目录
软件包管理器
概念理解
用法示例 - 以yum为例
vim
模式的切换
常用操作
插件和配置
gcc/g++
gdb
make / makefile
软件包管理器
概念理解
在Linux下安装软件的话,一个比较原始的办法是下载程序的源代码,然后进行编译,进而得到可执行程序,然后就可以运行这个软件了。但是这种做法太麻烦了,于是就有些人把一些常用的软件提前编译好,做成软件包,放到服务器上,通过包管理器可以很方便的获取到这个编译好的软件包,直接进行安装即可。而负责管理这些软件包的东西就叫软件包管理器。软件包和软件包管理器之间的关系,就好比手机上的 "App" 和 "应用商店" 这样的关系。
yum的实现过程大致可以概括为如下步骤:
此引用部分摘自:linux网络服务-部署yum仓库 - 掘金
先在yum服务器上创建 yum repository(仓库),在仓库中事先存储了众多rpm包,以及包的相关的元数据文件(放置于特定目录repodata下,内含有软件的依赖关系和软件的位置),当yum客户端利用yum/dnf工具进行安装时包时,会自动下载repodata中的元数据,查询元数据是否存在相关的包及依赖关系,自动从仓库中找到相关包下载并安装
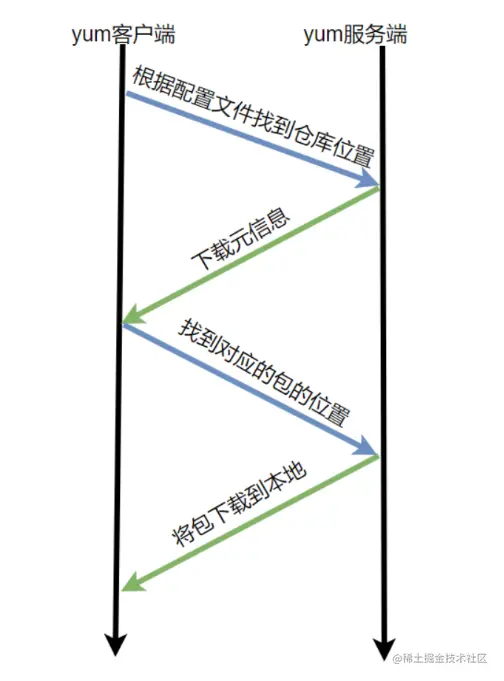
而不同的Linux发行版本通常使用不同的软件包管理器来管理和安装软件包。以下是一些常见的 Linux发行版本及其对应的软件包管理器:
Ubuntu 和 Debian,使用 apt 作为软件包管理器。
CentOS 和 Red Hat,使用 yum 或 dnf 作为软件包管理器。在较新的版本中(CentOS 8和Red Hat 8及其之后),dnf 更为常见。
Fedora,使用 dnf 作为默认的软件包管理器。
openSUSE,使用 zypper 作为软件包管理器。
Arch Linux,使用 pacman 作为软件包管理器。
Manjaro,也是基于 Arch Linux,所以同样使用 pacman 作为软件包管理器。
Linux Mint,通常使用 apt,类似于 Ubuntu。
注意,这些发行版本中的软件包管理器可能会有不同的命令和选项,因此在使用时需要查阅相关文档或指南以获取详细信息。
用法示例 - 以yum为例
yum源
yum仓库,俗称yum源,用于存放各种的软件包。需要安装软件的计算机连接到指定yum仓库来安装软件包。yum源就相当于一个软件包管理器,类似于一个软件管家,而yum源又有分为本地yum源和网络yum源,绝大多数情况下我们使用的是网络yum源。
如果我们安装的是官方的系统镜像的话,其使用的网络yum源基本都是国外官方的,但国外的下载软件速度非常慢,很多情况下都无法下载。所以国内一些大公司会做镜像,以同步国外的软件。 所以我们可以配置使用国内的yum镜像源(如腾讯源、阿里源、华为源等)。
配置yum源的操作 - 以centos7,腾讯源为例:
首先我们直接网上搜索“腾讯源”,然后打开这个网站:腾讯软件源 (tencent.com)
接着找到centos,然后点击右侧的查看:
然后按照网页提示就可以直接安装了,它已经贴心的把指令告诉我们了。CentOS (tencent.com) 腾讯软件源
https://mirrors.tencent.com/help/centos.html

yum的语法格式
yum [options] [command] [package ...]参数说明:
options: 选项,选项包括-h,-y,-q等等。
command: 要进行的操作。
package: 安装的包名。
常用选项:
-h:显示帮助信息
-y:对所有的提问都回答“yes”
-c:指定配置文件
-q:安静模式
-v:详细模式
-d:设置调试等级(0-10)
-e:设置错误等级(0-10)
-R:设置yum处理一个命令的最大等待时间
-C:完全从缓存中运行,而不去下载或者更新任何头文件
yum的常用命令
| 命令 | 作用 |
|---|---|
| yum list | 查询所有可安装的软件包 |
| yum list <package_name> | 查询指定软件包的安装情况 |
| yum info | 查询所有可安装软件包的详细信息 |
