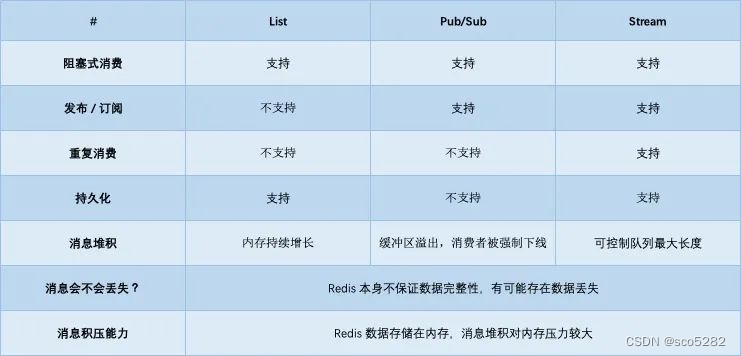
消息队列需要满足的要求:
- 顺序一致:要保证消息发送的顺序和消费的顺序是一致的,不一致的话可能会导致业务上的错误
- 消息确认机制:对于一个已经被消费的消息(已经收到ACK)不能再次被消费
- 消息持久化:要具有持久化的能力,避免消息丢失,这样当消费者异常宕机导致再次重启后需要重新消费消息时可以再次获取
Redis 提供了三种不同的方式来实现消息队列:
- list 结构:基于 list 结构模拟消息队列
- pubsub:点对点消息模型
- stream:比较完善的消息队列模型
1. 基于 list 结构
因为 list 底层的实现就是一个「链表」,在头部和尾部操作元素,时间复杂度都是 O(1),这意味着它非常符合消息队列的模型
如果你的业务需求足够简单,想把 Redis 当作队列来使用,肯定最先想到的就是使用 list 这个数据类型
常用的命令:
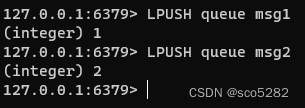
lpush:发布消息rpop:拉取消息brpop:阻塞拉取消息
生产者:
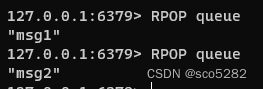
消费者:
这个模型非常简单,如下图:
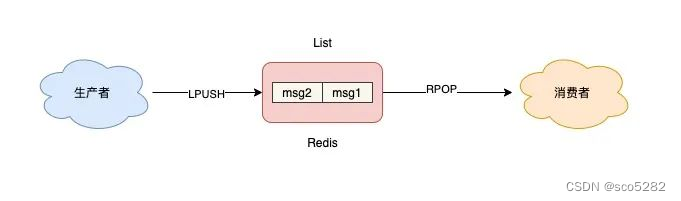
当队列中已经没有消息了,消费者在执行 RPOP 时,会返回 NULL

我们在编写消费者逻辑时,一般是一个「死循环」,这个逻辑需要不断地从队列中拉取消息进行处理,伪代码一般会这么写:
while true:
msg = redis.rpop("queue")
// 没有消息,继续循环
if msg == null:
continue
// 处理消息
handle(msg)
问题 1:如果此时队列为空,那消费者依旧会频繁拉取消息,这会造成「CPU 空转」,不仅浪费 CPU 资源,还会对 Redis 造成压力
怎么解决这个问题呢?
