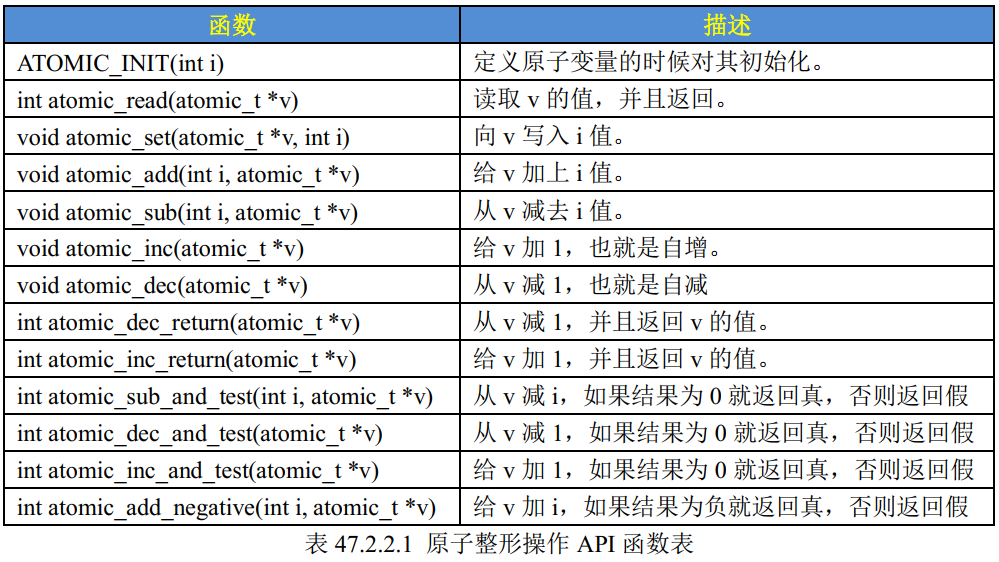
基础学习--原子操作
typedef struct {
int counter;
} atomic_t;
static __always_inline void
atomic_set(atomic_t *v, int i)
{
instrument_atomic_write(v, sizeof(*v));
raw_atomic_set(v, i);
}
static __always_inline void
raw_atomic_set(atomic_t *v, int i)
{
arch_atomic_set(v, i);
}
#define arch_atomic_read(v) __READ_ONCE((v)->counter)
#define arch_atomic_set(v, i) __WRITE_ONCE(((v)->counter), (i))
#define __WRITE_ONCE(x, val)
do {
*(volatile typeof(x) *)&(x) = (val); //typeof返回变量的类型
} while (0)结构体
spinlock -> raw_spinlock -> arch_spinlock_t(qspinlock)
typedef struct spinlock {
union {
struct raw_spinlock rlock; //自旋锁的核心成员是raw_spinlock锁
};
} spinlock_t;
typedef struct raw_spinlock {
arch_spinlock_t raw_lock; //raw_lock的核心成员是arch_spinlock_t,它与具体架构有关
} raw_spinlock_t;
//ARM64位架构中,为qspinlock
typedef struct qspinlock {
union {
atomic_t val; //原子变量
#ifdef __LITTLE_ENDIAN
struct {
u8 locked; //最优先持锁标志,即当unlock之后,这个位被置位的CPU最先持锁,1和0
u8 pending; //表示这个锁是否被人持有,1被人持有,0无人持锁
};
struct {
u16 locked_pending; //由locked 和 pending构成
u16 tail; //由idx CPU构成,用来标识等待队列最后一个节点
};
} arch_spinlock_t;
相关API的实现
调用逻辑:
spin_lock_* -> raw_spin_lock_* -> _raw_* -> arch_spin_lock(架构相关,qspinlock)
spin_lock_init
自旋锁的初始化:就是做个spinlock->raw_spinlock->arch_spinlock_t的转换,然后把arch_spinlock_t的val初始化为0
include\linux\spinlock_types_up.h
# define spin_lock_init(_lock)
do {
spinlock_check(_lock);
*(_lock) = __SPIN_LOCK_UNLOCKED(_lock);
} while (0)
spin_lock
加锁:直接加锁,如果成功则返回,失败,则进入qspinlock的具体实现方式上
static __always_inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();//关抢占
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
}#define spin_lock_irqsave(lock, flags) \
do { \
raw_spin_lock_irqsave(spinlock_check(lock), flags); \
} while (0)
static inline unsigned long __raw_spin_lock_irqsave(raw_spinlock_t *lock)
{
unsigned long flags;
local_irq_save(flags);//关本地中断,并保存中断状态
preempt_disable();//关抢占
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
return flags;
}
#define arch_spin_lock(l) queued_spin_lock(l)
#define arch_spin_trylock(l) queued_spin_trylock(l)
#ifndef queued_spin_lock
static __always_inline void queued_spin_lock(struct qspinlock *lock)
{
int val = 0;
if (likely(atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL)))
return;
queued_spin_lock_slowpath(lock, val);//这里就是直接获取锁失败的情况,需要自旋等待了。
}
qspinlock
qspinlock的实现是建立在MCS锁的理论基础上。
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked;
};mcs_spinlock中next成员就是构建单链表的基础,spin等锁的操作只需要将所属自己CPU的mcs_spinlock结构体加入单链表尾部,然后spin,直到自己的mcs_spinlock的locked成员置1(locked初始值是0)。unlock的操作也很简单,只需要将解锁的CPU对应的mcs_spinlock结构体的next域的lock成员置1,相当于通知下一个CPU退出循环。
以4个CPU的系统为例说明。首先CPU0申请spinlock时,发现链表是空,并且锁是释放状态。所以CPU0获得锁。

CPU1继续申请spinlock,需要spin等待。所以将CPU1对应的mcs_spinlock结构体加入单链表尾部。然后spin等待CPU1对应的mcs_spinlock结构体locked成员被置1。

当CPU2继续申请锁时,发现链表不为空,说明有CPU在等待锁。所以也将CPU2对应的mcs_spinlock结构体加入链表尾部。

当CPU0释放锁的时候,发现CPU0对应的mcs_spinlock结构体的next域不为NULL,说明有等待的CPU。然后将next域指向的mcs_spinlock结构体的locked成员置1,通知下个获得锁的CPU退出自旋。MCS lock头指针可以选择不更新,等到CPU2释放锁时更新为NULL。

通过以上步骤,我们可以看到每个CPU都spin在自己的使用变量上面。