任务1:数据预处理
表格数据资源如下百度网盘👇
链接:https://pan.baidu.com/s/1pUYfRIe557v6O9ByB2rhEw 提取码:ovgl
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# %matplotlib inline
# 更改绘图风格,此处是R语言的风格
plt.style.use('ggplot')
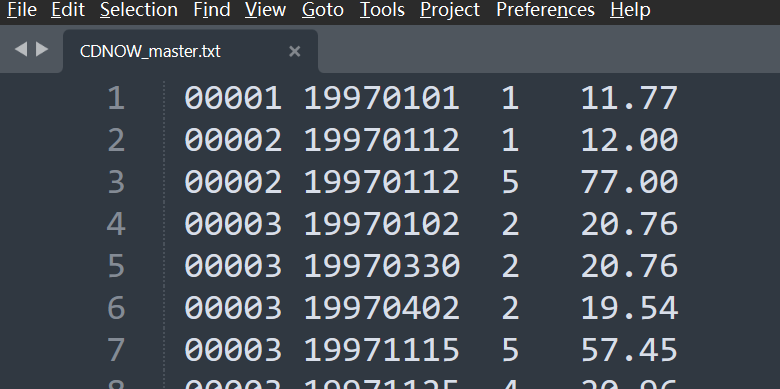
数据存放在.txt文件中,属性值没有列名且每列数值以空格作为分隔符
# 读取的 txt 数据中没有列名,因此需要手动添加
coloums=['user_id','order_dt','order_products','order_amount']
# sep='\s+' 表示以任意空格作为不同属性的分隔符
data = pd.read_table('CDNOW_master.txt',names=coloums,sep='\s+')
data
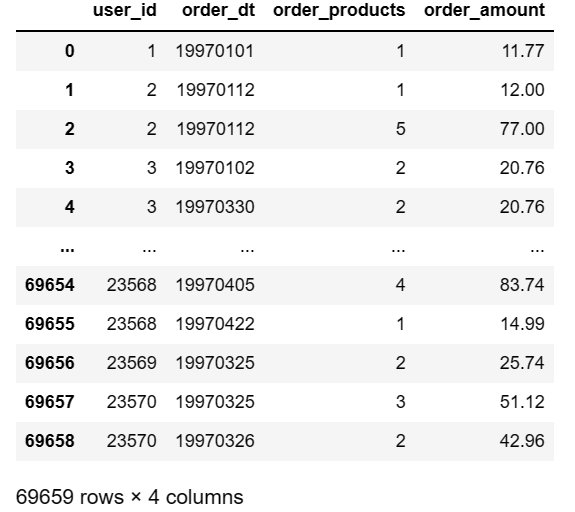
user_id:用户 I D ID IDorder_dt:购买日期order_products:购买产品数量order_amount:购买金额
# 查看数据一些基本数值信息
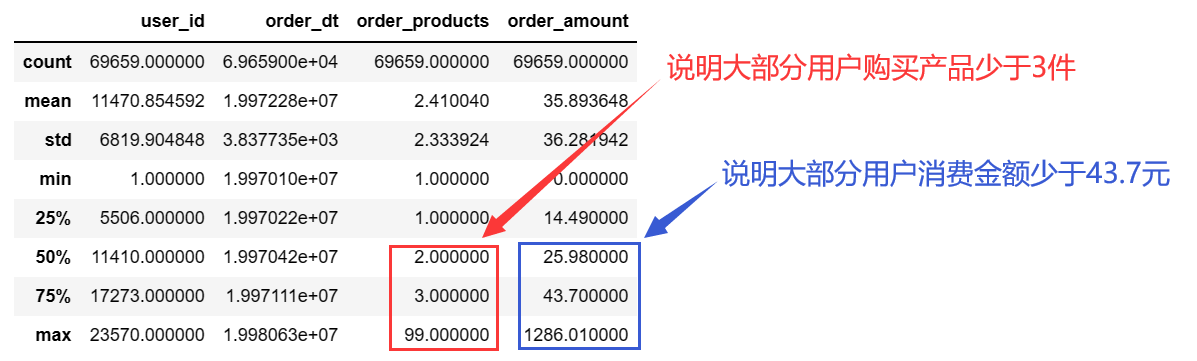
data.describe()
任务2:将order_dt列转换为标准日期格式
# format参数:按照指定的格式去匹配要转换的数据列
# %Y:四位的年份 %m:两位的月份 %d:两位的天【几号】
# %y:两位的年份 %h:两位的小时 %M:两位的分钟 %s:两位的秒
data['order_dt']=pd.to_datetime(data['order_dt'],format='%Y%m%d')
data
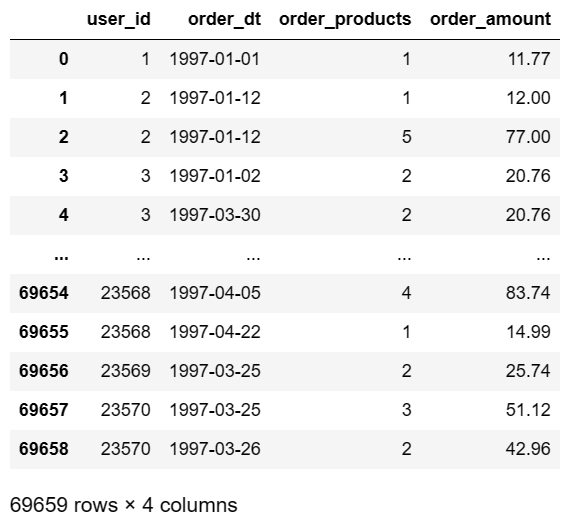
增添一列month,用来存放年份与月份的日期信息
# month这一列也是存放日期,不过精度只到月份;M 即控制精度到月份
data['month']=data['order_dt'].astype('datetime64[M]')
# data.drop(columns='month',inplace=True)
data
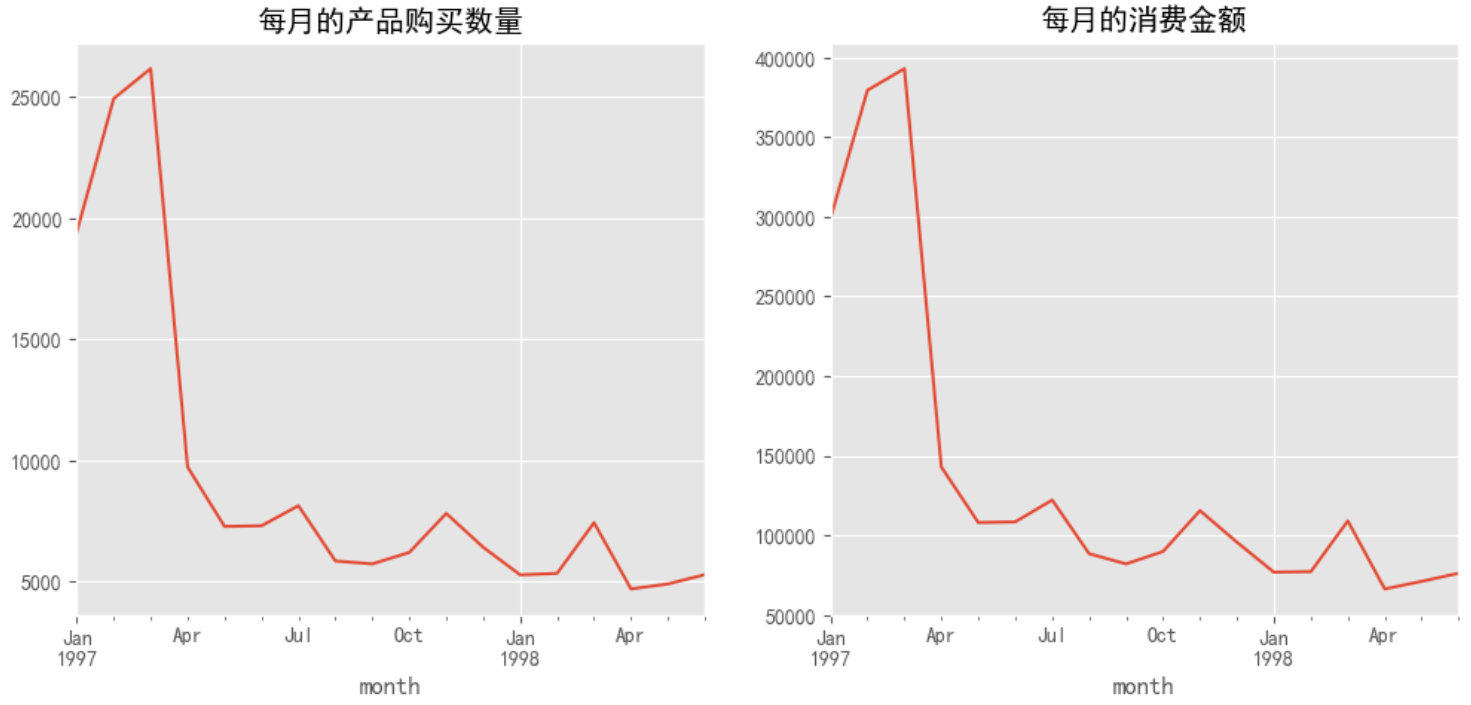
任务3:统计每月产品购买数,消费金额
同年同月的产品购买数,消费金额再相加即可
# 设置画布大小【即绘制的图形大小】
plt.figure(figsize=(12,5))
# 总共绘制1行2列,当前准备绘制第1行第1列的图形
plt.subplot(121)
# 每月的产品购买数量
data.groupby(by='month')['order_products'].sum().plot()
plt.title('每月的产品购买数量')
# # 每月的消费金额
plt.subplot(122)
data.groupby(by='month')['order_amount'].sum().plot()
plt.title('每月的消费金额')
plt.show()
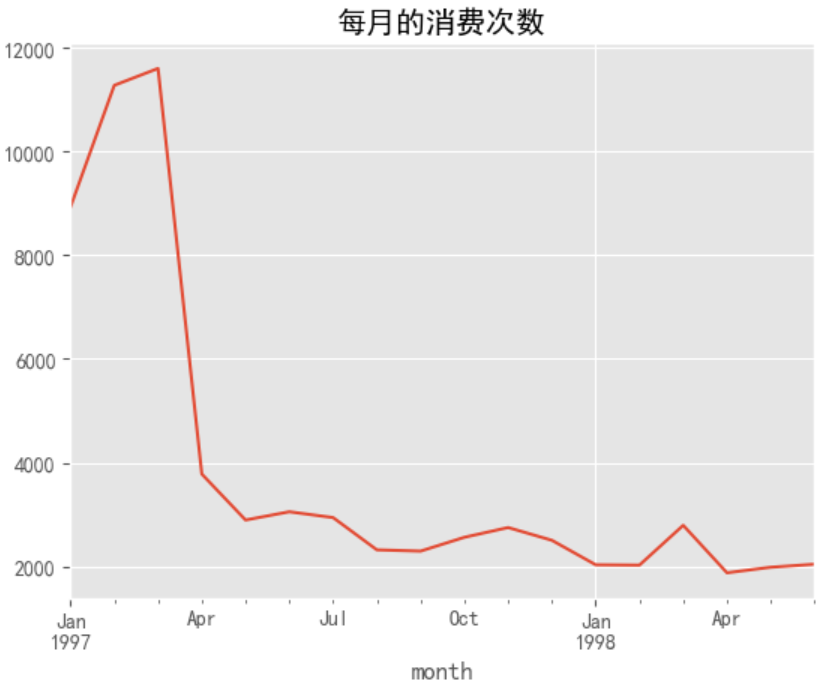
任务4:统计每月的消费次数
