一、Hadoop概述
1.1 Hadoop是什么
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,Hadoop通常是指一个更广泛的概念—Hadoop生态圈。
1.2 Hadoop三大发行版本
- Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
1)Apache版本最原始(最基础)的版本,对于入门学习最好。2006
官网地址:http://hadoop.apache.org
下载地址:https://hadoop.apache.org/releases.html
2)Cloudera内部集成了很多大数据框架,对应产品CDH。2008
官网地址:https://www.cloudera.com/downloads/cdh
下载地址:https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_6_download.html
3)Hortonworks文档较好,对应产品HDP。2011
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
1.3 Hadoop优势
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。

2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。

3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。

4)高容错性:能够自动将失败的任务重新分配。

1.4 大数据技术生态体系
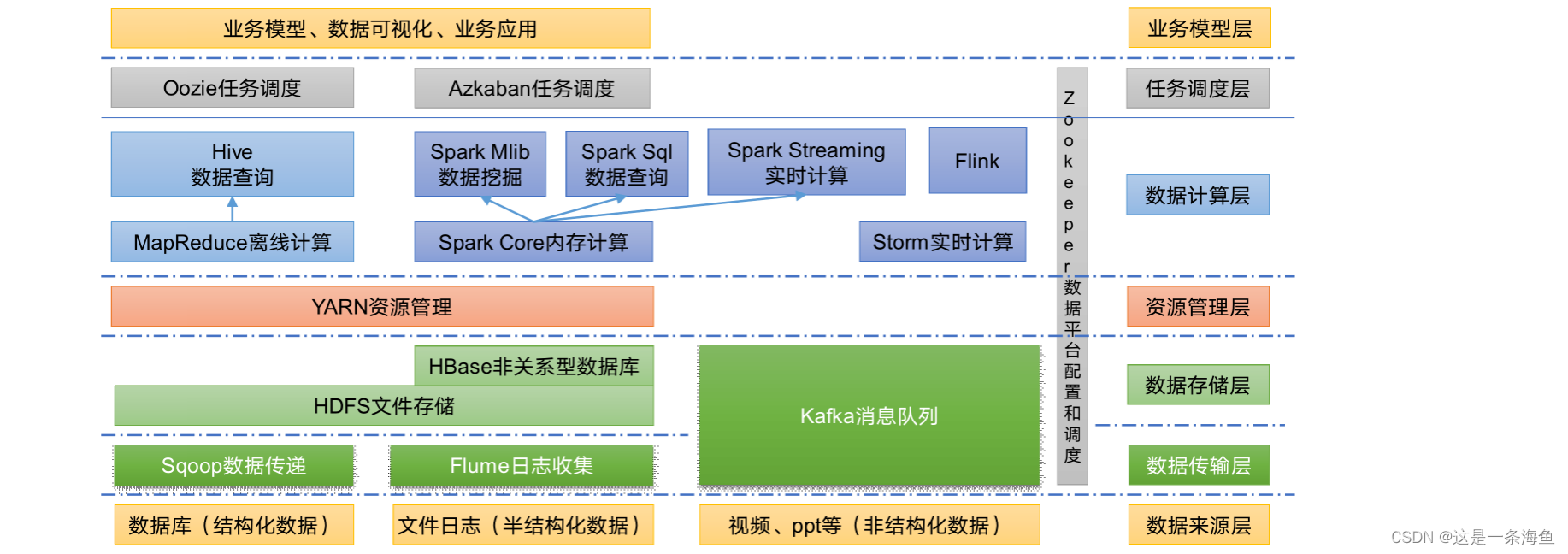
图中涉及的技术名词解释如下:
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
