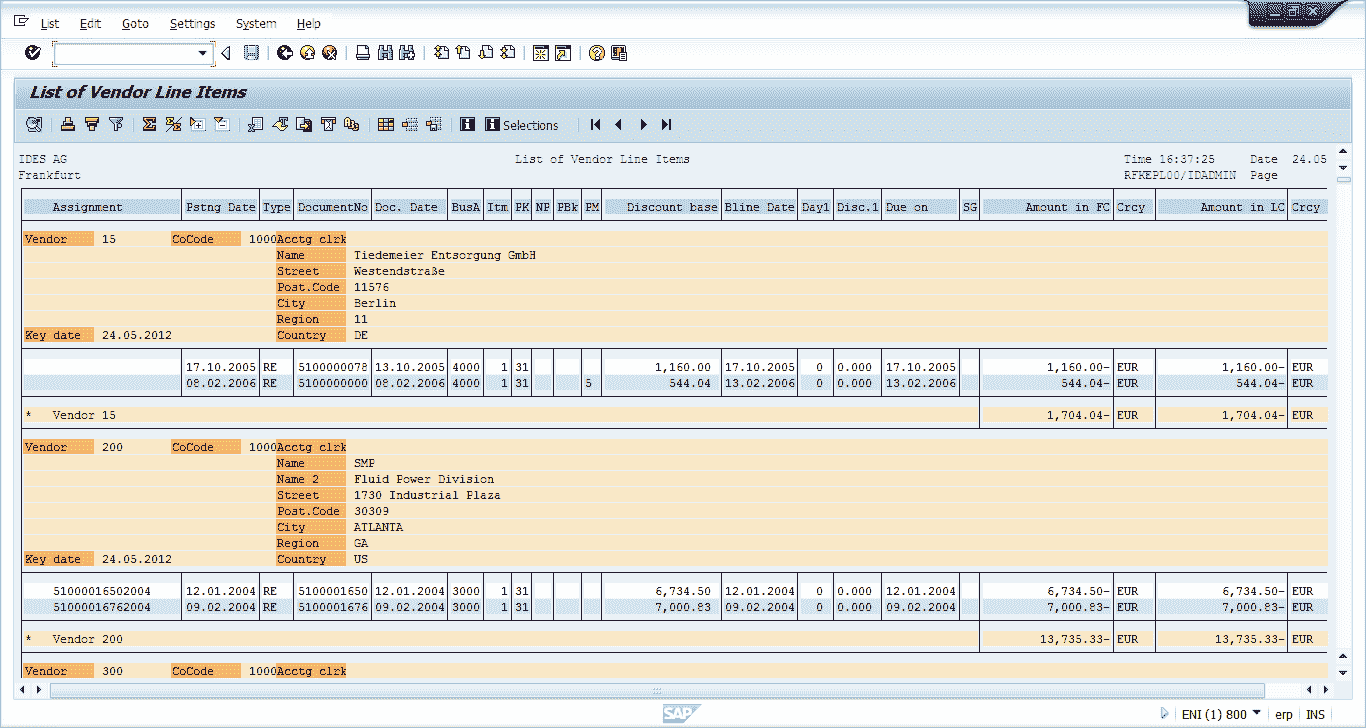
在构建模型前,首先将数据集下载至本地,查看数据集中标记的面部关键点信息,文件路径为 P1_Facial_Keypoints/data/training_frames_keypoints.csv:

检查此数据集中的面部关键点信息,可以看到,文件中共有 137 列,其中第 1 列是图像的名称,其余 136 列代表相应图像中 68 个面部关键点的 x 和 y 坐标值,偶数列表示面部 68 个关键点中每个关键点对应的 x 轴坐标,奇数列(第 1 列除外)表示面部 68 个关键点中每个关键点对应的 y 轴坐标。
2. 面部关键点检测
接下来,使用 PyTorch 实现面部关键点检测模型。
(1) 导入相关库:
import torch.nn as nn
import torch
from torchvision import transforms, models
import numpy as np, pandas as pd, os, glob
import matplotlib.pyplot as plt
import glob
device = 'cuda' if torch.cuda.is_available() else 'cpu'
(2) 下载并导入相关数据,下载包含图像及其对应的面部关键点的数据集:
root_dir = 'P1_Facial_Keypoints/data/training/'
all_img_paths = glob.glob(os.path.join(root_dir, '*.jpg'))
data = pd.read_csv('P1_Facial_Keypoints/data/training_frames_keypoints.csv')
(3) 定义为数据加载器提供输入和输出数据样本的 FacesData 类:
class FacesData(Dataset):
定义 __init__ 方法,以二维数据表格( df )作为输入:
def __init__(self, df):
super(FacesData).__init__()
self.df = df
定义用于预处理图像的均值和标准差,供预训练 VGG16 模型使用:
self.normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
定义 __len__ 方法:
def __len__(self):
return len(self.df)
定义 __getitem__ 方法,获取与给定索引对应的图像,对其进行缩放,获取与给定索引对应的关键点值,对关键点进行归一化,以便我们获取关键点的相对位置,并对图像进行预处理。
定义 __getitem__ 方法并获取与给定索引 (ix) 对应的图像路径:
def __getitem__(self, ix):
img_path = 'P1_Facial_Keypoints/data/training/' + self.df.iloc[ix,0]
缩放图像:
img = cv2.imread(img_path)/255.
将目标输出值(关键点位置)根据原始图像尺寸的比例进行归一化:
kp = deepcopy(self.df.iloc[ix,1:].tolist())
kp_x = (np.array(kp[0::2])/img.shape[1]).tolist()
kp_y = (np.array(kp[1::2])/img.shape[0]).tolist()
在以上代码中,确保关键点按原始图像尺寸的比例计算,这样做是为了当我们调整原始图像的尺寸时,关键点的位置不会改变。
对图像进行预处理后返回关键点( kp2 )和图像( img ):
kp2 = kp_x + kp_y
kp2 = torch.tensor(kp2)
img = self.preprocess_input(img)
return img, kp2
定义预处理图像函数( preprocess_input ):
def preprocess_input(self, img):
img = cv2.resize(img, (224,224))
img = torch.tensor(img).permute(2,0,1)
img = self.normalize(img).float()
return img.to(device)
定义函数加载图像,用于可视化测试图像和测试图像的预测关键点:
def load_img(self, ix):
img_path = 'P1_Facial_Keypoints/data/training/' + self.df.iloc[ix,0]
img = cv2.imread(img_path)
img =cv2.cvtColor(img, cv2.COLOR_BGR2RGB)/255.
img = cv2.resize(img, (224,224))
return img
(4) 拆分训练和测试数据集,并构建训练和测试数据集和数据加载器:
from sklearn.model_selection import train_test_split
train, test = train_test_split(data, test_size=0.2, random_state=101)
train_dataset = FacesData(train.reset_index(drop=True))
test_dataset = FacesData(test.reset_index(drop=True))
train_loader = DataLoader(train_dataset, batch_size=32)
test_loader = DataLoader(test_dataset, batch_size=32)
(5) 定义用于识别图像中关键点的模型。
加载预训练的 VGG16 模型:
def get_model():
model = models.vgg16(pretrained=True)
冻结预训练模型的参数:
for param in model.parameters():
param.requires_grad = False
重建模型最后两层并训练参数:
model.avgpool = nn.Sequential(nn.Conv2d(512,512,3),
nn.MaxPool2d(2),
nn.Flatten())
model.classifier = nn.Sequential(
nn.Linear(2048, 512),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, 136),
nn.Sigmoid())
分类器模块中最后一层使用 sigmoid 函数,它返回介于 0 和 1 之间的值,因为关键点位置是相对于原始图像尺寸的相对位置,因此预期输出将始终介于 0 和 1 之间。
定义损失函数(使用平均绝对误差)和优化器:
criterion = nn.L1Loss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
return model.to(device), criterion, optimizer
(6) 初始化模型,损失函数,以及对应的优化器:
model, criterion, optimizer = get_model()
(7) 定义函数在训练数据集上进行训练并在测试数据集上进行验证。
train_batch() 函数根据输入计算模型输出、损失值并执行反向传播以更新权重:
def train_batch(img, kps, model, optimizer, criterion):
model.train()
optimizer.zero_grad()
_kps = model(img.to(device))
loss = criterion(_kps, kps.to(device))
loss.backward()
optimizer.step()
return loss
构建函数返回测试数据的损失和预测的关键点:
@torch.no_grad()
def validate_batch(img, kps, model, criterion):
model.eval()
_kps = model(img.to(device))
loss = criterion(_kps, kps.to(device))
return _kps, loss
(8) 训练模型,并在测试数据上对其进行测试:
train_loss, test_loss = [], []
n_epochs = 50
for epoch in range(n_epochs):
print(f" epoch {epoch+ 1}/50")
epoch_train_loss, epoch_test_loss = 0, 0
for ix, (img,kps) in enumerate(train_loader):
loss = train_batch(img, kps, model, optimizer, criterion)
epoch_train_loss += loss.item()
epoch_train_loss /= (ix+1)
for ix,(img,kps) in enumerate(test_loader):
ps, loss = validate_batch(img, kps, model, criterion)
epoch_test_loss += loss.item()
epoch_test_loss /= (ix+1)
train_loss.append(epoch_train_loss)
test_loss.append(epoch_test_loss)
(9) 绘制模型训练过程中训练和测试损失:
epochs = np.arange(50)+1
import matplotlib.pyplot as plt
plt.plot(epochs, train_loss, 'bo', label='Training loss')
plt.plot(epochs, test_loss, 'r', label='Test loss')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()