| yum info <package_name> | 查询指定软件包的详细信息 |
| yum list updates | 列出所有可更新的软件清单 |
| yum list installed | 列出所有已安装的软件清单 |
| yum update | 更新所有软件包(更新所有包同时,也更新软件和系统内核) |
| yum -y upgrade | 更新所有软件包(只更新所有包,不更新软件和系统内核) |
| yum update <package_name> | 更新指定软件包 |
| yum install <package_name> | 安装指定软件包 |
| yum remove <package_name> | 删除指定软件包 |
| yum search <keyword> | 查找指定软件包 |
| yum makecache | 刷新缓存。把服务器的包信息下载到本地电脑缓存起来,makecache建立一个缓存。以后用install时就在缓存中搜索,提高了速度。配合yum -C search xxx使用,不用联网检索就能查找软件信息。 |
| yum makecache fast | 将软件包信息提前在本地索引缓存,用来提高搜索安装软件的速度,执行这个命令可以提升yum安装的速度。 |
| yum clean / yum clean all | 清除缓存目录下的软件包及旧的 headers。yum 会把下载的软件包和header存储在cache中而不自动删除。可以使用yum clean指令清除索引缓存和下载包的缓存。 |
| yum clean packages | 清除缓存目录下的软件包 |
| yum clean headers | 清除缓存目录下的 headers |
| yum clean oldheaders | 清除缓存目录下旧的 headers |
vim
注意,这里只是简单的解释vim的一些基础用法,使得我们可以快速上手使用vim。如果想要更深层次的学习vim,可以自行探索,这里我推荐一个很不错的教程:(这个人的主页也有很多关于vim的相关内容,感兴趣的话可以好好看看)Learn-Vim(the Smart Way) 中文翻译![]() https://github.com/wsdjeg/Learn-Vim_zh_cn
https://github.com/wsdjeg/Learn-Vim_zh_cn
如果觉得上面的内容太多了,也可以看一下这个:
Vim 命令速查表 - Chloneda - 博客园 (cnblogs.com)![]() https://www.cnblogs.com/chloneda/p/vim-cheatsheet.html当然,也可以参考这张很经典的图片:
https://www.cnblogs.com/chloneda/p/vim-cheatsheet.html当然,也可以参考这张很经典的图片:
模式的切换
下面就让我们来快速上手使用vim。首先,vim有很多模式,不同的模式下对应着不同的功能,虽然vim的模式有十几个但实际生活中最常用的也就3个:normal(命令)模式、command(底行)模式、insert(插入)模式,当然还有诸如v-block(视图)模式、replace(替换)模式等。
可以说,命令模式是vim中最基础的模式。首先,进入vim时默认的就是命令模式。而且,想要切换到其它模式,是必须在命令模式下进行的。下面就让我们来了解一下如何切换到其它模式。
首先,在命令模式下按i、a或o是可以进入到插入模式的,i是从当前光标下开始,a是光标后移一个,o是在下面另开一行。插入模式下就可以进行我们正常的写入了。在命令模式下按 shift+; 也就是打出冒号 ':' 就可以进入到底行模式。vim的一些操作,比如退出就是需要在低行模式下进行的。
按 Ctrl+v 是进入视图模式(v是大小写都可以),其中在视图模式下按shift+i、a、o等是在视图模式下进入插入模式,视图模式下可以批量对文本进行操作。输入大写的R(即shift+r)是进入到替换模式。替换模式下,每次输入的字符都会替换掉光标所在位置的字符。而对于任何模式下回到命令模式的情况,都是只需要按键盘左上角的Esc即可。

常用操作
0、进入vim
# 直接启动vim
vim
# 打开单个文件
vim file