5)Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6)Oozie:Oozie是一个管理Hadoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。hbase可以理解为为hdfs建立了索引,查询不走map-reduce,直接走自己的表,hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑(只是个逻辑表)
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
二、 Hadoop组成
在Hadoop1.x时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度apReduce只负责运算。
Hadoop:3.x在组成上没有变化。
2.1 HDFS架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、 文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
2.2 YARN架构概述
Yet Another Resource Negotiator简称YARN ,另一种资源协调者,是Hadoop的资源管理器。
1)ResourceManager(RM):整个集群资源(内存、CPU等)的老大
2)NodeManager(NM):单个节点服务器资源老大
3)ApplicationMaster(AM):单个任务运行的老大
4)Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
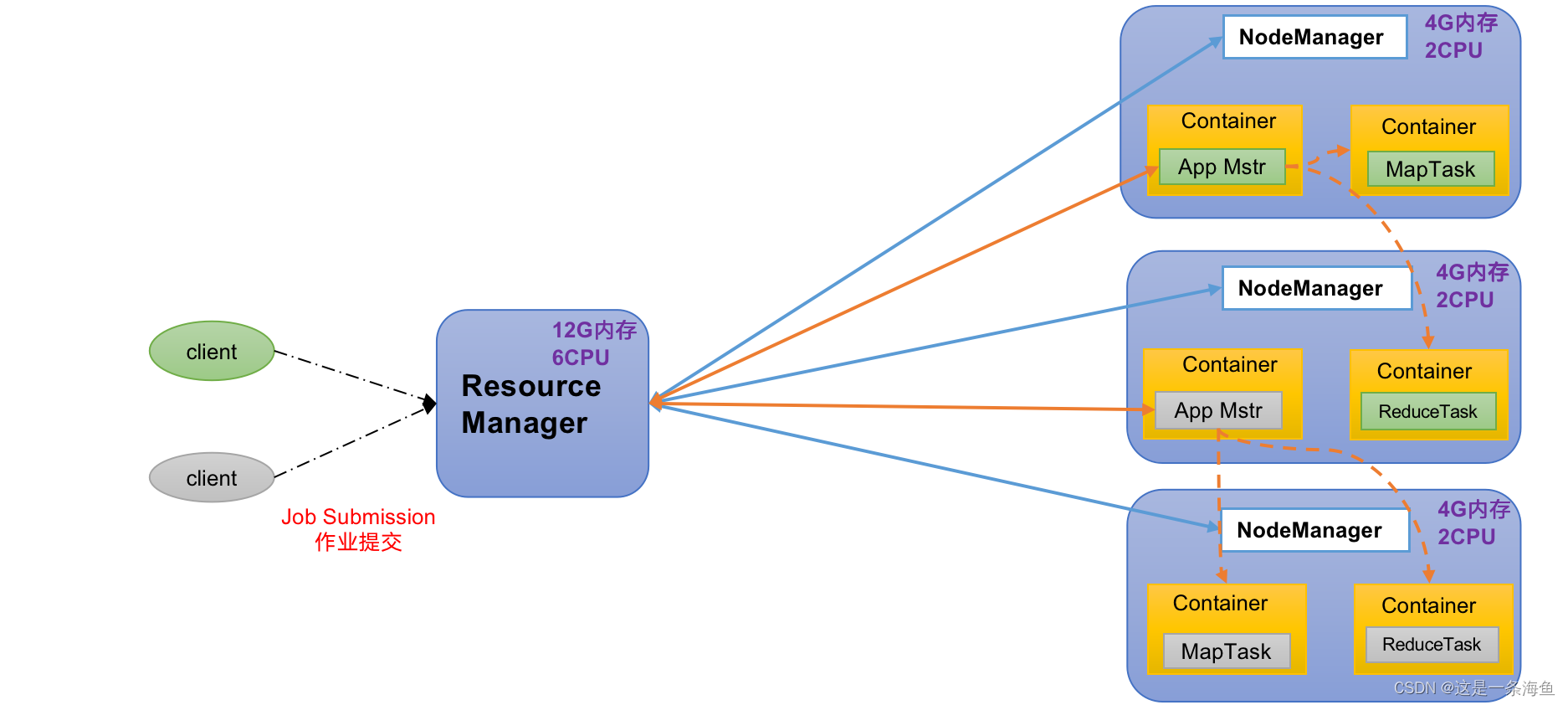
说明1:客户端可以有多个
说明2:集群上可以运行多个ApplicationMaster
说明3:每个NodeManager_上可以有多个Container
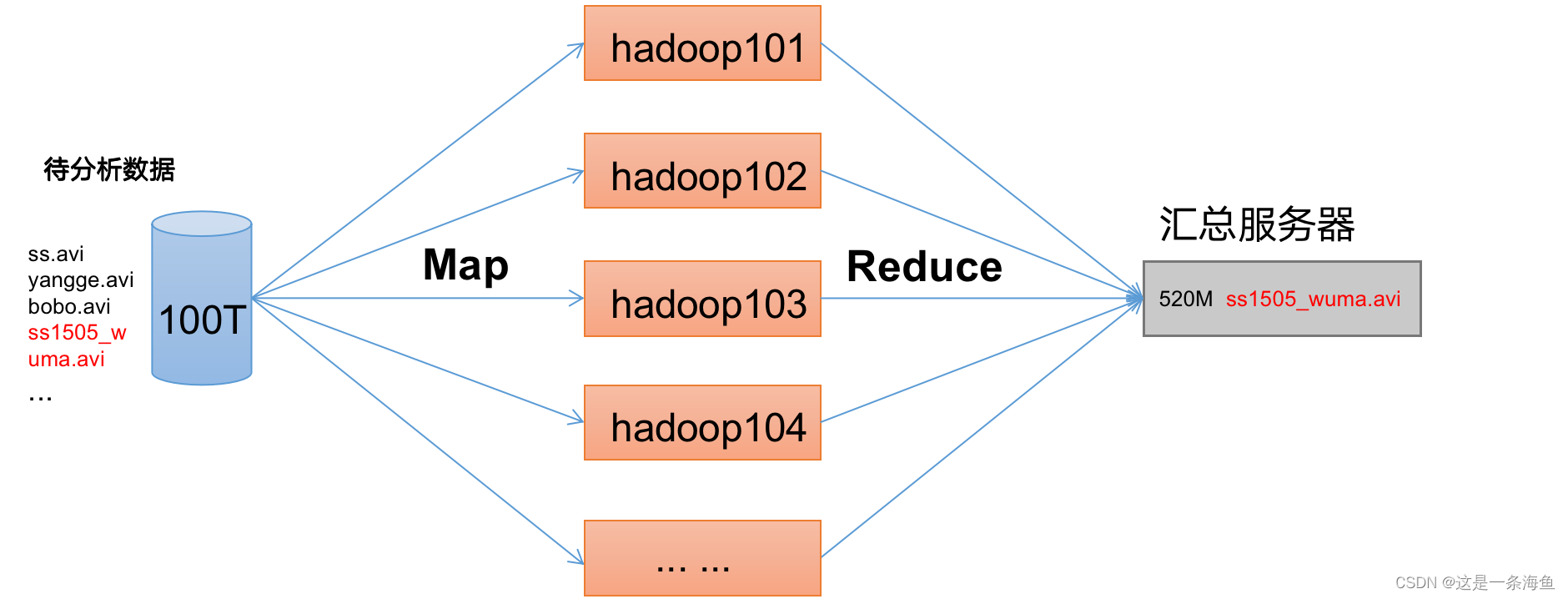
