一、目的
由于数仓的ADS层是在ClickHouse中,即把Hive中DWS层的结果数据同步到ClickHouse中,因此需要在ClickHouse中建表,于是需要海豚调度执行ClickHouse的.sql文件
二、实施步骤
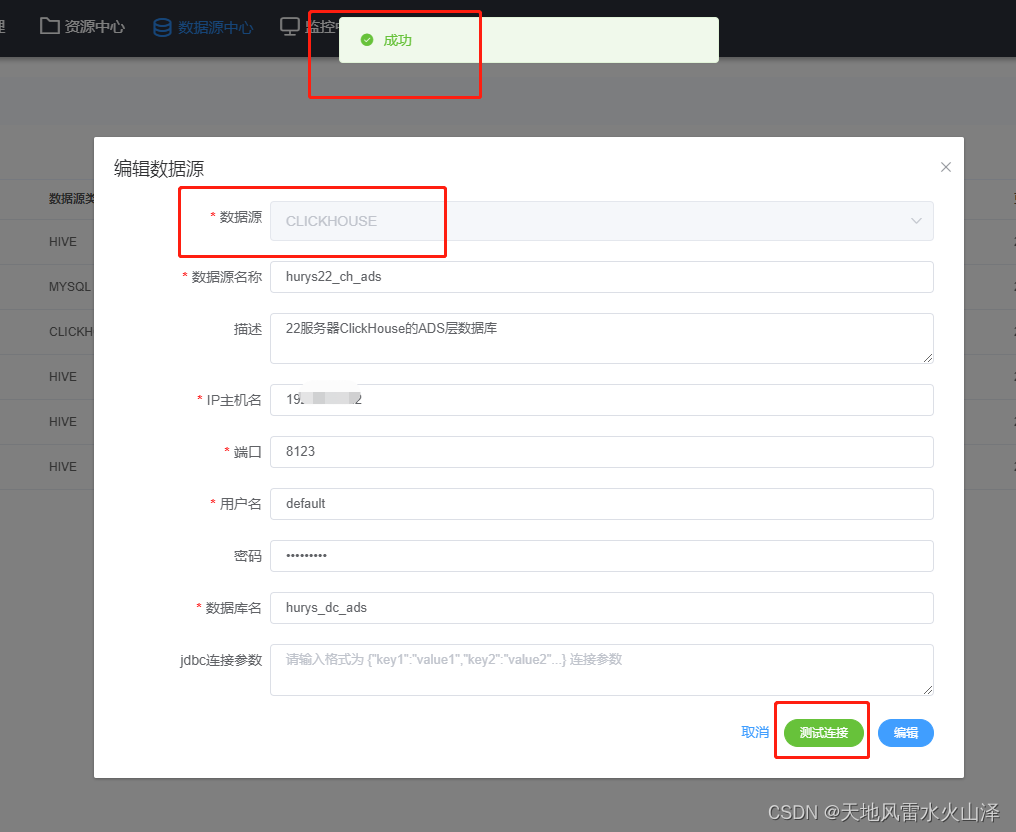
(一)第一步,海豚建立ClickHouse数据库连接
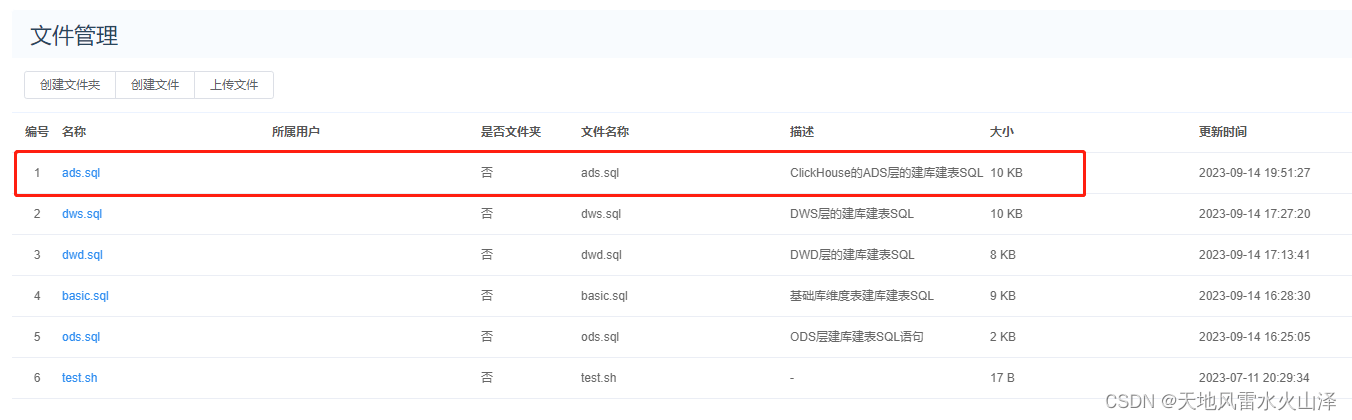
(二)第二步,上传.sql文件到海豚调度器上
(三)第三步,建立并配置工作流
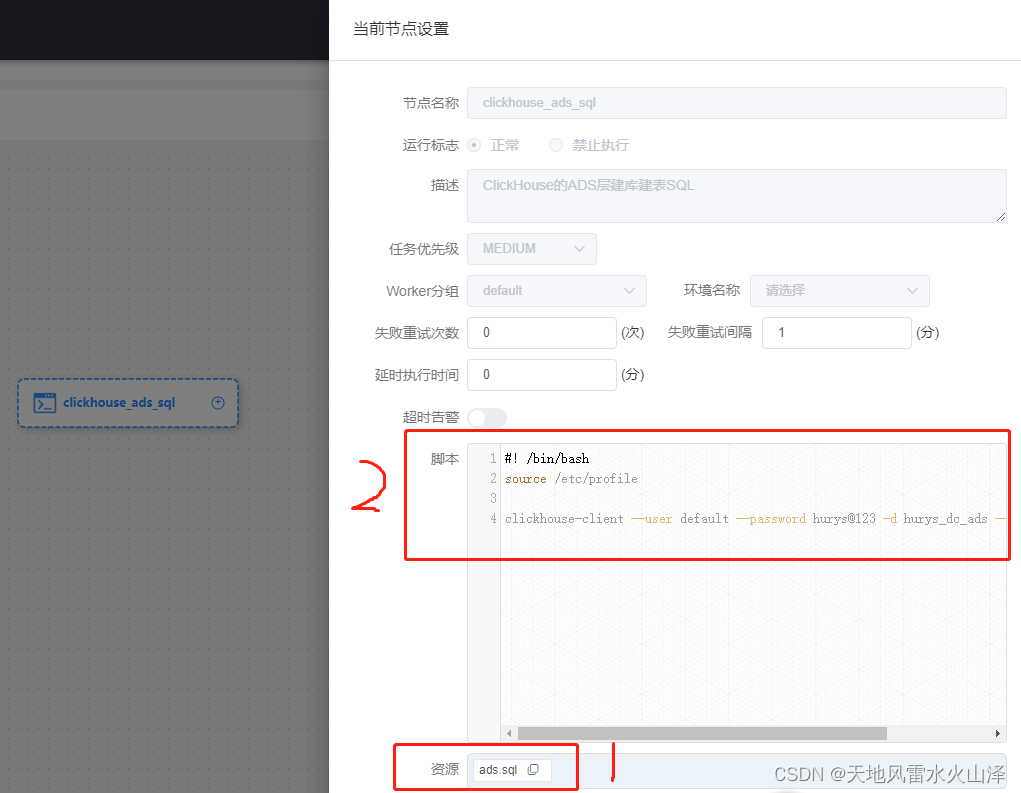
1、首先,获取.sql文件资源
2、配置脚本,执行.sql文件
#! /bin/bash
source /etc/profile
clickhouse-client --user default --password hurys@123 -d hurys_dc_ads --multiquery <ads.sql
分别是clickhouse的用户名、密码、数据库、.sql文件
(四)第四步,执行工作流

三、在ClickHouse执行.sql文件的方法
clickhouse-client --user 用户名 --password 密码 -d 数据库名 --multiquery <ads.sql
今天学会了在Hive和ClickHouse中执行.sql文件的方法,总结一下它们的使用
乐于奉献共享,帮助你我他!