# 同时打开多个文件
vim file1 file2 file3 ...1、进入到插入模式
i 在当前位置生前插入
I 在当前行首插入
a 在当前位置后插入
A 在当前行尾插入
o 在当前行之后插入一行
O 在当前行之前插入一行
s 删除当前字符并进入插入模式
S 删除当前行并进入插入模式
2、光标的移动
h 左移一个字符,nh 左移n个字符
j 下移一个字符,nj 下移n个字符
k 上移一个字符,nk 上移n个字符
l 右移一个字符,nl 右移n个字符
上面的这四个hjkl就对应着键盘右侧的 ←↓↑→ 方向键。gg / [[ 移动到文件头
G(shift + g) / ]] 移动到文件尾nG 移动到第n行
:n 移动到第n行
0 数字0,移动到本行第一个字符上,
功能键HOME 移动到本行第一个字符,同0健。
^ (shitf+6) 移动到本行第一个非空白字符上
$ (shitf+4) / 功能键END 移动到行尾n$ 移动到下面n行的行尾
(n)w 向后移动1(n)个单词,光标停在单词首部,如果已到行尾,则转至下一行行首。
(n)b 向前移动1(n)个单词,光标停在单词首部
(n)e 同w,只是光标停在单词尾部
(n)ge 同b,只是光标停在单词尾部
(n)fx 找到当前行,光标后的第1(n)个为x的字符
(n)F 同f,只不过是反向查找。
Ctrl + e 向下滚动一行
Ctrl + y 向上滚动一行
Ctrl + d 向下滚动半屏
Ctrl + u 向上滚动半屏
Ctrl + f 向下滚动一屏
Ctrl + b 向上滚动一屏
3、复制、剪切和粘贴
yiw 复制(yank)当前单词
yw 复制从当前光标的位置到下一个单词的开头
yb 复制从当前光标的位置到上一个单词的末尾
yy 复制整行(包括换行符)
4yy 复制4行(包括换行符)
y$ 复制从当前光标的位置到行尾
(n)x 剪切光标处连续的1(n)个字符
(n)X 剪切当前字符的前1(n)个字符
(n)dl 剪切后1(n)个字符,dl=x
(n)dh 剪切前1(n)个字符,dh=X
(n)d 剪切当前行开始的1(n)行,通常还需要再回车一次
(n)dd 剪切当前1(n)行
(n)dj 剪切上1(n)行
(n)dk 剪切下1(n)行
(n)d$ 剪切1(n)行当前字符之后的所有字符
(n)d^ 剪切从光标到当前1(n)行的开头
(n)D 剪切当前字符至行尾,D=d$
dG 从光标删除到文件尾 (d 是删除行, G 是文件尾, 连起来就是从光标行删除到文件尾)
:beg,nd 剪切beg至n行(最后的d是指令部分)
:beg,$d 剪切beg行至以后所有的行
p 小写,粘贴在光标之后
P 大写,粘贴在光标之前
4、替换操作
substitute命令,将指定字符串替换为目标字符串。通常我们一般一般使用的是命令的缩写形式:s,具体使用格式如下:
:[range] s/search/replace/[flags] [count]如果我们想要将所有出现的字符都替换成给定字符,可以在命令中使用g(global)标记,例如
:s/from/to/g如果没有在命令中指定范围,那么默认范围是当前行。范围指定的用法示例如下:
# 在第10行知第20行每行前面加四个空格 :10,20 s/^/ /g # 把当前行中的I替换为We。命令中的i标记,是用于指定区分大小写的。 :s/I/We/gi # 将文中所有的字符串idiots替换成managers :1,$s/idiots/manages/g #通常我们会在命令中使用%指代整个文件做为替换范围 :%s/search/replace/g # 在第5至第15行间进行替换 :5,15s/dog/cat/g # 只在当前行在内的以下4行内进行替换 :s/helo/hello/g4 # 只在当前行至文件结尾间进行替换 :.,$s/dog/cat/g # 只在后续9行内进行替换 :.,.+8s/dog/cat/g
- 参考:VIM学习笔记 替换(Substitute) - 知乎 (zhihu.com)
s/old/new/ 用old替换new,替换当前行的第一个匹配
s/old/new/g 用old替换new,替换当前行的所有匹配
%s/old/new/ 用old替换new,替换所有行的第一个匹配
%s/old/new/g 用old替换new,替换整个文件的所有匹配
