文章参考参考,在此基础上对人脸识别和神经风格转换的内容做一个简述。
人脸识别
模型构建
人脸识别仅仅用的表层特征做对比是远远不够的,这里用到的就是FaceNet的特征提取。由于FaceNet需要大量的数据以及长时间的训练,因此,遵循在应用深度学习设置中常见的实践,我们要加载其他人已经训练过的权值。哈哈哈哈哈哈,其实我也不知道怎么训练,模型是个啥样我都不知道,说白了就是我不会。
网络信息:该网络使用96x96的RGB图像作为输入,图像数量维m,输入数据的维度为(m, 3, 96, 96),输出为(m, 128)也就是一个m个128位的向量。
不管怎么说先加载一波模型,不得不说封装的真好,我都不知道怎么加载的......
from keras.models import Sequential
from keras.layers import Conv2D, ZeroPadding2D, Activation, Input, concatenate
from keras.models import Model
from keras.layers.normalization import BatchNormalization
from keras.layers.pooling import MaxPooling2D, AveragePooling2D
from keras.layers.merge import Concatenate
from keras.layers.core import Lambda, Flatten, Dense
from keras.initializers import glorot_uniform
from keras.engine.topology import Layer
from keras import backend as K
#------------用于绘制模型细节,可选--------------#
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
#------------------------------------------------#
K.set_image_data_format('channels_first')
import time
import cv2
import os
import numpy as np
from numpy import genfromtxt
import pandas as pd
import tensorflow as tf
import fr_utils
from inception_blocks_v2 import *
%matplotlib inline
%reload_ext autoreload
%autoreload 2
#获取模型
FRmodel = faceRecoModel(input_shape=(3,96,96)) #这个模型存在于inception_block_v2中
#打印模型的总参数数量
print("参数数量:" + str(FRmodel.count_params()))
#参数数量:3743280网络结构十分复杂,是我没见过的。随便看看,中间删掉了若干层,可以看到最后的输出是一个128位的向量,也就是从照片中提取的深层特征了。
FRmodel.summary() #可以看到最后输出的是一个(none, 128)的向量__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 3, 96, 96) 0
__________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D (None, 3, 102, 102) 0 input_1[0][0]
__________________________________________________________________________________________________
conv1 (Conv2D) (None, 64, 48, 48) 9472 zero_padding2d_1[0][0]
__________________________________________________________________________________________________
bn1 (BatchNormalization) (None, 64, 48, 48) 256 conv1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 64, 48, 48) 0 bn1[0][0]
__________________________________________________________________________________________________
zero_padding2d_2 (ZeroPadding2D (None, 64, 50, 50) 0 activation_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 64, 24, 24) 0 zero_padding2d_2[0][0]
__________________________________________________________________________________________________
conv2 (Conv2D) (None, 64, 24, 24) 4160 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
bn2 (BatchNormalization) (None, 64, 24, 24) 256 conv2[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 64, 24, 24) 0 bn2[0][0]
__________________________________________________________________________________________________
.......