# count()统计同一组 user_id 条目出现的个数
data.groupby(by='month')['user_id'].count().plot()
plt.title('每月的消费次数')
plt.show()
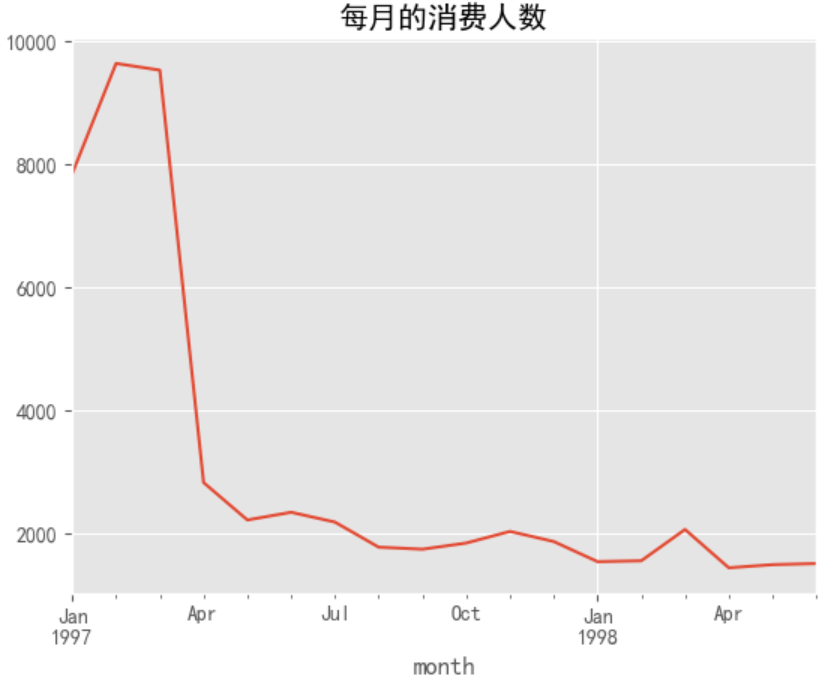
任务5:统计每月消费人数
# map()是对Series中的每个具体元素进行映射;apply()是对整个Series进行映射
# 此处将 user_id 去重后再进行人员统计,确保一个用户只被计算一次
data.groupby(by='month')['user_id'].apply(lambda x: len(x.drop_duplicates())).plot()
plt.title('每月的消费人数')
plt.show()
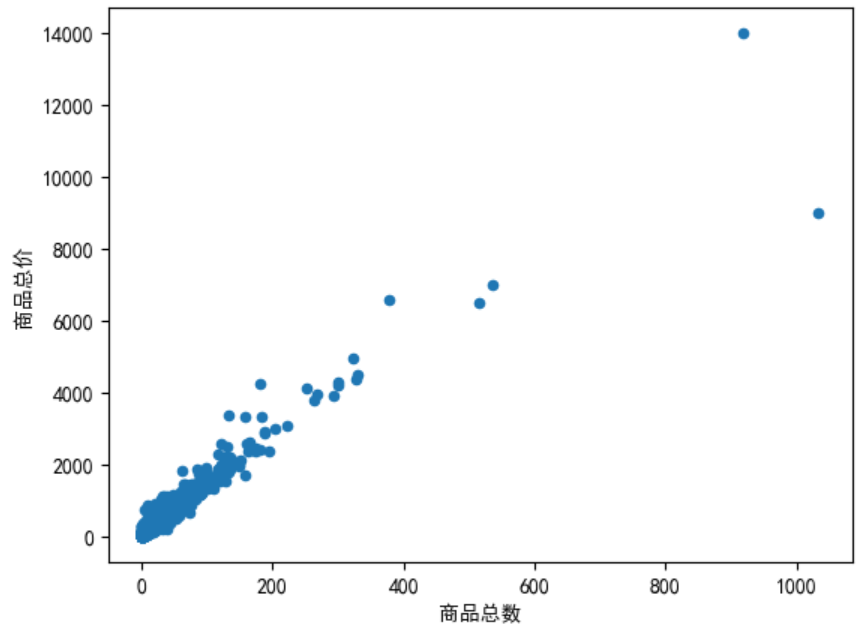
任务6:散点图展示用户购买商品数量与价钱关系
# 将 data 按照 user_id 分组,对于其他列进行求和处理【日期列无法求和,因此被丢弃】
user_id_group = data.groupby(by='user_id').sum()
# 绘制散点图,x 轴为 order_products;y 轴为 order_amount【斜率正好为平均单价】
user_id_group.plot(kind='scatter',x='order_products',y='order_amount')
plt.xlabel('商品总数')
plt.ylabel('商品总价')
plt.show()
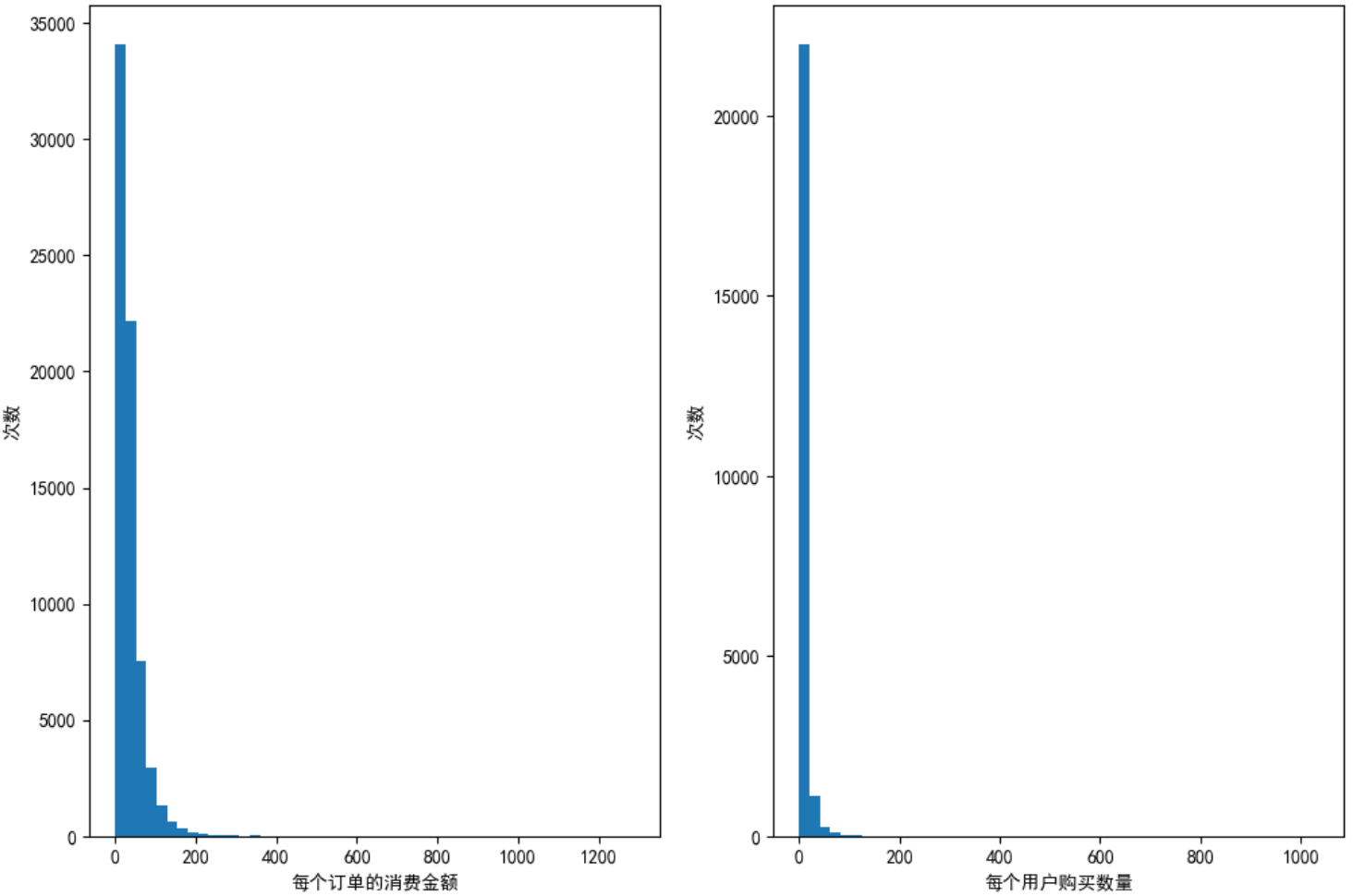
任务7:直方图统计订单消费金额与用户购买数量
# 设置画布大小,即绘制图形的大小
plt.figure(figsize=(12,8))
# 总共有1行2列个图,当前画第1个
plt.subplot(121)
# 订单的消费金额
# hist 代表直方图;柱子宽度=(最大值-最小值)/bins,所以bins越大,直方图越细
data['order_amount'].plot(kind='hist',bins=50)
plt.xlabel('每个订单的消费金额')
plt.ylabel('次数')
# 总共有1行2列个图,当前画第2个
plt.subplot(122)
# 每个用户的购买数量
data.groupby(by='user_id')['order_products'].sum().plot(kind='hist',bins=50)
plt.xlabel('每个用户购买数量')
plt.ylabel('次数')
plt.show()
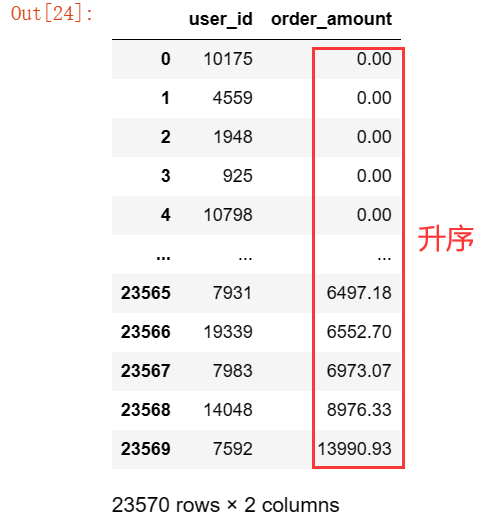
任务8:统计用户消费金额贡献率
8.1 按照用户消费金额进行升序排序
# 按照用户消费金额进行升序排序,合并掉一些条目后索引会乱,因此需要重置索引reset_index
user_sum_amount=data.groupby(by='user_id')['order_amount'].sum().sort_values().reset_index()
user_sum_amount
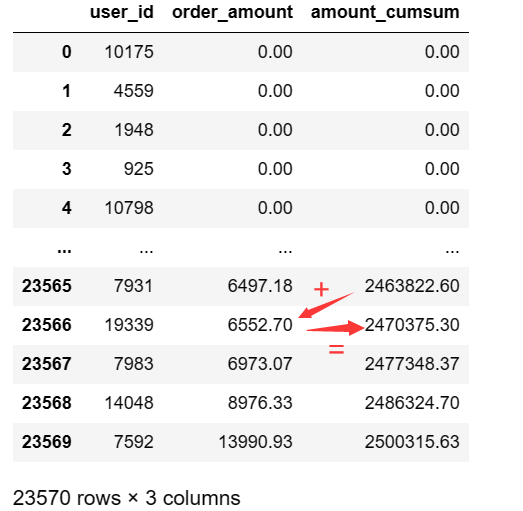
