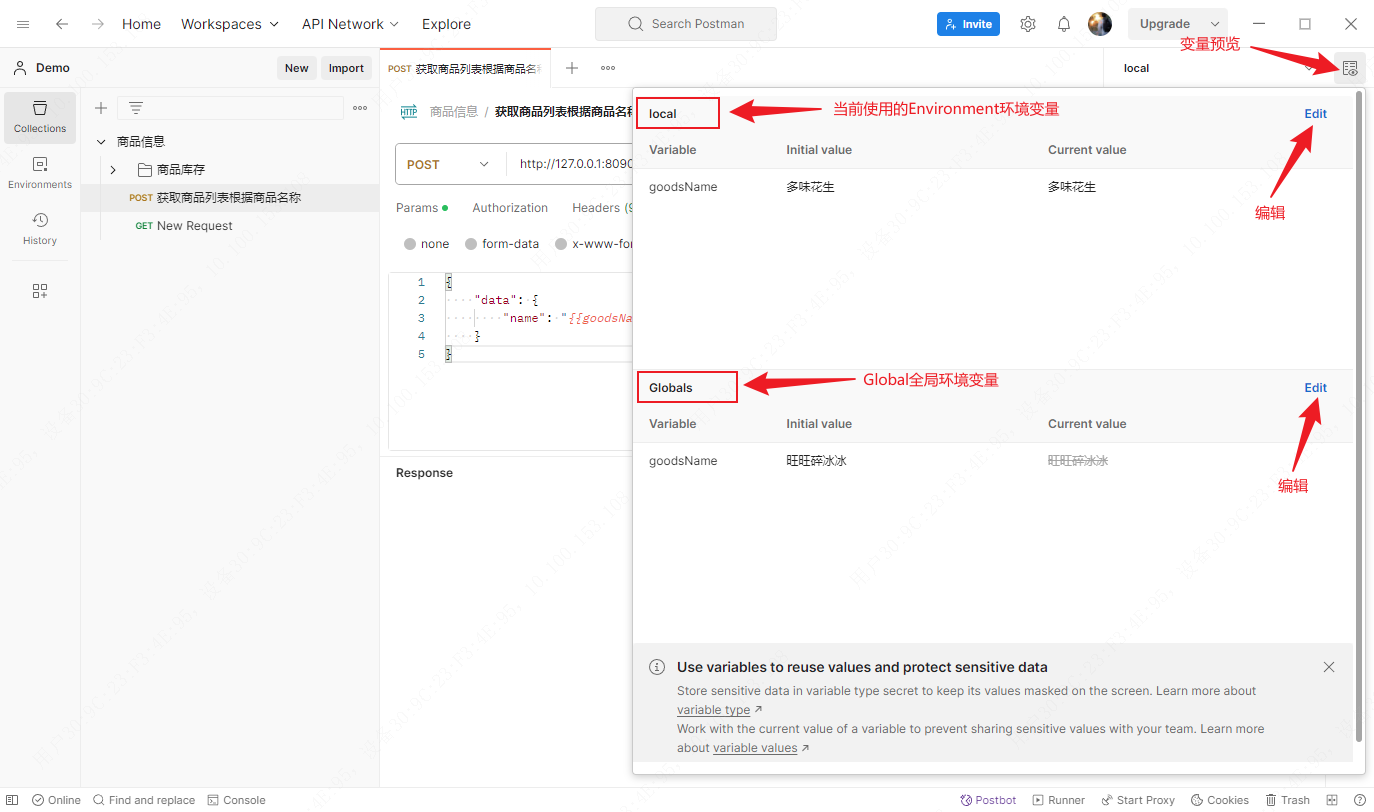
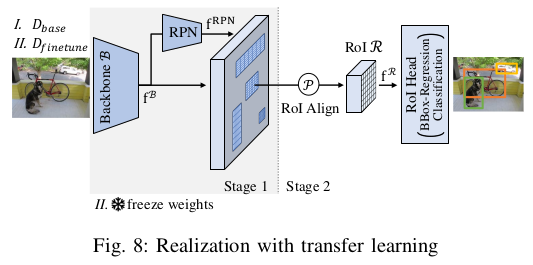
paper: Few-Shot Object Detection: A Comprehensive Survey (CVPR2021)
meta learning需要复杂的情景训练,而迁移学习仅需在一个single-branch结构上做两步训练。
