1. 认识IO
什么是IO
I/O简单来说对应的就是两个单词Input和Output,指的是计算机系统与外部环境(通常是硬件设备或其他计算机系统)之间的数据交换过程
I/O 可以分为两种主要类型:
- 输入(Input): 输入是指计算机系统接收来自外部环境的数据或信息的过程。例如,当用户在键盘上输入文本时,这些输入字符被视为输入操作。输入可以来自各种外部源,包括键盘、鼠标、传感器、网络连接、磁盘驱动器等。计算机系统需要能够接收和处理这些输入数据,以便执行相应的操作。
- 输出(Output): 输出是指计算机系统将处理后的数据或信息发送到外部环境的过程。例如,当计算机系统将文本显示在屏幕上、打印文档到打印机或将数据写入磁盘驱动器时,这些都是输出操作。输出使计算机系统能够与用户或其他设备进行有效的通信。
在计算机程序中,I/O 操作通常是相对较慢的操作,因为涉及到与外部设备通信或存储介质的读写,而这些操作比内存中的数据处理更为耗时。因此,在编写高效的程序时,需要注意如何最小化 I/O 操作的次数,以提高性能。此外,对于某些应用程序,如数据库管理系统和网络通信应用程序,有效的 I/O 管理对于系统的响应时间和吞吐量至关重要。
2.C文件接口的IO
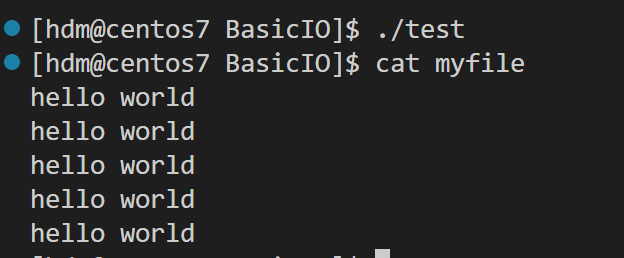
写文件
#include <stdio.h>
#include <string.h>
int main()
{
FILE* fp=fopen("myfile","w");
if(fp==NULL){
perror("open");
return 1;
}
const char* str="hello world\n";
int cnt=5;
while(cnt--)
fwrite(str,strlen(str),1,fp);
fclose(fp);
return 0;
}
读文件
#include <stdio.h>
#include <string.h>
int main()
{
FILE* fp=fopen("myfile","r");
if(fp==NULL){
perror("open");
return 1;
}
const char* msg="hello world\n";
char* str[1024];
while (1)
{
size_t s=fread(str,1,strlen(msg),fp);
if(s>0)
{
str[s]=0;
printf("%s",str);
}
if(feof(fp)) break;
}
fclose(fp);
return 0;
}

3. 系统文件接口的I/O
操作文件,除了上述C接口(当然其他语言也有),我们还可以采用系统接口来进行文件访问
接口介绍
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
pathname: 要打开或创建的目标文件
flags: 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
O_APPEND: 追加写
返回值:
成功:新打开的文件描述符
失败:-1
mode_t理解:直接看man 手册,比什么都清楚。
open 函数具体使用哪个,和具体应用场景相关,如目标文件不存在,需要open创建,则第三个参数表示创建文件的默认权限,否则,使用两个参数的open。
写文件
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(){
int fd=open("myfile",O_WRONLY);
if(fd<0){
perror("open");
}
const char* msg="hello world!!\n";
int cnt=5;
while (cnt--){
//fd: 后面讲, msg:缓冲区首地址, len: 本次读取,期望写入多少个字节的数据。 返回值:实际写了多少字节数据
write(fd,msg,strlen(msg));
}
close(fd);
return 0;
}
读文件
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
int fd=open("myfile",O_RDONLY);
if(fd<0){
perror("open");
}
const char* msg="hello world!!\n";
char* str[1024];
while (read(fd,str,strlen(msg)))
{
printf("%s",str);
}
close(fd);
return 0;
}
open函数返回值
在认识返回值之前,先来认识一下两个概念: 系统调用和 库函数
上面的
fopenfclosefreadfwrite都是C标准库当中的函数,我们称之为库函数(libc)。
而,openclosereadwritelseek都属于系统提供的接口,称之为系统调用接口
所以,可以认为,f#系列的函数,都是对系统调用的封装,方便二次开发。
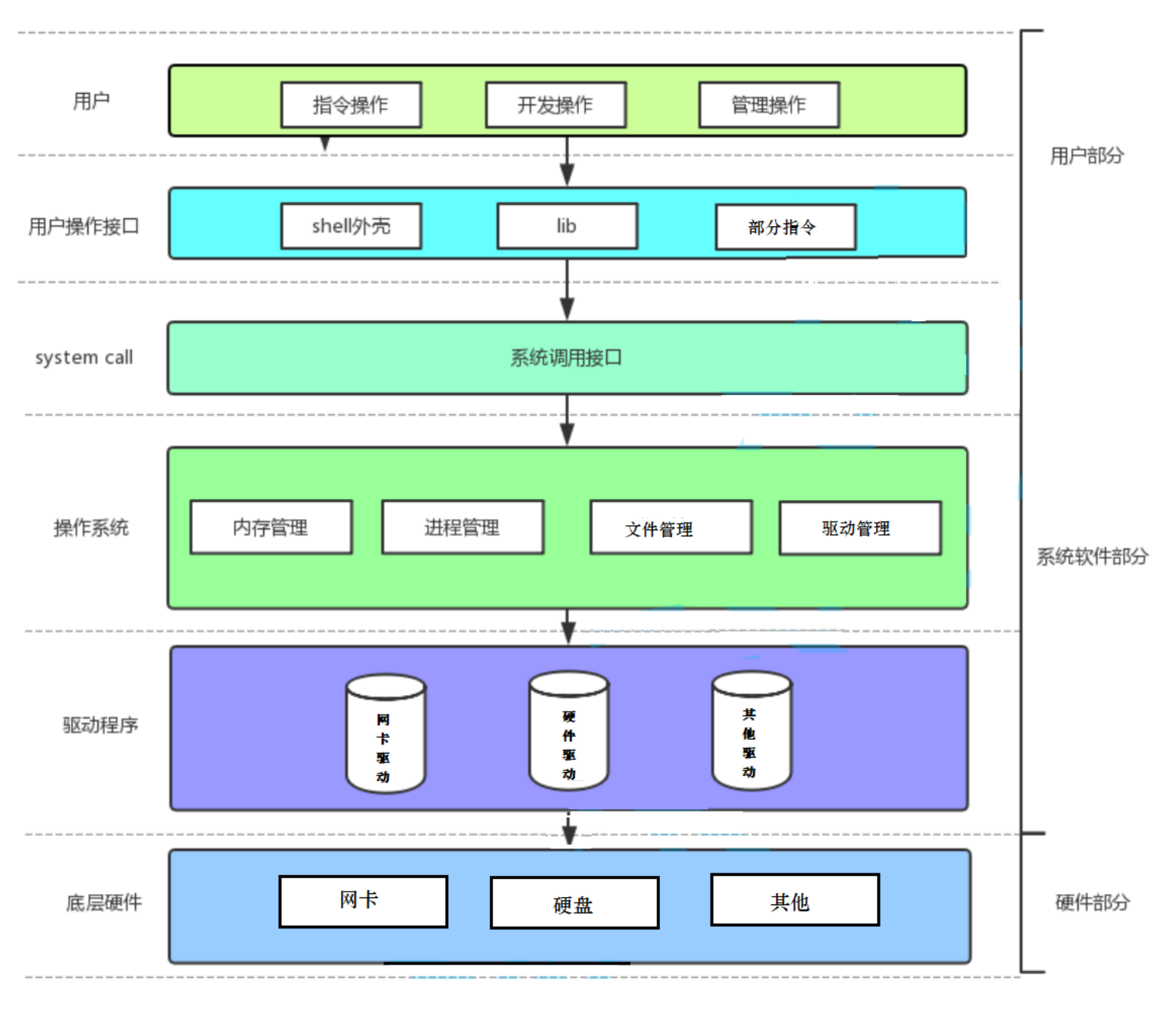
文件描述符fd
这个文件描述符fd究竟是个什么数字呢?