8.2 增添amount_cumsum列记录用户消费金额累加和
# cumsum()是对列表求前缀和并保存再新列表,如[1,2,3]计算后变[1,3,6]
user_sum_amount['amount_cumsum']=user_sum_amount['order_amount'].cumsum()
user_sum_amount
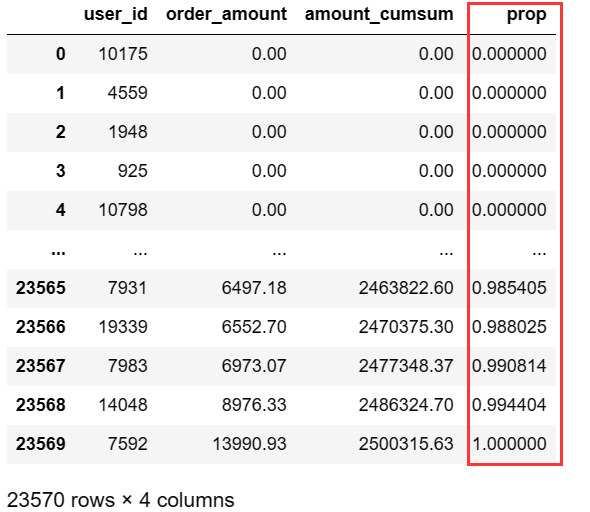
8.3 增添prop贡献率列
# 所有订单amount的累加和
amount_total = user_sum_amount['amount_cumsum'].max()
# 当前订单的累加和/总累加和 == 贡献率
user_sum_amount['prop']=user_sum_amount['amount_cumsum'].apply(lambda x:x/amount_total)
user_sum_amount
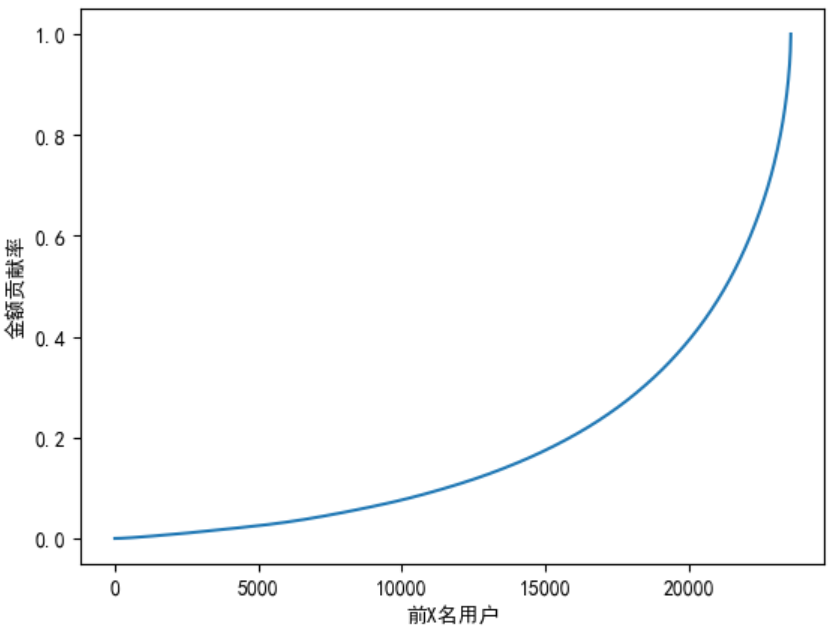
8.4 绘制贡献率折线图
user_sum_amount['prop'].plot()
plt.xlabel('前X名用户')
plt.ylabel('金额贡献率')
plt.show()
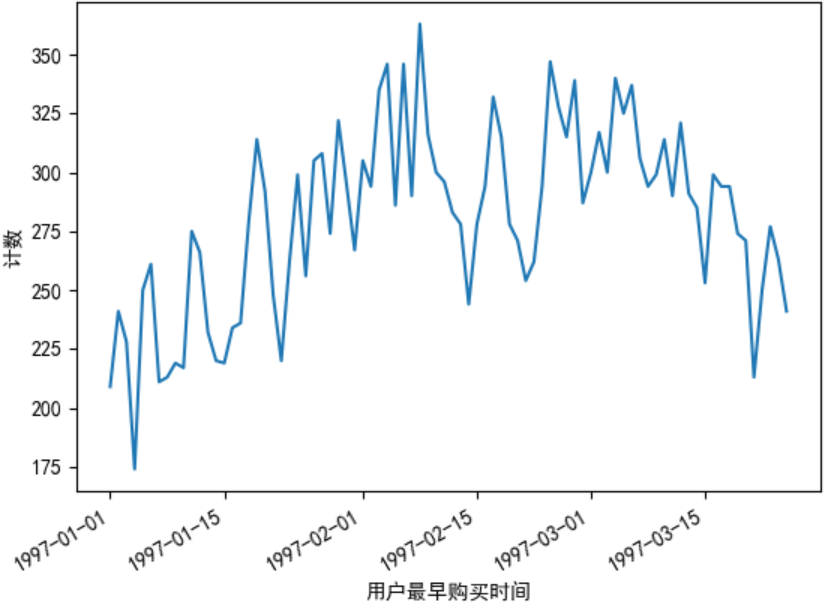
任务9:统计用户最早购买时间
# 取出用户的最早购买时间并对相同时间的用户进行计数
data.groupby(by='user_id')['order_dt'].min().value_counts().plot()
plt.xlabel('用户最早购买时间')
plt.ylabel('计数')
plt.show()
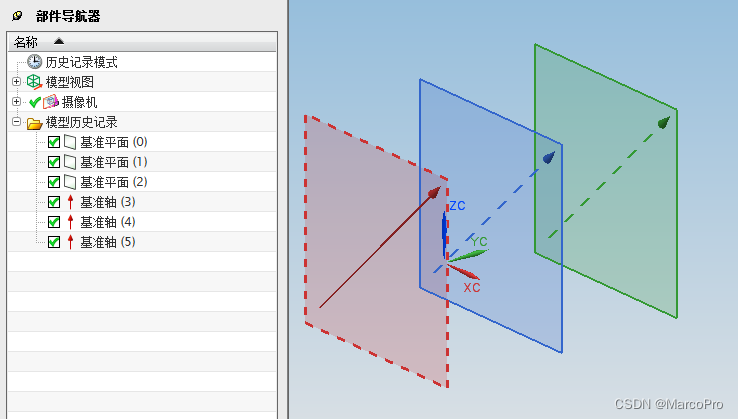
任务10:利用RMF模型对用户进行分类
10.1 RMF模型
为了进行精细化运营,可以利用RFM模型对用户价值指数(衡量历史到当前用户贡献的收益)进行计算
R(Recency,最近一次消费):R值越大,表示客户交易发生的日期越久,反之则交易发生的日期越近F(Frequency,消费频率):F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃M(Monetary,消费金额):M值越大,表示客户价值越高,反之则表示客户价值越低
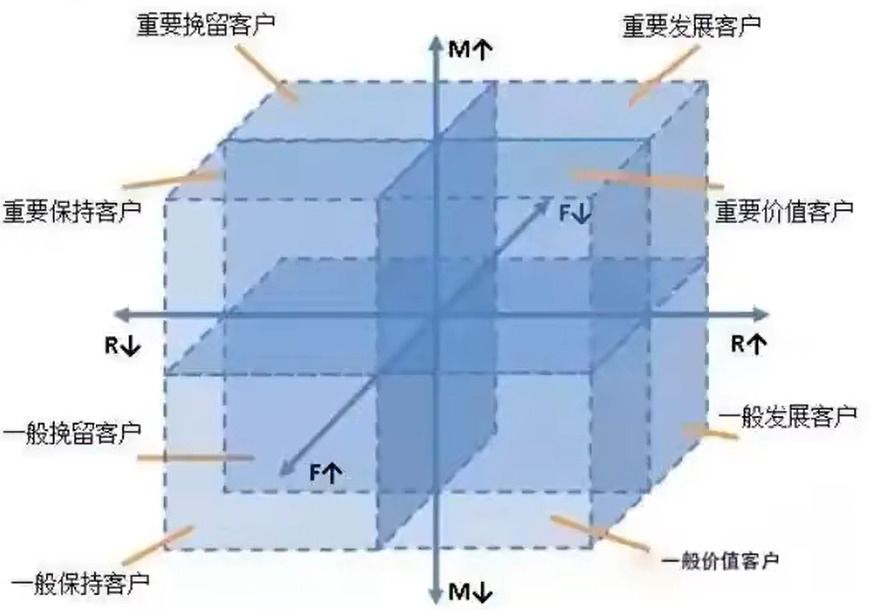
RFM计算方式:每一列数据减去数据所在列的平均值,有正有负,根据结果值与 1 做比较,如果 >=1 ,设置为1,否则0
所以最后会生成000~111共8种分类结果,如上图👆
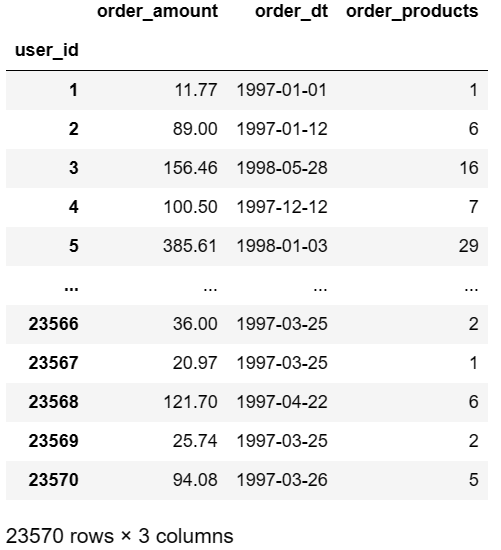
# pandas 自带透视表函数【透视表可以理解为对不同列进行不同聚合操作后形成的临时表】
# index指定透视表索引【重复项被合并】;values指定透视表列;aggfunc规定对不同列的聚合函数
rfm = data.pivot_table(index='user_id',
values=['order_products','order_amount','order_dt'],
aggfunc={
'order_products':'sum', # 用户购买产品总数
'order_amount':'sum', # 用户购买产品总金额