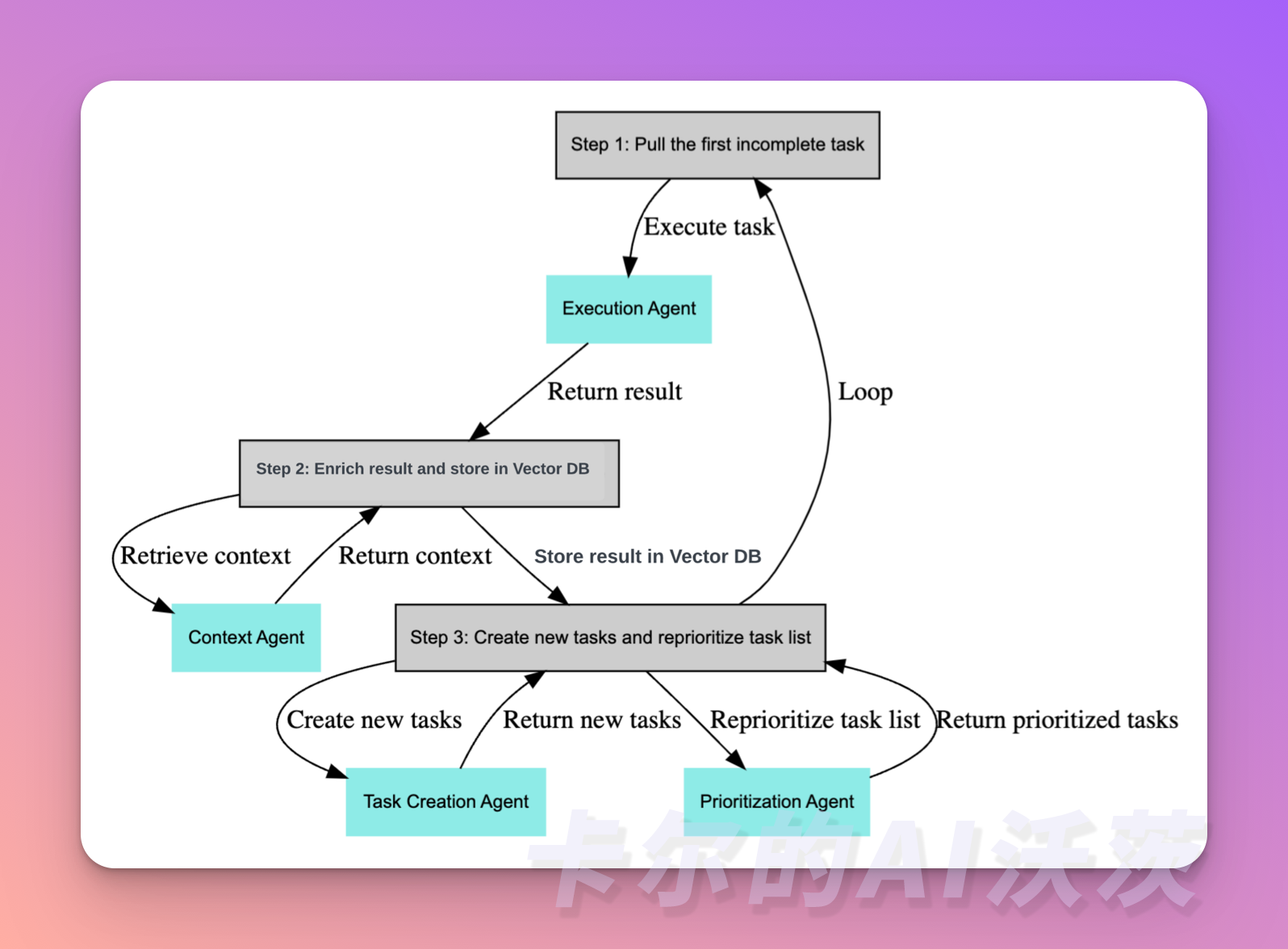
常用的结构是Faster R-CNN,下面是Faster R-CNN的结构图。
RPN的修改
当样本数量很少时,RPN是error增大的关键地方。
比如,当只有一个样本,模型会propose 多个ROI和目标的groud truth匹配,估计这个类别的方差,类似于random cropping augmentation.