2.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
三、完全分布式运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
1、本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
2、伪分布式模式:也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
3、完全分布式模式:多台服务器组成分布式环境。生产环境使用
3.1 Hadoop的安装
Hadoop需要java环境才能运行
[root@master local]# ll
-rw-r--r-- 1 root root 338075860 12月 16 13:41 hadoop-3.1.3.tar.gz
[root@master local]# tar -zxvf hadoop-3.1.3.tar.gz
[root@master local]# vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
[root@master local]# source /etc/profile
3.2 集群部署规划
NameNode和SecondaryNameNode不要安装在同一台服务器
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| 服务器 | master | node1 | node2 |
|---|---|---|---|
| HDFS | NameNode,DataNode | DataNode | SecondaryNameNode,DataNode |
| YARN | NodeManager | ResourceManager,NodeManager | NodeManager |
上面是
上面三个服务器的/etc/hosts文件添加下面的内容
192.168.93.230 master
192.168.93.231 node1
192.168.93.232 node2
解决服务器ip地址换了,Hadoop对应配置文件也要改
hadoop是集群,不安装ssh就会导致各服务器间无法访问,会出这种错的。
建议:每台机器都要装ssh并且设定“无密码访问”。
每台机器都要配置ssh免密登陆,这里也配置masterssh免密登陆为例
[root@master ~]# ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
[root@master ~]# ssh-copy-id master
[root@master ~]# ssh-copy-id node1
[root@master ~]# ssh-copy-id node2
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
3.3 配置集群
1)核心配置文件 core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
2)HDFS配置文件hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
</configuration>
3)YARN配置文件 yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
4)MapReduce配置文件mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5 )群起集群配置workers,在该文件中增加如下内容:
master
node1
node2
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
在集群上分发配置好的Hadoop配置文件
3.4 启动集群
(1)如果集群是第一次启动,需要在master节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
[root@master hadoop-3.1.3]# hdfs namenode -format