我们可以试着把它打印出来看看
#include <stdio.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> int main() { int fd=open("myfile",O_RDONLY); if(fd<0){ perror("open"); } printf("%d\n",fd); close(fd); return 0; } //输出结果 //3
文件描述符就是一个小整数,但它为什么是3呢?学过C语言的应该都知道
C默认会打开三个输入输出流,分别是stdin, stdout, stderr仔细观察发现,这三个流的类型都是FILE*, fopen返回值类型,文件指针,其实这三个流就对应数字0,1,2,进而可以得出,fd本质上就是数组的下标,只不过这个数组是系统帮我们维护的
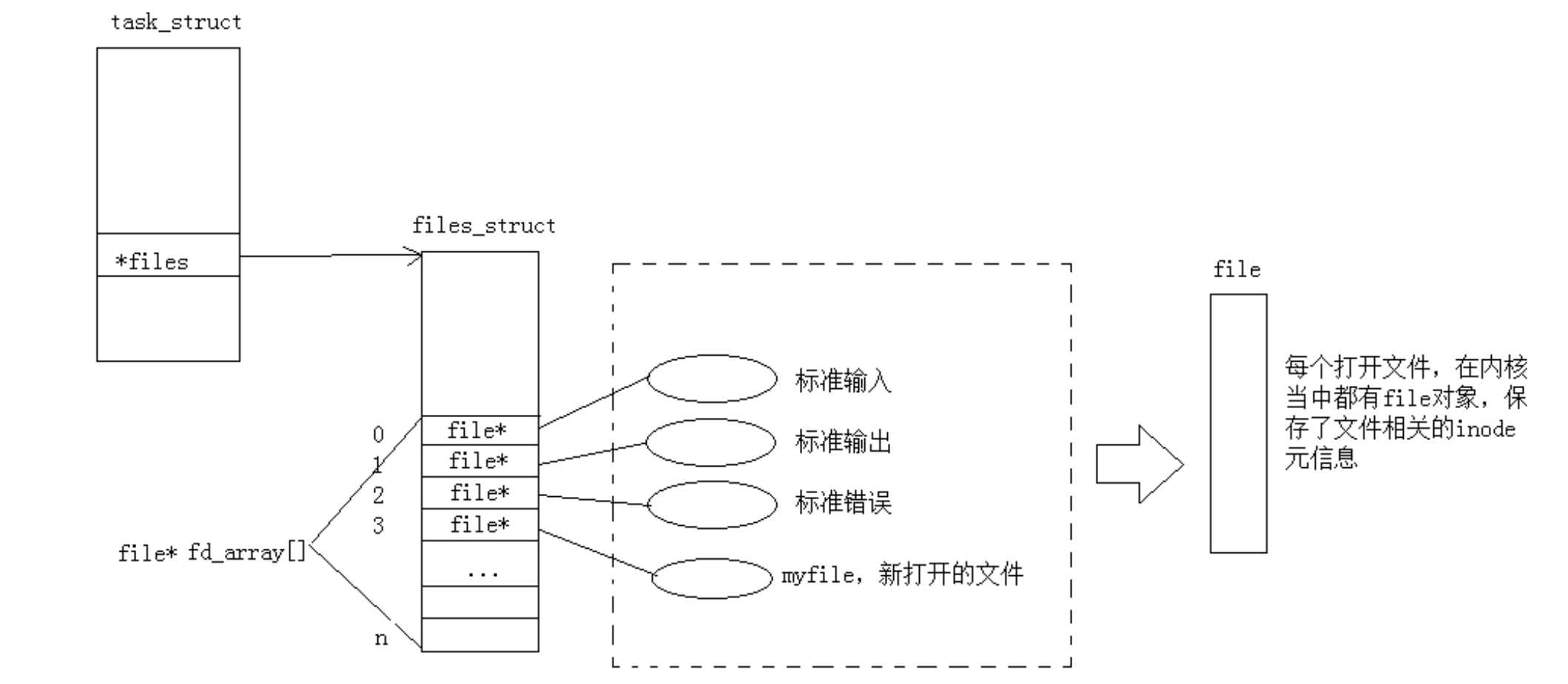
而现在知道,文件描述符就是从0开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件
Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2
0,1,2对应的物理设备一般是:键盘,显示器,显示器、
所以输入输出还可以采用如下方式:
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
char buffer[1024];
ssize_t s=read(0,buffer,sizeof buffer);
if(s>0){
buffer[s]=0;
write(1,buffer,strlen(buffer));
write(2,buffer,strlen(buffer));
}
return 0;
}
//运行结果
//输入:hello world!!!
//输出:
//hello world!!!