即使RPN miss掉一个ROI,performance也会有很大的下降。
因此,CoRPN中修改了RPN,把RPN中一个二分类器(前景背景)换成了M个二分类器。目的是至少有一个分类器能识别到相关的前景ROI。
FORD+BL在RPN之前加上了ASPP以增加感受野。
TFA则是在第2个训练阶段,固定RPN的权重,很多迁移学习也是这么做的。
在Retentive R-CNN中,发现在第一训练阶段(只用
D
b
a
s
e
D_{base}
Dbase训练)RPN会抑制新类别
C
n
o
v
e
l
C_{novel}
Cnovel的ROI,
固定RPN的权重,只训练RPN的最后一层,也就是区分前景背景的一层,对于在第2训练阶段提高RPN是足够的。这一点也有其他paper论证。
FSCE和CIR则是把通过NMS的proposal数量加倍,以得到新类别的更多proposal.
但是这会造成计算量的加大,FSCE为此只采样了ROI head中一半的proposal用于计算损失。依据是观察到扔掉的那一半在第2训练阶段都是背景。
总结:为了减少错误的检测,RPN的权重在第2阶段用
D
n
o
v
e
l
D_{novel}
Dnovel训练时需要调整,另外通过NMS的proposal数量可以增加。
FPN的修改
不再固定RPN的权重,FSCE中展示了在第2训练阶段微调FPN的权重比固定它的权重有提高。理论依据是认为base数据集的内容不能迁移到新的类别,需要微调权重。
MPSR中提到FPN的scales并不能补偿新类别小样本scale的稀疏性,因此,在refinement branch中,会应用data augmentation解决这个问题。
CIR设计了一个context模块扩大FPN的感受野,也提到了变化的scale问题,尤其是提高了小目标的检测率。
总结:FPN的权重也应该调整。
增加新类别样本之间的差异性
在新类别的样本数量有限,这些类别的样本差异也有限的情况下,一些方法试图增加新类别样本的差异性。
MPSR的refinement branch中,每个目标用正方形的window抠图,然后resize到不同的scales。这样做可以增加样本在size上的差异性。
FSOD-UP,CME中也用了这一策略。
另外,FSSP也用了类似的方法,在辅助分支中把目标做augmentation, 比如scale和平移。

Halluc中提出幻觉网络(hallucinator network),它会学习如何给新类别产生更多的训练样本。
怎么做到的呢。
用到了ROI head中的新类别样本的特征,把它们扩充,用分享的base数据集的类内特征方差。
LVC用到的data augmentation包括颜色抖动,随机抠图,马赛克,给每个ROI提取的特征作dropout,很大地提高了performance.
FSCE描述了用了随机抠图的augmentation和RPN中多个ROI proposals的相似性。因此,增加每个新类别instance的proposed ROI数量也可以提高样本的差异性,类似于随机抠图的augmentation.
增加样本的差异性主要应用于新的类别中样本极度缺少的场景。
如果包含新的类别的未标记的数据很多,也可以用半监督学习的方法增加样本的数量。
N-PME在微调模型之后伪标记base数据集,为找到base数据集中的
C
n
o
v
e
l
C_{novel}
Cnovel(新的类别)。然后在下一阶段的微调中会用到这些伪标注的样本,当然也用到新类别的小样本,这样会提高样本数量。不过这些伪标注的目标框不够准确,因此在计算损失时时要忽略的。
LVC进一步改进了这一措施,还是用的伪标注,不过要验证一下这一样本是不是真的属于
C
n
o
v
e
l
C_{novel}
Cnovel,同时还会纠正一下不够精确的目标框。用了ViT进行验证,训练用了一个叫DINO的自学习方法。有了这些高质量的附加样本,微调模型时就不再需要固定某部分的权重,而是直接end-to-end微调。
这种半监督的方法在COCO,VOC数据集中是可以的,但是在现实中,如果要检测某个稀有的类别或是医疗图像,这个方法就会有问题。
总结:在样本极度稀少的情况下,data augmentation或是伪标注可以提高检测准确率,因为增加了训练样本的差异性。
迁移base和新数据的knowledge
LSTD用了一个相似base类别的soft assignment, 对于新类别的权重,由base类别的权重进行初始化以迁移base数据的knowledge.