'order_dt':'max' # 用户最后一次消费时间
})
rfm.head()
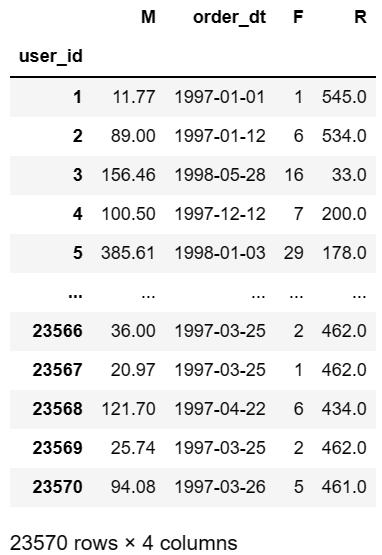
# 增添 R列 记录当前用户最后一次购买时间与统计中最晚一次购买时间相隔的天数
# /np.timedelta64(1,'D')将日期以天数进行存储,并保留1位小数
rfm['R']=(rfm['order_dt'].max()-rfm['order_dt'])/np.timedelta64(1,'D')
# F列 记录当前用户购买的产品总数,正好和order_products一致,因此直接替换;M列的处理同理
rfm.rename(columns={'order_products':'F','order_amount':'M'},inplace=True)
rfm
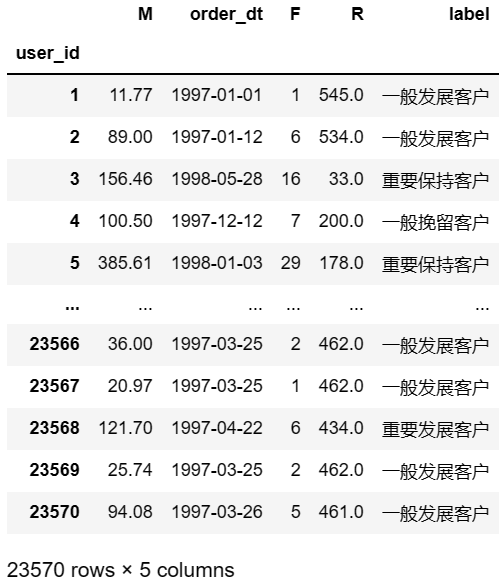
# 传入的 x 存储了 data 中R,F,M列与对应列平均值的差值
def rfm_func(x):
# 如果当前差值大于等于1就令新列取1,否则取0
level = x.apply(lambda x:'1' if x>=1 else '0')
# 将 level 的三列进行拼接可以得到一个长度为3的二进制字符串
label=level['R']+level['F']+level['M']
# 手动创建字典映射
d={
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要发展客户',
'001':'重要挽留客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般发展客户',
'000':'一般挽留客户'
}
# 按照拼装好的二进制去字典中寻找其对应标签,最后返回的列即不同用户对应的标签
return d[label]
# lambda中的x实际上取值为R一整列,F一整列,M一整列
# axis为1是以行的方向调用rfm_func函数
rfm['label']=rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
rfm
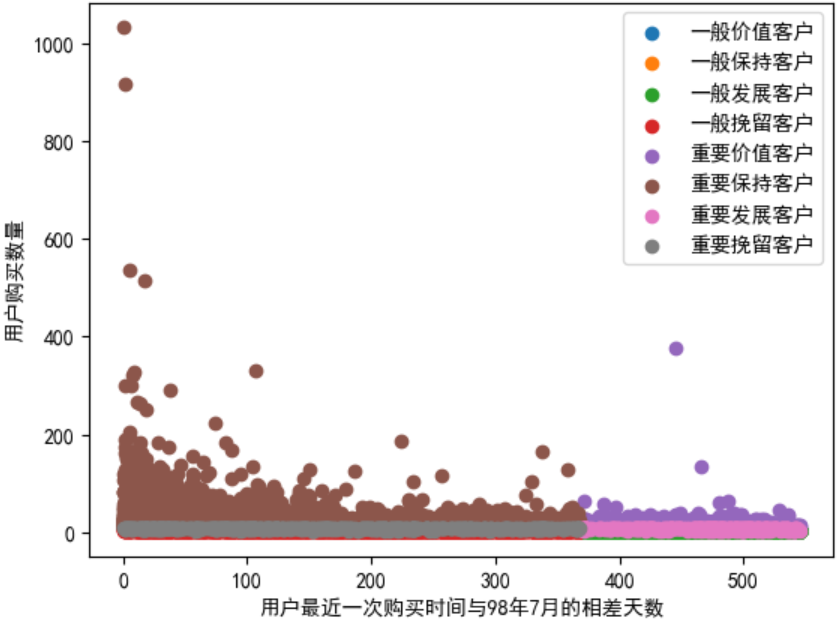
10.2 RMF模型散点化
- 当我们对一个
DataFrame进行groupby聚合分组操作时,我们会得到一个DataFrameGroupBy对象 DataFrameGroupBy包含若干个tupletuple中包含两项- 第一项是分组时指定的列得到的不同值
- 第二项是一个
DataFrame,DataFrame保持着和被聚合的原DataFrame结构一致
# 此处label装载8个标签结果,grouped即分组后的DataFrame
for label,grouped in rfm.groupby(by='label'):
# 主要为了查看标签散点分布【即哪种类型用户多】,因此x,y轴任取两列即可
x=grouped['R'] # 单个用户的购买数量
y=grouped['F'] # 最近一次购买时间与98年7月的相差天数
plt.scatter(x,y,label=label)
plt.legend() # 添加图例
plt.ylabel('用户购买数量')
plt.xlabel('用户最近一次购买时间与98年7月的相差天数')
