文章目录
- 1. 前言
- 2. 背景
- 3. Cache 硬件基础
- 3.1 什么是 Cache ?
- 3.2 Cache 工作原理
- 3.3 Cache 层级架构
- 3.4 内存架构中各级访问速度概览
- 3.5 Cache 分类
- 3.6 Cache 的 查找 和 组织方式
- 3.6.1 Cache 组织相关术语
- 3.6.2 Cache 查找
- 3.6.2.1 Cache 查找过程概述
- 3.6.2.2 Cache 查找硬件实现
- 3.6.3 Cache 的各种组织形式
- 3.6.3.1 直接映射(Direct Mapped)
- 3.6.3.2 多路组相联(N-Way Set-Associative)
- 3.6.3.3 全相联(Fully Associative)
- 3.6.4 Cache 查找相关问题和解决方案
- 3.6.4.1 Cache 歧义
- 3.6.4.2 Cache 别名
- 3.6.4.3 Cache 歧义 和 别名 的解决方案
- 3.7 Cache 策略
- 3.7.1 Cache 分配策略
- 3.7.1.1 读分配策略(read allocate)
- 3.7.1.2 写分配策略(write allocate)
- 3.7.2 Cache 替换策略
- 3.7.2.1 Round-robin
- 3.7.2.2 Pseudo-random
- 3.7.2.3 Last Recently Used(LRU)
- 3.7.2.4 替换策略总结
- 3.7.3 Cache 写策略
- 3.7.3.1 透写(Write-through)
- 3.7.3.2 回写(Write-back)
- 3.8 Cache 和 主存之间写缓冲: Write buffer
- 3.9 Cache 维护操作
- 3.9.1 Cache invalidate
- 3.9.2 Cache clean
- 3.9.3 Cache flush
- 3.9.4 Cache lockdown
- 3.9.5 Cache 操作的目标或范围
- 3.10 Cache 性能 和 命中率
- 3.11 内存的 Cache 属性
- 3.12 Cache 一致性
- 3.13 Cache 和 存储模型
- 3.14 地址翻译 Cache: TLB
- 3.14.1 什么是 TLB ?
- 3.14.2 TLB 维护操作
- 3.14.3 TLB 刷新
- 4. Linux 下的 Cache
- 4.1 Cache 初始化
- 4.2 Cache 代码文件组织
- 4.3 Cache 操作接口 和 范例
- 5. Cache 调试方法
- 5.1 使用 Cache 调试工具
- 5.2 查询 Cache 信息
- 6. Cache 性能优化案例
- 6.1 热点代码 iCache & dCache Miss
- 6.2 Cache 伪共享(False Sharing)优化
- 7. 参考资料
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 背景
本文所有分析基于 ARMv7 架构 和 Linux 4.14 内核。
3. Cache 硬件基础
3.1 什么是 Cache ?
Cache 是一块高速内存,由于 CPU 和 主存(通常是DDR等) 速度之间存在数量级的差异,于是在 CPU 和 主存 之间,加入速度更快、造价更高、容量更小 的内存,也即 Cache,以缓解 CPU 和 主存 之间速度差异造成的性能损失:CPU 可以先将数据从主存加载到高速内存(即Cache),然后 CPU 大多数时候和高速Cache交互,在必要的时候从主存加载数据到Cache,或者将Cache中的数据刷入到主存。
3.2 Cache 工作原理
Cache 之所以能提高程序的速度,首先自然是因为它相对于主存更高的读写速度。但同时由于 Cache 的容量有限,不可能缓存所有程序和数据,此时 Cache 利用了程序执行的 空间局部性(Spatial locality) 和 时间局部性(Temporal locality) 原理,来提高程序的性能。
空间局部性(Spatial locality) 是指紧邻当前位置访问的指令和数据,接下来本访问的可能性很大。
时间局部性(Temporal locality) 是指最近访问的指令和数据,在接下来短时间内被访问的可能性很大。
3.3 Cache 层级架构
下图是一个典型的 ARMv7 架构下,Cache 在内存层级架构中的位置,其它硬件架构下的类似,读者可查找相关资料。
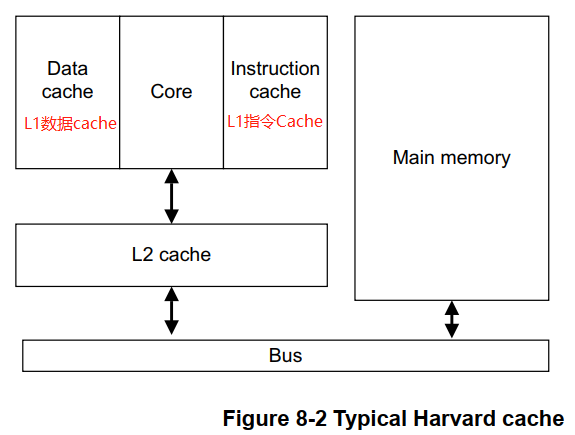
上面是典型的 哈佛总线 架构下 Cache 层级组织。上图中 第1级 Cache(L1 cache) 的 数据cache(Data cache) 和 指令cache(Instruction cache) 是独立的,第2级cache(L2 cache),指令和数据使用同一cache空间,L2 cache 通过 总线(Bus) 和 主存空间(Main memory)进行交互。
上图只给出了一个 CPU 核情况下的 cache 组织,对于多核情形下,ARMv8 架构下典型的 cache 组织如下图:
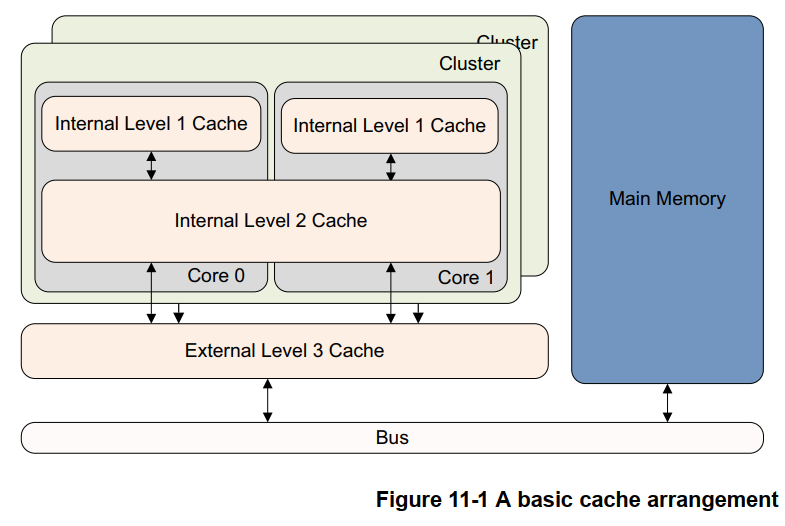
上图中:
. 每个 CPU Core ,有自身独立的 L1 Cache( ARM架构下,L1的指令和数据cache是独立的,途中未有体现);
. 每个 Cluster 有自己独立的 L2 Cache,同一 Cluster 内的所有 CPU Core,共享一个 L2 Cache,;
. 所有 Cluster 内的 CPU Core,共享同一个 L3 Cache。
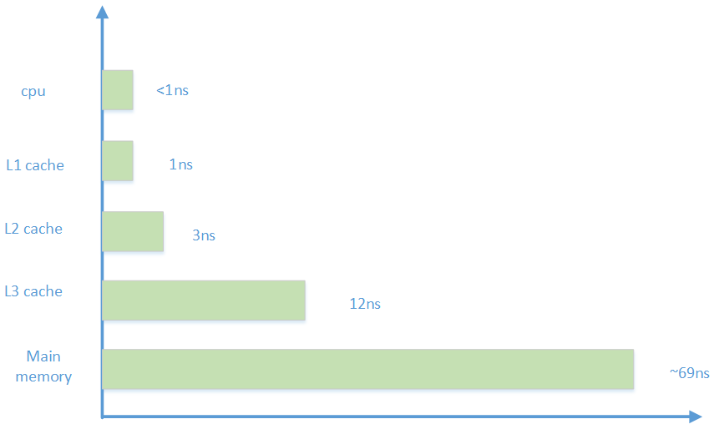
3.4 内存架构中各级访问速度概览
从 3.3 小节中,我们了解到了包括 Cache 在内的典型存储架构。下面通过一张图,让我们对存储架构中各级存储的访问速度有个大概了解:
3.5 Cache 分类
按照 处理器 取指操作 和 数据读写操作,是否使用独立的 指令 Cache 和 数据 Cache ,可以将 Cache 分为 统一型 Cache(Unified Cache) 和 分离型 Cache(Separate cache) 。统一型 Cache(Unified Cache) 指令 和 数据 使用相同的 Cache; 分离型 Cache(Separate cache) 指令 和 数据 使用各自独立的 Cache 。统一型 Cache(Unified Cache) 是 冯.诺伊曼架构(Neumann architecture) 使用的模型; 分离型 Cache(Separate cache) 是 哈佛架构(Harvard architecture) 使用的模型。