AttFDNet用base数据集检测器的参数来初始化新类别的检测器,而且用了一种imprinting初始化方法。
CGDP+FSCN也用了imprinting初始化方法。
为了学习和利用base和novel数据集视觉和语义上的相似性,在第2训练阶段,
UniT迁移了目标框regression和分类部分的权重(base to novel)。
SRR-FSD用语义word embedding表示每个类别。图像中的目标会映射到这个embedding空间,在视觉和语义上去学习新的类别。
FADI也融入了语义信息,用到了WordNet来估计base和novel类别的语义相似性。每个新类别应只与一个base类别关联,然后除了ROI head中的FC 层,其他权重都固定,进入第2阶段的微调。这一就可以把新类别的特征分布与base类别相关联。但是也会造成类别的混淆。所以还需要一个识别和区分的步骤。(听起来很复杂)
总结:给新的类别初始化权重的时候,与它语义上最近似的base类别的knowledge可以被迁移。
保持base类别的performance
很多模型会遇到“忘性”问题,训练新的类别之后就会不记得之前用base数据训练的类别。
当然在第2训练阶段可以再用base数据训练,不过跟之前相比效果还是有所下降。
为此,有一些改进方法:
Retentive R-CNN把RPN,ROI proposal中的分类头,classification分别都复制了一遍,分别用作base和novel类别的分类。
在novel head的finetuning阶段,用了cosine分类器,以平衡base和novel类别的特征差异。
同时,把区分base类别的RPN和ROI head的权重固定,这样就可以保持在base类别的performance.
(这样做模型就变大了)
BPMCH在finetuning阶段固定backbone
B
b
a
s
e
B_{base}
Bbase和分类head. 然后用一个新的backbone
B
n
o
v
e
l
B_{novel}
Bnovel用于提取新类别的特征。
MemFRCN中,除了在ROI head应用基于softmax的分类器,每个类别的代表性特征向量都会被学习和储存,以记住base类别,即使在finetuning阶段ROI head的权重被修改。
在推理阶段,前面提取的特征可以用来和输入的类别特征用cosine相似度进行比较,这有点类似于meta learning dual-branch的support vectors.
总结:为解决“忘性”问题,需要考虑base类别和新类别梯度之间的角度。
修改训练目标
可通过修改损失函数引导检测器集中在前景区域,提升多个branch间的一致性,提升特征的类内,类间方差。
还可以限制梯度流。
1)增加损失函数项
LSTD在损失函数中加入了抑制背景和迁移知识正则项,帮助检测器聚焦于目标。
CGDP+FSCN认识到未标注的新类别是个问题,引入了半监督损失项。
AttFDNet提出2个损失项,最大化相同类别instance的cosine相似度,处理未标注的instance的问题。
FADI介绍了set-specialized margin loss, 扩大类别内的差异性。对不同的margin用不同的scale因子。
2)辅助分支的Loss
类似于meta learning方法TIP,FSOD-UP用了一致性损失使两个分支近似。用了KL-Divergence损失。
MPSR的两个分支用共享的权重实现松耦合,两个分支都对损失有贡献。
FSCE在ROI head中引入新的分支。用了一个FC层作为对比分支,以估计相似性。在对比分支中用了contrastive proposal encoding loss用于训练,增加同类别的cosine相似性,减少不同类别的相似性。
DMNet用了辅助分类分支,比较特征的欧式距离。这些特征embedding是通过度量学习得到的。
修改梯度流
DeFRCN中,想在两个训练阶段都更新backbone, 但是他们发现了矛盾的地方。
RPN和ROI head的目的是不一样的,RPN学习与类别无关的region proposal, 但是ROI head又要区分类别。
大量的实验表明要停止RPN到backbone的梯度流,缩放ROI head到backbone的梯度流。
在第一训练阶段,把ROI head的梯度流缩放到0.75,backbone会学习少一点。
在第2训练阶段,训练的是base和novel的并集,需要把上述梯度缩放到0.01,基本上就freeze backbone了。
这样做很大程度地提高了performance, 尤其在第2训练阶段。
CFA提出一个新的梯度更新方法,用到
D
b
a
s
e
D_{base}
Dbase和
D
n
o
v
e
l
D_{novel}
Dnovel样本中的梯度angle.
