个人名片:
博主:酒徒ᝰ.
个人简介:沉醉在酒中,借着一股酒劲,去拼搏一个未来。
本篇励志:三人行,必有我师焉。

本项目基于B站黑马程序员Java《SpringCloud微服务技术栈》,SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式
【SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式,系统详解springcloud微服务技术栈课程|黑马程序员Java微服务】 点击观看
目录
- 一、数据聚合
- 3. RestAPI实现聚合
一、数据聚合
3. RestAPI实现聚合
- API语法
es查询语句
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
代码示例:
package cn.itcast.hotel;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.search.aggregations.Aggregation;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.List;
@SpringBootTest
public class DSLSearch {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("192.168.179.128:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
@Test
void testAggregation() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().size(0);
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(20));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}
private void handleResponse(SearchResponse response) {
Aggregations aggregations = response.getAggregations();
Terms brandTerms = aggregations.get("brandAgg");
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
String brandName = bucket.getKeyAsString();
long brandCount = bucket.getDocCount();
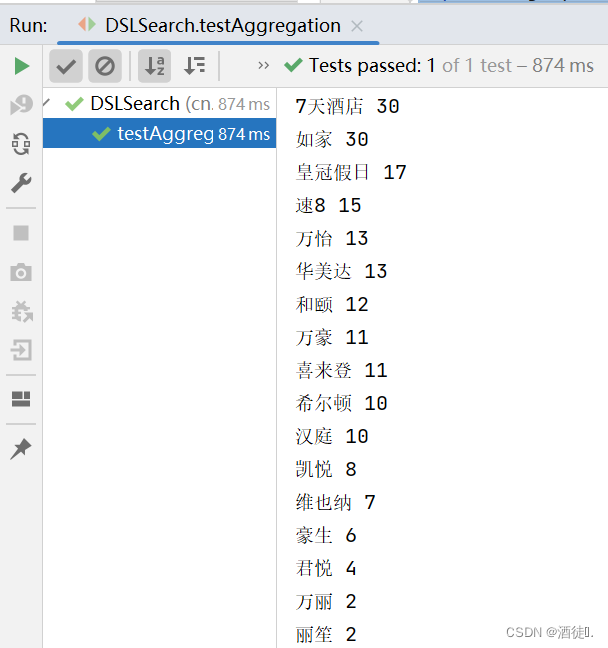
System.out.println(brandName + " " + brandCount);
}
}
}
输出结果:
- 业务需求
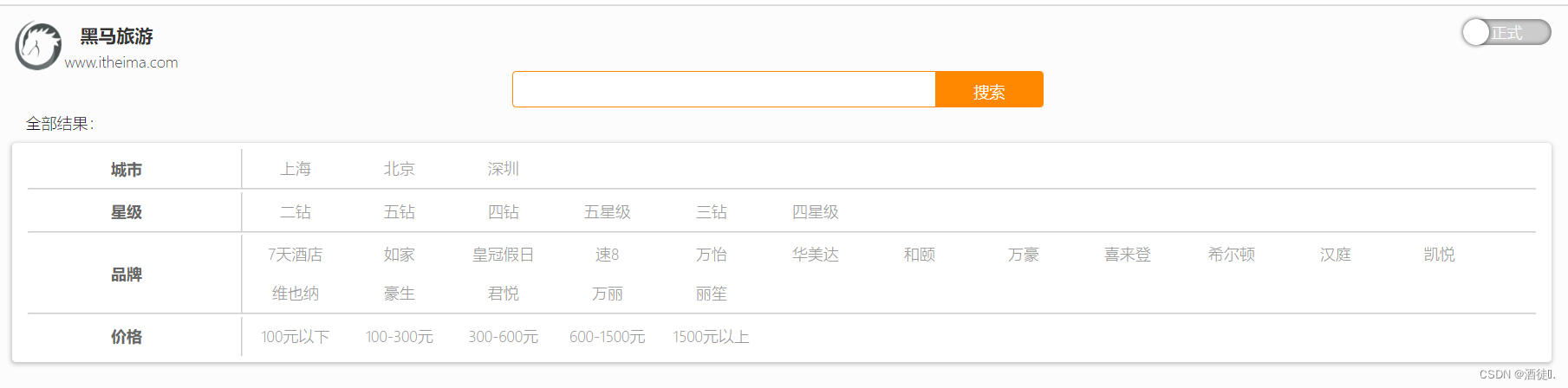
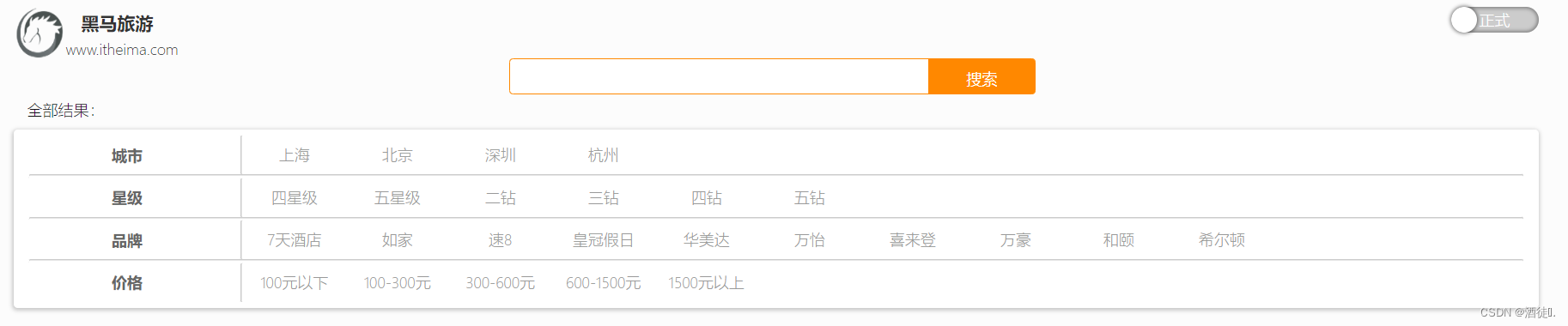
需求:搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的:
分析:
目前,页面的城市列表、星级列表、品牌列表都是写死的,并不会随着搜索结果的变化而变化。但是用户搜索条件改变时,搜索结果会跟着变化。
例如:用户搜索“东方明珠”,那搜索的酒店肯定是在上海东方明珠附近,因此,城市只能是上海,此时城市列表中就不应该显示北京、深圳、杭州这些信息了。
也就是说,搜索结果中包含哪些城市,页面就应该列出哪些城市;搜索结果中包含哪些品牌,页面就应该列出哪些品牌。
如何得知搜索结果中包含哪些品牌?如何得知搜索结果中包含哪些城市?