ARM 架构下 Cache,使用 哈佛架构(Harvard architecture) 的 分离型 Cache(Separate cache) 。
3.6 Cache 的 查找 和 组织方式
下图给出了 ARMv7 架构下的 Cache 组织形式:
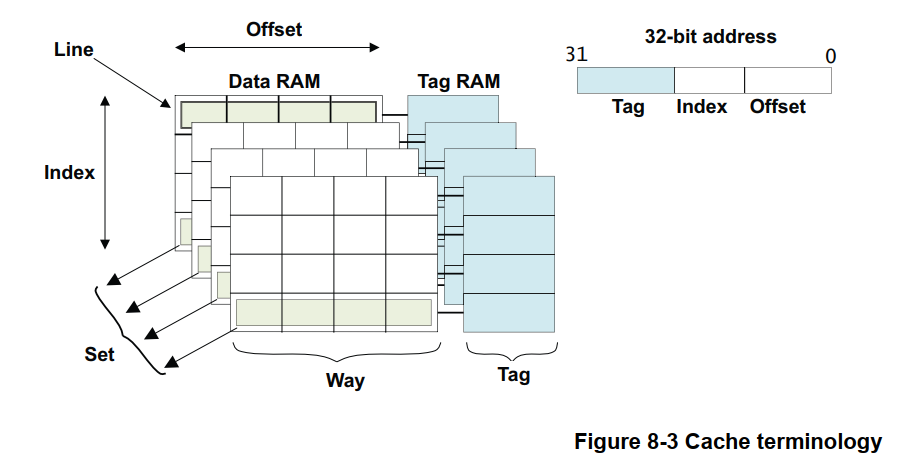
上图中涉及多个 Cache 相关的术语,将在 3.5.1 小节中一一加以说明。
3.6.1 Cache 组织相关术语
先介绍下 Cache 相关术语 Way 和 Line :
Way: 中文通常翻译为 路,将 Cache 按容量平均分成 N 份,每一份称为一路(Way),N 份就是 N 路(Way)。
如一个 32KB 的 Cache ,分为4份,每份 32KB / 4 = 8KB ,每 8KB 为一路,总共有 4 路。
Line: Cache 行(Line),Cache的每一路(Way),包含多个 Cache 行(Line),每个 Cache 行(Line)包含 多个Word
或 多个字节,所有的 Cache 行(Line)的长度都是一样的,常见的有 32 或 64 字节等。
如一个 32KB Cache 分为 4 路,则每路为 8KB,如果 Cache 行的长度为 64 字节,则每 8KB 大小的一路 Cache,
将包含 8KB / 64 = 128 个 Cache 行。
由于所有 Cache 路 具有相同的容量,那自然所有的 Cache 路 都包含相同的 Cache 行 数目。
Cache 行也是 和 主存 进行交互的最小单位,即 每次从 主存 加载 到 Cache ,或者 将 Cache 数据刷回到 主存,
都是以 Cache 行 为单位进行的。
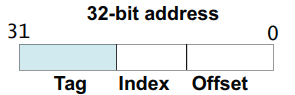
需要有一种方法,建立 主存地址块 和 Cache 行 之间的映射关系,硬件通过 主存地址块首地址,来建立 主存地址块 和 Cache 行 之间的映射,如下图(ARM32 架构示例):
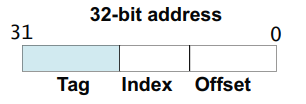
上图将 主存地址块首地址,划分为 Tag,Index,Offset 三部分。其中:
Tag: 用来 匹配 或者说 标记 一个 Cache 行。
每个 Cache 行有额外的空间(图中 Tag RAM),用来存储映射的主存内存块的首地址的 Tag ,这个额外 Tag 空间,
不包含在 Cache 行的存储空间(图中 Data RAM)之内。
Index: 每路 Cache 包含多个 Cache 行,这些 Cache 行通过 主存地址的 Index 部分进行索引。
Offset: 每个 Cache 行包含 多个Word 或 多个字节。这些 Cache 行中的 Word 或 字节,通过 Offset 进行定位。
到此已经基本介绍完了 3.5 开头部分图片包含的、Cache 组织相关的术语,只剩下一个 Set 的术语了,来看一下:
Set: 所有 Cache 路中,(对应主存地址的) Index 相同的所有 Cache 行,称为 一组(Set)。组(Set)的数目对应每路中 Cache 行的数目。
如一个 32KB 的 Cache,分为 4 路,Cache 行大小为 64 字节,则每路 Cache 有 128 个 Cache 行,也即有 128 组(Set)。
3.6.2 Cache 查找
3.6.2.1 Cache 查找过程概述
Cache 查找,是指根据数据的虚拟地址(VA:Virtual Address)和物理地址(PA:Physical Address),定位到 数据对应 Cache 行(Line)内的Word或字节偏移位置的过程。如果查找成功,则表示 Cache 命中(Cache Hit),否则为 Cache 未命中(Cache Miss) 。
Cache 查找过程将数据地址分为如下图的3部分进行:
首先通过数据地址的 Index 部分,定位到 Cache 组(Set),如 3.6 节开始部分图中所示 Set;然后比较 Cache 组(Set) 中的每个 Cache 行(Line) 的 Tag 和 数据地址的 Tag 部分,如果 Tag 相等,则表示 Cache 命中(Cache Hit),否则 Cache 未命中(Cache Miss) 。在 Cache 命中后,已经定位到了 Cache 行,数据地址的 Offset 部分,最后用来定位数据在 Cache 行中的偏移位置。
下图是一个 32KB,4 路(Way) 组相联 Cache 查找实现示例:
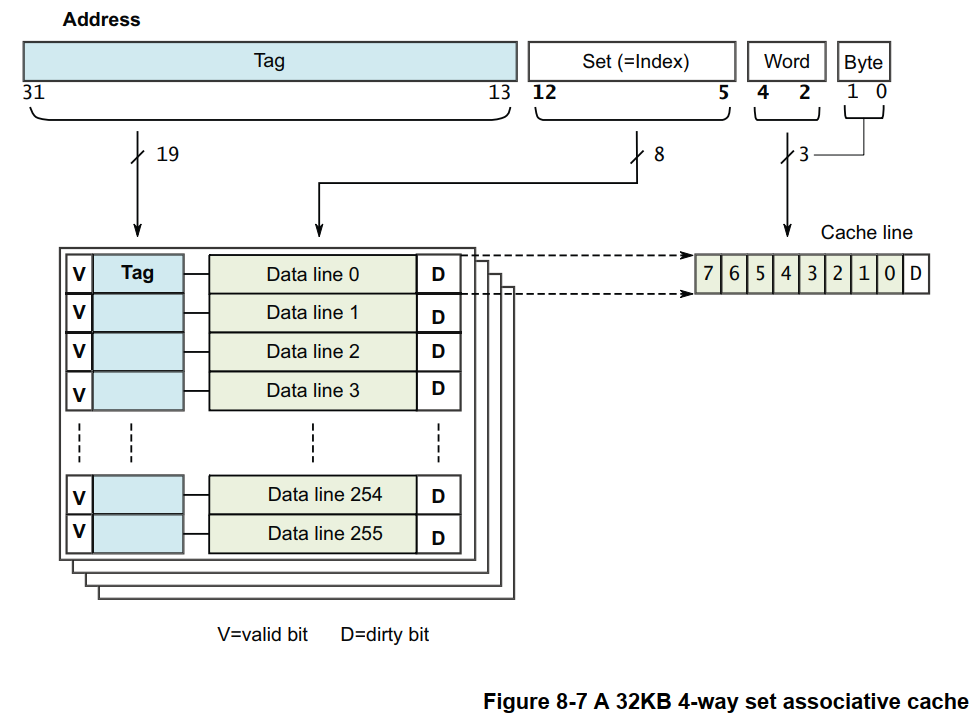
3.6.2.2 Cache 查找硬件实现
在 3.6.2.1 小节对 Cache 查找过程的描述中,没有具体交代 数据地址 是指的 虚拟地址(VA) 还是 物理地址(PA)。查找使用的 Tag,Index,Offset 可能来自于被 Cache 缓存数据的 虚拟地址(VA) 或 物理地址(PA),常见的硬件实现有 VIVT,VIPT,PIPT:
o `VIVT(Virtually Indexed Virtually Tagged)`
`Tag` 来自于数据的虚拟地址(VA),`Index` 来自于数据的虚拟地址(VA),`Offset` 来自于数据的虚拟地址。
o `VIPT(Virtually Indexed PhysicallyTagged)`
`Tag` 来自于数据的物理地址(PA),`Index` 来自于数据的虚拟地址(VA),`Offset` 来自于数据的虚拟地址(VA)。
o `PIPT(Physically Indexed PhysicallyTagged)`
`Tag` 来自于数据的物理地址(PA),`Index` 来自于数据的虚拟地址(PA),`Offset` 来自于数据的虚拟地址(PA)。
3.6.3 Cache 的各种组织形式
本小节描述 Cache 的各种组织形式,以及它们各自的优缺点。
3.6.3.1 直接映射(Direct Mapped)
直接映射 Cache(Direct Mapped Cache),是指主存的每个位置,唯一映射到一个 Cache 行。由于 Cache 的容量远小于主存的容量,所以会存在多个主存位置映射到同一 Cache 行的情形。 映射示例如下图:
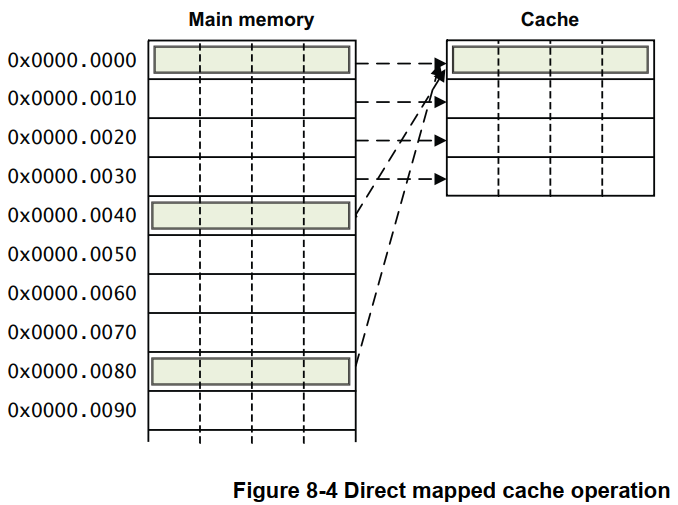
上图中,Cache 只有1路(Way),同时没有分组(Set),或者也可以认为是只有1路1组的情形;Cache 行大小为 16 字节,Cache 总大小为 16x4 = 64 字节,总共 64/16 = 4 个 Cache 行。Cache 行的分配如下:
o 主存地址块 0x00000000, 0x00000040, 0x00000080, ... 映射到 Cache 的第 1 行