当队列为空时,我们可以「休眠」一会,再去尝试拉取消息。代码可以修改成这样:
while true:
msg = redis.rpop("queue")
// 没有消息,休眠2s
if msg == null:
sleep(2)
continue
// 处理消息
handle(msg)
这就解决了 CPU 空转问题
问题 2:但又带来另外一个问题:当消费者在休眠等待时,有新消息来了,那消费者处理新消息就会存在「延迟」
假设设置的休眠时间是 2s,那新消息最多存在 2s 的延迟。
要想缩短这个延迟,只能减小休眠的时间。但休眠时间越小,又有可能引发 CPU 空转问题
Redis 确实提供了「阻塞式」拉取消息的命令:BRPOP / BLPOP。这里的 B 指的是阻塞(Block)
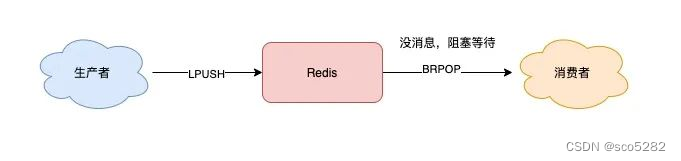
现在,你可以这样来拉取消息了:
while true:
// 没消息阻塞等待,0表示不设置超时时间
msg = redis.brpop("queue", 0)
if msg == null:
continue
// 处理消息
handle(msg)
使用 BRPOP 这种阻塞式方式拉取消息时,还支持传入一个「超时时间」,如果设置为 0,则表示不设置超时,直到有新消息才返回,否则会在指定的超时时间后返回 NULL
注意:如果设置的超时时间太长,这个连接太久没有活跃过,可能会被 Redis Server 判定为无效连接,之后 Redis Server 会强制把这个客户端踢下线。所以,采用这种方案,客户端要有重连机制
使用 Jedis 实现:https://blog.csdn.net/jam_yin/article/details/130967040
优点:
- 利用 Redis 存储,不受 JVM 内存上限
- 基于 Redis 的持久化机制,数据安全有保证
- 可以满足消息有序性
缺点:
- 不支持重复消费:消费者拉取消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费,即不支持多个消费者消费同一批数据
- 消息丢失:消费者拉取到消息后,如果发生异常宕机,那这条消息就丢失了(因为从 List 中 POP 一条消息出来后,这条消息就会立即从链表中删除了。也就是说,无论消费者是否处理成功,这条消息都没办法再次消费了)
2. 基于 Pub-Sub 模式
【Redis】Redis 的学习教程(九)之 发布 Pub、订阅 Sub
Redis 提供了以下命令来完成发布、订阅的操作:
SUBSCRIBE:订阅一个或多个频道UNSUBSCRIBE:取消订阅一个或多个频道PSUBSCRIBE:订阅一个或多个模式PUNSUBSCRIBE:取消订阅一个或多个模式
2.1 通过频道(Channel)进行发布订阅