(2)启动HDFS
[root@master hadoop-3.1.3]# sbin/start-dfs.sh
(3)在配置了ResourceManager的节点(hadoop103)启动YARN
[root@node1 hadoop-3.1.3]# sbin/start-yarn.sh
(4)Web端查看HDFS的NameNode
浏览器中输入:http://master:9870
(5)Web端查看YARN的ResourceManager
浏览器中输入:http://node1:8088
[root@master hadoop-3.1.3]# hadoop fs -mkdir /input
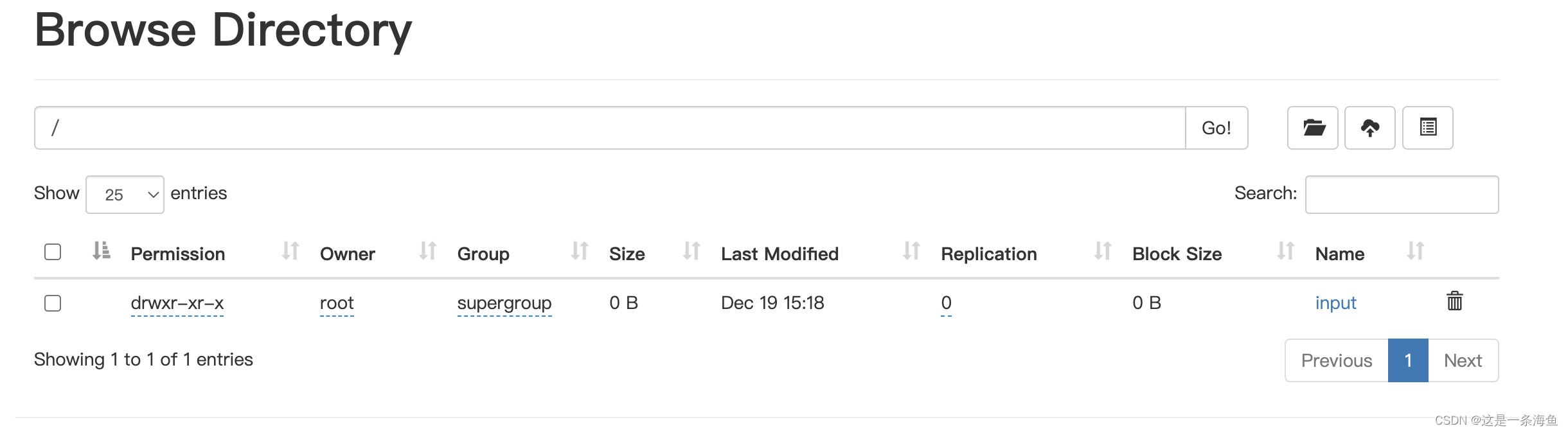
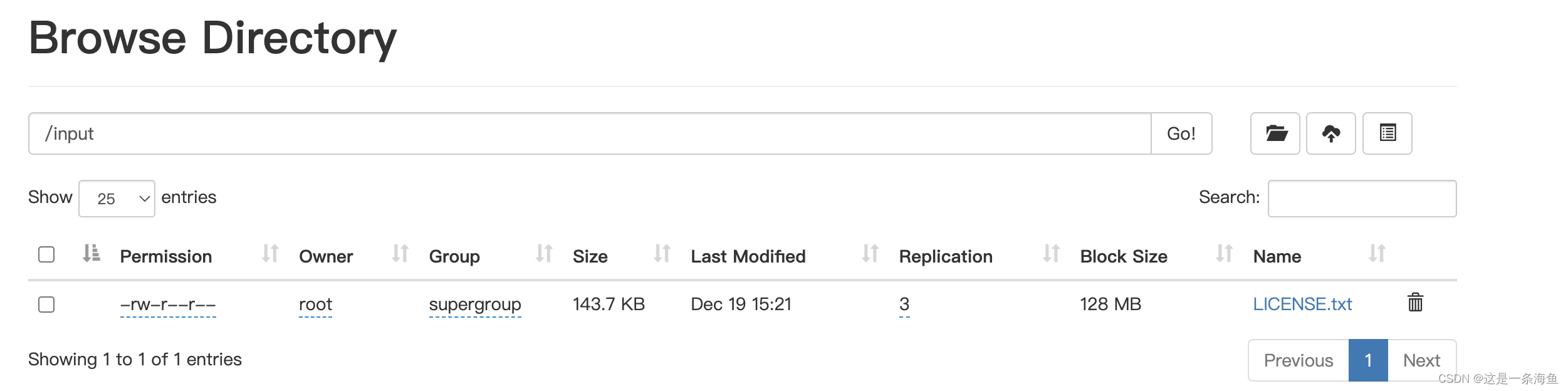
[root@master hadoop-3.1.3]# hadoop fs -put LICENSE.txt /input
2022-12-19 15:21:05,655 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1\杀死进程
2、删除每个节点上的data logs
然后开始启动集群
3.5 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下
[root@master hadoop-3.1.3]# vim mapred-site.xml
1、在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
把分发到各个节点
2、node1中重启ResourceManager
[root@node1 hadoop-3.1.3]# sbin/stop-yarn.sh
[root@node1 hadoop-3.1.3]# sbin/start-yarn.sh
3、在master启动历史服务器