//hello world!!!
文件描述符的分配规则
上面的例子中,我们新打开一个文件输出后发现是 fd: 3
现在关闭文件描述符0或者2再来看看
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0);
//close(2);
int fd = open("myfile", O_RDONLY);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
发现是结果是: fd: 0 或者 fd 2 可见,文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
那如果我们关闭标准输出1呢?
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
close(1);
int fd = open("myfile", O_WRONLY|O_CREAT, 00644);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
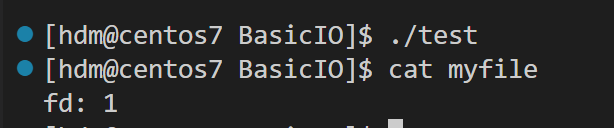
此时,我们发现,本来应该输出到显示器上的内容,输出到了文件 myfile 当中,其中,fd=1。这种现象叫做输出重定向。常见的重定向有:>, >>, <
//比如我想让myfile文件写入ls -l 打印的内容
[hdm@centos7 BasicIO]$ ls -l > myfile
[hdm@centos7 BasicIO]$ cat myfile
total 28
-rw-r--r-- 1 hdm wheel 65 Sep 9 15:56 makefile
-rw-r--r-- 1 hdm wheel 0 Sep 10 12:40 myfile
-rwxr-xr-x 1 hdm wheel 16576 Sep 10 12:33 test
-rw-r--r-- 1 hdm wheel 652 Sep 10 12:33 test.c
重定向
重定向的本质是什么呢?
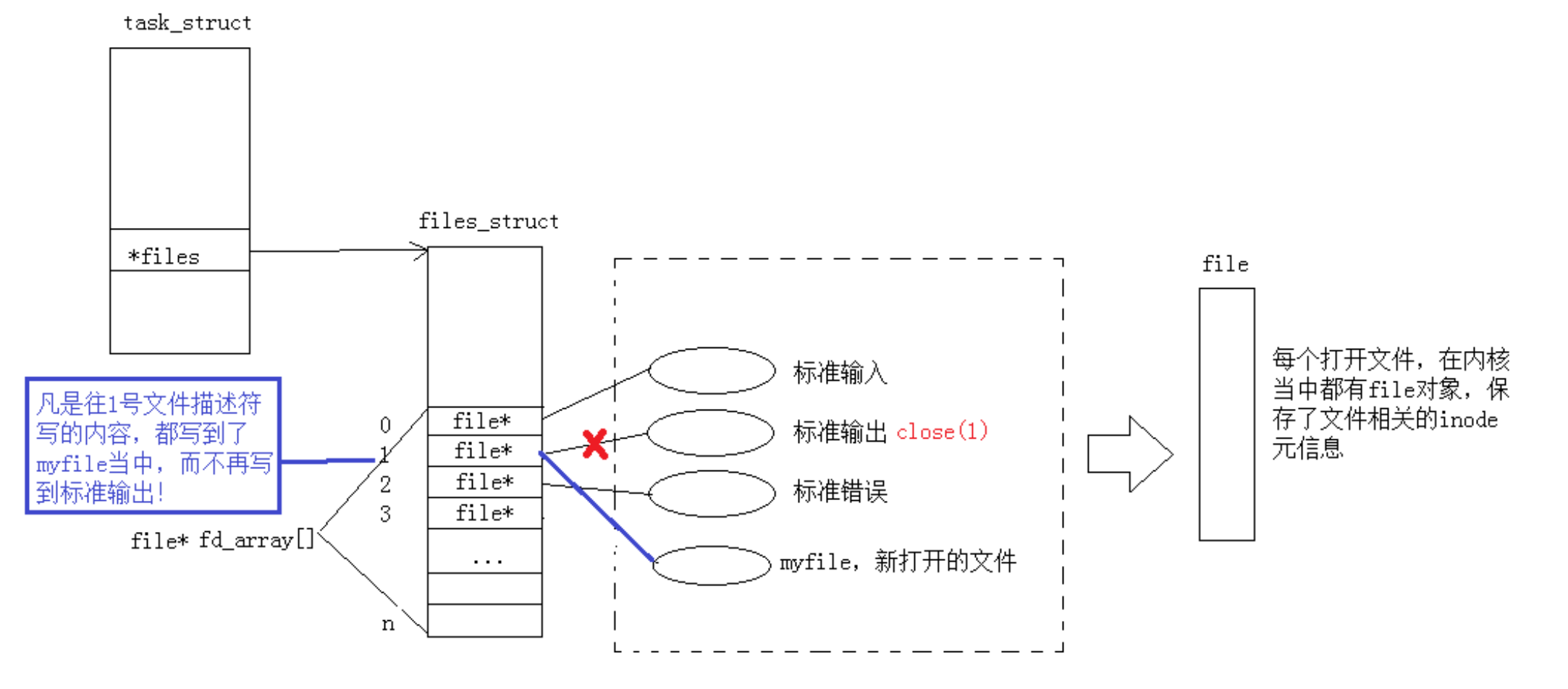
不过我们要实现重定向,并不会像上面的列子一样,先把一个文件描述符关闭再打开,系统给了我们一套接口
dup2 系统调用
函数原型如下:
#include <unistd.h>
int dup2(int oldfd, int newfd);
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
int fd=open("myfile",O_WRONLY | O_CREAT,0644);
if(fd<0){
perror("open");
}
dup2(fd,1);
printf("fd: %d\n", fd);
fflush(stdout);
const char* str="hello\n";
const char* str1="nihao\n";
fprintf(stdout,"%s",str1);
write(1,str,strlen(str));
write(fd,str,strlen(str));
return 0;
}
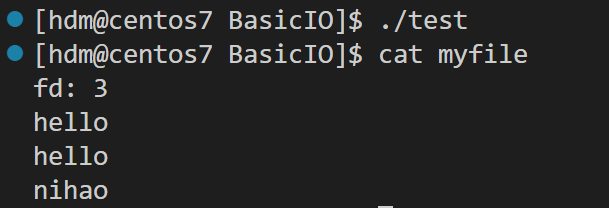
printf是C库当中的IO函数,一般往 stdout 中输出,但是stdout底层访问文件的时候,找的还是fd:1, 但此时,fd:1下标所表示内容,已经变成了myfile的地址,不再是显示器文件的地址,所以,输出的任何消息都会往文件中写入,进而完成输出重定向。
FILE
因为IO相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过fd访问的。所以C库当中的FILE结构体内部,必定封装了fd。
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
const char* str1="hello printf\n";
const char* str2="hello fprintf\n";
const char* str3="hello write\n";
printf("%s",str1);
fprintf(stdout,"%s",str2);
write(1,str3,strlen(str3));
fork();
return 0;
}
//运行出结果:
//hello printf
//hello fprintf
//hello write
但如果对进程实现输出重定向呢? ./test > myfile , 我们发现结果变成了:
[hdm@centos7 BasicIO]$ ./test >myfile
[hdm@centos7 BasicIO]$ cat myfile
hello write
hello printf
hello fprintf
hello printf
hello fprintf
我们发现 printf 和 fwrite (库函数)都输出了2次,而 write 只输出了一次(系统调用)。
为什么呢?肯定和fork有关!