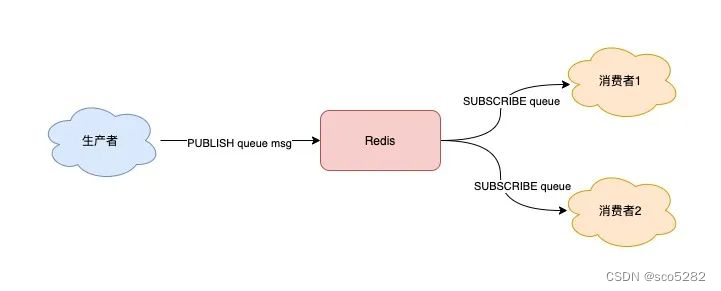
1、消费者订阅队列
使用 SUBSCRIBE 命令,启动 2 个消费者,并「订阅」同一个队列
此时,2 个消费者都会被阻塞住,等待新消息的到来
2、生产者发布消息
3、消费者解除阻塞,接收消息
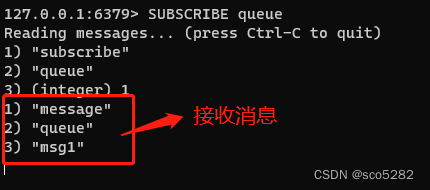
使用 Pub/Sub 这种方案,既支持阻塞式拉取消息,还很好地满足了多组消费者,消费同一批数据的业务需求
2.2 使用模式(Pattern)匹配实现发布订阅
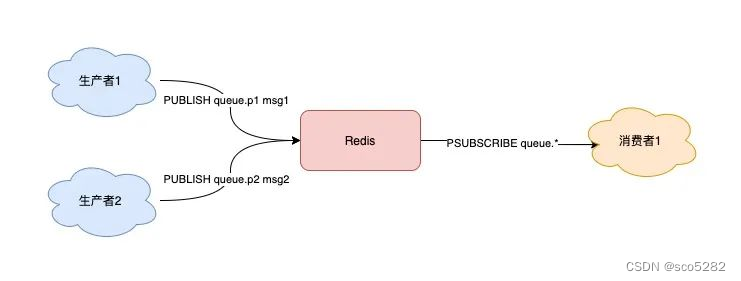
1、消费者订阅队列
消费者订阅 queue.* 相关的队列消息
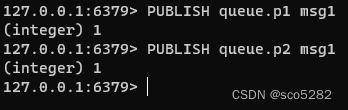
2、生产者发布消息
生产者分别向 queue.p1 和 queue.p2 发布消息
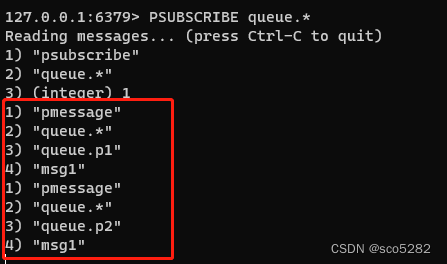
3、消费者解除阻塞,接收消息
消费者接收到这 2 个生产者的消息
Pub/Sub 最大的优势就是,支持多组生产者、消费者处理消息;最大问题是:丢数据
如果发生以下场景,就有可能导致数据丢失:
- 消费者下线
- Redis 宕机
- 消息堆积
Pub/Sub 在实现时非常简单,它没有基于任何数据类型,也没有做任何的数据存储,它只是单纯地为生产者、消费者建立「数据转发通道」,把符合规则的数据,从一端转发到另一端
一个完整的发布、订阅消息处理流程是这样的:
- 消费者订阅指定队列,Redis 就会记录一个映射关系:队列->消费者
- 生产者向这个队列发布消息,那 Redis 就从映射关系中找出对应的消费者,把消息转发给它
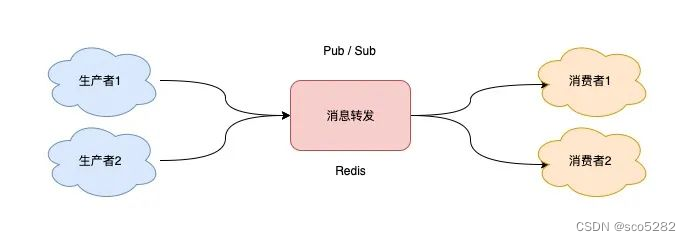
整个过程中,没有任何的数据存储,一切都是实时转发的
这种设计方案,就导致了上面提到的那些问题:例如,如果一个消费者异常挂掉了,它再重新上线后,只能接收新的消息,在下线期间生产者发布的消息,因为找不到消费者,都会被丢弃掉。如果所有消费者都下线了,那生产者发布的消息,因为找不到任何一个消费者,也会全部「丢弃」
所以,当你在使用 Pub/Sub 时,一定要注意:消费者必须先订阅队列,生产者才能发布消息,否则消息会丢失。Pub/Sub 的相关操作,不会写入到 RDB 和 AOF 中,当 Redis 宕机重启,Pub/Sub 的数据也会全部丢失
Pub/Sub 在处理「消息积压」时,为什么也会丢数据?
当消费者的速度,跟不上生产者时,就会导致数据积压的情况发生。
如果采用 list 当作队列,消息积压时,会导致这个链表很长,最直接的影响就是,Redis 内存会持续增长,直到消费者把所有数据都从链表中取出
但 Pub/Sub 的处理方式却不一样,当消息积压时,有可能会导致消费失败和消息丢失!