__________________________________________________________________________________________________
concatenate_7 (Concatenate) (None, 736, 3, 3) 0 activation_35[0][0]
zero_padding2d_23[0][0]
activation_37[0][0]
__________________________________________________________________________________________________
average_pooling2d_4 (AveragePoo (None, 736, 1, 1) 0 concatenate_7[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 736) 0 average_pooling2d_4[0][0]
__________________________________________________________________________________________________
dense_layer (Dense) (None, 128) 94336 flatten_1[0][0]
__________________________________________________________________________________________________
lambda_1 (Lambda) (None, 128) 0 dense_layer[0][0]
==================================================================================================
Total params: 3,743,280
Trainable params: 3,733,968
Non-trainable params: 9,312三元损失
-
同一个人的两个图像的编码非常相似。
-
两个不同人物的图像的编码非常不同。
因此我们会给出一个同一个人的两个不同编码以及另外一个人的编码。三元损失会将同一个人的两个编码拉近,将不同人的编码分离。
代码中是利用二范数来计算编码距离,说白了就是差值的平方和。为了保证同一个人的编码差值比不同人的编码差小一定距离,这里加上了个间距alpha,然后和0再比较,这里的处理很像SVM的损失函数。
def triplet_loss(y_true, y_pred, alpha = 0.2):
anchor, positive,negative = y_pred[0],y_pred[1],y_pred[2]
pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,positive)),axis= -1)
neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,negative)),axis= -1)
basic_loss = tf.add(tf.subtract(pos_dist,neg_dist),alpha)
loss = tf.reduce_sum(tf.maximum(basic_loss,0))
return loss现在开始加载模型,之前加载的是一个模型框架,这边要给模型中的参数赋值
开始时间
start_time = time.clock()
#编译模型
FRmodel.compile(optimizer = 'adam', loss = triplet_loss, metrics = ['accuracy'])
#加载权值
fr_utils.load_weights_from_FaceNet(FRmodel) #根据层标签加载权重
#结束时间
end_time = time.clock()
#计算时差
minium = end_time - start_time
print("执行了:" + str(int(minium / 60)) + "分" + str(int(minium%60)) + "秒")模型应用
建造一个数据库,里面存储的是人的名字以及对应的编码,一旦有人刷了名字就查询其编码,然后计算差异。
database = {}
database["danielle"] = fr_utils.img_to_encoding("images/danielle.png", FRmodel)
database["younes"] = fr_utils.img_to_encoding("images/younes.jpg", FRmodel)
database["tian"] = fr_utils.img_to_encoding("images/tian.jpg", FRmodel)
database["andrew"] = fr_utils.img_to_encoding("images/andrew.jpg", FRmodel)
database["kian"] = fr_utils.img_to_encoding("images/kian.jpg", FRmodel)
database["dan"] = fr_utils.img_to_encoding("images/dan.jpg", FRmodel)
database["sebastiano"] = fr_utils.img_to_encoding("images/sebastiano.jpg", FRmodel)
database["bertrand"] = fr_utils.img_to_encoding("images/bertrand.jpg", FRmodel)
database["kevin"] = fr_utils.img_to_encoding("images/kevin.jpg", FRmodel)
database["felix"] = fr_utils.img_to_encoding("images/felix.jpg", FRmodel)
database["benoit"] = fr_utils.img_to_encoding("images/benoit.jpg", FRmodel)
database["arnaud"] = fr_utils.img_to_encoding("images/arnaud.jpg", FRmodel)验证过程中并不是使用三元损失来计算距离的,而是直接用二范数
def verify(image_path, identify, database,model):
encoding = fr_utils.img_to_encoding(image_path, model)
dist = np.linalg.norm(encoding - database[identify]) #三元损失的计算方式和距离的计算方式不同
if dist<0.7:
print("欢迎 " + str(identify) + "回家!")
is_door_open = True
else:
print("经验证,您与" + str(identify) + "不符!")