一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
printf fwrite 库函数会自带缓冲区,当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。
而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后
但是进程退出之后,会统一刷新,写入文件当中。
但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
write没有变化,说明没有所谓的缓冲。
综上: printf fwrite 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围内。
那这个缓冲区谁提供呢? printf fwrite 是库函数, write 是系统调用,库函数在系统调用的“上层”, 是对系统调用的“封装”,但是 write 没有缓冲区,而 printf fwrite 有,足以说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供。
4. 理解文件系统
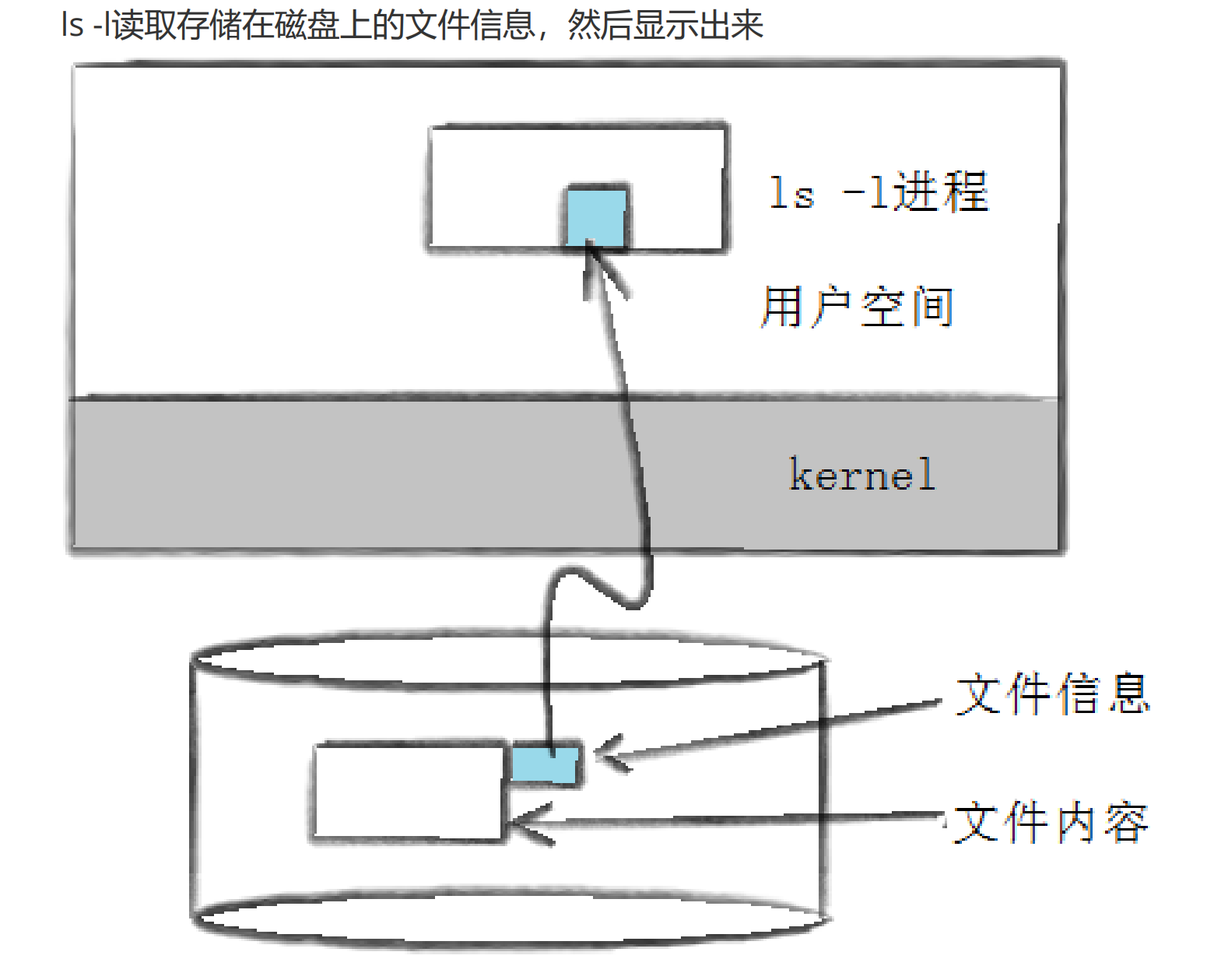
我们使用ls -l的时候看到的除了看到文件名,还看到了文件的其他数据。
[hdm@centos7 BasicIO]$ ls -l
total 12
-rw-r--r-- 1 hdm wheel 65 Sep 10 12:57 makefile
-rw-r--r-- 1 hdm wheel 66 Sep 10 15:50 myfile
-rw-r--r-- 1 hdm wheel 1101 Sep 10 15:48 test.c
每行包含7列:
模式
硬链接数
文件所有者
组
大小
最后修改时间
文件名
其实这个信息除了通过这种方式来读取,还有一个stat命令能够看到更多信息
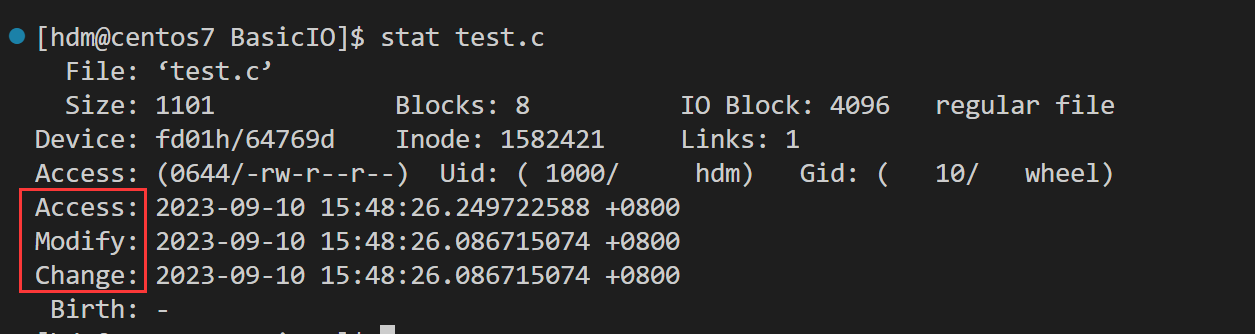