从 Pub/Sub 的实现细节上来说:每个消费者订阅一个队列时,Redis 都会在 Server 上给这个消费者在分配一个「缓冲区」,这个缓冲区其实就是一块内存。当生产者发布消息时,Redis 先把消息写到对应消费者的缓冲区中。之后,消费者不断地从缓冲区读取消息,处理消息。
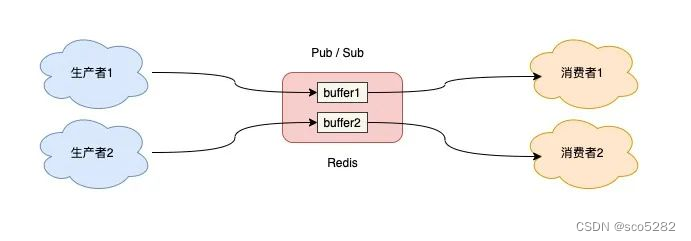
但是,问题就出在这个缓冲区上。
因为这个缓冲区其实是有「上限」的(可配置),如果消费者拉取消息很慢,就会造成生产者发布到缓冲区的消息开始积压,缓冲区内存持续增长。如果超过了缓冲区配置的上限,此时,Redis 就会「强制」把这个消费者踢下线。这时消费者就会消费失败,也会丢失数据。
从 Redis 的配置文件可以看到这个缓冲区的默认配置:client-output-buffer-limit pubsub 32mb 8mb 60
- 32mb:缓冲区一旦超过 32MB,Redis 直接强制把消费者踢下线
- 8mb + 60:缓冲区超过 8MB,并且持续 60 秒,Redis 也会把消费者踢下线
Pub/Sub 的这一点特点,是与 list 作队列差异比较大的:list 其实是属于「拉」模型,而 Pub/Sub 其实属于「推」模型。
- list 中的数据可以一直积压在内存中,消费者什么时候来「拉」都可以
- Pub/Sub 是把消息先「推」到消费者在 Redis Server 上的缓冲区中,然后等消费者再来取。当生产、消费速度不匹配时,就会导致缓冲区的内存开始膨胀,Redis 为了控制缓冲区的上限,强制把消费者踢下线的机制
优点:
- 支持发布 / 订阅,支持多组生产者、消费者处理消息
缺点:
- 消费者下线,数据会丢失
- 不支持数据持久化,Redis 宕机,数据也会丢失
- 消息堆积,缓冲区溢出,消费者会被强制踢下线,数据也会丢失
3. 基于 Stream 的消息队列
Redis 作者在开发 Redis 期间,还另外开发了一个开源项目 disque。这个项目的定位,就是一个基于内存的分布式消息队列中间件。但由于种种原因,这个项目一直不温不火。终于,在 Redis 5.0 版本,作者把 disque 功能移植到了 Redis 中,并给它定义了一个新的数据类型:Stream
Stream 本质上是 Redis 中的 key,相关指令根据可以分为两类,分别是消息队列相关指令,消费组相关指令。
消息队列相关指令:
| 指令名称 | 指令作用 |
|---|---|
| XADD | 添加消息到队列末尾 |
| XREAD | 获取消息(阻塞/非阻塞),返回大于指定 ID 的消息 |
| XLEN | 获取 Stream 中的消息长度 |
| XDEL | 删除消息 |
| XRANGE | 获取消息列表(可以指定范围),忽略删除的消息 |
| XREVRANGE | 和XRANGE相比区别在于反向获取,ID从大到小 |
| XTRIM | 限制 Stream 的长度,如果已经超长会进行截取 |
消费组相关指令:
| 指令名称 | 指令作用 |
|---|---|
| XGROUP CREATE | 创建消费者组 |
| XREADGROUP | 读取消费者组中的消息 |
| XACK | ack 消息,消息被标记为“已处理” |
| XGROUP SETID | 设置消费者组最后递送消息的ID |
| XGROUP DELCONSUMER | 删除消费者组 |
| XPENDING | 打印待处理消息的详细信息 |