o 主存地址块 0x00000010, 0x00000050, 0x00000090, ... 映射到 Cache 的第 2 行
o 主存地址块 0x00000020, 0x00000060, 0x000000A0, ... 映射到 Cache 的第 3 行
o 主存地址块 0x00000030, 0x00000070, 0x000000B0, ... 映射到 Cache 的第 4 行
假设使用 VIVT 查找实现,则 数据虚拟地址(VA) 的 划分如下:
VA
31 6 5 4 3 0
--------------------------------------------------
| Tag | Index | Offset |
--------------------------------------------------
VA[31:8]: Tag
VA[5:4] : Index
VA[3:0] : Offset
直接映射 Cache(Direct Mapped Cache) 的优点点在于硬件实现简单、成本低;缺点在于容易造成 Cache 颠簸(thrashing):前一数据刚被加载到某一 Cache 行,紧接着使用的数据又要使用相同的 Cache 行,这就使得前一数据刚加载到 Cache 行、立马又被换出这个 Cache 行,这样就无法利用 Cache 带来的速度优势。下面用一个例子代码来说明造成 Cache 颠簸的情形:
void add_array(int *data1, int *data2, int *result, int size)
{
int i;
for (i = 0; i < size; i++)
result[i] = data1[i] + data2[i];
}
假设示例代码中的 result,data1,data2 分别位于地址 0x00, 0x040, 0x80 ,并以前面图 Figure 8-4所示进行映射,那计算语句 result[i] = data1[i] + data2[i]; 会造成 3 次 cache 加载,因为 result[i],data1[i],data2[i] 映射到了同一 Cache 行,这种情形就是 Cache 颠簸。
在现代计算机上,没再见过使用 直接映射 Cache(Direct Mapped Cache) 。
3.6.3.2 多路组相联(N-Way Set-Associative)
多路组相联 Cache(N-Way Set-Associative Cache),是指 将 Cache 按容量平均分成 N 份,称为 N 路(N-Way);同时每路(Way) Cache 中,Index 相同的 Cache 行(Line) 形成一组(Set),组(Set)的数目为一路(Way) Cache 包含的 Cache 行(Line)数。来看一个例子,有一 Cache,其容量为 128 字节,分为两路,每路容量则为 128/2 = 64 字节,Cache 行的大小为 16 字节,所以每路 Cache 包含 64/16 = 4 个 Cache 行,也即 Cache 组数为 4 组。这是一个 两路组相联的 Cache 。看一下图示:
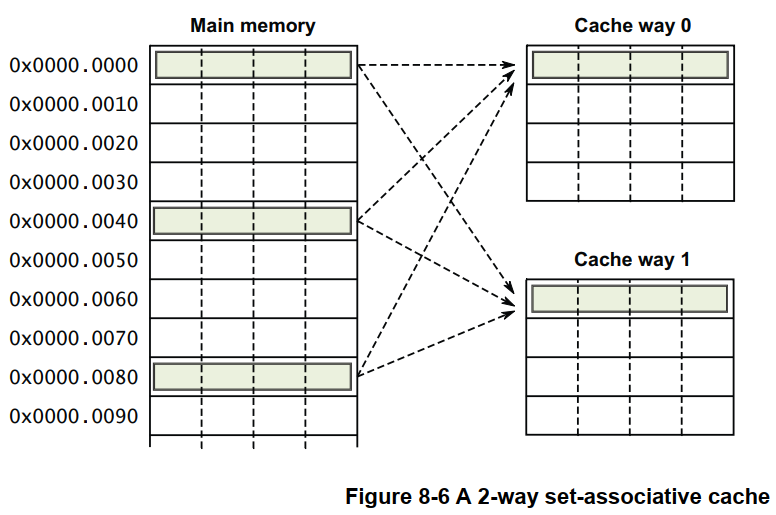
多路组相联 Cache(N-Way Set-Associative Cache),是现代 Cache 实现的主流方式。
3.6.3.3 全相联(Fully Associative)
全相联 Cache(Fully Associative Cache),可以认为是 多路组相联(N-Way Set-Associative) 的一种特殊情形:任意的主存数据在 Cache 所有行都可进行映射。这和 直接映射 Cache(Direct Mapped Cache) 的情形刚好相反,是 Cache 映射的另一种极端情况。
在实际应用当中,大于4路的组相联 L1 Cache,对性能提升很小;8路 或 16路 的组相联,对于容量更大的 L2 Cache 会更有用。
3.6.4 Cache 查找相关问题和解决方案
在不同的 Cache 查找策略下,在某些情形会引入 Cache 歧义 和 Cache 别名 问题,下面将一一加以说明。在正式开始之前,首先要明晰的是:所有的讨论都是基于对同一 Cache 的访问。 如对于多个不同 VA 映射到同一 PA 的情形,不同 VA 加载 PA 的数据到不同 CPU core 的 L1 Cache ,这就不是 Cache 别名问题;只有同一 PA 数据加载到同一 Cache 的不同 Cache 行,这才是 Cache 别名。
3.6.4.1 Cache 歧义
一个 虚拟地址(VA),可能映射到两个不同的 物理地址(PA1,PA2),典型的如进程切换,如果当前被调度出去的 进程1 将 VA 映射到 PA1 ,同时 Cache 缓存了 PA1 的数据在 Cache 行1;然后进行进程切换(假定不进行 Cache Clean/Invalidate 操作),切换到目标 进程2,目标 进程2 的 页表(进程切换会伴随页表切换)将 VA 映射到 PA2,接下来 进程2 访问 VA 映射的 PA2 数据,如果使用 VIVT(Virtually Indexed Virtually Tagged) Cache 查找方式,由于 进程1 访问 VA 时 将 PA1 数据加载到了 Cache 行1,所以 进程2 用同一 VA 访问 PA2 会命中 PA1 的数据,但是事实上,进程2 应该去访问 PA2 的数据,这种情形,就是 Cache 歧义。
只有 VIVT 会引入 Cache 歧义,而 VIPT 和 PIPT 都不会引入 Cache 歧义,感兴趣的读者可以自行推导一下。
3.6.4.2 Cache 别名
多个不同的虚拟地址 (VA1,VA2,…) ,如果映射到同一个 物理地址 PA (如不同进程间的共享内存),可能导致 同一 PA 地址的数据,被加载到多个不同 Cache 行的情形,就是所谓的 Cache 别名。Cache 别名 会导致 Cache 浪费,以及潜在的数据不一致性。
各种 Cache 查找方式,除了 PIPT 外,VIVT 和 VIPT 在不同的情形下,都可能引发 Cache 别名问题。本小节接下来的讨论,都假定两个不同的虚拟地址 VA1,VA2,映射到了同一物理地址 PA 。
第一类 Cache 别名问题是由 VIVT 下 Cache Index 的不唯一性 引发的 。假设有一个 8KB 的 直接映射(Direct Mapped) 的 Cache,那么 Cache 查找的 Index + Offset 两部分需要 13-bit;同时假定内存系统采用 4KB 大小的页面,那么页面内偏移需要 12-bit 。当 VA1,VA2 映射到同一 PA 时,则一定有 VA1[11:0]==VA2[11:0] (即 页面内偏移位置相同) ,但 VA1[12]==VA2[12] 则不一定成立;如果 VA1[12] != VA2[12],则意味着 VA1 和 VA2 的 Index 值不同 (VA[12]是Index的一位),所以 VA1 和 VA2 会占据两个不同的 Cache 行。