is_door_open = False
return dist,is_door_open上面的验证通过ID来查询编码,下面的验证是不需要ID的,直接通过拍摄的照片生成编码,遍历数据库查看是否有近似的
def who_is_it(image_path, database, model):
encoding = fr_utils.img_to_encoding(image_path, model)
min_dist = 100
for (name,db_enc) in database.items():
dist = np.linalg.norm(encoding - db_enc)
if dist < min_dist:
min_dist = dist
identity = name
if min_dist >0.7:
print("抱歉,您的信息不在数据库中。")
else:
print("姓名" + str(identity) + " 差距:" + str(min_dist))
return min_dist, identity神经风格转换
由于之前博客中使用的是tensorflow,不知道在讲什么。自己的理解和另一个博客相吻合,所以附加参考参考
这一部分用到的是迁移学习,就是将拿别人的网络来实现自己的想法。这里用的是VGG-19,同样我不知道VGG-19是个什么东西。还好有这张图,网络结构就很清晰了,这里运用时最后的两个FC是不需要的。

我们将会用两张图,一张作为内容,一张作为风格,输入到该网络中提取相应的特征,注意VGG-19网络的输入是400x300的3通道图像。

简单的来说该怎么做神经风格迁移。可以看到示意中有左中右三幅图,左边的作为风格,右边的作为内容,中间的是生成的图像。
左边:图像卷积运算的时候提取到风格特征,总共有五层,拿到的特征矩阵需要转化为风格矩阵
中间:我们会预先生成一张图片(给内容图片加噪),同样进行卷积,也会有5层特征,我们对这五层的特征进行运算,缩小他们的距离,那么中间图像的风格就和左边相近了。
右边:不同卷积层提取到的内容图像是不同的,我们将中间图像的第五层特征和内容图像的第四层特征做运算(这边可以和任何一层做对比,当然可以是第二层也可以是第三层),拉近他们之间的距离,那么中间图像和内容图像的内容就很像了。
实施细节
计算内容损失
内容损失计算比较简单,直接将生成图片的特征和内容图片的特征做差求平方,然后求和。
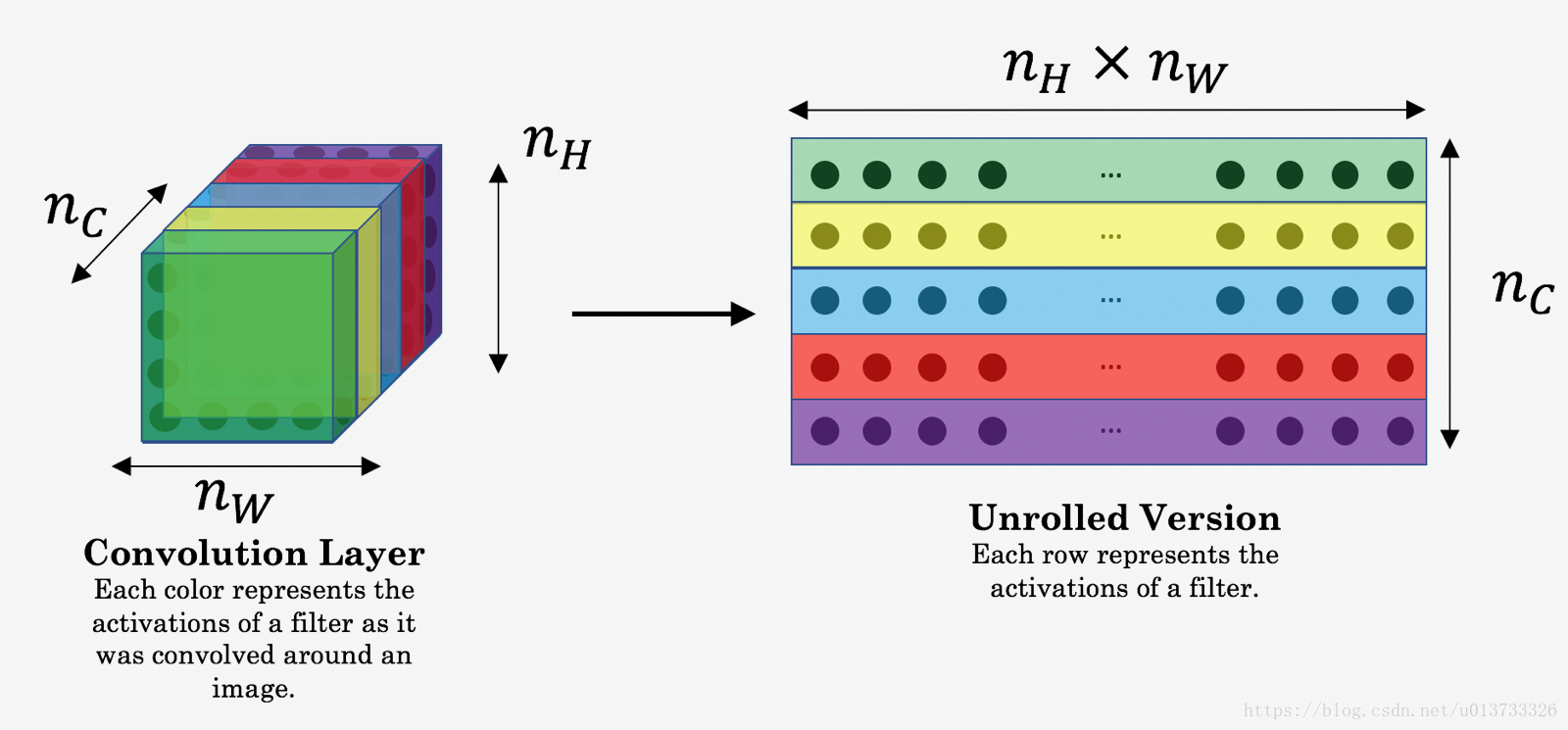
这里存在问题,代码中为简便计算将三维矩阵转换成为二维矩阵,但是,由于使用的特征不一样,生成图像用的第五层,内容图像用的第四层(或者其他层),明显不能转化到同样的维度,怎么可以计算的。转化方式如下面第一幅图
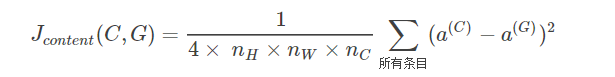
def compute_content_cost(a_C, a_G):
#计算内容代价函数
m, n_H, n_W, n_C = a_G.get_shape().as_list()
a_C_unrolled = tf.transpose(tf.reshape(a_C,[n_H*n_W,n_C]))
a_G_unrolled = tf.transpose(tf.reshape(a_G,[n_H*n_W,n_C]))
J_content = 1/(4*n_C*n_H*n_W)*tf.reduce_sum(tf.square(tf.subtract(a_C_unrolled,a_G_unrolled)))
return J_content计算风格损失
风格矩阵运用了“格拉姆矩阵”:
![]()