| XCLAIM | 转移消息的∂归属权(长期未被处理/无法处理的消息,转交给其他消费者组进行处理) |
| XINFO | 打印 Stream\Consumer\Group 的详细信息 |
| XINFO GROUPS | 打印消费者组的详细信息 |
| XINFO STREAM | 打印 Stream 的详细信息 |
3.1 通过 XREAD 命令读取消息
命令如下:
XADD:发布消息。XADD key [NOMKSTREAM] [MAXLEN|MINID [= | ~] threshold [LIMIT count]] *|ID field value [field value ...]- [NOMKSTREAM]:如果队列不存在,是否自动创建队列。默认 是
- [MAXLEN|MINID [= | ~] threshold [LIMIT count]]:设置消息队列的最大消息数量
- |ID:消息的唯一 ID。 表示由 Redis 自动生成,格式:时间戳-递增数字
- field value [field value …]:发送到队列中的消息 Entry,格式是 key-value
如:创建一个名为 mystream 的队列,并向其发送消息 {“name”:“zzc”, “age”: 26},使用 Redis 的递增 ID
xadd mystream * name zzc age 26
XREAD:读取消息。XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key...] ID [ID ...]- [COUNT count]:每次读取消息的最大数量
- [BLOCK milliseconds]:当没有消息时,是否阻塞、阻塞时长
- STREAMS key [key…]:要从哪个队列读取消息,key 就是队列名
- ID [ID …]:起始 ID,只返回大于该 ID 的消息。0:从第一个消息开始;$:从最新的消息开始
如:从名为 mystream 的队列读取最新的消息,每次读取 1 条
XREAD COUNT 1 BLOCK 0 STREAMS mystream $
生产者:
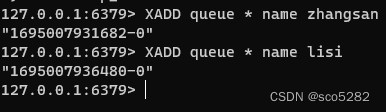
消费者:
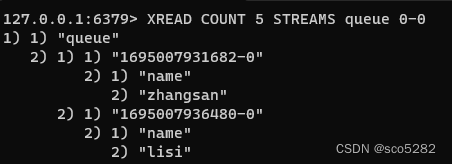
3.2 通过 消费者组 命令读取消息
消费者组:将多个消费者划分到一个组,监听同一个队列,具备如下特点:
- 消息分流:队列中的消息会分流给组内的不同消费者,而不是重复消费,从而加快消息处理的速度
- 消息标识:消费者组会维护一个标识:记录最后一个被处理的消息。哪怕消费者宕机重启,还会从标识之后读取消息,确保每一个消息都会被消费
- 消息确认:消费者读取消息之后,消息处于 pending 状态,并存入一个 pending-list。当处理完成后,需要通过 ACK 来确认消息,标记为已处理,才会从 pending-list 移除
命令如下:
XGROUP CREATE:创建消费者组。XGROUP CREATE key groupName ID|$ [NOMKSTREAM]- key:队列名称
- groupName:消费者组名称
- ID:起始 ID 标识。0:第一个消息;$:从最新的消息
- NOMKSTREAM:如果队列不存在,是否自动创建队列。默认 是
创建消费者组:在队列 mystream 创建一个消费者组 mystreamGroup,从第一个消息开始读取