(n)ra 光标之后的1(n)个字符替换为a(r是命令,a是具体的字符)
R 从光标所在处开始替换字符,按 esc 键结束。也就是replace模(n)~ 也就是shift+`(Esc下面),将从光标位置之后的1(n)个字符转换大小写
5、文件操作
:w 保存不退出
:q 不保存退出
:wq 保存退出
:q! 强制不保存退出,不保存数据
:wq! 强制保存退出
:open file 在新窗口中打开文件
:split file 切换到下一个文件
:bn 切换到上一个文件
:bp 切换到上一个文件
6、多窗口操作
在底行模式下可以以多窗口的方式打开一个新文件,具体操作形式如下
:sp file 以纵向显示的方式打开file文件
:vsp file 以横向向显示的方式打开file文件
:vs file 以横向显示的方式打开file文件
在多窗口模式的常用操作如下
| 命令 | 关键词联想 | 功能 |
|---|---|---|
| Ctrl w w | window | 切换到下一个窗口。 |
| Ctrl w h/← | window | 切换到左边的窗口。 |
| Ctrl w j/↓ | window | 切换到下边的窗口。 |
| Ctrl w k/↑ | window | 切换到上边的窗口。 |
| Ctrl w l/→ | window | 切换到右边的窗口。 |
| Ctrl w r | reverse | 互换窗口。 |
| Ctrl w c | close | 关闭当前窗口。(但是不能关闭最后一个窗口) |
| Ctrl w q | quit | 退出当前窗口。(如果是最后一个窗口,则关闭vim编辑器) |
| Ctrl w o | other | 关闭其他窗口 |
7、常用的set命令
:set number " 显示行号
:set nu " 显示行号
:set nonumber " 关闭行号
:set showcmd " 显示输入的命令
:set noshowcmd " 不显示输入的命令
:set tabstop=4 " 设置 tab space 为4个空格
:set ts=4 " 同 tabstop
:set expandtab " 将tab替换为指定数量的空格
:set autoindent " 设置为自动缩进
:set background=dark " 设置背景颜色
:set guifont=consolas:h14 " 设置字体为 consolas,字号为14
:set history=700 " 设置保存命令的行数
:set autoread " 设置当文件变化时,自动读取新文件
:set wrap " 启动折行
:set nowrap " 禁止折行
" 切换文件格式,ff是 fileformat 的缩写
:set ff=unix " 将文件切换为 unix 格式,每行以 "\n" 结尾
:set ff=dos " 切换为 Windows 格式,每行以 "\r\n" 结尾
" 设置编码格式
:set encoding=utf-8 " 设置 vim 展示文本时的编码格式
:set fileencoding=utf-8 " 设置 vim 写入文件时的编码格式
:set filetype=html " 设定文件类型,方便语法高亮
:set hlsearch " 高亮显示搜索结果
:set paste " 设置为 paste 模式,在粘贴前设置该模式,可以避免各种 auto-formating
:set nopaste " 切换回 normal 模式
其它操作
- :! command 在不退出vim的情况下执行command指令
- . 重复前一次命令
- u 撤销
- ctrl + r 反撤销
- 一个小技巧:vim退出时的光标在哪,进去时的光标就在哪
插件和配置
.vimrc文件
vim通常是用.vimrc文件配置的,其实原理很简单,就是.vimrc文件会在进入vim之前执行.vimrc文件中的所有指令,所以我们通常把一些set命令放入到.vimrc文件中,这样就不用每次进入vim时手动的输入指令来个性化我们的vim了。
插件