(10) 使用随机测试图像的测试模型,利用 FacesData 类中的 load_img 方法:
ix = 20
plt.figure(figsize=(10,10))
plt.subplot(121)
plt.title('Original image')
im = test_dataset.load_img(ix)
plt.imshow(im)
plt.grid(False)
plt.subplot(122)
plt.title('Image with facial keypoints')
x, _ = test_dataset[ix]
plt.imshow(im)
kp = model(x[None]).flatten().detach().cpu()
plt.scatter(kp[:68]*224, kp[68:]*224, c='r')
plt.grid(False)
plt.show()

从以上图像中可以看出,给定输入图像,模型能够相当准确地识别面部关键点。
3. 2D 和 3D 面部关键点检测
在上一小节中,我们从零开始构建了面部关键点检测器模型。在本节中,我们将学习如何利用专门为 2D 和 3D 关键点检测而构建的预训练模型来获取面部的 2D 和 3D 关键点。为了完成此任务,我们将使用 face-alignment 库。
(1) 使用 pip 安装 face-alignment 库:
pip install face-alignment
(2) 加载所需库和图片:
import face_alignment
import cv2
file = '4.jpeg'
im = cv2.imread(file)
input = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
(3) 定义人脸对齐方法,指定是要获取 2D 还是 3D 关键点坐标:
fa = face_alignment.FaceAlignment(face_alignment.LandmarksType._2D, flip_input=False, device='cpu')
(4) 读取输入图像并将其作为 get_landmarks 方法的输入:
preds = fa.get_landmarks(input)[0]
print(preds.shape)
# (68, 2)
在以上代码,利用 FaceAlignment 类的对象 fa 中的 get_landmarks 方法来获取与面部关键点对应的 68 个 x 和 y 坐标。
(5) 用检测到的关键点绘制图像:
import matplotlib.pyplot as plt
fig,ax = plt.subplots(figsize=(5,5))
plt.imshow(input)
ax.scatter(preds[:,0], preds[:,1], marker='+', c='r')
plt.show()

(6) 获得面部关键点的 3D 投影:
fa = face_alignment.FaceAlignment(face_alignment.LandmarksType._3D, flip_input=False, device='cpu')
im = cv2.imread(file)
input = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
preds = fa.get_landmarks(input)[0]
import pandas as pd
df = pd.DataFrame(preds)
df.columns = ['x','y','z']
import plotly.express as px
fig = px.scatter_3d(df, x = 'x', y = 'y', z = 'z')
fig.show()
与 2D 关键点检测中使用的代码的唯一变化是将 LandmarksType 指定为 3D 而不是 2D,输出结果如下所示:

通过利用 face_alignment 库,可以看到利用预训练的面部关键点检测模型在预测新图像时具有较高精度。
小结
面部关键点的定位通常是许多面部分析方法和算法中的关键步骤。在本节中,我们介绍了如何通过训练卷积神经网络来检测面部的关键点,首先通过预训练模型提取特征,然后利用微调模型预测图像中人物的面部关键点,并利用 face_alignment 库来获取图像中人物面部的 2D 和 3D 关键点。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习