[hdm@centos7 BasicIO]$ stat test.c File: ‘test.c’ Size: 1101 Blocks: 8 IO Block: 4096 regular file Device: fd01h/64769d Inode: 1582421 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 1000/ hdm) Gid: ( 10/ wheel) Access: 2023-09-10 15:48:26.249722588 +0800 Modify: 2023-09-10 15:48:26.086715074 +0800 Change: 2023-09-10 15:48:26.086715074 +0800 Birth: -上面的执行结果有几个信息需要解释清楚
inode
为了能解释清楚inode我们先简单了解一下文件系统
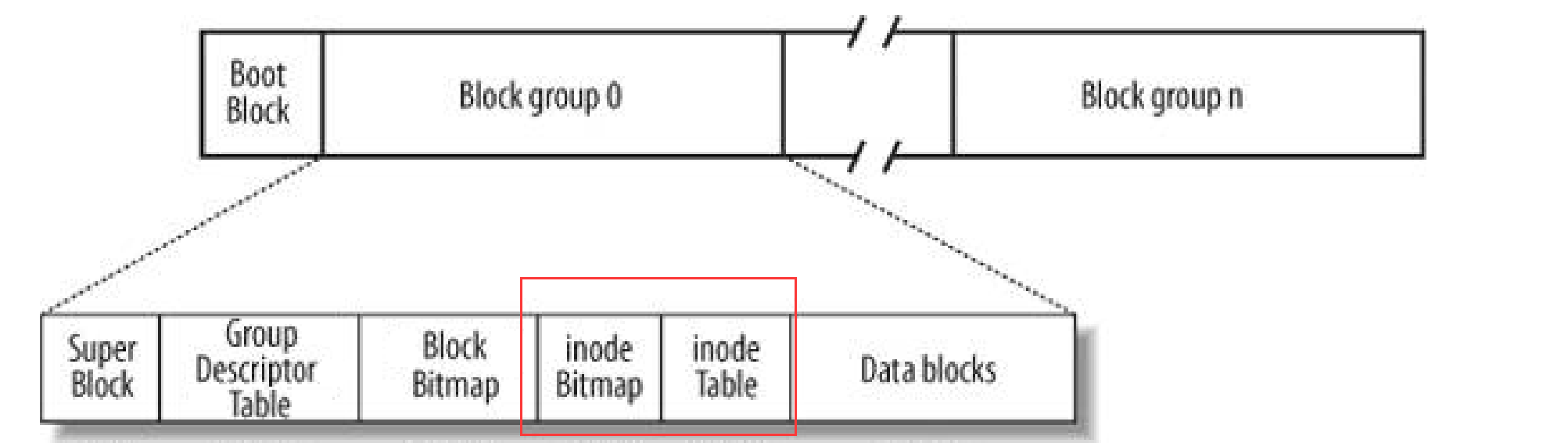
Linux ext2文件系统,上图为磁盘文件系统图(内核内存映像肯定有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的block。一个block的大小是由格式化的时候确定的,并且不可以更改。
- Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。政府管理各区的例子
- 超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了
- GDT,Group Descriptor Table:块组描述符,描述块组属性信息
- 块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用
- inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用
- i节点表:存放文件属性 如 文件大小,所有者,最近修改时间等
- 数据区:存放文件内容
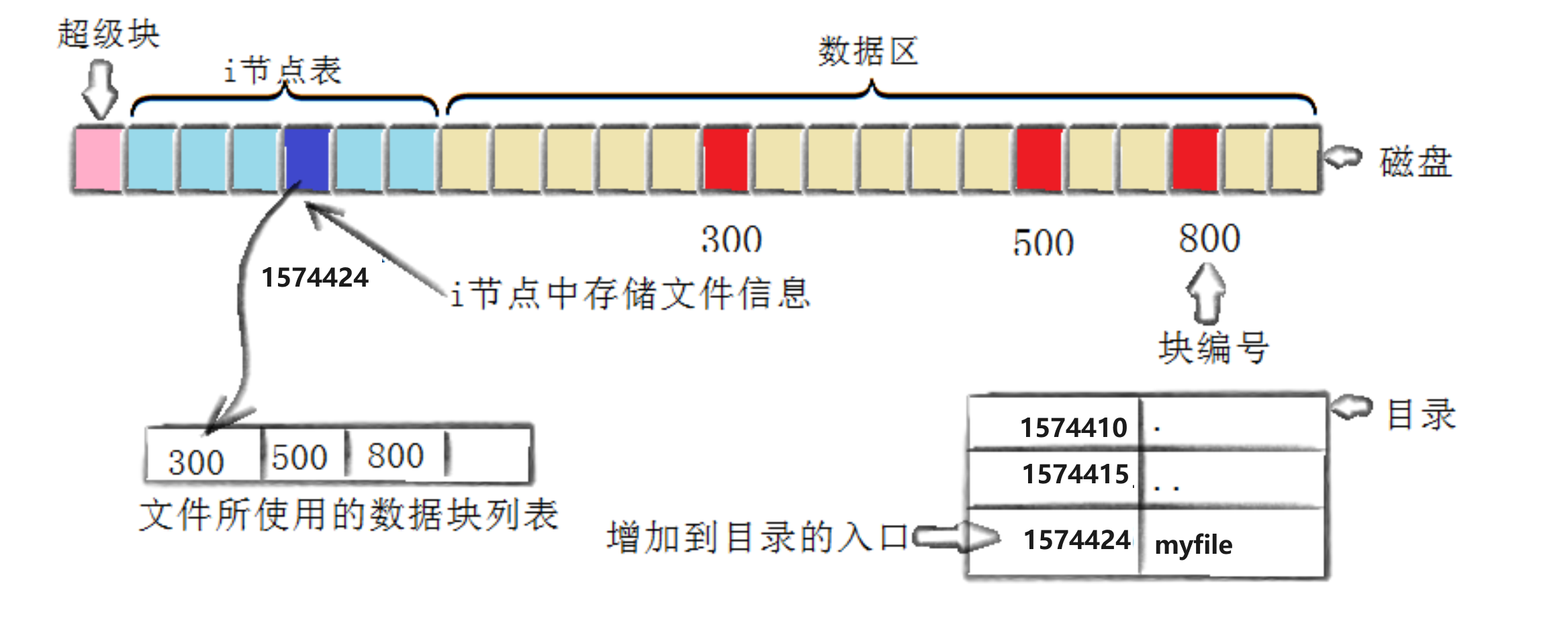
将属性和数据分开存放的想法看起来很简单,但实际上是如何工作的呢?我们通过touch一个新文件来看看如何工作
[hdm@centos7 BasicIO]$ touch myfile [hdm@centos7 BasicIO]$ ls -i myfile 1574424 myfile
为了说明问题,我们将上图简化
创建一个新文件主要有一下4个操作:
存储属性
内核先找到一个空闲的i节点(这里是1574424)。内核把文件信息记录到其中。存储数据
