- 💂 个人网站:【工具大全】【游戏大全】【神级源码资源网】
- 🤟 前端学习课程:👉【28个案例趣学前端】【400个JS面试题】
- 💅 寻找学习交流、摸鱼划水的小伙伴,请点击【摸鱼学习交流群】

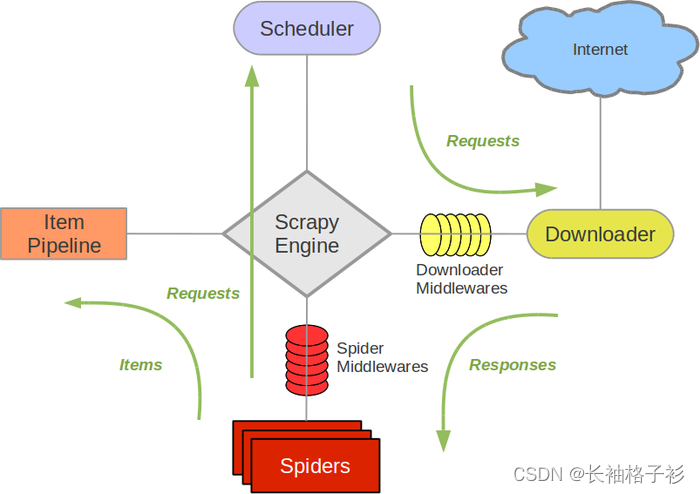
Scrapy是一个强大的Python框架,用于构建高效的网络爬虫。它提供了一组工具和功能,使得爬取、提取和存储网页数据变得相对容易。本文将深入介绍Scrapy框架的基本原理,并提供一个示例项目,以演示如何使用Scrapy构建自己的网络爬虫。
Scrapy框架简介
Scrapy是一个基于Python的开源网络爬虫框架,它具有以下主要特点:
- 高性能: Scrapy使用异步非阻塞IO,能够高效地处理大量请求和数据。
- 可扩展性: 您可以根据需要编写自定义的爬虫中间件和管道,以满足特定需求。
- 内置的选择器: Scrapy内置了强大的选择器,用于从HTML或XML中提取数据。
- 自动化: Scrapy处理请求和响应的流程自动化,使爬虫编写更简单。
示例:使用Scrapy构建网络爬虫
以下是一个使用Scrapy构建网络爬虫的示例项目,用于爬取名言网站上的名言信息。
- 创建Scrapy项目
首先,创建一个新的Scrapy项目:
scrapy startproject quotes_crawler
- 定义爬虫
在项目中创建一个名为quotes_spider.py的爬虫文件,定义一个爬虫类,如下所示:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
这个爬虫类定义了如何处理网页响应以及如何提取名言信息。
- 运行爬虫
在项目根目录下运行爬虫:
scrapy crawl quotes
Scrapy将开始爬取网站上的数据,并将结果存储在项目中的文件中。
高级功能和配置
Scrapy提供了许多高级功能和配置选项,以满足不同的爬虫需求。例如,您可以配置爬虫的下载延迟、用户代理、代理IP等。您还可以使用中间件来实现自定义的请求和响应处理逻辑。
总结
Scrapy是一个功能强大且高效的网络爬虫框架,适用于各种数据采集任务。本文提供了一个简单的Scrapy示例项目,演示了如何创建和运行爬虫,以及如何提取数据。通过深入学习Scrapy,您可以构建更复杂的爬虫,并处理各种数据源,为数据分析和应用开发提供有力支持。
Scrapy还提供了许多高级功能,如自动限速、分布式爬取、用户代理设置等,使其成为一个强大的爬虫框架。