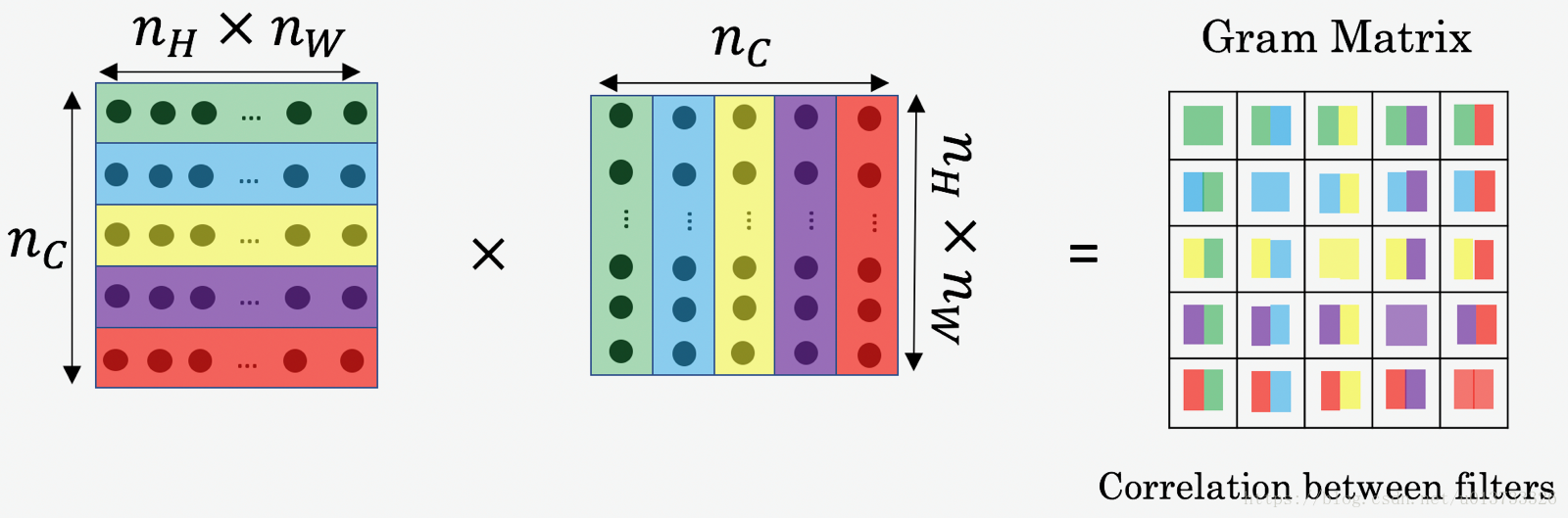
这里的矩阵A是一个二维的矩阵,是将每一层的特征矩阵转化过来的 ,转化方式如上第一幅图
def gram_matrix(A):
"""
计算矩阵A的风格矩阵
参数:
A -- 矩阵,维度为(n_C, n_H * n_W)
返回:
GA -- A的风格矩阵,维度为(n_C, n_C)
"""
GA = tf.matmul(A, A, transpose_b = True)
return GA有了特征矩阵可以来计算特征成本了:

def compute_layer_style_cost(a_S, a_G):
"""
计算单隐藏层的风格损失
参数:
a_S -- tensor类型,维度为(1, n_H, n_W, n_C),表示隐藏层中图像S的风格的激活值。
a_G -- tensor类型,维度为(1, n_H, n_W, n_C),表示隐藏层中图像G的风格的激活值。
返回:
J_content -- 实数,用上面的公式2计算的值。
"""
m, n_H, n_W, n_C = a_G.get_shape().as_list()
a_S = tf.transpose(tf.reshape(a_S,[n_H*n_W, n_C]))
a_G = tf.transpose(tf.reshape(a_G,[n_H*n_W, n_C]))
#第3步,计算S与G的风格矩阵
GS = gram_matrix(a_S)
GG = gram_matrix(a_G)
#第4步:计算风格损失
#J_style_layer = (1/(4 * np.square(n_C) * np.square(n_H * n_W))) * (tf.reduce_sum(tf.square(tf.subtract(GS, GG))))
J_style_layer = 1/(4*n_C*n_C*n_H*n_H*n_W*n_W)*tf.reduce_sum(tf.square(tf.subtract(GS, GG)))
return J_style_layer由于我们有5个特征层,需要利用一个循环把五个特征成本加起来,给与五个权重
STYLE_LAYERS = [
('conv1_1', 0.2),
('conv2_1', 0.2),
('conv3_1', 0.2),
('conv4_1', 0.2),
('conv5_1', 0.2)]
def compute_style_cost(model, STYLE_LAYERS):
"""
计算几个选定层的总体风格成本
参数:
model -- 加载了的tensorflow模型
STYLE_LAYERS -- 字典,包含了:
- 我们希望从中提取风格的层的名称
- 每一层的系数(coeff)
返回:
J_style - tensor类型,实数,由公式(2)定义的成本计算方式来计算的值。
"""
# 初始化所有的成本值
J_style = 0
for layer_name, coeff in STYLE_LAYERS:
#选择当前选定层的输出
out = model[layer_name]
#运行会话,将a_S设置为我们选择的隐藏层的激活值
a_S = sess.run(out)
# 将a_G设置为来自同一图层的隐藏层激活,这里a_G引用model[layer_name],并且还没有计算,
# 在后面的代码中,我们将图像G指定为模型输入,这样当我们运行会话时,
# 这将是以图像G作为输入,从隐藏层中获取的激活值。
a_G = out
#计算当前层的风格成本
J_style_layer = compute_layer_style_cost(a_S,a_G)