该文件需要存储在三个磁盘块,内核找到了三个空闲块:300,500,800。将内核缓冲区的第一块数据复制到300,下一块复制到500,以此类推。记录分配情况
文件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表。添加文件名到目录
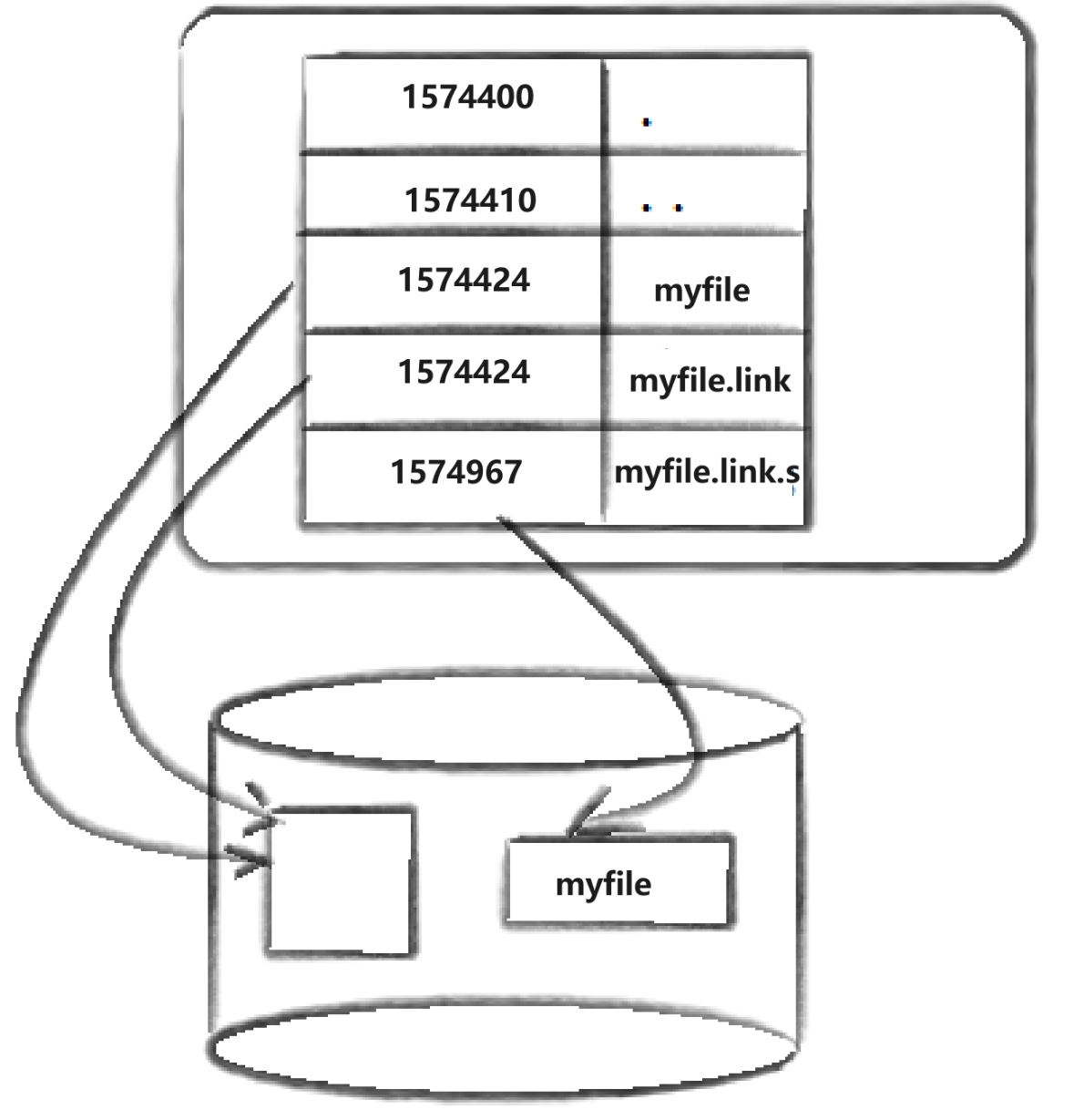
新的文件名myfile。linux如何在当前的目录中记录这个文件?内核将入口(1574424,myfile)添加到目录文件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。
理解软硬链接
我们看到,真正找到磁盘上文件的并不是文件名,而是inode。 其实在linux中可以让多个文件名对应于同一个inode。
//ln 属于硬链接的文件 硬链接文件的名字
ln file file.link
[hdm@centos7 BasicIO]$ touch myfile
[hdm@centos7 BasicIO]$ ls -li
1574424 -rw-r--r-- 1 hdm wheel 66 Sep 11 13:27 myfile
hdm@centos7 BasicIO]$ ln myfile myfile.link
[hdm@centos7 BasicIO]$ ls -li
1574424 -rw-r--r-- 2 hdm wheel 66 Sep 11 13:27 myfile
1574424 -rw-r--r-- 2 hdm wheel 66 Sep 11 13:27 myfile.link
[hdm@centos7 BasicIO]$ unlink myfile.link
[hdm@centos7 BasicIO]$ ls -li
1574424 -rw-r--r-- 1 hdm wheel 66 Sep 11 13:27 myfile
[hdm@centos7 BasicIO]$ rm myfile
[hdm@centos7 BasicIO]$ ls -li
myfile和myfile.link的链接状态完全相同,他们被称为指向文件的硬链接。内核记录了这个连接数,inode
1574424的硬连接数为2。
我们在删除文件时干了两件事情:
1.在目录中将对应的记录删除,
2.将硬连接数-1,如果为0,则将对应的磁盘释放。
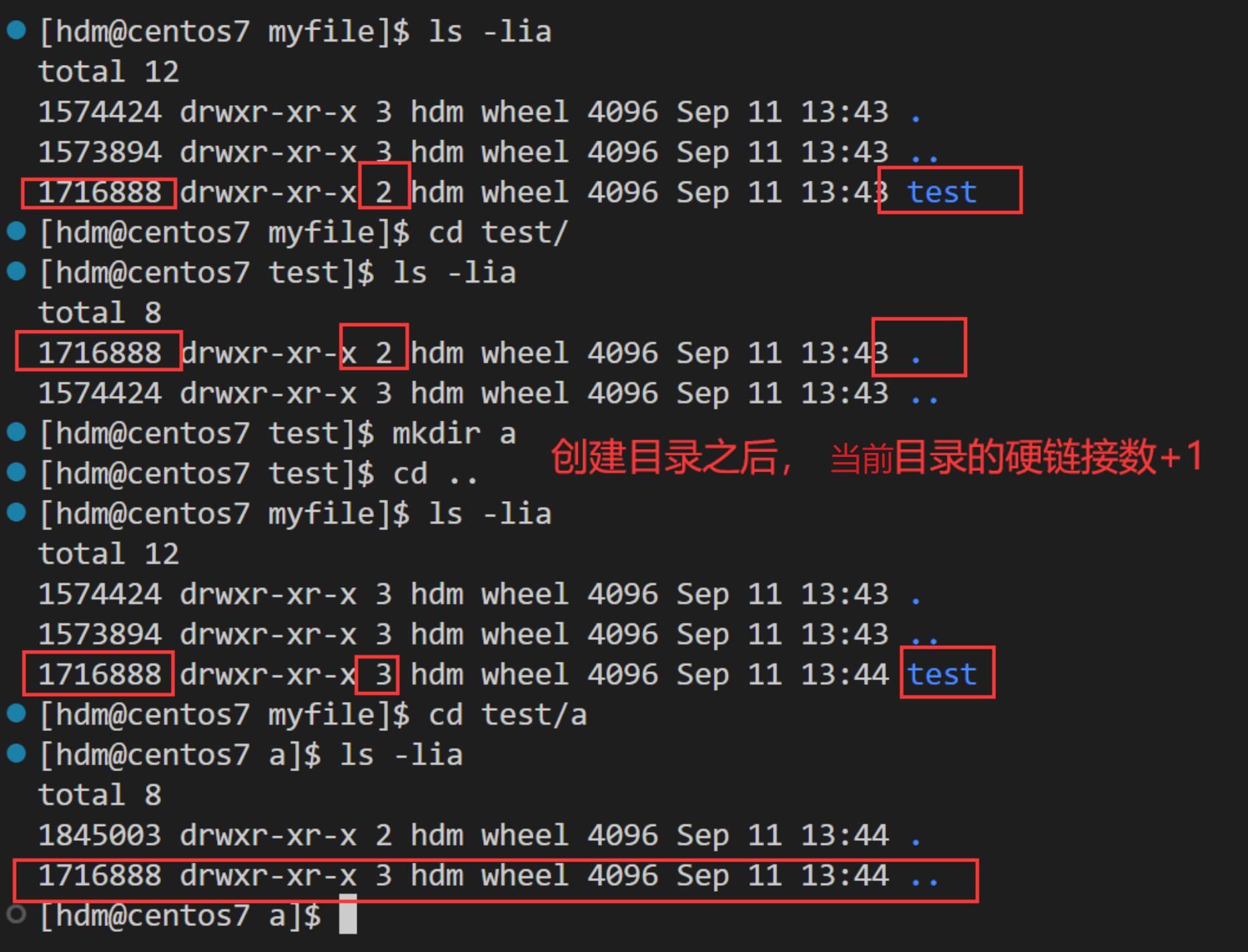
