在过去的一周里,为了更好的构建 AI Agent 框架 Chocolate Factory(以下简称 CF),我们加入了一个新的应用:代码库 AI 助手。
在设计时,为了更好的在框架底层提供这种能力,我们参阅了 Bloop 应用、LangChain、Spring AI、LlamaIndex 框架等的代码与思想,参考/复制(基于 Apache 2.0 协议) LangChain4j 的一部分 VectorStore 实现。
详细见代码库:https://github.com/unit-mesh/chocolate-factory 。
详细文档见:https://framework.unitmesh.cc/ 。
Demo 视频见:
引子:代码库 AI 助手
首先,先让 ChatGPT 根据我们的素材总结了一下:什么是代码库 AI 助手?负责读取和格式化数据,以便将其分成适合存储在数据库中的片段。
代码库 AI 助手是一种智能工具,通常使用自然语言处理和机器学习技术,旨在帮助开发者更有效地管理和理解大型代码库。这些助手能够回答关于代码库的问题、提供文档、搜索代码、识别错误源头、减少代码重复等,从而提高开发效率、降低错误率,并减轻开发者的工作负担。
其设计目标是使开发者能够以更直观和自然的方式与代码库进行互动,减少繁琐的文档查找和编码任务,从而加速软件开发过程。
简单来说,用户直接提出问题,基于现有的业务逻辑实现,去进去后续的任务,如:需求是如何实现的?根据 bug 来分析与代码的关系,并提供修复意见。
先让我们看个示例:
代码库 AI 助手问答示例
问题:Semantic Workflow 是如何实现的?
ChatGPT 根据 CF 检查的代码,返回的答案:
根据提供的代码,我们可以看到 CodeSemanticWorkflow 是一个继承自 Workflow 的类,它实现了 execute 方法来执行语义化的代码搜索。
在 execute 方法中,它首先创建了一个 ElasticsearchStore 对象,并获取了用户最后一条消息的内容作为问题。然后,它使用 SemanticProblemAnalyzer 对象来分析问题,该对象使用 llmProvider 来完成问题的解析。接下来,它使用 SemanticSolutionExecutor 对象来执行语义化的代码搜索,并将结果转换为 Flowable。最后,它调用 toFlowableResult 方法将结果转换为 Flowable 并返回。
下面是一个使用 PlantUML 绘制的流程图,展示了 CodeSemanticWorkflow 的执行过程:
@startuml
start
:创建 ElasticsearchStore对象;
:获取用户最后一条消息的内容;
:使用 SemanticProblemAnalyzer对象分析问题;
:使用 SemanticSolutionExecutor对象执行语义化的代码搜索;
:将结果转换为 Flowable<Answer>;
:将结果转换为 Flowable<WorkflowResult>;
stop
@enduml希望以上信息能够回答您的问题。
CF 代码库 AI 助手设计
在设计 Chocolate Factory(以下简称 CF)时,我们依旧采用的是 DDD 思想所构建的。
第一部分,围绕于问题空间的求解,对用户问题进行分析与转换,以获得潜在的解决方案。
第二部分,围绕于解决空间的实现,即通过检索增强(RAG,Retrieval Augmented Generation),来获得对应问题的答案。
为此,在第一部分,我们将会分析问答的问题,以构建出一个针对于解决方案的 DSL。然后,围绕于 DSL 来进行检索,获得相应的答案,最后交由 LLM 来进行总结。
Prompt 构建策略阶段 1:问题求解
在设计上,为了更好的进进行检索,在设计 CoUnit 时,我们拆分成三种检查条件:
englishQuery,将中文翻译成英文,再结合英文进行搜索。
originLanguageQuery,如我们在使用中文里,翻译成英语可能不标准,但是注释中则可能是使用中文存在,所以相似式也会很靠谱。
hypotheticalDocument,假设性文档,即根据用户的请求生成代码,再结合生成的代码进行相似式搜索。
所以,在阶段一就需要由 LLM 来分析用户的问题,并给出如上的三个检查条件。hypotheticalDocument 参考的是 Bloop 的设计:
hypotheticalDocument is a code snippet that could hypothetically be returned by a code search engine as the answer.