plt.show()
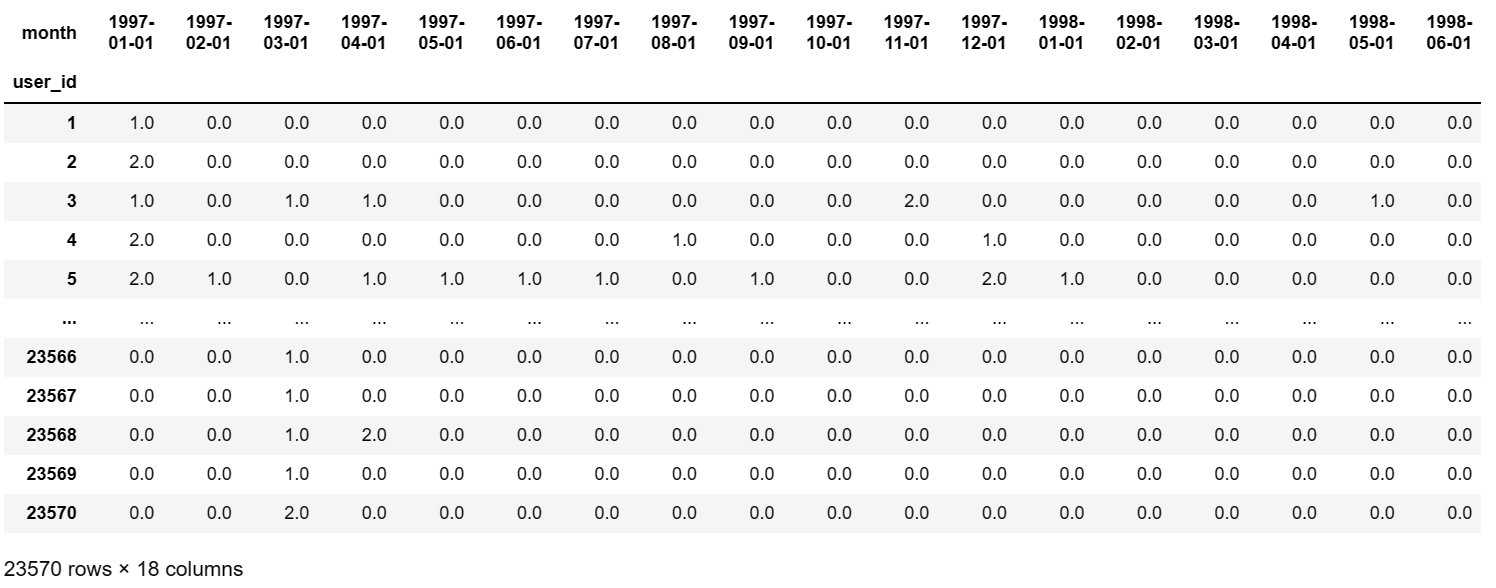
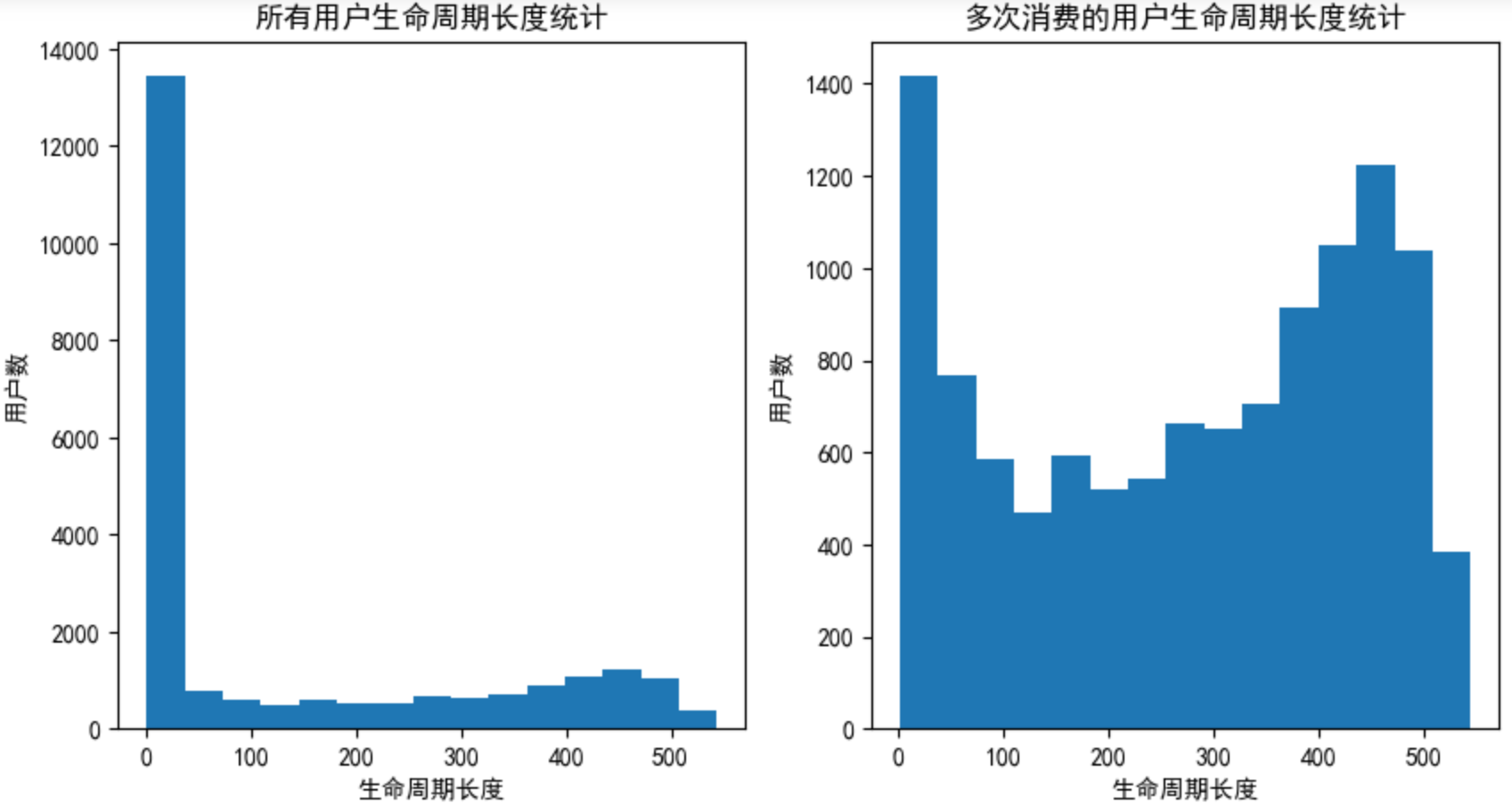
任务11:统计用户在各个月份的消费情况
# 新建透视表,行存放用户在某个月的订单数
pivoted_counts = data.pivot_table(
index='user_id',
columns='month', # month列的取值作为列属性值
values='order_dt', # order_dt作为列值
aggfunc={
'order_dt':'count' # 聚合时对列值使用count函数,结合起来也就是统计用户在某个月的订单数
}).fillna(0) # 将NAN空值用0来替换
pivoted_counts
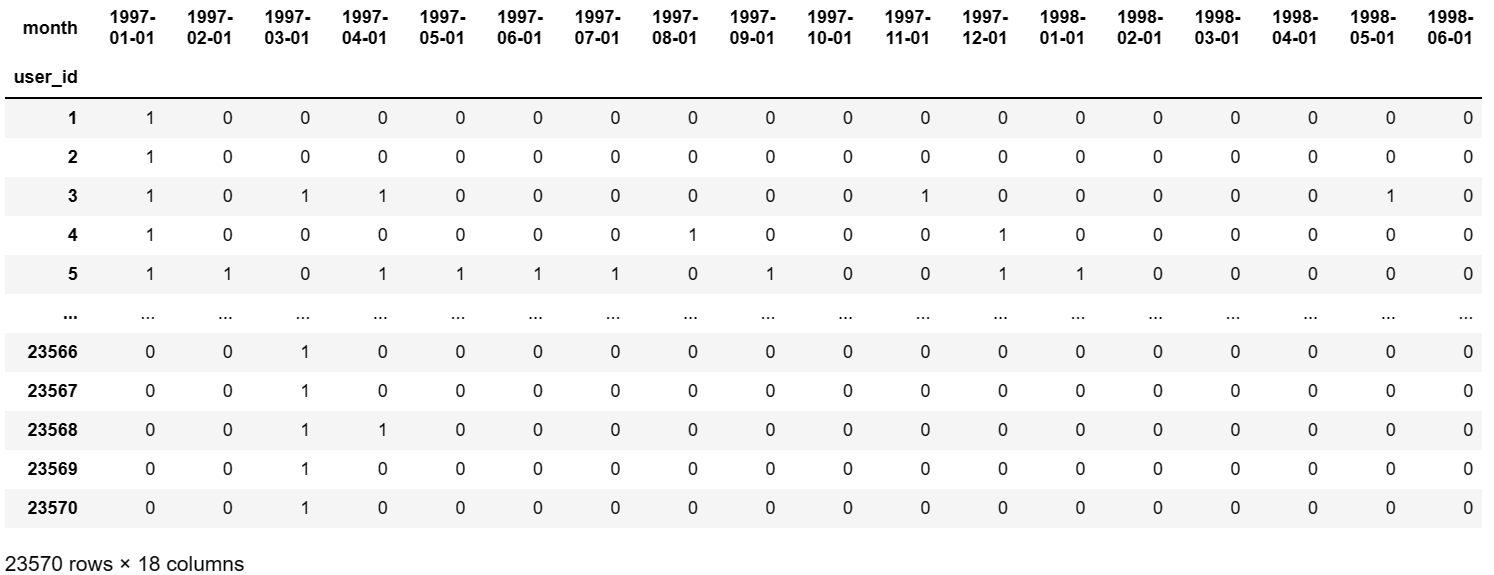
apply:作用与dataframe数据中的一行或者一列数据【也就是要有明确的行和列方向】applymap:作用与dataframe数据中的每一个元素map:本身是一个series的函数,在df结构中无法使用map函数,map函数作用于series中每一个元素
# def test_method(x):
# level = x.apply(lambda x:1 if x>0 else 0)
# return level
# df_purchase = pivoted_counts.apply(test_method,axis=1)
# 将有进行消费的标记为1,反之标记为0。此处实现方法等价于等价于👆
df_purchase = pivoted_counts.applymap(lambda x:1 if x>0 else 0)
df_purchase
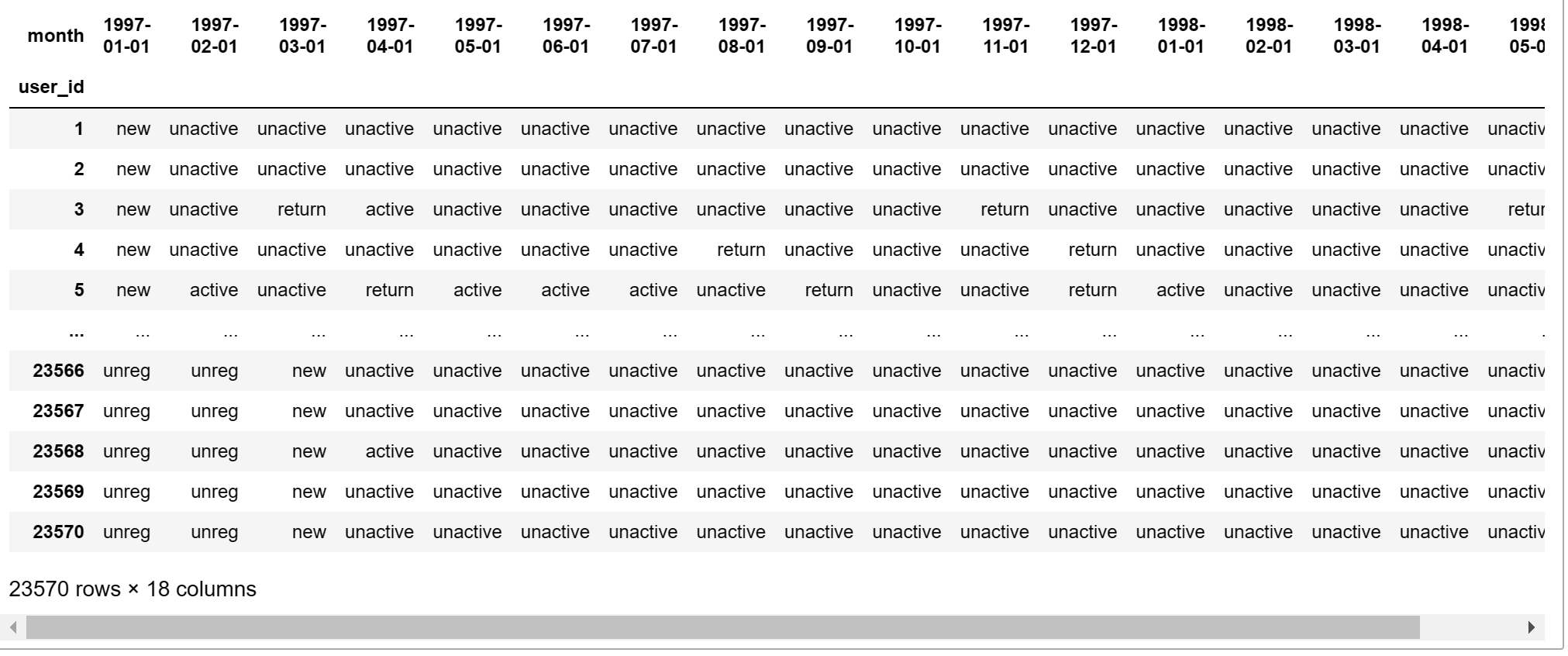
任务12:统计不同类型用户个数
- 从未消费过的用户,当下进行第一次消费标记为new【新用户】
- 当前月份未进行消费标记未unactive【不活跃用户】
- 上个月有消费,这个月也有消费标记未active【活跃用户】
- 曾经有消费过,并且上个月未进行消费,这个月进行了消费标记未return【回流用户】
- 从未进行过消费的用户标记未unreg【未注册用户】
# data:每一行数据(共18列)
def active_status(data):
status = [] #存储用户18个月的状态(new|active|unactive|return|unreg)
for i in range(18):
# 本月没有消费
if data[i] ==0: # 当前月份 i 没有消费
if len(status)==0: # 此时对应的是第一个月,肯定从未进行过消费
status.append('unreg')
else: # 第一个月之后的情况
if status[i-1] =='unreg':#一直没有消费过
status.append('unreg')
else:
status.append('unactive')
# 本月有消费
else:
if len(status)==0:
status.append('new') #第一次消费
else:# 第一个月之后的情况
# 说明之前有过消费但是不活跃,此时算回流用户
if status[i-1]=='unactive':