为什么创建目录之后,它的当前目录硬链接数会加一?
因为在当前目录比如test下创建一个目录比如a,那么进入这个目录a之后,里面会存在两个隐藏目录, 一个. ..对应的含义分别是当前目录和上级,而这个 ..就是对上级目录test的硬链接。而且这样对目录的硬链接我们普通用户自己不能进行操作,只能由操作系统分配
为什么我们自己不能对目录进行硬链接?
- 循环链接问题: 允许目录硬链接可能导致循环链接的问题。当一个目录被硬连接到另一个目录时,可以创建一个链接链,其中一个目录包含硬连接到另一个目录,而另一个目录包含硬连接到第一个目录,从而形成一个无限循环的链接链。这种循环链接对文件系统的稳定性和可用性造成了严重威胁,因为它会导致文件系统陷入无限循环的操作中。
- 文件系统的一致性和安全性: 目录是用于组织文件和子目录的结构,包括文件和子目录的层次结构和元数据(如权限、所有者等)。如果允许硬链接目录,可能会导致混淆和权限问题。例如,不同的用户或进程可以在不同位置创建硬链接,这可能导致混淆和权限冲突。目录硬链接可能会对文件系统的一致性和安全性造成严重影响。
- 性能问题: 如果目录可以硬连接,那么在处理目录结构时,文件系统必须处理硬链接的情况,这可能导致性能问题和更复杂的目录操作实现。
软链接
硬链接是通过inode引用另外一个文件,软链接是通过名字引用另外一个文件,在shell中的做法
软连接其实就跟windows系统上的文件快捷方式一样,只要被链接那个文件删除了,那么软连接也将失效
//ln 属于软链接的文件 软链接文件的名字
ln -s file file.link
[hdm@centos7 BasicIO]$ touch myfile
[hdm@centos7 BasicIO]$ ls -li
1574424 -rw-r--r-- 1 hdm wheel 0 Sep 11 13:34 myfile
[hdm@centos7 BasicIO]$ ln -s myfile myfile.link.s
[hdm@centos7 BasicIO]$ ls -li
1574424 -rw-r--r-- 1 hdm wheel 0 Sep 11 13:34 myfile
1574967 lrwxrwxrwx 1 hdm wheel 6 Sep 11 13:34 myfile.link.s -> myfile
我们在用 stat命令进行查看文件属性的时候,会出现三行时间,那它们分别代表上面含义呢?