第二类 Cache 别名问题是由 VIVT 下 Cache Tag 的不唯一性 引发的。假设有一个 8KB 两路组相联 的 Cache ,Cache 查找的 Index + Offset 两部分需要 12-bit。当 VA1,VA2 映射到同一 PA 时,则一定有 VA1[11:0]==VA2[11:0] (即 页面内偏移位置相同) ,也即 VA1,VA2 Cache 查找的 Index 是相等的,这意味着 VA1,VA2 的 Cache 行位于同一组(Set),但同时由于 VA1 != VA2,所以 VA1 和 VA2 的 Cache Tag 值不相等,这样 VA1,VA2 映射的 PA 数据,会被加载同一 Cache 组中的不同路(Way) 的 Cache 行中,也就导致了 Cache 别名。
第三类 Cache 别名问题是由 VIPT 下 Cache Index 的不唯一性 引发的。假设有一个 32KB 4路组相联 的 Cache,那么 Cache 查找的 Index + Offset 两部分需要 13-bit;同时假定内存系统采用 4KB 大小的页面,那么页面内偏移需要 12-bit 。当 VA1,VA2 映射到同一 PA 时,则一定有 VA1[11:0]==VA2[11:0] (即 页面内偏移位置相同) ,但 VA1[12]==VA2[12] 则不一定成立;如果 VA1[12] != VA2[12],则意味着 VA1 和 VA2 的 Index 值不同 (VA[12]是Index的一位),这样 VA1,VA2 映射的 PA 数据,会被加载到 Cache 的不同 Cache 行中,也就是 Cache 别名。
3.6.4.3 Cache 歧义 和 别名 的解决方案
Cache 歧义 问题,可以通过 Cache Clean/Invalidate 操作避免。Cache Clean/Invalidate 操作的含义在后续章节 3.10 中进行解释。只有 VIVT 下才会发生 Cache 歧义,Cache Clean/Invalidate 的解决方式很低效,但好在现在没有实现再用 VIVT 。
Cache 别名 问题,我们只关注 VIPT 查找方式(VIVT 弃用,PIPT 不存在该问题)。同时,本小节的后续讨论,都是基于多个不同 VA 映射到 同一个 PA 的前提下进行的,这也是产生 Cache 别名问题的必要条件。从 3.6.4.2 了解到,VIPT 下的别名问题,是由于 Cache Index 的不唯一性 引起的,我们可以通过 将 Index + Offset 占用虚拟地址的位数,限定为 小于等于 虚拟地址页面偏移所占用的位数 来避免。为什么?Cache 别名的根因,是多个不同 VA 映射到了同一 PA ,导致 Cache Index 可能的不同 引发的。如果我们消除那些 Cache Index 不同的情形,自然也就消除了 VIPT 的 Cache 别名问题。那么哪些情形可能会导致不同 VA 的 Cache Index 不同?对比一下 虚拟地址 VA 的 Cache 映射 和 页面映射:
31 S+1 S 0
--------------------------------------------------
| Tag | Index + Offset | VA 的 Cache 映射
--------------------------------------------------
31 P+1 P 0
--------------------------------------------------
| 页表索引 | Page Offset | VA 的 页面映射
--------------------------------------------------
看出点什么没有?如果上图中 S <= P ,在多个 VA 映射到同一 PA 的前提下,则必定会有 VA[S:0]==VA[P:0] 成立,这意味着这些不同 VA 的 Cache Index 值相同;如果 S > P ,即划分为 Cache Index + Offset 的比特数,比用来作为页面内偏移 Page Offset 的比特数要多,就有可能出现同一 PA 的不同 VA 的 Cache Index 不同的情形。因为不同 VA 映射到同一 PA ,只能保证 Cache 映射中 和 页面映射 的 Page Offset 对应部分的值是相同的。所以,消除 VIPT 的 Cache 别名,只需要保证上图中的 S <= P 成立即可。也可以换成另一个说法,要消除 VIPT 的 Cache 别名,只需要保证 Cache 路的容量 <= 内存映射页面容量 即可,因为在 Cache 映射中的 Index + Offset 部分,就是描述的一路 Cache 的寻址范围(Cache 路的容量 = 2 ^ S+1);而 内存页面映射中的 Page Offset 部分就是寻址的一个页面(内存映射页面容量 = 2 ^ P+1)。Cache 别名,本质是因为 Cache 的映射方式 和 内存页面映射方式 的不一致造成的。
3.7 Cache 策略
3.7.1 Cache 分配策略
Cache 分配策略,是指在什么情形下分配 Cache 行。有 读分配 和 写分配 两种分配策略,下面一一加以说明。
3.7.1.1 读分配策略(read allocate)
当且仅当读操作引发 Cache Miss 时,才会分配 Cache 行。写操作 Cache Miss ,只会将 Cache 行数据写入到内存架构的下一级存储(L2 Cache 或 主存)。
3.7.1.2 写分配策略(write allocate)
更准确来说,写分配策略(write allocate) 应该叫 读写分配策略(read-write allocate)。读和写引发的 Cache Miss,都会分配 Cache 行。
写分配策略(write allocate) 通常搭配 Cache 写策略 write-back 一起使用。
3.7.2 Cache 替换策略
Cache Index 选择 Cache 组(Set);而 Cache 替换策略,用来决定选择 Cache 组中的哪一个 Cache 行(Line)。如果被替换的 Cache 当前包含合法的(Valid)、脏(Dirty)数据,则在替换 Cache 行之前,必须先将 Cache 行的数据写回到主存。
Cache 替换策略 有 Round-robin,Pseudo-random,Last Recently Used(LRU) 三种,下面一一加以说明。