XGROUP CREATE mystream mystreamGroup 0
XREADGROUP:从消费者组读取消息。XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]- group:消费者组名称
- consumer:消费者名称。如果消费者名称不存在,会自动创建一个消费者
- count:本次查询的最大数量
- milliseconds:当没有消息时最长等待时间
- NOACK:无需手动 ACK,获取到消息时自动确认
- STREAMS key:指定队列名称
- ID:获取消息的起始 ID。“>”:从下一个未消费的消息开始(正常情况下推荐);其它:根据指定 id 从 pending-list 中获取已消费但未确认的消息。例如:0 是从 pending-list 中第一个消息开始
消费者 c1 从队列 mystream 中的消费者组 mystreamGroup 读取消息,2000 毫秒内读取不到返回
XREADGROUP GROUP mystreamGroup c1 COUNT 1 BLOCK 2000 STREAMS mystream
其它命令:
// 删除指定的消费者组
XGROUP DESTROY key groupName
// 给指定的消费者组添加消费者
XGROUP CREATECONSUMER key groupName consumername
// 删除消费者组中指定的消费者
XGROUP DELCONSUMER key groupName consumername
生产者:
生产者发送两条消息:

创建消费者组:
开启 2 组消费者处理同一批数据,就需要创建 2 个消费者组。0-0:从头拉取消息

消费者:
消费者组创建好之后,我们可以给每个「消费者组」下面挂一个「消费者」,让它们分别处理同一批数据
第一个消费组开始消费:
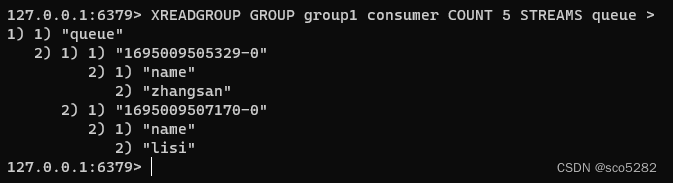
第二个消费组开始消费:
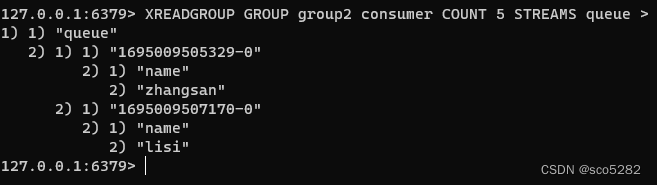
可以看到,这 2 组消费者,都可以获取同一批数据进行处理了。这样一来,就达到了多组消费者「订阅」消费的目的
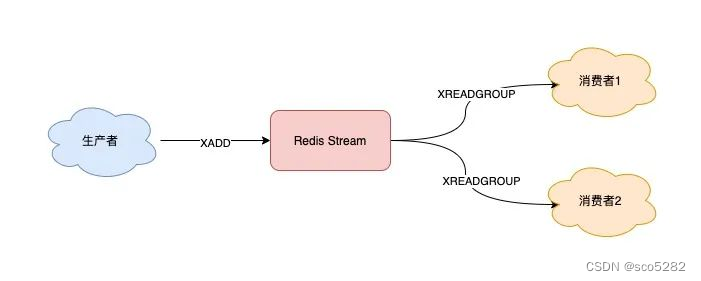
3.2.1 消息处理时异常,Stream 保证消息不丢失,重新消费
若某个消费者,消费了某条消息,但是并没有处理成功时(例如消费者进程宕机),这条消息可能会丢失,因为组内其他消费者不能再次消费到该消息了
当一组消费者处理完消息后,需要执行 XACK 命令告知 Redis,这时 Redis 就会把这条消息标记为「处理完成」
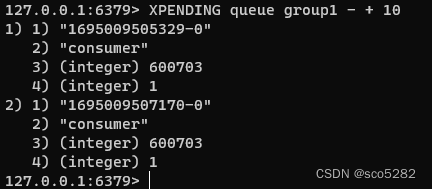
XPENDING:为了解决组内消息读取但处理期间消费者崩溃带来的消息丢失问题,Stream 设计了 Pending 列表,用于记录读取但并未确认完毕的消息。XPENDING key group [start end count] [consumer]- key:队列名
- group:消费者组名称
- start:开始值。-:最小值
- end:结束值。+:最大值
- count 数量
XACK:对于已读取未处理的消息,使用命令 XACK 完成告知消息处理完成。XACK 命令确认消费的信息,一旦信息被确认处理,就表示信息被完善处理。XACK key group ID [ID ...]
