文章目录
- 【Flink实时数仓】数据仓库项目实战 《五》流量域来源关键词粒度页面浏览各窗口汇总表 【DWS】
- 1.1流量域来源关键词粒度页面浏览各窗口汇总表(FlinkSQL)
- 1.1.1 主要任务
- 1.1.2 思路分析
- 1.1.3 图解
- 1.1.4 代码
【Flink实时数仓】数据仓库项目实战 《五》流量域来源关键词粒度页面浏览各窗口汇总表 【DWS】
设计要点:
(1)DWS层的设计参考指标体系;
(2)DWS层表名的命名规范为dws_数据域_统计粒度_业务过程_统计周期(window)
注:window 表示窗口对应的时间范围。
1.1流量域来源关键词粒度页面浏览各窗口汇总表(FlinkSQL)
1.1.1 主要任务
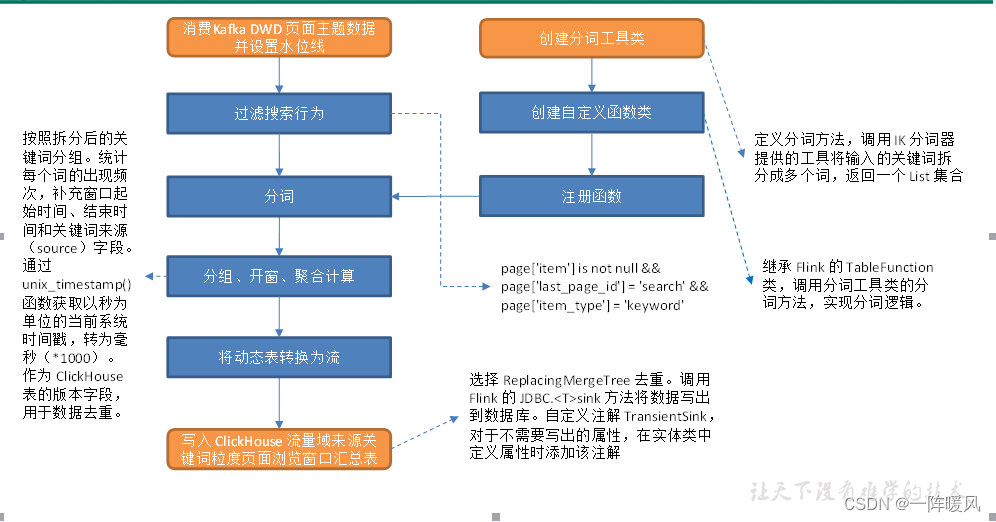
从 Kafka 页面浏览明细主题读取数据,过滤搜索行为,使用自定义 UDTF(一进多出)函数对搜索内容分词。统计各窗口各关键词出现频次,写入 ClickHouse。
1.1.2 思路分析
分词是个一进多出的过程,需要一个 UDTF 函数来实现,FlinkSQL 没有提供相关的内置函数,所以要自定义 UDTF 函数。此处将借助 IK 分词器完成分词。最终要将数据写入 ClickHouse,需要补充相关依赖,封装 ClickHouse 工具类和方法。
1.1.3 图解
1.1.4 代码
代码来自尚硅谷,微信关注尚硅谷公众号 回复: 大数据 即可获取源码及资料。
展示主流程代码。具体工具类及实现请下载源码。
package com.atguigu.app.dws;
import com.atguigu.app.func.SplitFunction;
import com.atguigu.bean.KeywordBean;
import com.atguigu.utils.MyClickHouseUtil;
import com.atguigu.utils.MyKafkaUtil;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
//数据流:web/app -> Nginx -> 日志服务器(.log) -> Flume -> Kafka(ODS) -> FlinkApp -> Kafka(DWD) -> FlinkApp -> ClickHouse(DWS)
//程 序: Mock(lg.sh) -> Flume(f1) -> Kafka(ZK) -> BaseLogApp -> Kafka(ZK) -> DwsTrafficSourceKeywordPageViewWindow > ClickHouse(ZK)
public class DwsTrafficSourceKeywordPageViewWindow {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 1.1 状态后端设置
// env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);
// env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);
// env.getCheckpointConfig().enableExternalizedCheckpoints(
// CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION
// );
// env.setRestartStrategy(RestartStrategies.failureRateRestart(
// 3, Time.days(1), Time.minutes(1)
// ));
// env.setStateBackend(new HashMapStateBackend());
// env.getCheckpointConfig().setCheckpointStorage(
// "hdfs://hadoop102:8020/ck"
// );
// System.setProperty("HADOOP_USER_NAME", "atguigu");
//TODO 2.使用DDL方式读取Kafka page_log 主题的数据创建表并且提取时间戳生成Watermark
String topic = "dwd_traffic_page_log";
String groupId = "dws_traffic_source_keyword_page_view_window_211126";
tableEnv.executeSql("" +
"create table page_log( " +
" `page` map<string,string>, " +
" `ts` bigint, " +
" `rt` as TO_TIMESTAMP(FROM_UNIXTIME(ts/1000)), " +
" WATERMARK FOR rt AS rt - INTERVAL '2' SECOND " +
" ) " + MyKafkaUtil.getKafkaDDL(topic, groupId));
//TODO 3.过滤出搜索数据
Table filterTable = tableEnv.sqlQuery("" +
" select " +
" page['item'] item, " +
" rt " +
" from page_log " +
" where page['last_page_id'] = 'search' " +
" and page['item_type'] = 'keyword' " +
