一、查漏补缺、熟能生巧:
1.什么是转置卷积convTranspose、以及这种转置卷积怎么使用:
(1)具体的原理直接看李沐老师的那个演示,非常清晰:
47 转置卷积【动手学深度学习v2】_哔哩哔哩_bilibili
(2)对于这个代码
def dconv_bn_relu(self, in_dim, out_dim):
return nn.Sequential(
nn.ConvTranspose2d(in_dim, out_dim, kernel_size=5, stride=2,
padding=2, output_padding=1, bias=False), #double height and width
nn.BatchNorm2d(out_dim),
nn.ReLU(True)
)来自GPT的说法:

2.关于weight_init和self.apply()

3.关于G(z_samples)部分的一个不理解的地方:

二、DCGAN , WGAN ,WGAN_GP (三种的5个epoch的效果对比):
1.DCGAN版本:一般般,直接用助教的sample_code即可,
2.对于WGAN的代码:

也就是在DCGAN中进行这种修改就好了
效果:

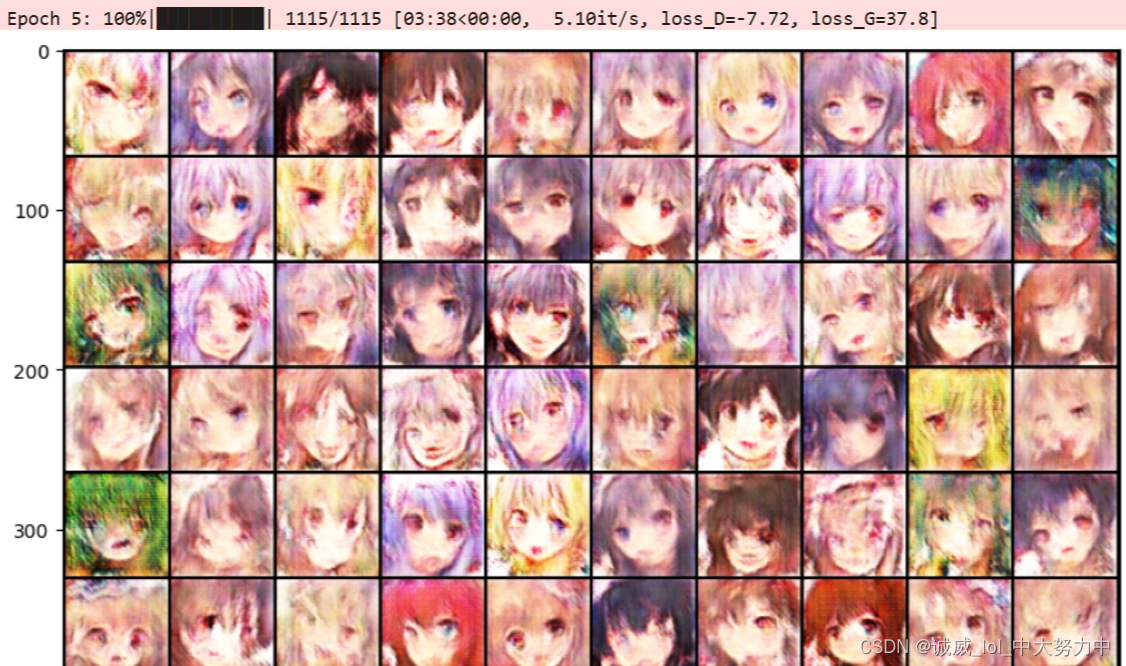
3.采用WAGN-GP:
需要做的修改:
PyTorch-GAN/implementations/wgan_gp/wgan_gp.py at master · eriklindernoren/PyTorch-GAN (github.com)
主要是写一个函数,然后把weight_clam那个for循环注释掉,其他的就按照助教给的注释来就好了
def compute_gradient_penalty(self,D, real_samples, fake_samples):
Tensor = torch.cuda.FloatTensor #if cuda else torch.FloatTensor
"""
#这里需要参考那个link引入gradient penalty function
Implement gradient penalty function
"""
"""Calculates the gradient penalty loss for WGAN GP"""
# Random weight term for interpolation between real and fake samples
alpha = Tensor(np.random.random((real_samples.size(0), 1, 1, 1)))
# Get random interpolation between real and fake samples
interpolates = (alpha * real_samples + ((1 - alpha) * fake_samples)).requires_grad_(True)
d_interpolates = D(interpolates)
fake = Variable(Tensor(d_interpolates.shape).fill_(1.0), requires_grad=False)
# Get gradient w.r.t. interpolates
gradients = autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs=fake,
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean()
return gradient_penalty效果:
 ;
;
中午睡觉的时候,用这个kaggle来train一下这个WGAN-GP,
直接设置critic =5 , epoch =1000 试一试