TTS是Text To Speech的缩写,即“从文本到语音”。 它将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语(或者其他语言语音)输出的技术,隶属于语音合成(SpeechSynthesis)。
语音,在人类的发展过程中,起到了巨大的作用。语音是语言的外部形式,是最直接地记录人的思维活动的符号体系,也是人类赖以生存发展和从事各种社会活动最基本、最重要的交流方式之一。
而让机器开口说话,则是人类千百年来的梦想。语音合成(Text To Speech),是人类不断探索、实现这一梦想的科学实践,也是受到这一梦想不断推动、不断提升的技术领域。

语音合成作为人机交互中必不可少的一个环节,随着计算机的运算和存储能力的迅猛发展,语音合成技术由早期的基于规则的参数合成,到基于小样本的拼接调整合成,并逐渐发展为现在比较流行的基于大语料库的拼接合成。

与此同时,合成语音的自然度和音质都得到了明显的改善,在一定程度上达到了人们的应用需求,从而促进了其在实际系统中的应用。
语音合成发展历史
在第二次工业革命之前,语音的合成主要以机械式的音素合成为主。1779年,德裔丹麦科学家 Christian Gottlieb Kratzenstein 建造了人类的声道模型,使其可以产生五个长元音。
1791年, Wolfgang von Kempelen 添加了唇和舌的模型,使其能够发出辅音和元音。
贝尔实验室于20世纪30年代发明了声码器(Vocoder),将语音自动分解为音调和共振,此项技术由 Homer Dudley 改进为键盘式合成器并于 1939年纽约世界博览会展出。
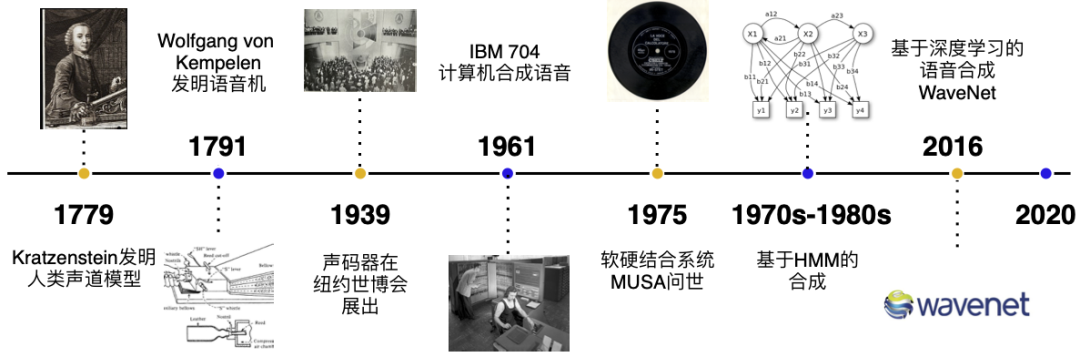
第一台基于计算机的语音合成系统起源于20世纪50年代。1961年,IBM 的 John Larry Kelly,以及 Louis Gerstman 使用 IBM 704 计算机合成语音,成为贝尔实验室最著名的成就之一。
1975年,第一代语音合成系统之一 —— MUSA(MUltichannel Speaking Automation)问世,其由一个独立的硬件和配套的软件组成。1978年发行的第二个版本也可以进行无伴奏演唱。90 年代的主流是采用 MIT 和贝尔实验室的系统,并结合自然语言处理模型。
基于深度学习的技术
当前的主流方法分为基于统计参数的语音合成、波形拼接语音合成、混合方法以及端到端神经网络语音合成。