# 计算总风格成本,同时考虑到系数。
J_style += coeff * J_style_layer
return J_style优化公式
![]()
def total_cost(J_content, J_style, alpha = 10, beta = 40):
"""
计算总成本
参数:
J_content -- 内容成本函数的输出
J_style -- 风格成本函数的输出
alpha -- 超参数,内容成本的权值
beta -- 超参数,风格成本的权值
"""
J = alpha * J_content + beta * J_style
return JJ的值也就是我们需要优化的,可以看到,J值与风格图像无关、与内容图像无关、与网络权值无关,只与生成图像有关。所以整个网络优化过程梯度下降都是在对这个图像求导。
实战
由于实在不懂tensorflow在搞什么,原理以及思路上面已经讲得很明白了,这边只放上代码以及效果。
最后还有一个问题,内容损失是在增加而不是减小的。这是因为我们生成的初始图片是在原图上加噪,所以一开始的成本比较低,随着不断演化,成本在上升。猜想如果随机初始图象那么成本是下降的
第 0轮训练, 总成本为:24287758000.0 内容成本为:8792.098 风格成本为:607191740.0
第 20轮训练, 总成本为:4335552500.0 内容成本为:26040.2 风格成本为:108382296.0
第 40轮训练, 总成本为:1796130700.0 内容成本为:28367.377 风格成本为:44896176.0
第 60轮训练, 总成本为:974274600.0 内容成本为:29780.506 风格成本为:24349420.0
第 80轮训练, 总成本为:656141400.0 内容成本为:30443.324 风格成本为:16395924.0
第 100轮训练, 总成本为:496794700.0 内容成本为:30877.447 风格成本为:12412148.0
第 120轮训练, 总成本为:400211620.0 内容成本为:31226.652 风格成本为:9997484.0
第 140轮训练, 总成本为:333818020.0 内容成本为:31505.57 风格成本为:8337574.5
第 160轮训练, 总成本为:285234000.0 内容成本为:31755.535 风格成本为:7122910.5
第 180轮训练, 总成本为:247696830.0 内容成本为:31973.885 风格成本为:6184427.0
执行了:0分13秒
tf.reset_default_graph()
#创建交互绘画
sess = tf.InteractiveSession()
#加载内容图像并且归一化
content_image = scipy.misc.imread("images/resize1.jpg")
content_image = nst_utils.reshape_and_normalize_image(content_image)
#加载风格图像并且归一化
style_image = scipy.misc.imread("images/resize5.jpg")
style_image = nst_utils.reshape_and_normalize_image(style_image)
#随机初始化生成的图像,通过在内容图像中添加随机噪声来产生噪声图像
generated_image = nst_utils.generate_noise_image(content_image)
imshow(generated_image[0])