status.append('return')
# 说明之前没有过消费,此时算新用户
elif status[i-1]=='unreg':
status.append('new') #第一次消费
# 说明之前有过消费并且活跃,此时仍然延续活跃状态
else:
status.append('active') #活跃用户
# apply函数返回对象应是Series,此处按行处理,因此18个元素需要指定18个列名
# df_purchase是任务11最后生成的DataFrame
return pd.Series(status,df_purchase.columns) # 值:status,列名:18个月份
purchase_states = df_purchase.apply(active_status,axis=1) #得到用户分层结果
purchase_states
# 把 unreg 状态用 Nan 空值替换
purchase_states.replace('unreg',np.NaN,inplace=True)
# 统计每个月份不同类型用户的个数,由于unreg状态已经背替换为Nan,因此此状态个数不会被统计
purchase_states_ct = purchase_states.apply(lambda x:pd.value_counts(x))
purchase_states_ct.head()

# 图表中的Nan实则就是当前月份没有这个状态,即统计次数为0,因此可用0进行替换
purchase_states_ct.fillna(0,inplace=True)
# T代表转置,把原本应该为y轴的month转到x轴显示,另一个方向同理
# 数据可视化,面积图
purchase_states_ct.T.plot.area(figsize=(10,4))
plt.ylabel('不同类型用户的个数')
plt.show()
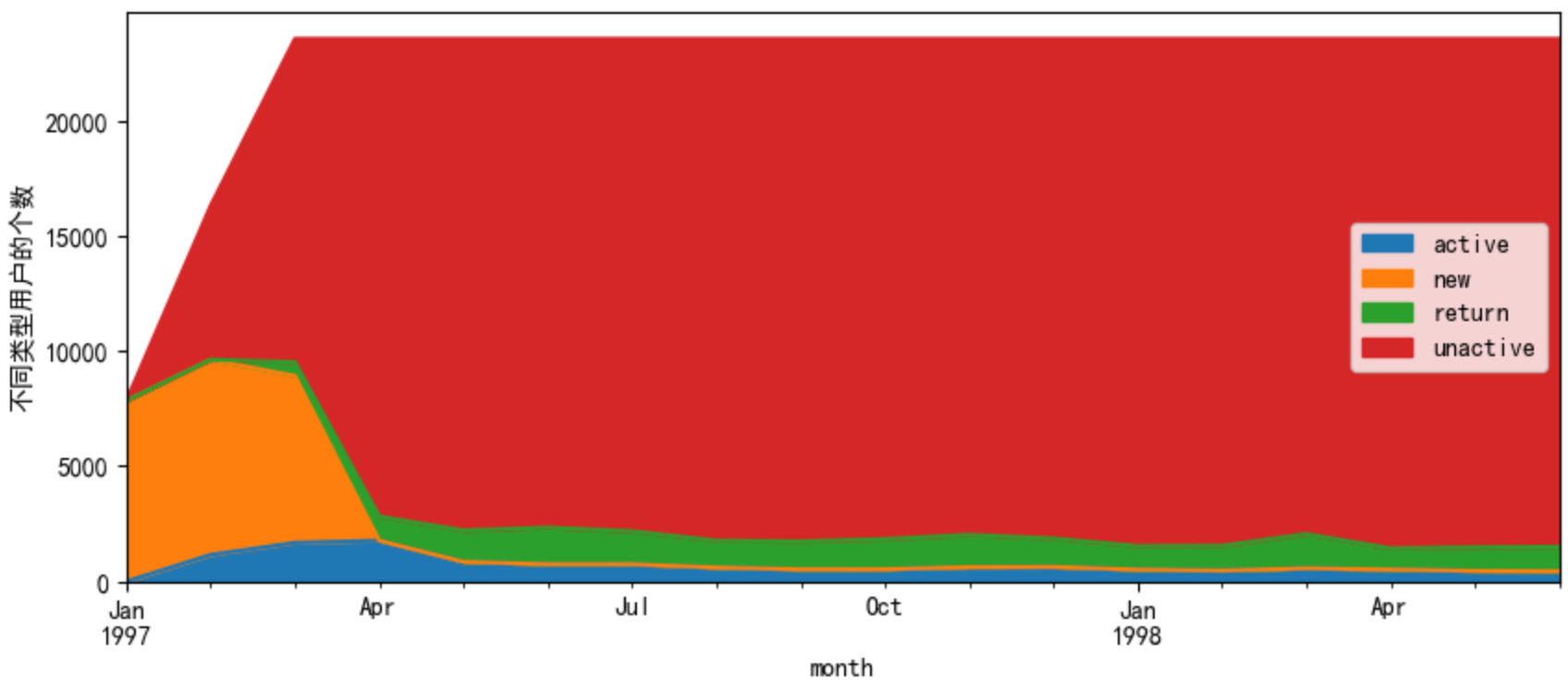
任务13:统计回流用户占比情况
# 每月中回流用户占比情况(占所有用户的比例)
plt.figure(figsize=(12,6))
# 默认对表格按列处理,所以rate最后得到的是四行数据,存放每个月不同类型用户占所有用户的比例
rate = purchase_states_ct.apply(lambda x:x/x.sum())
# 转置后列为用户类型,行为月份
rate.T.head()
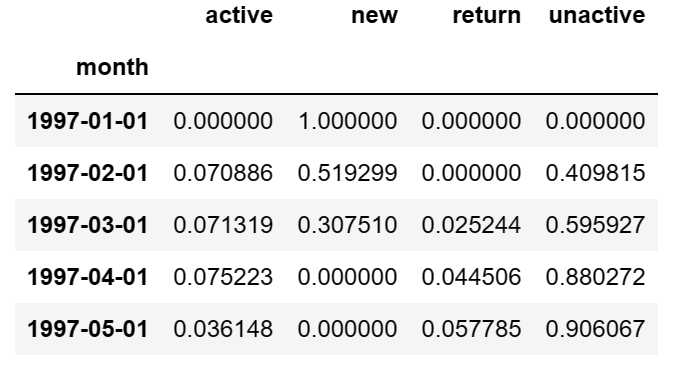
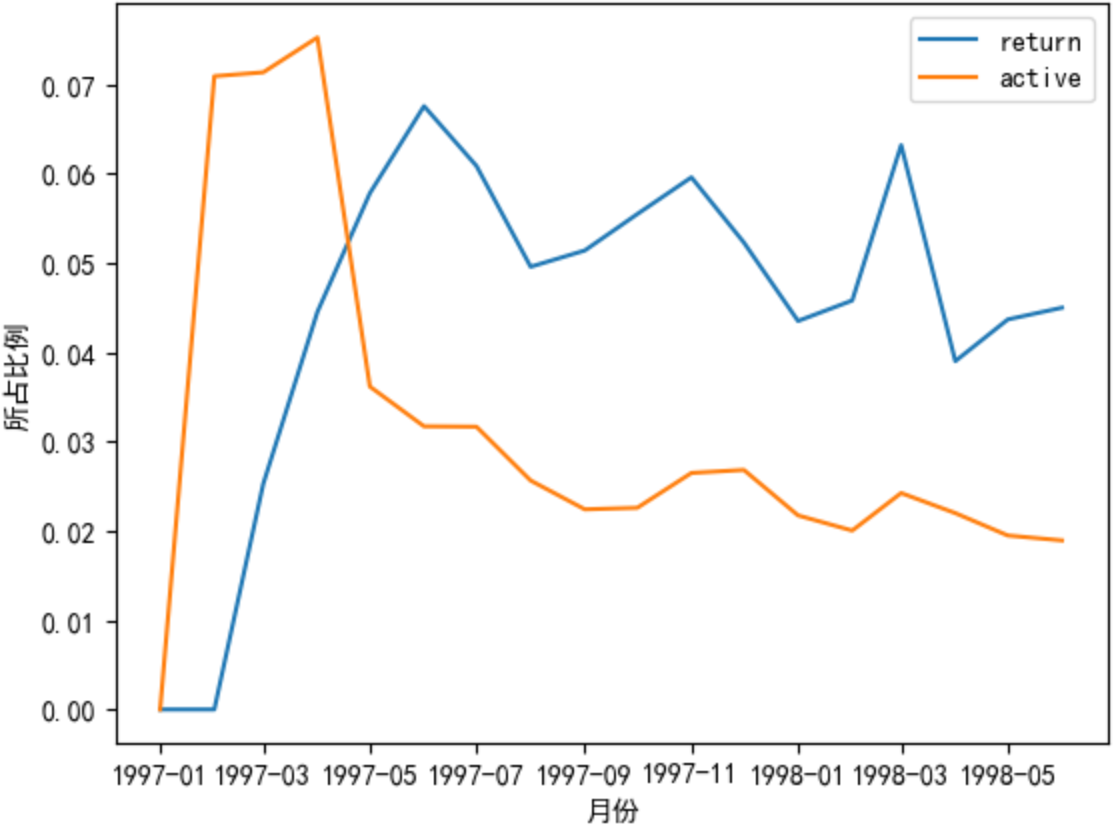
# pandas直接索引是按列进行取值的,所以绘制状态在不同月份的取值需要用到rate.T
# plot是折线图
plt.plot(rate.T['return'],label='return')
plt.plot(rate.T['active'],label='active')
# 增加图例
plt.legend()
plt.xlabel('月份')
plt.ylabel('所占比例')
plt.show()
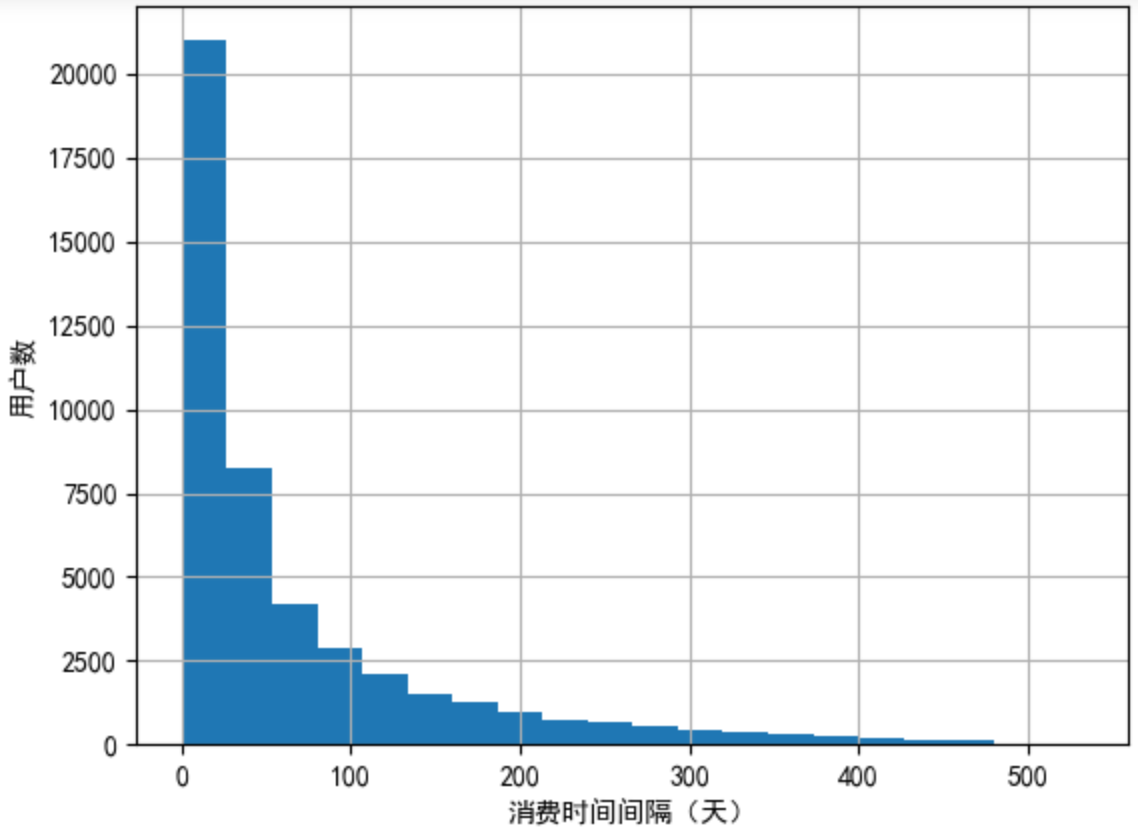
任务14:统计用户消费时间间隔