3.7.2.1 Round-robin
轮流替换每路中的 Cache 行。在 Index 选定某个 Cache 组后,依次替换组中各路的 Cache 行。如第1次替换某组第1路的 Cache 行,第2次替换某组第1路的 Cache 行,… 依次类推,替换到某组的最后一路的 Cache 行后,将回卷到该组的第一路。
3.7.2.2 Pseudo-random
在 Index 选定某个 Cache 组后,随机选择一路 Cache 的 Cache 行替换。
3.7.2.3 Last Recently Used(LRU)
在 Index 选定某个 Cache 组后,替换组中最近最少使用的 Cache 行替换。
3.7.2.4 替换策略总结
大多数 ARM 处理同时支持 Round-robin 和 Pseudo-random 两种替换策略,Cortex-A15 支持 LRU 替换策略。
Round-robin 在某些情形下,会导致很差的性能,通常来讲,Pseudo-random 会是更好的选择。
3.7.3 Cache 写策略
Cache 写策略,是指当写操作 Cache 命中时,所作出的数据更新策略:同步更新 Cache 和 主存(Write-through),或 仅更新 Cache(Write-back)。
3.7.3.1 透写(Write-through)
数据同时写入到 Cache 和 主存。这意味着,Cache 和 主存 的数据保持一致。
3.7.3.2 回写(Write-back)
数据仅回写到 Cache,不回写到 主存。很显然,Cache 和 主存 的数据会不一致。
3.8 Cache 和 主存之间写缓冲: Write buffer
为了加快 Cache 回写数据到主存的速度,在 Cache 和 主存之间,加入了 Write buffer,其大小通常是几个 Cache 行。这样在将 Cache 数据回写到主存时,CPU 只需要给 Write buffer 提供一些信息(如数据地址,大小等),发起回写请求后,就不需要等待回写操作完成,可以继续执行后续工作;而后 Write buffer 会在某个时间点完成回写操作。
有的 Write buffer 实现,还支持多个回写请求的合并,即 write merging,又叫做 write combining。write merging 将多个回写操作合并成单个操作,这样可以减少和主存间交互,提高性能。但 write merging 并不总是可行的,譬如与外设的数据交互,可能需要即时完成。
有回写的 Write buffer,自然也有为提高效率的预取缓冲,如用来 指令 prefetch buffer 等。
3.9 Cache 维护操作
3.9.1 Cache invalidate
Cache invalidate 是指清除一个或多个 Cache 行的 Valid 位,Cache 行的数据将丢失。如果被清除的 Cache 行包含合法数据,通常应该先将数据刷回主存,然后再执行清除操作。当然如果不关心这些数据自然就没所谓了。
在复位后,所有的 Cache 行都处于被 Invalidate 了的状态。
3.9.2 Cache clean
Cache clean 是指将包含脏(Dirty)数据的Cache行回写到主存,并清除 Cache 行的 Valid 位。
3.9.3 Cache flush
通常没有对 Cache flush 给出正式定义,通常所说的 Cache flush 是指 Cache invalidate + Cache clean。
3.9.4 Cache lockdown
Cache 随着代码和数据的运行,会被分配到不同位置的代码和数据,这导致 Cache 对性能的提升呈现抖动(不稳定)。可以通过锁定(lockdown)一些关键代码和数据的 Cache 行,这些被锁定的 Cache 行,后续不再参加重新分配,这使得这些映射到被锁定 Cache 行的代码和数据稳定,呈现出稳定的性能提升。
ARM架构支持 Format A,Format B,Format C,Format D 4种格式的 Cache 锁定机制,更多相关细节,可参考 ARM 官方手册,本文不做更多展开。
3.9.5 Cache 操作的目标或范围
Cache 操作可按 Cache 组(Set)、Cache 路(Way)、虚拟地址 实施。
3.10 Cache 性能 和 命中率
要利用 Cache 提高性能,说到底是利用程序执行的时空局限性,尽力的提高 Cache 命中率。一直在说 Cache 命中率,到底什么是 Cache 命中率?Cache 命中率 是指在一定时间内,Cache 命中的次数,通常表示为一个百分比。
对于提高 Cache 命中率(也即提高 Cache 性能),有一些通用性的规则和建议:
. 将近期访问的数据和代码,尽量让它们在地址空间上相邻
. 更小的数据和更小的代码
. 尽量将热点代码和数据组织到相邻位置
. 避免cache行的伪共享:把没有依赖关系的数据,放到不同的 Cache 行,避免写数据时无谓的Cache同步操作
. 保持数据对齐到 cache 行
3.11 内存的 Cache 属性
ARM架构下,将内存分为如下三种类型:
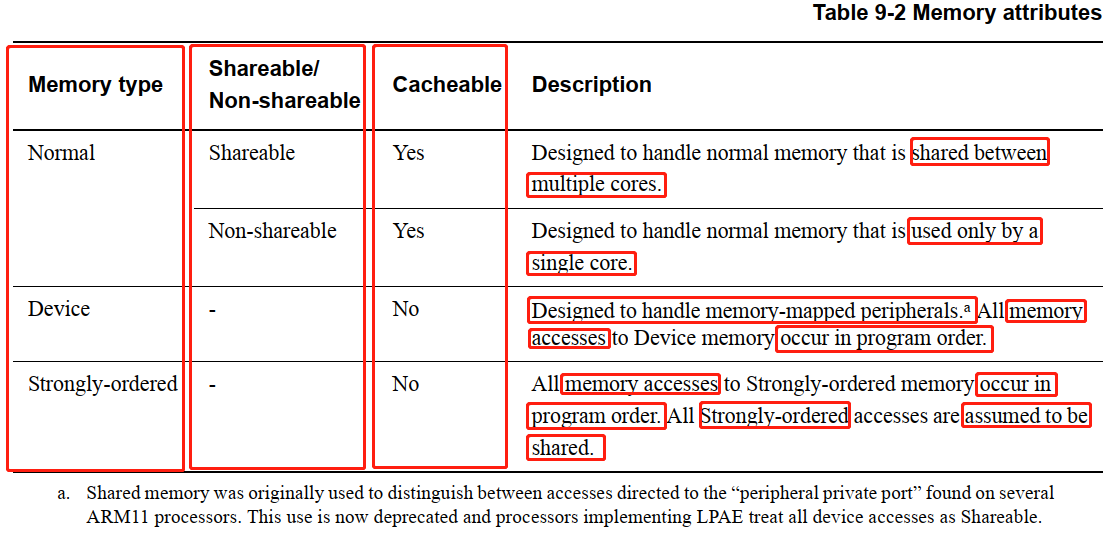
Normal: 如果标记为共享类型(Shareable),则可被多个CPU核访问,数据可被Cache缓存(Cacheable);
如果标记为非共享类型(Non-shareable),则只能被指定的某个CPU和访问,数据可被Cache缓存。
Device: 数据不能被 Cache 缓存。数据的访问遵循编程顺序。
Strongly-ordered: 数据不能被 Cache 缓存。数据的访问遵循编程顺序。
我们仅关注和 Cache 相关部分,只有 Normal 类型的内存,是可被 Cache 缓存。这些相关细节,可以在后面的章节 4. 里看到。
3.12 Cache 一致性
即使跳过 Cache 歧义 和 别名 的坑,Cache 带来的也不只是性能的提升,同样也带来了其它麻烦。当多个不同的 CPU 核访问相同的主存位置,会将数据加载到 CPU 核各自的缓存中,如果其中一个 CPU 核更新了缓存(假设写策略使用 write-back),那另一个 CPU 核可能看不到最新的数据版本,这就是 Cache 一致性问题。当然,不仅不同 CPU 核之间对数据的访问存在一致性问题,CPU 和 外设之间的协同数据访问,也存在一致性问题。
本文不打算对 Cache 一致性 做更多展开,未来可能会单独写一篇关于 ARM Cache 一致性 MESI 协议 的学习文章。
3.13 Cache 和 存储模型
(待续)
3.14 地址翻译 Cache: TLB
3.14.1 什么是 TLB ?