基于参数的语音合成包含隐马尔可夫模型(Hidden Markov Model,HMM)以及深度学习网络(Deep Neural Network,DNN)。
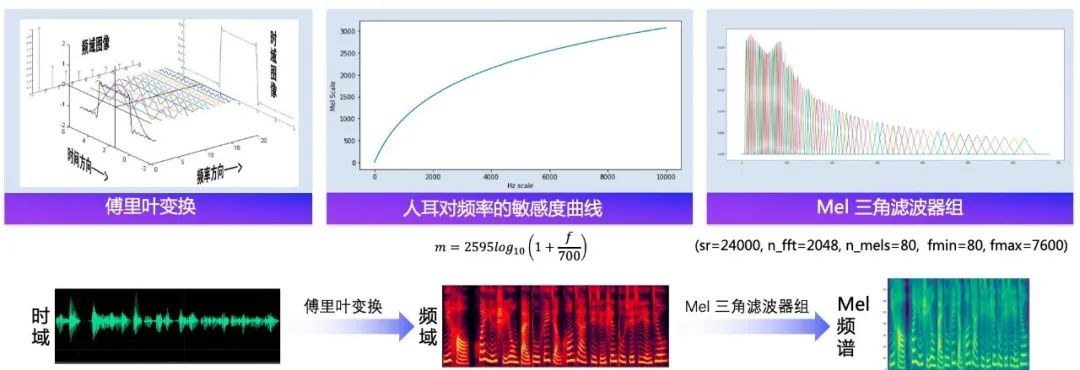
语音合成流水线包含 文本前端(Text Frontend) 、声学模型(Acoustic Model) 和 声码器(Vocoder) 三个主要模块:
通过文本前端模块将原始文本转换为字符/音素;通过声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等;通过声码器将声学特征转换为波形。
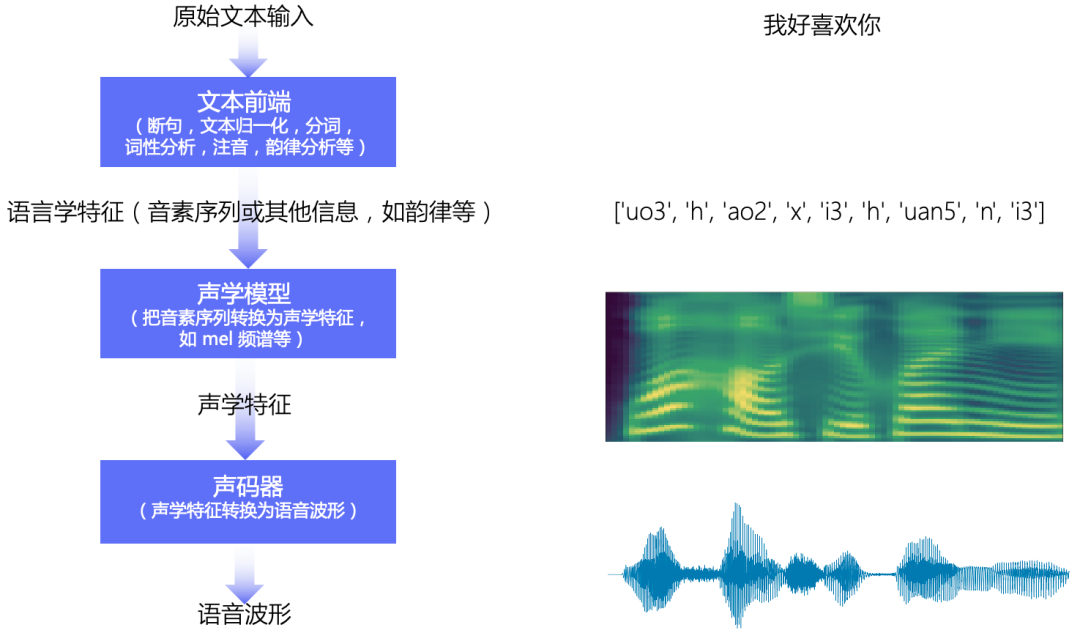
语音合成基本流程图
文本前端
文本前端模块主要包含: 分段(Text Segmentation)、文本正则化(Text Normalization, TN)、分词(Word Segmentation, 主要是在中文中)、词性标注(Part-of-Speech, PoS)、韵律预测(Prosody)和字音转换(Grapheme-to-Phoneme,G2P)等。
声学模型
声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等。 声学特征以 “帧” 为单位,一般一帧是 10ms 左右,一个音素一般对应 5~20 帧左右。
声学模型需要解决的是 “不等长序列间的映射问题”,“不等长”是指,同一个人发不同音素的持续时间不同,同一个人在不同时刻说同一句话的语速可能不同,对应各个音素的持续时间不同,不同人说话的特色不同,对应各个音素的持续时间不同。
声码器
声码器将声学特征转换为波形,它需要解决的是 “信息缺失的补全问题”。 信息缺失是指,在音频波形转换为频谱图时,存在相位信息的缺失; 在频谱图转换为 mel 频谱图时,存在频域压缩导致的信息缺失。
假设音频的采样率是 16kHz, 即 1s 的音频有 16000 个采样点,一帧的音频有 10ms,则 1s 中包含 100 帧,每一帧有 160 个采样点。 声码器的作用就是将一个频谱帧变成音频波形的 160 个采样点,所以声码器中一般会包含上采样模块。
随着车联网和智能汽车的兴起,越来越多的语音功能被搭载在车机上,仙林智能也将持续深耕智能出行场景,以前沿AI科技赋能智能车联网,为汽车用户带来更便捷、更安全、更有温度的语音交互体验。