#加载VGG16
model = nst_utils.load_vgg_model("pretrained-model/imagenet-vgg-verydeep-19.mat")#将内容图像作为VGG模型输入
sess.run(model['input'].assign(content_image))
out = model['conv4_2']
#a_C设置成为conv4_2的激活值
a_C = sess.run(out)
a_G = out
#计算内容成本
J_content = compute_content_cost(a_C, a_G)
#将风格图像输入
sess.run(model['input'].assign(style_image))
#计算风格成本
J_style = compute_style_cost(model, STYLE_LAYERS)
J = total_cost(J_content,J_style)
optimizer = tf.train.AdamOptimizer(2.0)
train_step = optimizer.minimize(J)def model_nn(sess, input_image, num_iterations = 200, is_print_info = True,
is_plot =True, is_save_process_image = True, save_last_image_to= "output/generated_image.jpg"):
#初始化全局变量
sess.run(tf.global_variables_initializer())
#运行带噪声的输入图像
sess.run(model["input"].assign(input_image))
for i in range(num_iterations):
#运行最小化的目标:
sess.run(train_step)
#产生把数据输入模型后生成的图像
generated_image = sess.run(model["input"])
if is_print_info and i % 20 == 0:
Jt, Jc, Js = sess.run([J, J_content, J_style])
print("第 " + str(i) + "轮训练," +
" 总成本为:"+ str(Jt) +
" 内容成本为:" + str(Jc) +
" 风格成本为:" + str(Js))
if is_save_process_image:
nst_utils.save_image("output/" + str(i) + ".png", generated_image)
nst_utils.save_image(save_last_image_to, generated_image)
return generated_image#开始时间
start_time = time.clock()
#非GPU版本,约25-30min
#generated_image = model_nn(sess, generated_image)
#使用GPU,约1-2min
with tf.device("/cpu:0"):
generated_image = model_nn(sess, generated_image)
#结束时间
end_time = time.clock()
#计算时差
minium = end_time - start_time
print("执行了:" + str(int(minium / 60)) + "分" + str(int(minium%60)) + "秒")