TLB 是 Translation Lookaside Buffer 的缩写,是 MMU(Memory Management Unit) 在执行地址翻译过程中,缓存最近地址翻译数据的一块 Cache。在需要进行地址翻译时,首先从 TLB 缓存查找,如果命中则直接使用 TLB 缓存结果,不必再执行整个地址翻译过程。
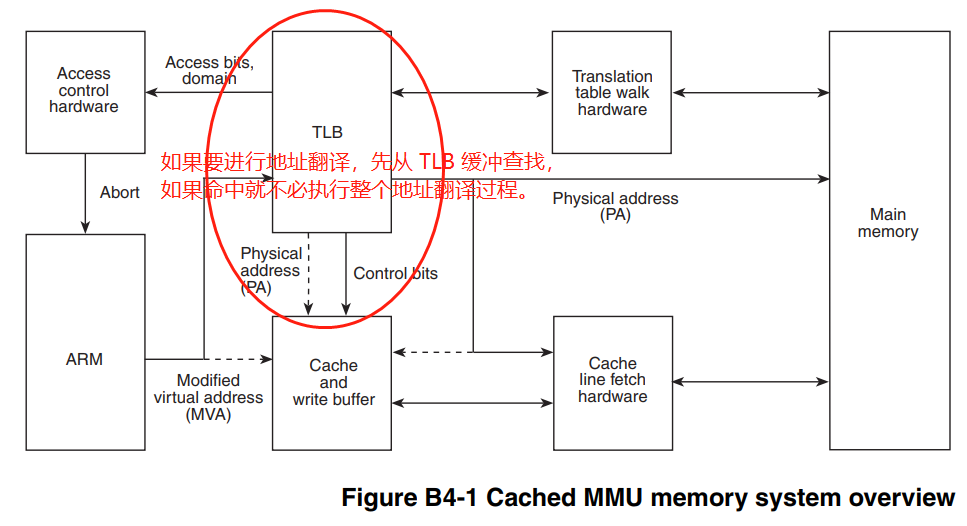
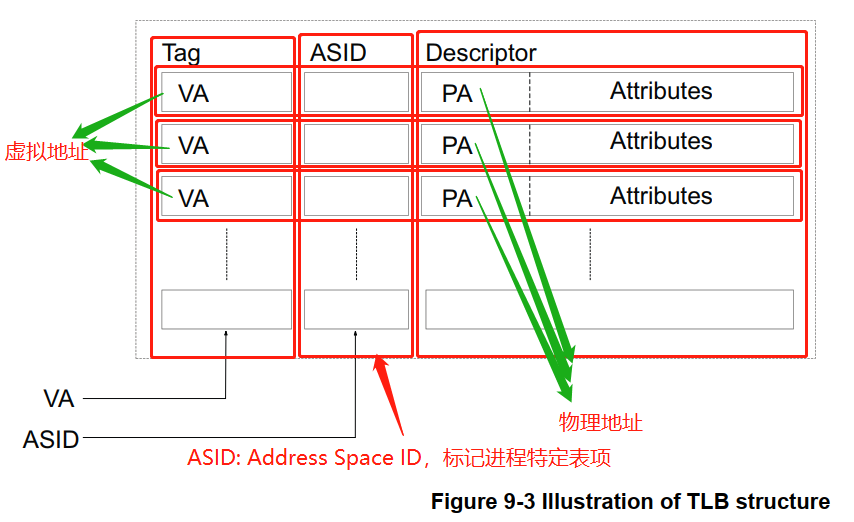
TLB 缓存包含多条 地址翻译数据 的缓存,每条 TLB 缓存的结构大体如下:
3.14.2 TLB 维护操作
TLB 支持 使能(Enable)、使无效(Invalidate) 等操作。系统复位时,所有的 TLB 表项处于禁用状态,此时要使用 TLB ,需要先对 TLB 表项进行 Invalidate 操作,然后再使能。
3.14.3 TLB 刷新
在进程切换时,会伴随着页表的切换,此时 TLB 中缓存着旧进程的虚拟地址翻译数据,如果不进行清理,新进程会在相同虚拟地址下命中这些翻译数据,从而访问错误的物理地址。为了避免这种问题,在进程切换时需要刷新整个 TLB,这很低效,事实上,我们只需要清理那些进程特定的 TLB 表项,那些全局共享的地址空间对应的 TLB 表项,完全没必要进行清理。鉴于此,引入了 ASID(Address Space ID) 和 页表项的 nG(not Global) 比特位。对于每个进程,系统为其分配一个唯一的 ASID,同时将特定于进程页表项的 nG 比特位设为1,标识该页表项是特定于特定进程的;同时对于这些特定于进程的 TLB 表项,同样也用进程 ASID 和 nG 进行标记。这样在进行 TLB 查找时,通过 ASID 和 nG 区分是不是进程特定的表项,提高效率;切换进程时,也可以只清理那些不属于新进程的、非全局(nG=0) TLB 表项。当然,要有位置记录当前进程的 ASID,ARM 设计有用于记录当前进程 ASID 的寄存器。
ARM 架构下,ASID 用 8-bit 或 16-bit 进行标识,所以能分配的 ASID 是有限的,如果当前可分配的 ASID 消耗完了,那需要刷掉 TLB 中所有进程特定的表项,重新来过。
4. Linux 下的 Cache
Cache 的实现,和具体的硬件架构和硬件设计紧密相关,因此 Linux 下 Cache 相关代码也随着具体硬件实现而不同。本文仅就 ARMv7 架构下 Cortex A7 相关代码进行分析。
4.1 Cache 初始化
在内核启动阶段,会进行 Cache 相关的初始化。先来看一下内核中 Cortex A7 处理器的配置数据:
/* arch/arm/mm/proc-v7.S */
/*
* ARM Ltd. Cortex A7 processor.