首先我们需要知道,如果想要很好的使用vim中的插件,一个很重要的工具就是插件管理器,一般来说,最常使用的插件管理器就是vim-plug。不过由于vim的插件种类繁多,没有办法让我们快速上手,所以我们可以尝试去GitHub上找一个一键部署的,比如:GitHub - askunix/VimForCpp: VIM一键配置C/C++开发环境,可自动下载各类插件。VIM一键配置C/C++开发环境,可自动下载各类插件。. Contribute to askunix/VimForCpp development by creating an account on GitHub.![]() https://github.com/askunix/VimForCpp
https://github.com/askunix/VimForCpp
如果要手动安装插件的话,可以参考这篇博客:神级编辑器 Vim 使用 - 插件篇 | 闪耀旅途 (hanleylee.com)![]() https://www.hanleylee.com/articles/usage-of-vim-editor-plugin/
https://www.hanleylee.com/articles/usage-of-vim-editor-plugin/
gcc/g++
前置知识:源文件形成可执行文件需要经过预处理、编译、汇编和链接这四大过程。不知道的可以看这篇博客:浅析编译和链接
概念理解
gcc 与 g++ 分别是 gnu 的 c & c++ 编译器 gcc/g++ 在执行编译工作的时候,总共需要4步:
1、预处理,生成 .i 的文件[预处理器cpp]
2、将预处理后的文件转换成汇编语言, 生成文件 .s [编译器egcs]
3、有汇编变为目标代码(机器代码)生成 .o 的文件[汇编器as]
4、连接目标代码, 生成可执行程序 [链接器ld]
参数说明
g++和gcc的使用参数是一样的,所以虽然以gcc的角度进行讲解,但g++也是同样使用的。gcc的多样性大多是源于它的参数,其中有5个比较常用的参数:Esco和std,下面是相关解释:
-E 只运行 C 预编译器,把源文件编译为.i文件。
-S 只激活预处理和编译,把文件编译成为汇编代码.s文件。
-c 只编译生成.o可重定位目标文件。
-o FILE 生成指定的输出文件FILE,也就是说,-o后面是必须跟文件名的。
-std=Standard 用于指定编译器的执行标准,比如C99或者C++11就需要手动指定。
当然,还有一个 -g 选项也是比较常用的,这是在需要调试代码时常用的一个选项。
gcc/g++ 命令的常用选项
-ansi 只支持ANSI标准的C语法。这一选项将禁止GNU C的某些特色,例如asm或typeof关键词。
-c 只编译生成.o可重定位目标文件。
-DMACRO 以字符串"1"定义 MACRO 宏。
-DMACRO=DEFN 以字符串"DEFN"定义 MACRO 宏。
-E 只运行 C 预编译器,把源文件编译为.i文件。
-g 生成调试信息。GNU 调试器可利用该信息。
-IDIRECTORY 指定额外的头文件搜索路径DIRECTORY。
-LDIRECTORY 指定额外的函数库搜索路径DIRECTORY。
-lLIBRARY 连接时搜索指定的函数库LIBRARY。
-m486 针对 486 进行代码优化。
-o FILE 生成指定的输出文件。用在生成可执行文件时。
-O0 不进行优化处理。
-O 或 -O1 优化生成代码。
-O2 进一步优化。
-O3 比 -O2 更进一步优化,包括 inline 函数。
-S 只激活预处理和编译,把文件编译成为汇编代码.s文件。
-static 将禁止使用动态库,即只使用静态库。
-std=Standard 用于指定编译器的执行标准,比如C99或者C++11就需要手动指定。
-share 尽量使用动态库。
-shared 生成共享目标文件。通常用在建立共享库时。
-UMACRO 取消对 MACRO 宏的定义。
-w 不生成任何警告信息。
-Wall 生成所有警告信息。gdb
使用过VS的人都知道,在VS中编译一个程序时有debug和release版本。而在Linux中的gcc下,默认生成的就是release版本的,也就是说gcc/g++默认生成的可执行程序是没有调试信息的,当然也就不能调试,如果想要生成可调式的,需要在gcc/g++的选项上再加一个-g。如果没有-g选项生成的可执行文件是没有调试信息的,那么就会显示:![]()