修改训练方法
FORD+BL提出一上来先不把K个样本都用上,每个类别先用一个样本finetuning一次。然后再把K shot都用上,再finetuning,会提高performance.
TD-sampler在finetuning阶段用了batch采样策略。
总结:当优化了梯度流,修改类内样本差异性后,loss也要被修改。
在辅助分支,对比性的loss可以提高特征的区分度,类似于2 branch meta learning.
用Attention
Attention会加强特征。
方法有FSOD-UP,在prototype和RPN的输出中用到soft attention.
FSSP先用self-attention模块处理图片,然后把这个处理过的input送给one-stage detector. 这样检测器可以把注意力集中在图片重要的部分。
AttFDNet结合了top-down和bottom-up attention. top-down通过监督方式学习。 bottom-up由显着性预测模型计算(BMS,SAM)
修改模型结构
1)基于Faster R-CNN
2)基于one-stage detector
比较早的方法LSDT,结合了SSD的目标框regression方法和Faster R-CNN的分类思想。
CoTrans用了SSD作为one-stage detector, 认为SSD中多尺度的感受野提供了丰富的信息,对knowledge迁移比较重要。
AttFDNet也用了SSD检测器,但是加了2个attention分支,使检测器集中到图片中重要的部分,用了6个prediction heads预测不同scale的目标框和类别。
DMNet结合SSD和YOLO的设计理念提出了一个one-stage detector. 但是对定位和分类用了2个解耦的分支,认为这种解耦有助于少量样本。
FSSP用了YOLOv3, 用了a lot of effort,
比如自注意力机制,辅助分支中包含了网络的复制,辅助分支input data的augmentation, 新增加了损失函数。
使得网络在非常少的样本(10 shot)时效果比TFA要好。
总结:基于Faster R-CNN的检测器,score细化可以减少FP。one-stage检测器可以通过辅助分支做data augmentation.
目前比较好的迁移学习方法
DeFRCN中认为与类别无关的定位任务(RPN)和区分类别的任务(ROI head) 刚好相反,因此,要停止RPN到backbone的梯度,缩放ROI head到backbone的梯度。然后训练检测器的所有部分。一个模块在ROI head中消除掉高分的FP类别,这是分类中平移不变特征和定位的平移协变特征矛盾的地方。
CFA可以应用与DeFRCN的顶部,用来解决finetuning阶段出现的“忘性”问题,这种问题常出现在base类别和novel类别梯度的角度为钝角时。CFA会储存K个base类别样本,用来在finetuning阶段计算base类别的梯度。当base和novel的梯度角为钝角时,两个类别的梯度要被平均,重新赋予权重,不是钝角时新类别的梯度就可以back propagation, 不用担心会出现“忘性”问题。
FADI在finetuning之前把每个新的类别都和一个base类别相关联,通过WordNet测量它们的语义相似度。然后网络被用来训练对齐特征的分布。虽然这样会降低新类别的类内方差,不过会让base和novel混淆,因此后面还跟着一个区分它们的步骤。
总结
迁移学习的训练流程比较简单,不像元学习中用到复杂的情景训练。通过结合一些方法,使得可以finetune尽可能多的模块(比如前面提到的方法),这样迁移学习可以达到SOTA水平。
与元学习的比较
元学习的single-branch近年来用的比较少,而且performance不如dual-branch. 所以比较的是元学习的dual-branch和迁移学习。它们都很有前景,且都可以融合其他训练策略的idea.

可以看到迁移学习的“忘性”比较大,训练了新的就会忘了旧的,很难保持base数据集的效果。
另外,one-stage detector的效果不如faster R-CNN, 大部分的工作都是基于Faster R-CNN的。


![[Python进阶] Pyinstaller打包模式](https://img-blog.csdnimg.cn/867a3be3df8a485fb013a8b6f19d179f.png)