" and page['item'] is not null");
tableEnv.createTemporaryView("filter_table", filterTable);
//TODO 4.注册UDTF & 切词
tableEnv.createTemporarySystemFunction("SplitFunction", SplitFunction.class);
Table splitTable = tableEnv.sqlQuery("" +
"SELECT " +
" word, " +
" rt " +
"FROM filter_table, " +
"LATERAL TABLE(SplitFunction(item))");
tableEnv.createTemporaryView("split_table", splitTable);
tableEnv.toAppendStream(splitTable, Row.class).print("Split>>>>>>");
//TODO 5.分组、开窗、聚合
Table resultTable = tableEnv.sqlQuery("" +
"select " +
" 'search' source, " +
" DATE_FORMAT(TUMBLE_START(rt, INTERVAL '10' SECOND),'yyyy-MM-dd HH:mm:ss') stt, " +
" DATE_FORMAT(TUMBLE_END(rt, INTERVAL '10' SECOND),'yyyy-MM-dd HH:mm:ss') edt, " +
" word keyword, " +
" count(*) keyword_count, " +
" UNIX_TIMESTAMP()*1000 ts " +
"from split_table " +
"group by word,TUMBLE(rt, INTERVAL '10' SECOND)");
//TODO 6.将动态表转换为流
DataStream<KeywordBean> keywordBeanDataStream = tableEnv.toAppendStream(resultTable, KeywordBean.class);
keywordBeanDataStream.print(">>>>>>>>>>>>");
//TODO 7.将数据写出到ClickHouse
keywordBeanDataStream.addSink(MyClickHouseUtil.getSinkFunction("insert into dws_traffic_source_keyword_page_view_window values(?,?,?,?,?,?)"));
//TODO 8.启动任务
env.execute("DwsTrafficSourceKeywordPageViewWindow");
}
}
clickhouse表结果输出
hadoop102 :) select * from dws_traffic_source_keyword_page_view_window;
SELECT *
FROM dws_traffic_source_keyword_page_view_window
Query id: f9c8f52a-d23d-4250-b39b-c6d3621da797
┌─────────────────stt─┬─────────────────edt─┬─source─┬─keyword──┬─keyword_count─ ┬────────────ts─┐
│ 2022-06-14 23:44:40 │ 2022-06-14 23:44:50 │ search │ 口红 │ 3 │ 1669218554000 │
│ 2022-06-14 23:44:40 │ 2022-06-14 23:44:50 │ search │ 图书 │ 2 │ 1669218554000 │
└─────────────────────┴─────────────────────┴────────┴──────────┴─────────────────────────┘
idea输出
Split>>>>>>> +I[图书, 2022-11-23T20:55:34]
Split>>>>>>> +I[图书, 2022-11-23T20:55:36]
Split>>>>>>> +I[口红, 2022-11-23T20:55:37]
Split>>>>>>> +I[口红, 2022-11-23T20:55:39]
Split>>>>>>> +I[口红, 2022-11-23T20:55:39]
>>>>>>>>>>>>> KeywordBean(stt=2022-11-23 20:55:30, edt=2022-11-23 20:55:40, source=search, keyword=图书, keyword_count=2, ts=1671454538000)
>>>>>>>>>>>>> KeywordBean(stt=2022-11-23 20:55:30, edt=2022-11-23 20:55:40, source=search, keyword=口红, keyword_count=3, ts=1671454538000)
>```







![[Vue3]自定义指令实现组件元素可拖拽移动](https://img-blog.csdnimg.cn/c1228dcc49b842e98df6827dec716e20.png#pic_center)