由于gdb的使用非常的复杂,东西很多,所以这里我们只是简单的介绍如何快速上手用起gdb,至于详细的内容,可以参考gdb手册:Help (Debugging with GDB) (sourceware.org)![]() https://sourceware.org/gdb/onlinedocs/gdb/Help.html#index-GDB-version-number
https://sourceware.org/gdb/onlinedocs/gdb/Help.html#index-GDB-version-number
当然,由于这个手册是纯英文的,所以可能很难入手,如果很介意英文,可以尝试在下面这篇博客里找,里面的内容相对来说也是比较全面的:
显示gdb版本信息 | 100个gdb小技巧 (gitbooks.io)![]() https://wizardforcel.gitbooks.io/100-gdb-tips/content/show-version.html
https://wizardforcel.gitbooks.io/100-gdb-tips/content/show-version.html
下面是一些基础常用的gdb命令介绍,以便我们能够快速上手。
- list(l) :显示文件的源代码,从当前函数开始,每次显示10行,按回车键继续。其中,list是全称,l是简写。
- list(l) line:显示文件源代码,从第line行开始。其余内容同上。
- list(l) func:显示文件源代码,从func函数开始。其余内容同上。
- run(r):运行程序,通常配合断点来使用。和VS中不同的是,gdb运行程序结束之后,只要gdb没有退出,就还可以继续用的。其中run是全称,r是简写。
- start:start和run的功能基本上一致。最大区别的就是:run命令是在第一个断点处停下,start是在main函数的的入口处停下。
- break(b) line:在第line行设置断点。
- break(b) func:在func的函数入口处设置断点。
- break(b) file:line:给file文件的line行打断点。
- break(b) file:func:给file文件的func函数入口处打断点。
- info break(b):查看所有断点的信息。从gdb的打开到gdb的退出,这之间断点的编号会一直增加,即使某个断点被删除了它的编号也不会被占用。当gdb退出时,所有的断点就会被全部清除。
- info break(b) n:查看指定编号为n的断点。
- next(n):单条执行,不会进入到语句的函数中,相当于VS中的逐过程执行(F10)。通常在程序运行时配合断点使用。
- step(s):和next功能类似,只是step会进入到当前语句的函数中,更详细。相当于VS的逐语句执行(F11)。通常在程序运行时配合断点使用。
- continue(c):直接跳转到下一个断点处,没有断点则直接执行至程序结束。
- until line:无视任何条件,直接跳转至line行。
- finish:略过所有断点,直接执行剩下的所有语句,正常的结束当前函数。
- return:立即结束(停止)执行当前函数,并指函数的定返回值
- delete breakpoints(d):删除所有断点。
- delete breakpoints(d) n:删除编号为n的断点。
- disable breakpoints(disable):禁用所有断点。
- disable breakpoints(disable) n:禁用编号为n的断点。
- enable breakpoints(enable):启用所有断点。
- enable breakpoints(enable) n:启用编号为n的断点。
- p val:打印一次val变量的值,但只显示一次。
- display val:跟踪变量val。每次输入命令之后,都会紧接着显示变量val的值。
- info display:显示所有跟踪变量的信息。
- undisplay:取消对所有变量的跟踪。
- undisplay n:取消对编号为n的变量的跟踪。
- disable display <n>:禁用对所有(编号为n)的变量跟踪。