# shift()使得Series整体移动一个单位,如[0,1,2]经过shift后变[Nan,0,1]
# 按照用户ID分类后,用户下次消费时间减去上次消费时间即消费时间间隔
order_diff=data.groupby(by='user_id')['order_dt'].apply(lambda x:x-x.shift())
# 消费时间间隔转换为“天”单位,绘制直方图
(order_diff/np.timedelta64(1,'D')).hist(bins=20)
plt.xlabel('消费时间间隔(天)')
plt.ylabel('用户数')
plt.show()
任务15:统计用户生命周期
所谓生命周期即第一次消费与最后一次消费相隔的天数
# agg()函数内可放置多个聚合函数,此处是生成同一用户'order_dt'列的最小值列和最大值列
user_life = data.groupby(by='user_id')['order_dt'].agg(['min','max'])
user_life
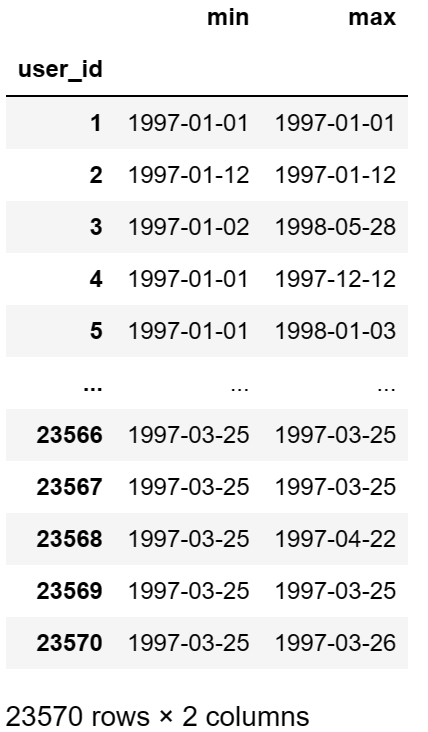
# 统计只消费过一次的人数和消费多次的人数,pie是饼图
# %.1f%%是比例保留一位小数,%%实际是一个百分号;radius是饼的半径
(user_life['max']== user_life['min']).value_counts().plot(kind='pie',autopct='%.1f%%',radius=0.8)
plt.legend(['只消费过一次的人','消费过多次的人'])
plt.show()
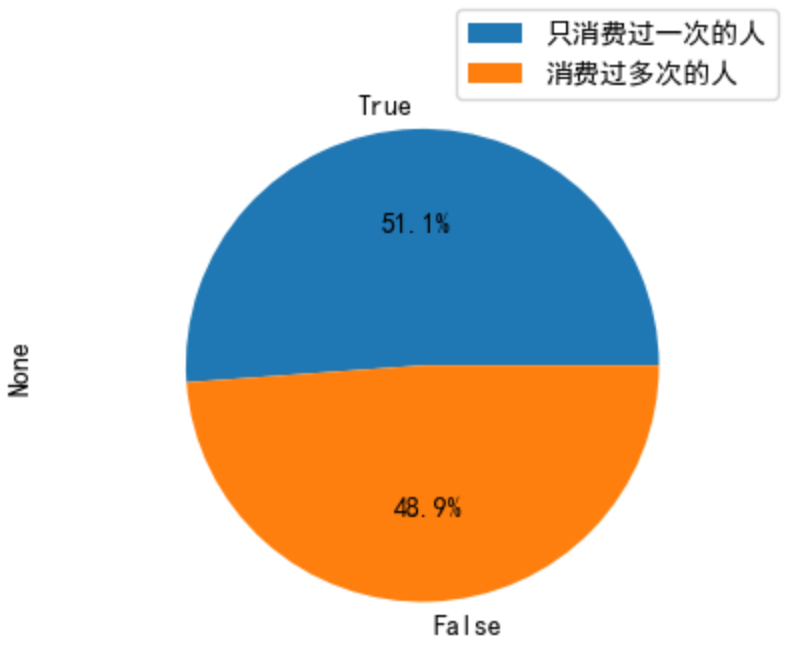
plt.figure(figsize=(10,5))
plt.subplot(121)
# 用户最晚消费的时间-最早消费的时间即为此用户生命周期,只消费过一次的用户生命周期长度为0
date_gap=(user_life['max']-user_life['min'])/np.timedelta64(1,'D')
date_gap.plot(kind='hist',bins=15)
plt.title('所有用户生命周期长度统计')
plt.xlabel('生命周期长度')
plt.ylabel('用户数')
plt.subplot(122)
date_gap[date_gap>0].plot(kind='hist',bins=15)
plt.title('多次消费的用户生命周期长度统计')
plt.xlabel('生命周期长度')
plt.ylabel('用户数')
plt.show()
任务16:分析复购率
复购率即当月多次消费的用户数所占当月有过消费的用户数的比例
# 任务11的透视表pivoted_counts存放了用户各个月份的购买情况
pivoted_counts
对上述DataFrame进行二次处理
- 当月购买次数大于1的标记为
1,意思为在当月有复购 - 当月购买次数等于1的标记为
0,意思为没有复购 - 当月根本没有消费记录的标记为
NaN
# lambda中第一个else后所有内容为一个整体
purchase_r = pivoted_counts.applymap(lambda x:1 if x>1 else np.nan if x==0 else 0)
purchase_r
# sum()得到当前月份所有复购用户数;count()得到当前月份所有有消费的用户数
# 二者相除即复购用户占所有消费用户的比例【注:count不会对Nan计数】
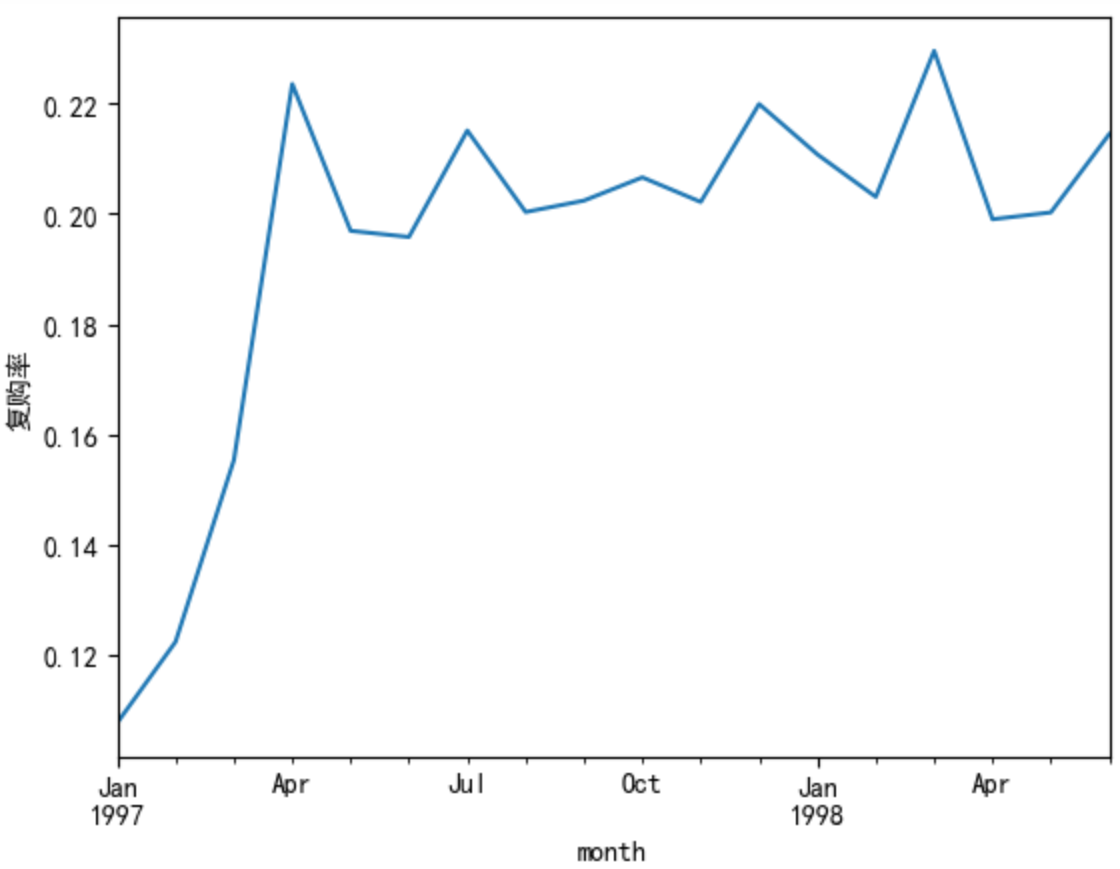
