进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_大数据OLAP体系技术栈,Apache Doris,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
1. 避免小批量数据写入
2. count优化
3. 避免使用select *
4. 避免构建虚拟列
5. 使用uniqCombined代替count(distinct)
6. 使用物化视图
7. Join关联相关
8. 分布式表使用global
9. 避免使用final
1. 避免小批量数据写入
尽量避免单条和小批量插入、删除操作,会产生大量小分区文件,给后台Merge带来压力。
2. count优化
在clickhouse中向查询数据总条数时,使用count() 代替count(列)查询,因为使用count()查询会自动寻找数据目录中的“count.txt”文件读取数据总条目,性能极高。如果使用count(列)相当于扫描全表读取总数据量。
node1 :) explain plan select count() from person_info;
node1 :) explain plan select count(name) from person_info;
3. 避免使用select *
数据量太大时应避免使用select * 查询,这种查询会将表中所有字段都查询出来,IO消耗大,查询字段越少消耗的IO资源就越少,性能就会越高。
4. 避免构建虚拟列
如果非必要尽量避免在查询时构建虚拟列,虚拟列非常消耗资源,造成性能浪费,可以考虑在前端进行处理或者在表中构建实际的列进行额外存储。
#避免使用虚拟列 ,以下count1/count2就是虚拟列
select id,name,count1,count2,count1/count2 as new_col from tbl;5. 使用uniqCombined代替count(distinct)
使用uniqCombined替代distinct性能可提升10倍以上,uniqCombined 底层采用类似HyperLogLog算法实现,如能接收2%左右的数据误差,可直接使用这种去重方式提升查询性能。
node1 :) select count(distinct WatchID) from datasets.hits_v1; 
node1 :) select uniqCombined(WatchID) from datasets.hits_v1; 
6. 使用物化视图
对于一些确定的数据模型,可以将统计指标通过物化视图的方式进行构建,这样可避免数据查询时重复计算的过程,同样在后期也可以构建Projection投影来替代物化视图。
7. Join关联相关
当多表关联查询时,查询的数据仅来源于一张表时,可考虑用IN代替JOIN,速度会更快。
node1 :) select count(distinct a.CounterID) as cnt from hits_v1 as a join visits_v1 as b on a.CounterID = b.CounterID
node1 :) select count(distinct CounterID) as cnt from hits_v1 where CounterID in (select CounterID from visits_v1);
此外,多表关联时,将小表放在右侧,因为右表自动会被加载到内存中与左表进行关联。
8. 分布式表使用global
对分布式表使用join 或者 in时,clickhouse会将当前SQL分发到各个clickhouse节点上执行,例如有如下SQL:
select a.id,a.name,b.score from a join b on a.id = b.id如果以上a表和b表都是分布式表,clickhouse集群有3个节点,那么上面SQL会分发到clickhouse所有节点执行,b表会在每个节点上收集其他节点对应b表数据并放在内存,这样的话,每个clickhouse节点都会从对应的3台节点上将b表数据进行汇集。
如果使用global关键字,执行如下SQL:
select a.id,a.name,b.score from a global join b on a.id = b.id这样执行SQL的话,相当于在当前写SQL节点会将查询得到b表所有数据,然后统一分发到其他clickhouse各个节点上,然后每个节点在执行与a表关联。这样使用global就减少了集群之间查询次数。假设b表有N个分片分布在N个clickhouse节点上,不使用global时,每个节点获取b表全量数据需要执行N的平方次查询,使用global时只需要执行N次查询即可。
所以在使用分布式表进行join或者in时,可以优先考虑使用global,使用用法如下:
select a.id,a.name,b.score from a global join b on a.id = b.id
select a.id,a.name from a global where a.id global in (select id from b)9. 避免使用final
clickhouse中我们可以使用ReplacintMergeTree来对数据进行去重,这个引擎可以在数据主键相同时根据指定的字段保留一条数据,ReplacingMergeTree只是在一定程度上解决了数据重复问题,由于自动分区合并机制在后台定时执行,所以并不能完全保障数据不重复。我们需要在查询时在最后执行final关键字,final执行会导致后台数据合并,查询时如果有final效率将会极低,我们应当避免使用final查询,那么不使用final我们可以通过自己写SQL方式查询出想要的数据,举例如下:
#创建replacingMergeTree 表t_replacing_mt
create table t_replacing_mt(
id UInt8,
name String,
age UInt8
) engine = ReplacingMergeTree(age)
order by id;
#向表中插入以下数据
insert into t_replacing_mt values (1,'张三',18),(2,'李四',19),(3,'王五',20); 
#继续向表中插入如下数据
insert into t_replacing_mt values (1,'张三',20),(2,'李四',15); 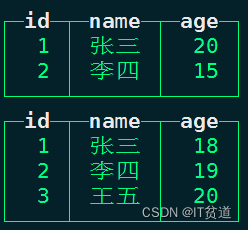
#通过final查询最终结果
node1 :) select * from t_replacing_mt final; 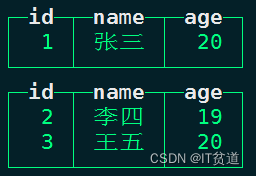
下面我们不使用final,通过自己写SQL方式现在查询最终合并数据,操作如下:
#重新删除表t_replacing_mt,重建、并加载如下数据
drop table t_replacing_mt;
create table t_replacing_mt(
id UInt8,
name String,
age UInt8
) engine = ReplacingMergeTree(age)
order by id;
insert into t_replacing_mt values (1,'张三',18),(2,'李四',19),(3,'王五',20);
#继续向表中插入如下数据
insert into t_replacing_mt values (1,'张三',20),(2,'李四',15);
#自己写SQL方式实现查询去重后的数据,这样避免使用final查询,效率提高
SELECT
id,
argMax(name, age) AS namex,
max(age) AS agex
FROM t_replacing_mt
GROUP BY id 
注意:argMax(arg,val)函数意思是找到val最大值对应的arg值,如果val有多个相同最大值,则遇到的第一条对应的arg值输出。
我们还可以针对ReplacingMergeTree表加上一个时间字段,通过自己写SQL方式实现数据更新来避免使用CollapsingMergeTree引擎进行数据更新。当有数据更新时,我们插入这条更新的数据,时间对应的是最新时间,查询时找到最大时间对应的数据即可,不必再创建CollapsingMergeTree引擎使用final语句进行更新数据,具体操作类似以上SQL操作。
👨💻如需博文中的资料请私信博主。