- set variable/var val = x:将变量val的值改为x,一般用于特殊情况的测试,不过有一定的风险性,而且一般不常用。
- breaktrace(bt):查看各级函数调用及参数,可以类比VS中的查看调用栈帧。
- quit(q):退出gdb
其它
- 有时我们打开gdb时会显示一些提示信息,感觉很冗余,如果想要不显示,可以在使用gdb时加上一个 -q 参数
- 如果不输入任何东西直接回车,默认是执行上一次的命令
make / makefile
作用介绍及语法格式
一般情况下。如果只用gcc/g++编译源文件的话,会很麻烦。首先,重复性的输入近乎相同的指令是一个很繁杂的工作,而且还会有一定的出错概率。其次如果文件很多,很大的话,那么对应的工作量也是会非常大的。所以综合考虑就比较适合使用make和Makefile用于日常开发。下面就让我们简单的快速了解一下make和Makefile,以快速上手。
首先,make是一个指令,Makefile是一个文件。Makefile是我们自己手动创建并写入的,而且文件名必须为makefile、Makefile或者GNUmakefile,只能是这三个之一,其中前两个是最为常用的。原因如下:
默认的情况下,make命令会在当前目录下按顺序找寻文件名为“GNUmakefile”、“makefile”、“Makefile”的文件。在这三个文件名中,最好使用“Makefile”这个文件名,因为,这个文件名第一个字符为大写,这样有一种显目的感觉。最好不要用 “GNUmakefile”,这个文件是GNU的make识别的。有另外一些make只对全小写的“makefile”文件名敏感,但是基本上来说,大多数的make都支持“makefile”和“Makefile”这两种默认文件名。
make命令就是执行Makefile文件中的内容,make命令的用法格式如下:
make #执行第一条方法
make target #执行具体的target方法
#用法说明:
# target是对应Makefile文件中的方法名
# 当没有指定具体的方法名时,默认执行第一条方法其中make命令有3个较为常用的参数:
1)-k :使用 -k 参数可以让 make 命令在发现错误时仍然继续执行,而不是在检测到第一个错误时就停下来。利用这个选项可以在一次操作中发现所有未编译成功的源文件
2)-n :使用 -n 参数,让 make 命令输出将要执行的操作步骤,而不是真正执行这些操作;
3)-f :使用 -f 参数,后面可以接一个文件名,用于指定一个文件作为 makefile 文件。如果没有使用 -f 选项,则 make 命令会在当前目录下查找名为 makefile 的文件,如果该文件不存在,则查找名为 Makefile 的文件。
从宏观概念上讲,Makefile里主要包含了五个东西:
显式规则、隐晦规则、变量定义、文件指示和注释
- 显式规则:显式规则说明了,如何生成一个或多的的目标文件。这是由Makefile的书写者明显指出,要生成的文件,文件的依赖文件,生成的命令。
- 隐晦规则:由于我们的make有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写Makefile,这是由make所支持的。
- 变量的定义:在Makefile中我们要定义一系列的变量,变量一般都是字符串,这个有点你C语言中的宏,当Makefile被执行时,其中的变量都会被扩展到相应的引用位置上。
- 文件指示:其包括了三个部分,一个是在一个Makefile中引用另一个Makefile,就像C语言中的include一样;另一个是指根据某些情况指定Makefile中的有效部分,就像C语言中的预编译#if一样;还有就是定义一个多行的命令。
- 注释:Makefile中只有行注释,和UNIX的Shell脚本一样,其注释是用“#”字符,这个就像C/C++中的“//”一样。如果你要在你的Makefile中使用“#”字符,可以用反斜框进行转义,如:“\#”。
而从使用层面上讲,makefile文件有着固定的语法格式,由一系列的“方法”组成,而每一个“方法”都由依赖关系和依赖方法两部分组成,“方法”的语法可以概括为如下格式:
target:prerequisites
<tab>command1
<tab>command2
...