-
Access 最后访问时间
访问时间: 访问时间是文件或目录上一次被访问的时间。每当文件或目录被打开、读取或执行时,访问时间都会被更新。访问时间的记录有助于了解文件或目录的访问频率,但在某些情况下,频繁更新访问时间可能会对性能产生影响。可以使用
stat或ls -lu命令查看文件的访问时间。 -
Modify 文件内容最后修改时间
访问时间: 访问时间是文件或目录上一次被访问的时间。每当文件或目录被打开、读取或执行时,访问时间都会被更新。访问时间的记录有助于了解文件或目录的访问频率,但在某些情况下,频繁更新访问时间可能会对性能产生影响。可以使用
stat或ls -lu命令查看文件的访问时间。 -
Change 属性最后修改时间
更改时间: 更改时间是文件或目录上一次元数据(metadata)发生更改的时间。元数据包括文件的权限、所有者、链接数等信息。当文件的元数据发生更改时(例如,文件的权限被修改),更改时间将被更新。更改时间还包括文件或目录的创建时间。可以使用
stat命令查看文件的更改时间。
5. 动态库和静态库
动态库和静态库是在编程中常用的两种库文件类型,它们有不同的特点和用途。
- 静态库(Static Library):
- 静态库是一组已编译的对象文件的集合,通常以
.a(在Unix/Linux)或.lib(在Windows)为文件扩展名。 - 当你将静态库链接到一个可执行文件中时,编译器会将库中的代码和数据复制到最终的可执行文件中。
- 静态库使得可执行文件具有所有必需的代码,因此它们通常较大。
- 静态库的优点是独立性,不需要依赖外部库文件,但可能导致可执行文件变得较大。
- 静态库是一组已编译的对象文件的集合,通常以
- 动态库(Dynamic Link Library, DLL,或Shared Library):
- 动态库也是一组已编译的对象文件的集合,通常以
.dll(在Windows)或.so(在Unix/Linux)为文件扩展名。 - 与静态库不同,动态库的代码和数据不会被复制到可执行文件中。相反,可执行文件包含指向库的引用,库在运行时加载到内存中。
- 动态库使得多个程序可以共享同一份库,节省了磁盘和内存空间。
- 动态库的缺点是,如果库文件不存在或版本不匹配,程序可能无法运行。
- 动态库也是一组已编译的对象文件的集合,通常以
选择使用动态库还是静态库取决于项目的需求和设计。通常情况下:
- 使用动态库可以减小可执行文件的大小,因为多个程序可以共享同一个库。
- 使用静态库可以确保可执行文件的独立性,不受外部库的影响,但可能导致可执行文件变得较大。
生成静态库
我们可以自己制定一个动静态库来测试,例如
/add.h/
#ifndef __ADD_H__
#define __ADD_H__
int add(int a, int b);
#endif // __ADD_H__
/add.c/
#include "add.h"
int add(int a, int b){
return a + b;
}
/sub.h/
#ifndef __SUB_H__
#define __SUB_H__
int sub(int a, int b);
#endif // __SUB_H__
/add.c/
#include "add.h"
int sub(int a, int b){
return a - b;
}
///main.c
#include <stdio.h>
#include "add.h"
#include "sub.h"
int main(void)
{
int a = 10;
int b = 20;
printf("add(%d,%d)=%d\n", a, b, add(a, b));
a = 100;
b = 200;
printf("sub(%d,%d)=%d\n", a, b, sub(a, b));
}
[hdm@centos7 myfile]$ ls
add.c add.h main.c sub.c sub.h
[hdm@centos7 myfile]$ gcc -c add.c -o add.o
[hdm@centos7 myfile]$ gcc -c sub.c -o sub.o
生成静态库
[hdm@centos7 myfile]$ ar -rc libmymath.a add.o sub.o
ar是gnu归档工具,rc表示(replace and create)
查看静态库中的目录列表
[hdm@centos7 myfile]$ ar -tv libmymath.a
rw-r--r-- 1000/10 1240 Sep 11 15:49 2023 add.o
rw-r--r-- 1000/10 1232 Sep 11 15:50 2023 sub.o
t:列出静态库中的文件
v:verbose 详细信息
[hdm@centos7 myfile]$ gcc main.c -L. -lmymath
-L 指定库路径
-l 指定库名
测试目标文件生成后,静态库删掉,程序照样可以运行。
库搜索路径
从左到右搜索-L指定的目录。
由环境变量指定的目录 (LIBRARY_PATH)
由系统指定的目录
/usr/lib
/usr/local/lib
生成动态库
shared: 表示生成共享库格式
fPIC:产生位置无关码(position independent code)
库名规则:libxxx.so
[hdm@centos7 myfile]$ ls
add.c add.h add.o libmymath.a main.c sub.c sub.h sub.o
[hdm@centos7 myfile]$ gcc -fPIC -c sub.c add.c
[hdm@centos7 myfile]$ gcc -shared -o libmymath.so *.o
[hdm@centos7 myfile]$ ls -l
total 44
-rw-r--r-- 1 hdm wheel 57 Sep 11 15:42 add.c
-rw-r--r-- 1 hdm wheel 0 Sep 11 15:36 add.h
-rw-r--r-- 1 hdm wheel 1240 Sep 11 15:57 add.o
-rw-r--r-- 1 hdm wheel 2680 Sep 11 15:50 libmymath.a
-rwxr-xr-x 1 hdm wheel 15824 Sep 11 15:58 libmymath.so
-rw-r--r-- 1 hdm wheel 236 Sep 11 15:52 main.c
-rw-r--r-- 1 hdm wheel 57 Sep 11 15:43 sub.c
-rw-r--r-- 1 hdm wheel 66 Sep 11 15:42 sub.h
-rw-r--r-- 1 hdm wheel 1232 Sep 11 15:57 sub.o
使用动态库
编译选项
l:链接动态库,只要库名即可(去掉lib以及版本号)
L:链接库所在的路径.
示例: gcc main.c -lmymath -L.
运行动态库
1、拷贝.so文件到系统共享库路径下, 一般指/usr/lib(需要管理员权限)
2、更改 LD_LIBRARY_PATH