使用聚合功能,利用Bucket聚合,对搜索结果中的文档基于品牌分组、基于城市分组,就能得知包含哪些品牌、哪些城市了。
因为是对搜索结果聚合,因此聚合是限定范围的聚合,也就是说聚合的限定条件跟搜索文档的条件一致。
查看浏览器可以发现,前端其实已经发出了这样的一个请求:
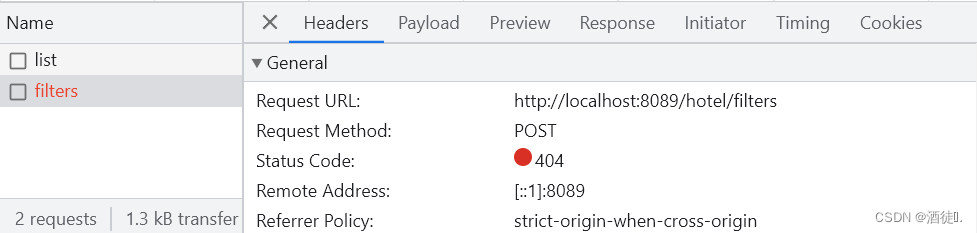
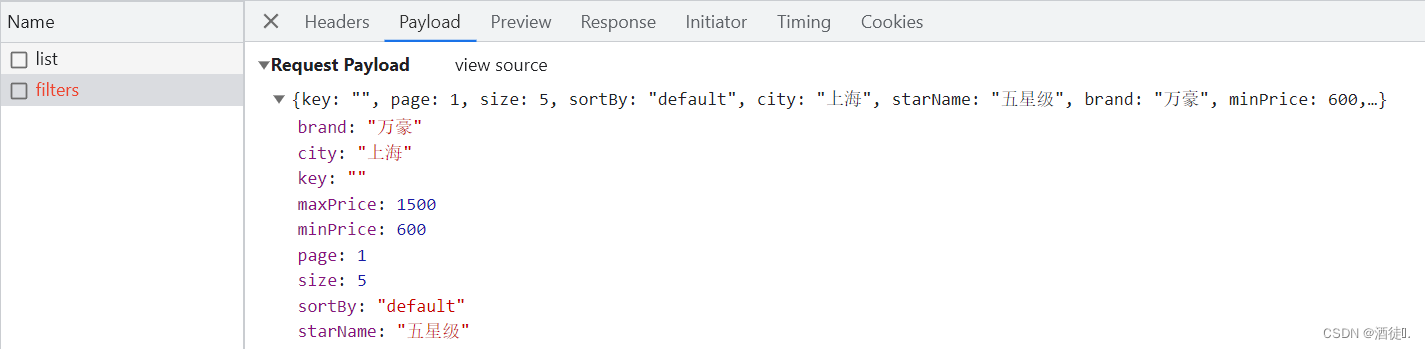
请求参数与搜索文档的参数完全一致。
分析:
filter地址,POST请求方式
参数:key, page. size, sortBy, city, starName, brand, minPrice, maxPrice,
返回值类型就是页面要展示的最终结果:
结果是一个Map结构:
key是字符串,城市、星级、品牌、价格
value是集合,例如多个城市的名称
- 业务实现
在
cn.itcast.hotel.controller包的HotelController中添加一个方法,遵循下面的要求:
请求方式:POST
请求路径:/hotel/filters
请求参数:RequestParams,与搜索文档的参数一致
返回值类型:Map<String, List<String>>
代码:
@PostMapping("/filters")
public Map<String, List<String>> getFilter(@RequestBody RequestParam params) {
return hotelService.getFilter(params);
}
这里调用了IHotelService中的getFilters方法,尚未实现。
在cn.itcast.hotel.service.IHotelService中定义新方法:
Map<String, List<String>> getFilter(RequestParam params);
在cn.itcast.hotel.service.impl.HotelService中实现该方法:
@Override
public Map<String, List<String>> getFilter(RequestParam params) {
try {
SearchRequest request = new SearchRequest("hotel");
buildBasicQuery(params, request);
request.source().size(0);
buildAggregation(request);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Map<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
List<String> brandlist = getAggByName(aggregations, "brandAgg");
result.put("brand", brandlist);
List<String> starList = getAggByName(aggregations, "starAgg");
result.put("starName", starList);
List<String> cityList = getAggByName(aggregations, "cityAgg");
result.put("city", cityList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private List<String> getAggByName(Aggregations aggregations, String aggName) {
Terms brandTerm = aggregations.get(aggName);
List<? extends Terms.Bucket> buckets = brandTerm.getBuckets();
List<String> list = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
list.add(key);
}
return list;
}
private void buildAggregation(SearchRequest request) {
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(100));
request.source().aggregation(AggregationBuilders
.terms("starAgg")
.field("starName")
.size(100));
request.source().aggregation(AggregationBuilders
.terms("cityAgg")
.field("city")
.size(100));
}
结果:
重启项目,刷新浏览器,如果城市中的杭州消失了,则业务实现成功。