#格式说明:
# 注释是以#号开头,一直延续到该行的结束。
# target是方法的名称,一般就是编译器生成的文件名(当然也可以不是)
# prerequisites通常是依赖关系,就是下面的命令会用到哪些文件
# command就是具体的依赖方法,也就是make需要执行的命令,它可以是任意的shell命令
# 一个强制性的规则是,每一条依赖方法前必须有一个制表符<tab>
# 续行符反斜杠'\'以让所有的命令在逻辑上处于同一行.PHONY伪目标
有一种特殊的方法叫做伪目标,伪目标用.PHONY来定义,伪目标的格式:
.PHONY:name
# .PHONY:是声明,后面的name是具体的伪目标方法名伪目标的作用:
- 伪目标并不是实际存在的,所以可以避免命令与目录下的文件名重复。
- 伪目标可以没有依赖关系,也就是说可以直接拿来用。
- 伪目标可以保证依赖方法总是被执行的。
- .PHONY,伪目标。凡是被.PHONY的,依赖方法总是被执行,就不会有“make不会执行没有修改过的文件”的效果。
make的自动推导功能
make很强大,它可以自动推导文件以及文件依赖关系后面的命令。而且如果当前语句中出现了一个未定义的依赖关系,make是会继续查看后面的内容的,并顺便寻找这个未定义的依赖关系。
所以我们就没必要去在每一个[.o]文件后都写上类似的命令,因为,我们的make会自动识别,并自己推导命令。只要make看到一个[.o]文件,它就会自动的把[.c]文件加在依赖关系中,如果make找到一个whatever.o,那么 whatever.c,就会是whatever.o的依赖文件。并且 cc -c whatever.c 也会被推导出来,于是,我们的makefile 再也不用写得这么复杂。例如:
objects = main.o kbd.o
cc = gcc
edit : $(objects)
$(cc) -o $@ $^
%.o:%.c #这是Makefile的静态模式规则,意思是:所有的.o文件,依赖于对应的.c文件
.PHONY : clean
clean :
rm edit $(objects)
不会执行未改动的依赖方法
如果生成文件和方法名target是一样的话,那么make就不会执行没有修改过的文件对应的方法。大致原理就是通过对比方法名target和依赖关系文件的时间戳来实现的。但是如果生成的文件和方法名target不一致的话,就不会有此效果。所以大多数情况下,为了防止大规模程序的多余编译行为,我们一般默认就是把生成的文件名和方法名target保持一致。
两个特殊字符: - 和 @:
1)若在依赖关系的语句前,加上了符号 '-',则表明将忽略该命令产生的所有错误
2)若在依赖关系的语句前,加上了符号 '@',则表明不会将该命令显示在标准输出上
宏 /变量
宏,也可以理解为变量,定义的方法很简单,格式如下:
NAME=value
# NAME是宏名(变量名),val是对应的值
# 这个值常用于为了简化写法而设置为依赖关系的文件名、生成的文件名、使用的编译器等名称引用宏的方法是用$坐前缀,然后将宏名用小括号或者大括号引起来,格式如下:
# 两种写法都可以
$(NAME)
${NAME} 使用宏定义,可以让 makefile 文件的可移植性更强。除了自己定义一些宏以外,make 命令还内置了一些特殊的宏定义,使得 makefile 文件变得更加简洁:
| 宏 | 说明 |
|---|---|
| $? | 当前目标所依赖的文件列表中比当前目标文件还要新的文件 |
| $@ | 当前目标的名字 |
| $< | 当前依赖文件的名字 |
| $* | 不包括后缀名的当前依赖文件的名字 |
除了在 makefile 文件里面定义宏以外,还可以调用 make 命令时,在命令行上给出宏定义。命令行上的宏定义将覆盖在 makefile 文件中的宏定义。需要注意的是,在 make 命令后接宏定义时,宏定义必须以单个参数的形式传递,因此,尽量要避免在宏定义中使用空格或加引号。