(purchase_r.sum()/purchase_r.count()).plot()
plt.ylabel('复购率')
plt.show()
任务17:分析回购率
回购率是指一段时间内【这里的一段时间是两个月】有多次消费的用户数占一段有过消费的用户数的比例,不过同一个月消费多次
# 任务11的最后的df_purchase对用户在每个月是否消费进行了处理
df_purchase
对上述DataFrame进行二次处理
- 如果当前月消费了,但是下个月没有消费,标记为
0,说明在这个月不属于回购用户 - 如果当前月没有消费标记为
NaN - 当前月消费了,下个月也消费了标记为
1,说明在这个月是回购用户
# 计算方式:在一个时间窗口内进行了消费,在下一个窗口内又进行了消费
def purchase_back(x):
status = [] # 存储用户回购率状态
# 1:回购用户 0:非回购用户(当前月消费了,下个未消费) NaN:当前月份未消费
for i in range(17):
# 当前月份消费了
if x[i] == 1:
if x[i+1]==1:
status.append(1) # 回购用户
elif x[i+1] == 0: # 下个月未消费
status.append(0)
else: # 当前月份未进行消费
status.append(np.NaN)
# for循环没有处理到最后一个元素,因此需要单独进行处理
status.append(np.NaN)
# 传进来的x是一行数据,因此要给其对应位置加上列名返回
return pd.Series(status,df_purchase.columns)
purchase_b=df_purchase.apply(purchase_back,axis=1)
purchase_b
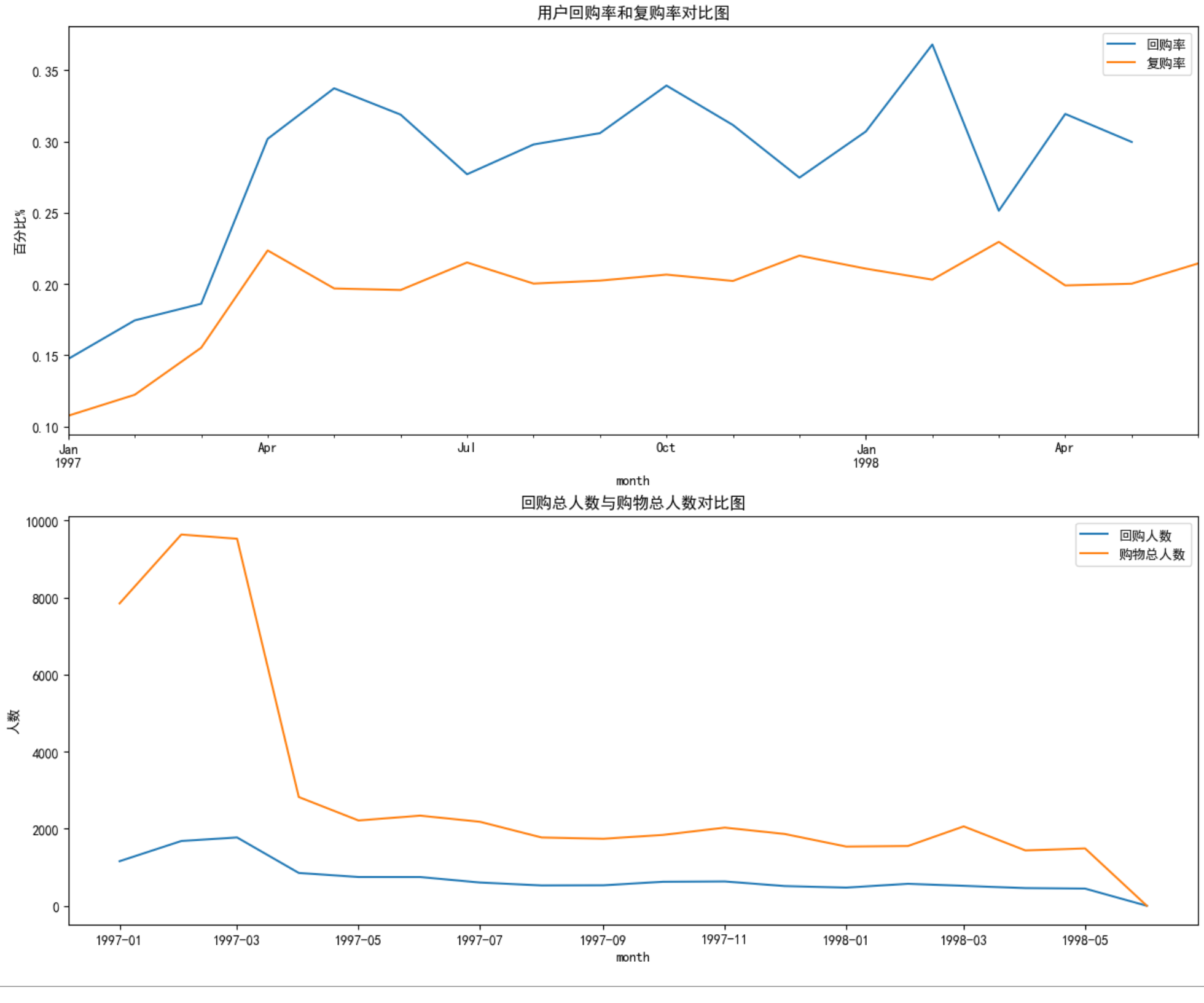
plt.figure(figsize=(15,12))
plt.subplot(211)
# 同样这里sum得到当前月份所有用户总共回购的次数,count得到当前月份所有用户有消费的次数,二者相除即为回购率
(purchase_b.sum() / purchase_b.count()).plot(label='回购率')
# 复购率
(purchase_r.sum()/purchase_r.count()).plot(label='复购率')
plt.legend()
plt.ylabel('百分比%')
plt.title('用户回购率和复购率对比图')
# 回购人数与购物总人数
plt.subplot(212)
plt.plot(purchase_b.sum(),label='回购人数')
plt.plot(purchase_b.count(),label='购物总人数')
plt.title('回购总人数与购物总人数对比图')
plt.xlabel('month')
plt.ylabel('人数')
plt.legend()
plt.show()




![[附源码]计算机毕业设计Python的桌游信息管理系统(程序+源码+LW文档)](https://img-blog.csdnimg.cn/ff4f0c8d31e24d629e35aa890ba50738.png)