hypotheticalDocument code snippet should be between 5 and 10 lines long
不过,由于一次给了三个条件,偶尔还是存在概率性的假设性文档出错的问题。
Prompt 构建策略阶段 2:检索增强
在现有的设计里,一个代码库 AI 助手本质也是 RAG(检索增强,Retrieval Augmented Generation),因此可以分为 indexing 阶段和 querying 阶段。
代码库 AI 助手:indexing 阶段

在 indexing 阶段,基本上就是:
文本分割(TextSplitter)。负责将源数据分割成较小单元(Chunks)的工具或组件。
文本向量化(Vectoring)。负责将拆分好的 Chunk 转变化向量化数组。
数据库(Vector Database)负责通过高效的向量检索技术来实现文档片段的快速检索。
在文本向量化上,我们使用的是 SentenceTransformer 的本地化极小 NLP 模型(22M 左右)。对于代码来说,它是结构化的形式,并且也经过了 GitHub Copilot、Bloop 的充分验证,所以准确度并不差。
由于使用的是本地化模型,通过 CPU 就可以快速计算完成,所以更新策略上可以和 CI、CD 集成。一旦有代码更新时,就可以 indexing。
代码库 AI 助手:querying 阶段
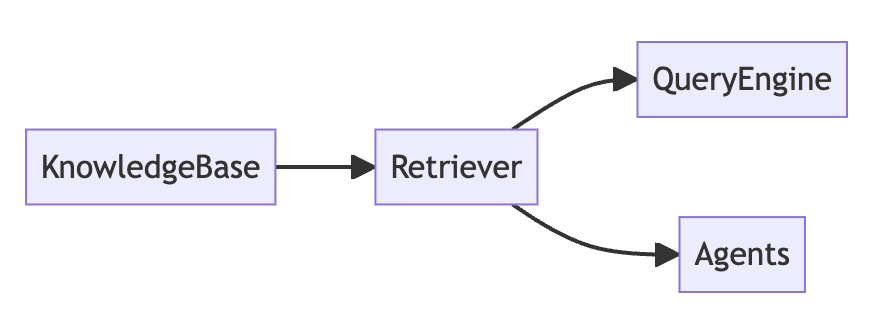
在 querying 阶段,我们会围绕阶段 1 的 DSL,先转换 DSL 的文本成对应的向量化形式。
再对其进行对应的内容检索:
// 基于英语的相关代码列表
val list = store.findRelevant(query, 15, 0.6)
// 基于中文的相关代码列表
val originLangList = store.findRelevant(originQuery, 15, 0.6)
// 相关的假设性代码列表
val hydeDocs = store.findRelevant(hypotheticalDocument, 15, 0.6)随后,再对结果进行排序。考虑到诸如 《Lost in the Middle: How Language Models Use Long Contexts》对于长文本的影响,我们在 CF 中也引入了对应的方式,因此一个排序后的代码结果如下所示:
0.7847863// canonicalName: cc.unitmesh.cf.domains.semantic.CodeSemanticWorkflowTest
0.76635444// canonicalName: cc.unitmesh.cf.domains.semantic.CodeSemanticDecl
0.74648994// canonicalName: cc.unitmesh.cf.core.flow.ProblemAnalyzer
0.7410852// canonicalName: cc.unitmesh.cf.domains.spec.SpecDomainDecl
0.72767156// canonicalName: cc.unitmesh.cf.core.flow.DomainDeclaration
0.73245597// canonicalName: cc.unitmesh.cf.core.flow.model.WorkflowResult
0.7434818// canonicalName: cc.unitmesh.cf.domains.interpreter.CodeInterpreterWorkflow.execute
0.757218// canonicalName: cc.unitmesh.cf.core.flow.Workflow
0.7722022// canonicalName: cc.unitmesh.cf.domains.semantic.flow.SemanticProblemAnalyzer
0.807935// canonicalName: cc.unitmesh.cf.domains.semantic.CodeSemanticWorkflow.execute前面的数字便是相关性的 score,后面的 canonicalName 则是相关代码的信息,可能是类、类方法、方法等。
Prompt 策略 3:代码拆分策略
在代码的分割上,不同的框架有不同的策略,LangChain 是基于关键字的方式,LlamaIndex 是基于 TreeSitter 方式,Bloop 则是基于 TreeSitter 的 S-表达式创建。
我们则是采用 ArchGuard Scanner 的标准化代码结构方式,除了可以直接利用 ArchGuard 项目的现有的 CLI 基础设施,在形式上与结果上也更加准确。诸如于可以针对于 Interface、abstract class 等进行优化 Chunk 的拆分规则,并构建出 canonicalName 的方式,来方便索引和定位。
代码拆分规则
我们参考的折分规则是:https://docs.sweep.dev/blogs/chunking-2m-files 。即:
代码的平均 Token 到字符比例约为1:5(300 个 Token),而嵌入模型的 Token 上限为 512 个。
1500 个字符大约对应于 40 行,大致相当于一个小到中等大小的函数或类。
挑战在于尽可能接近 1500 个字符,同时确保分块在语义上相似且相关上下文连接在一起。
对应的模型如下:
classCodeSplitter(
private val comment: String= "//",
private val chunkLines: Int= 40,
private val maxChars: Int= 1500,
// TODO: for unsupported languages, we can use the following heuristic to split the code
val chunkLinesOverlap: Int= 15,
)当然了,这里的 chunkLinesOverlap 是还没有襰的。
Chunk 拆分实现
由 CF 的代码库 AI 助手生成:
问题:CodeSplitter 是如何实现的
答案:
根据提供的代码,CodeSplitter 是一个用于将代码拆分成多个文档的类。它有一个 split 函数,该函数接受一个 CodeDataStruct 对象并返回一个 Document 对象的列表。
在 split 函数中,它首先根据代码的长度判断是否需要拆分。如果代码的长度小于等于 maxChars(默认为1500个字符),则直接将整个代码作为一个文档返回。
如果代码的长度大于 maxChars,则会遍历 CodeDataStruct 对象中的每个函数,并将函数的内容拆分成多个文档。拆分的方式是根据 chunkLines(默认为40行)将函数内容分割成多个部分。如果函数的行数超过了 chunkLines,则只取前 chunkLines 行作为一个文档的内容。
拆分后的文档的内容由 canonicalName 和函数的内容组成。如果拆分后的内容长度超过了 maxChars,则会截取前 maxChars 个字符作为文档的内容。
小结
本文深入探讨了代码库AI助手的设计和实现策略,包括问题求解、检索增强和代码拆分。这些策略有助于提高开发者与代码库的互动效率和准确性,加速软件开发过程。
详细见代码库:https://github.com/unit-mesh/chocolate-factory 。
详细文档见:https://framework.unitmesh.cc/ 。