*/
.type __v7_ca7mp_proc_info, #object
__v7_ca7mp_proc_info:
.long 0x410fc070 /* proc_info_list::cpu_val */
.long 0xff0ffff0 /* proc_info_list::cpu_mask */
__v7_proc __v7_ca7mp_proc_info, __v7_ca7mp_setup
.size __v7_ca7mp_proc_info, . - __v7_ca7mp_proc_info
汇编代码 .type __v7_ca7mp_proc_info, #object 定义了一个 struct proc_info_list 结构体数据,struct proc_info_list 的定义如下:
/* arch/arm/include/asm/procinfo.h */
struct proc_info_list {
unsigned int cpu_val; /* 处理器 ID (寄存器)值 */
unsigned int cpu_mask; /* 处理器 ID 掩码 */
unsigned long __cpu_mm_mmu_flags; /* used by head.S */ /* MMU 相关配置,包括 Cache 配置 */
unsigned long __cpu_io_mmu_flags; /* used by head.S */
unsigned long __cpu_flush; /* used by head.S */ // __v7_ca7mp_setup()
const char *arch_name;
const char *elf_name;
unsigned int elf_hwcap;
const char *cpu_name;
struct processor *proc; // &v7_processor_functions
struct cpu_tlb_fns *tlb; // &v7wbi_tlb_fns
struct cpu_user_fns *user; // &v6_user_fns
struct cpu_cache_fns *cache; // &v7_cache_fns
};
这里只重点关注结构体成员 __cpu_mm_mmu_flags 中 Cache 相关的设置。前面的汇编代码中,__v7_proc 是一个汇编宏,定义了结构体 struct proc_info_list 中除 cpu_val,cpu_mask 外的其它成员的值:
/* arch/arm/mm/proc-v7.S */
.section ".rodata"
string cpu_arch_name, "armv7"
string cpu_elf_name, "v7"
.section ".proc.info.init", #alloc /* 将所有定义的 struct proc_info_list 链接到 .proc.info.init 输出段中 */
/*
* Standard v7 proc info content
*/
.macro __v7_proc name, initfunc, mm_mmuflags = 0, io_mmuflags = 0, hwcaps = 0, proc_fns = v7_processor_functions
ALT_SMP(.long PMD_TYPE_SECT | PMD_SECT_AP_WRITE | PMD_SECT_AP_READ | \
PMD_SECT_AF | PMD_FLAGS_SMP | \mm_mmuflags) /* unsigned long __cpu_mm_mmu_flags; */
.long PMD_TYPE_SECT | PMD_SECT_AP_WRITE | \
PMD_SECT_AP_READ | PMD_SECT_AF | \io_mmuflags /* unsigned long __cpu_io_mmu_flags; */
initfn \initfunc, \name /* unsigned long __cpu_flush; ==> __v7_ca7mp_setup */
.long cpu_arch_name /* const char *arch_name; ==> "armv7" */
.long cpu_elf_name /* const char *elf_name; ==> "v7" */
.long HWCAP_SWP | HWCAP_HALF | HWCAP_THUMB | HWCAP_FAST_MULT | \
HWCAP_EDSP | HWCAP_TLS | \hwcaps /* unsigned int elf_hwcap; */
.long cpu_v7_name /* const char *cpu_name; ==> "ARMv7 Processor" */
.long \proc_fns /* struct processor *proc; ==> v7_processor_functions */
.long v7wbi_tlb_fns /* struct cpu_tlb_fns *tlb; ==> v7wbi_tlb_fns */
.long v6_user_fns /* struct cpu_user_fns *user; ==> v6_user_fns */
.long v7_cache_fns /* struct cpu_cache_fns *cache; ==> v7_cache_fns */
.endm
string cpu_v7_name, "ARMv7 Processor"
...
/*
* 处理器操作接口定义:
* struct processor v7_processor_functions = {
* ._data_abort = v7_early_abort,
* ._prefetch_abort = v7_pabort,
* ._proc_init = cpu_v7_proc_init,
* .check_bugs = cpu_v7_bugs_init,
* ._proc_fin = cpu_v7_proc_fin,
* .reset = cpu_v7_reset,
* ._do_idle = cpu_v7_do_idle,
* .dcache_clean_area = cpu_v7_dcache_clean_area,
* .switch_mm = cpu_v7_switch_mm,
* .set_pte_ext = cpu_v7_set_pte_ext,
* .suspend_size = cpu_v7_suspend_size,
* .do_suspend = cpu_v7_do_suspend,
* .do_resume = cpu_v7_do_resume,
* };
* struct processor 结构体 定义在文件 arch/arm/include/asm/proc-fns.h 中。
*/
@ define struct processor (see <asm/proc-fns.h> and proc-macros.S)
define_processor_functions v7, dabort=v7_early_abort, pabort=v7_pabort, suspend=1, bugs=cpu_v7_bugs_init
/* arch/arm/mm/tlb-v7.S */
/*
* TLB 操作接口 定义:
* struct cpu_tlb_fns v7wbi_tlb_fns = {
* .flush_user_range = v7wbi_flush_user_tlb_range,
* .flush_kern_range = v7wbi_flush_kern_tlb_range,
* .tlb_flags = v7wbi_tlb_flags_smp,
* };
* struct cpu_tlb_fns 结构体 定义在文件 arch/arm/include/asm/tlbflush.h 中。
*/
/* define struct cpu_tlb_fns (see <asm/tlbflush.h> and proc-macros.S) */
define_tlb_functions v7wbi, v7wbi_tlb_flags_up, flags_smp=v7wbi_tlb_flags_smp
/* arch/arm/mm/copypage-v6.c */
struct cpu_user_fns v6_user_fns __initdata = {
.cpu_clear_user_highpage = v6_clear_user_highpage_nonaliasing,
.cpu_copy_user_highpage = v6_copy_user_highpage_nonaliasing,
};
/* arch/arm/mm/cache-v7.S */
/*
* 处理器 Cache (L1 Cache) 操作接口定义:
* struct cpu_cache_fns v7_cache_fns = {
* .flush_icache_all = v7_flush_icache_all,
* .flush_kern_all = v7_flush_kern_cache_all,
* .flush_kern_louis = v7_flush_kern_cache_louis,
* .flush_user_all = v7_flush_user_cache_all,
* .flush_user_range = v7_flush_user_cache_range,
* .coherent_kern_range = v7_coherent_kern_range,
* .coherent_user_range = v7_coherent_user_range,
* .flush_kern_dcache_area = v7_flush_kern_dcache_area,
* .dma_map_area = v7_dma_map_area,
* .dma_unmap_area = v7_dma_unmap_area,
* .dma_flush_range = v7_dma_flush_range,
* };
* struct cpu_cache_fns 结构体 定义在文件 arch/arm/include/asm/cacheflush.h 中。
*/
@ define struct cpu_cache_fns (see <asm/cacheflush.h> and proc-macros.S)
define_cache_functions v7
上面已经给出了所有 Cache 相关接口的定义,接下来看 Cache 的初始化过程。进入内核时,系统先将 L1 Cache 置于无效状态:
/* 内核入口 */
__HEAD
ENTRY(stext)
...
mrc p15, 0, r9, c0, c0 @ get processor id
bl __lookup_processor_type @ r5=procinfo r9=cpuid
movs r10, r5 @ invalid processor (r5=0)? /* r10: 处理器信息指针 (struct proc_info_list *) */
...
bl __create_page_tables // 内核初始页表建立,以及页表相关 Cache 属性配置
...
/* 处理器初始化,包括 Invalidate 所有 L1 Cache */
ldr r12, [r10, #PROCINFO_INITFUNC]
add r12, r12, r10
ret r12 /* CPU 初始化: __v7_ca7mp_setup */
....
ENDPROC(stext)
__create_page_tables: // 内核初始页表建立,以及页表相关 Cache 属性配置
ldr r7, [r10, #PROCINFO_MM_MMUFLAGS] @ mm_mmuflags (struct proc_info_list::__cpu_mm_mmu_flags, Cache 配置)
...
1: orr r3, r7, r5, lsl #SECTION_SHIFT @ flags + kernel base (配置页表项属性,包括 Cache 属性 (PMD_FLAGS_SMP))
str r3, [r4, r5, lsl #PMD_ORDER] @ identity mapping
cmp r5, r6
addlo r5, r5, #1 @ next section
blo 1b
/* arch/arm/mm/proc-v7.S */
__v7_ca7mp_setup:
...
/* arch/arm/mm/cache-v7.S: v7_invalidate_l1() */
bl v7_invalidate_l1 /* 使 L1 Cache 所有 Set/Way 中的 Cache 行无效 (Invalidate) */
...
b __v7_setup_cont
...
__v7_setup_cont:
...