查询已经消费但未处理(未 ACK)的消息:
ACK 消息:
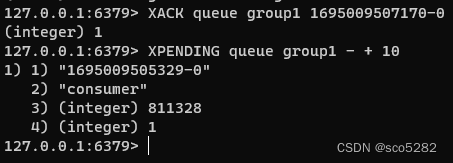
如果消费者异常宕机,肯定不会发送 XACK,那么 Redis 就会依旧保留这条消息。
待这组消费者重新上线后,Redis 就会把之前没有处理成功的数据,重新发给这个消费者。这样一来,即使消费者异常,也不会丢失数据了
3.2.2 代码实现
①:引入 redis 依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
②:配置
spring:
redis:
host: localhost
port: 6379
password:
timeout: 2000s
# 配置文件中添加 lettuce.pool 相关配置,则会使用到lettuce连接池
lettuce:
pool:
max-active: 8 # 连接池最大连接数(使用负值表示没有限制) 默认为8
max-wait: -1ms # 接池最大阻塞等待时间(使用负值表示没有限制) 默认为-1ms
max-idle: 8 # 连接池中的最大空闲连接 默认为8
min-idle: 0 # 连接池中的最小空闲连接 默认为 0
main:
allow-circular-references: true
redis:
mq:
streams:
# key名称
- name: redis:mq:streams:key1
groups:
# 消费者组名称
- name: group1
# 消费者名称
consumers: group1-con1, group1-con2
- name: redis:mq:streams:key2
groups:
- name: group2
consumers: group2-con1, group2-con2
- name: redis:mq:streams:key3
groups:
- name: group3
consumers: group3-con1, group3-con2
队列、消费者组、消费者 通过配置文件进行配置
③:Redis 配置类
@Slf4j
@Configuration
public class RedisConfig {
@Resource
private RedisMqProperties redisMqProperties;
@Resource
private RedisStreamUtil redisStreamUtil;
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
// json 序列化配置
Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
jackson2JsonRedisSerializer.setObjectMapper(om);
// String 序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// 所有的 key 采用 string 的序列化
template.setKeySerializer(stringRedisSerializer);
// 所有的 value 采用 jackson 的序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash 的 key 采用 string 的序列化
template.setHashKeySerializer(stringRedisSerializer);
// hash 的 value 采用 jackson 的序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
@Bean
public RedisMessageListenerContainer container(RedisConnectionFactory redisConnectionFactory, RedisMessageListener listener, MessageListenerAdapter adapter) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
// 设置连接工厂
container.setConnectionFactory(redisConnectionFactory);
// 所有的订阅消息,都需要在这里进行注册绑定,new PatternTopic("topic")表示发布的主题信息。可以添加多个 messageListener,配置不同的通道
container.addMessageListener(listener, new PatternTopic("topic1"));
container.addMessageListener(adapter, new PatternTopic("topic2"));
// 设置序列化对象:① 发布的时候需要设置序列化;订阅方也需要设置序列化;② 设置序列化对象必须放在[加入消息监听器]这一步后面,否则会导致接收器接收不到消息
Jackson2JsonRedisSerializer seria = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
seria.setObjectMapper(objectMapper);
container.setTopicSerializer(seria);
return container;
}
@Bean
public MessageListenerAdapter listenerAdapter(PrintMessageReceiver printMessageReceiver) {
MessageListenerAdapter receiveMessage = new MessageListenerAdapter(printMessageReceiver, "receiveMessage");
Jackson2JsonRedisSerializer seria = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
seria.setObjectMapper(objectMapper);
receiveMessage.setSerializer(seria);
return receiveMessage;
}
@Bean
public List<Subscription> subscription(RedisConnectionFactory factory){
List<Subscription> resultList = new ArrayList<>();
AtomicInteger index = new AtomicInteger(1);
int processors = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor executor = new ThreadPoolExecutor(processors, processors, 0, TimeUnit.SECONDS,
new LinkedBlockingDeque<>(), r -> {
Thread thread = new Thread(r);
thread.setName("async-stream-consumer-" + index.getAndIncrement());
thread.setDaemon(true);
return thread;
});
StreamMessageListenerContainer.StreamMessageListenerContainerOptions<String, MapRecord<String, String, String>> options =
StreamMessageListenerContainer
.StreamMessageListenerContainerOptions
.builder()
// 一次最多获取多少条消息
.batchSize(5)
.executor(executor)
.pollTimeout(Duration.ofSeconds(1))
.errorHandler(throwable -> log.error("[MQ handler exception]" + throwable.getMessage()))
.build();
for (RedisMqStream redisMqStream : redisMqProperties.getStreams()) {
String streamName = redisMqStream.getName();
RedisMqGroup redisMqGroup = redisMqStream.getGroups().get(0);