[root@master hadoop-3.1.3]# mapred --daemon start historyserver
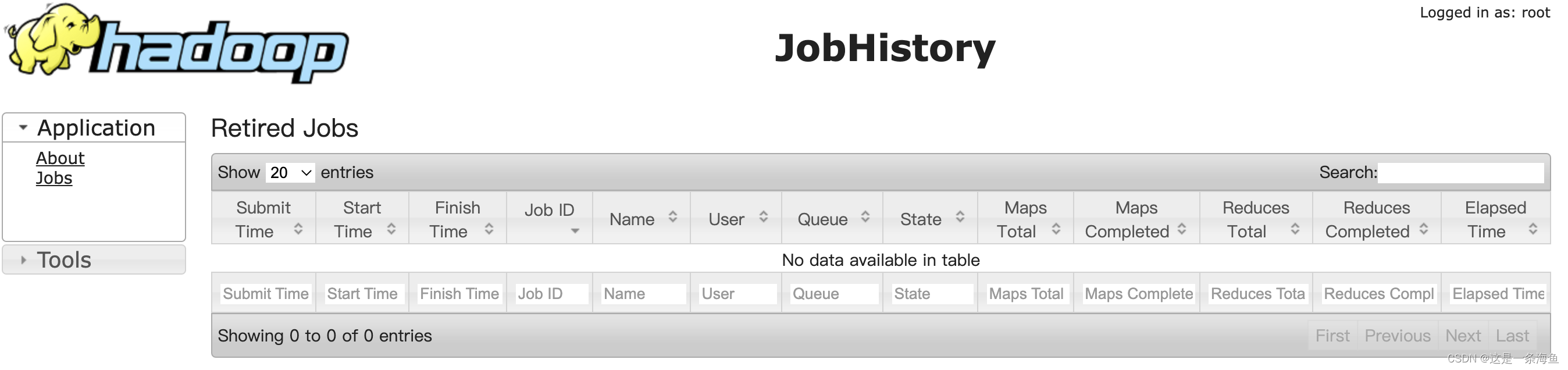
4、查看JobHistory http://master:19888/jobhistory
3.6 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
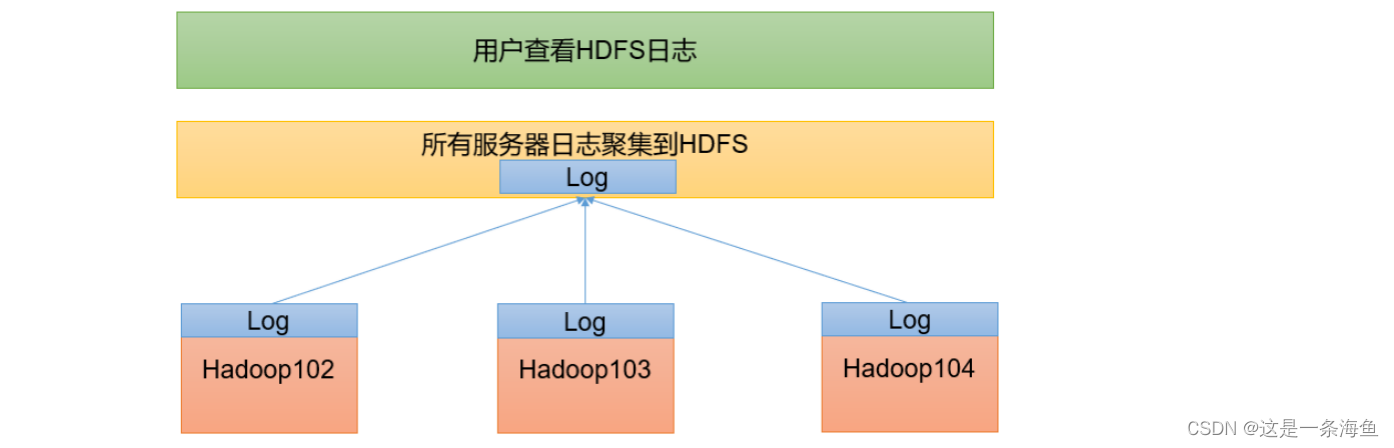
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
- 配置yarn-site.xml,在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
3)在node1中重启关闭NodeManager 、ResourceManager
[root@node1 hadoop-3.1.3] sbin/stop-yarn.sh
[root@node1 hadoop-3.1.3] sbin/start-yarn.sh
4)在master中重启HistoryServer
[root@master hadoop-3.1.3] mapred --daemon stop historyserver
[root@master hadoop-3.1.3] mapred --daemon start historyserver
3.7 常用端口号说明
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
![[Vue3]自定义指令实现组件元素可拖拽移动](https://img-blog.csdnimg.cn/c1228dcc49b842e98df6827dec716e20.png#pic_center)





![[附源码]计算机毕业设计Node.js宠物商店管理系统(程序+LW)](https://img-blog.csdnimg.cn/981d9d72aadb4e538cd005d96fda4ccd.png)