initStream(streamName,redisMqGroup.getName());
var listenerContainer = StreamMessageListenerContainer.create(factory,options);
// 手动ask消息
Subscription subscription = listenerContainer.receive(Consumer.from(redisMqGroup.getName(), redisMqGroup.getConsumers()[0]),
StreamOffset.create(streamName, ReadOffset.lastConsumed()), new ReportReadMqListener());
// 自动ask消息
/* Subscription subscription = listenerContainer.receiveAutoAck(Consumer.from(redisMqGroup.getName(), redisMqGroup.getConsumers()[0]),
StreamOffset.create(streamName, ReadOffset.lastConsumed()), new ReportReadMqListener());*/
resultList.add(subscription);
listenerContainer.start();
}
ReportReadMqListener.redisStreamUtil = redisStreamUtil;
return resultList;
}
private void initStream(String key, String group) {
boolean hasKey = redisStreamUtil.hasKey(key);
if(!hasKey){
Map<String,Object> map = new HashMap<>(1);
map.put("field","value");
//创建主题
String result = redisStreamUtil.addMap(key, map);
//创建消费组
redisStreamUtil.createGroup(key, group);
//将初始化的值删除掉
redisStreamUtil.del(key, result);
log.info("stream:{}-group:{} initialize success",key, group);
}
}
}
④:消费者组的配置对应的 Java 类
RedisMqProperties:所有的 队列
@Data
@Configuration
@EnableConfigurationProperties
@ConfigurationProperties(prefix = "redis.mq")
public class RedisMqProperties {
// 所有队列
public List<RedisMqStream> streams;
}
RedisMqStream:队列封装类
@Data
public class RedisMqStream {
// 队列
public String name;
// 消费者组
public List<RedisMqGroup> groups;
}
RedisMqGroup:消费者组
@Data
public class RedisMqGroup {
// 消费者组名
private String name;
// 消费者
private String[] consumers;
}
⑤:RedisStreamUtil:操作 Stream 的工具类
@Component
public class RedisStreamUtil {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 创建消费组
public String createGroup(String key, String group){
return redisTemplate.opsForStream().createGroup(key, group);
}
// 获取消费者信息
public StreamInfo.XInfoConsumers queryConsumers(String key, String group){
return redisTemplate.opsForStream().consumers(key, group);
}
public StreamInfo.XInfoGroups queryGroups(String key) {
return redisTemplate.opsForStream().groups(key);
}
// 添加Map消息
public String addMap(String key, Map<String, Object> value){
return redisTemplate.opsForStream().add(key, value).getValue();
}
// 读取消息
public List<MapRecord<String, Object, Object>> read(String key){
return redisTemplate.opsForStream().read(StreamOffset.fromStart(key));
}
// 确认消费
public Long ack(String key, String group, String... recordIds){
return redisTemplate.opsForStream().acknowledge(key, group, recordIds);
}
// 删除消息。当一个节点的所有消息都被删除,那么该节点会自动销毁
public Long del(String key, String... recordIds){
return redisTemplate.opsForStream().delete(key, recordIds);
}
// 判断是否存在key
public boolean hasKey(String key){
Boolean aBoolean = redisTemplate.hasKey(key);
return aBoolean != null && aBoolean;
}
}
⑥:消费者
@Slf4j
@Component
public class ReportReadMqListener implements StreamListener<String, MapRecord<String, String, String>> {
public static RedisStreamUtil redisStreamUtil;
@Override
public void onMessage(MapRecord<String, String, String> message) {
// stream的key值
String streamKey = message.getStream();
//消息ID
RecordId recordId = message.getId();
//消息内容
Map<String, String> msg = message.getValue();
//TODO 处理逻辑
log.info("【streamKey】= " + streamKey + ",【recordId】= " + recordId + ",【msg】=" + msg);
//逻辑处理完成后,ack消息,删除消息,group为消费组名称
StreamInfo.XInfoGroups xInfoGroups = redisStreamUtil.queryGroups(streamKey);
xInfoGroups.forEach(xInfoGroup -> redisStreamUtil.ack(streamKey, xInfoGroup.groupName(), recordId.getValue()));
redisStreamUtil.del(streamKey, recordId.getValue());
}
}
⑦:发布消息
@GetMapping("/testStream")
public String testStream() {
HashMap<String, Object> message = new HashMap<>(2);
message.put("body", "消息主题" );
message.put("sendTime", "消息发送时间");
String streamKey = "redis:mq:streams:key2";
redisStreamUtil.addMap(streamKey, message);
return "testStream";
}
4. 总结