/* 使 L1 指令 Cache 无效 */
mcr p15, 0, r10, c7, c5, 0 @ I+BTB cache invalidate
#ifdef CONFIG_MMU
/* 使所有 TLB 无效 */
mcr p15, 0, r10, c8, c7, 0 @ invalidate I + D TLBs
/* 配置页表基地址到 TTBRx 寄存器 */
v7_ttb_setup r10, r4, r5, r8, r3 @ TTBCR, TTBRx setup
/* 内存区域的 类型 和 属性 寄存器配置 (包括 是否可以加载到 Cache,Cache 的分配、写策略) */
ldr r3, =PRRR @ PRRR
ldr r6, =NMRR @ NMRR
mcr p15, 0, r3, c10, c2, 0 @ write PRRR
mcr p15, 0, r6, c10, c2, 1 @ write NMRR
#endif
dsb @ Complete invalidations
/* 设置 Cache 替换策略,I & D Cache 使能 比特位 (后续在 __turn_mmu_on 中写入到 SCTLR 寄存器,使配置生效) */
adr r3, v7_crval /* ARMv7 的 SCTLR 配置(包括 Cache 配置) */
ldmia r3, {r3, r6}
mrc p15, 0, r0, c1, c0, 0 @ read control register (r0 = SCTLR)
bic r0, r0, r3 @ clear bits them
orr r0, r0, r6 @ set them
/* 返回到 head.S: stext 中 1: b __enable_mmu 处 */
ret lr @ return to head.S:__ret
/* arch/arm/kernel/head.S */
__enable_mmu:
...
b __turn_mmu_on
__turn_mmu_on:
...
mcr p15, 0, r0, c1, c0, 0 /* 启用 当前 CPU 的 MMU,以及 Cache 等其它配置 (r0 的值在前面 __v7_setup_cont 中设置) */
...
/*
* BOOT CPU: 返回到 __mmap_switched 处
* 非 BOOT CPU: 返回到 __secondary_switched 处
*
* BOOT CPU: TTBR0 = TTBR1 = swapper_pg_dir
* 非 BOOT CPU: TTBR0 = idmap_pgd(用于等同映射代码), TTBR1 = swapper_pg_dir ???
*/
ret r3
/* arch/arm/kernel/head-common.S */
__mmap_switched:
adr r3, __mmap_switched_data /* r3 = __mmap_switched_data 虚拟地址 */
...
/*
* r4 = &processor_id (arch/arm/kernel/setup.c)
* r5 = &__machine_arch_type (arch/arm/kernel/setup.c)
* r6 = &__atags_pointer (arch/arm/kernel/setup.c)
* r7 = &cr_alignment (arch/arm/kernel/entry-armv.S)
* sp = 当前 CPU 的 swapper 进程内核栈指针
*/
ARM( ldmia r3, {r4, r5, r6, r7, sp})
/* processor_id = 处理器 ID */
str r9, [r4] @ Save processor ID
/* __machine_arch_type = machine no */
str r1, [r5] @ Save machine type
/* __atags_pointer = DTB 物理地址 */
str r2, [r6] @ Save atags pointer
cmp r7, #0
/* cr_alignment = CP15 控制寄存器 SCTLR 的当前配置值 */
strne r0, [r7] @ Save control register values
b start_kernel /* 跳转到 start_kernel() 执行 */
进入start_kernel() 后,按上面定义的 struct proc_info_list::__cpu_mm_mmu_flags 里,Cache 相关的配置进行 Cache 初始化:
start_kernel()
setup_arch(&command_line)
setup_processor()
/* arch/arm/kernel/setup.c */
static void __init setup_processor(void)
{
unsigned int midr = read_cpuid_id(); /* 读取 CPU ID */
/* 找到预定义的、和 CPU ID 匹配的处理器对象(struct proc_info_list) */
struct proc_info_list *list = lookup_processor(midr); /* arch/arm/mm/proc-v7.S: &__v7_ca7mp_proc_info */
...
#ifdef MULTI_TLB
cpu_tlb = *list->tlb; /* 设置 TLB 操作接口 */
#endif
...
#ifdef MULTI_CACHE
cpu_cache = *list->cache; /* 设置 cache 操作接口 */
#endif
pr_info("CPU: %s [%08x] revision %d (ARMv%s), cr=%08lx\n",
list->cpu_name, midr, midr & 15,
proc_arch[cpu_architecture()], get_cr());
...
#ifdef CONFIG_MMU
/*
* 设置 cache 读写、分配 策略到 @cachepolicy:
* 按 CPU 的 MMU 配置 (list->__cpu_mm_mmu_flags), 从策略表 cache_policies[]
* 中,找到匹配 (list->__cpu_mm_mmu_flags) 的 cache 策略,设定为默认的 cache 策略:
* (write back, write through, non-cachable, bufferable, ...)
* 设置到 @cachepolicy 。
*/
init_default_cache_policy(list->__cpu_mm_mmu_flags);
#endif
...
/* 设置 cache 查找策略到 @cacheid */
cacheid_init();
...
}
/* arch/arm/mm/mmu.c */
/* ARM32 架构支持的 cache 读写、分配 策略 */
static struct cachepolicy cache_policies[] __initdata = {
{
.policy = "uncached",
.cr_mask = CR_W|CR_C,
.pmd = PMD_SECT_UNCACHED,
.pte = L_PTE_MT_UNCACHED,
.pte_s2 = s2_policy(L_PTE_S2_MT_UNCACHED),
}, {
.policy = "buffered",
.cr_mask = CR_C,
.pmd = PMD_SECT_BUFFERED,
.pte = L_PTE_MT_BUFFERABLE,
.pte_s2 = s2_policy(L_PTE_S2_MT_UNCACHED),
}, {
.policy = "writethrough",
.cr_mask = 0,
.pmd = PMD_SECT_WT,
.pte = L_PTE_MT_WRITETHROUGH,
.pte_s2 = s2_policy(L_PTE_S2_MT_WRITETHROUGH),
}, {
.policy = "writeback",
.cr_mask = 0,
.pmd = PMD_SECT_WB,
.pte = L_PTE_MT_WRITEBACK,
.pte_s2 = s2_policy(L_PTE_S2_MT_WRITEBACK),
}, {
.policy = "writealloc",
.cr_mask = 0,
.pmd = PMD_SECT_WBWA,
.pte = L_PTE_MT_WRITEALLOC,
.pte_s2 = s2_policy(L_PTE_S2_MT_WRITEBACK),
}
};
...
/* 设置 cache 读写、分配 策略到 @cachepolicy */
void __init init_default_cache_policy(unsigned long pmd)
{
int i;
initial_pmd_value = pmd;
pmd &= PMD_SECT_CACHE_MASK;
for (i = 0; i < ARRAY_SIZE(cache_policies); i++)
if (cache_policies[i].pmd == pmd) {
cachepolicy = i;
break;
}
if (i == ARRAY_SIZE(cache_policies))
pr_err("ERROR: could not find cache policy\n");
}
/* 设置 cache 查找策略到 @cacheid */
static void __init cacheid_init(void)
{
unsigned int arch = cpu_architecture();
if (arch >= CPU_ARCH_ARMv6) { /* Armv6, Armv7 架构 */
unsigned int cachetype = read_cpuid_cachetype();
if ((arch == CPU_ARCH_ARMv7M) && !(cachetype & 0xf000f)) { /* Cortex-M 系列、不支持 cache 的 CPU */
cacheid = 0;
} else if ((cachetype & (7 << 29)) == 4 << 29) { /* Armv7 架构 */
/* ARMv7 register format */
arch = CPU_ARCH_ARMv7;
cacheid = CACHEID_VIPT_NONALIASING;
switch (cachetype & (3 << 14)) {
case (1 << 14):
cacheid |= CACHEID_ASID_TAGGED;
break;
case (3 << 14):
cacheid |= CACHEID_PIPT;
break;
}
} else { /* Armv6 架构 */
arch = CPU_ARCH_ARMv6;
if (cachetype & (1 << 23))
cacheid = CACHEID_VIPT_ALIASING;
else
cacheid = CACHEID_VIPT_NONALIASING;
}
} else { /* Armv6 之前的架构,使用 VIVT cache 查找策略 */
cacheid = CACHEID_VIVT;
}
pr_info("CPU: %s data cache, %s instruction cache\n",
cache_is_vivt() ? "VIVT" :
cache_is_vipt_aliasing() ? "VIPT aliasing" :
cache_is_vipt_nonaliasing() ? "PIPT / VIPT nonaliasing" : "unknown",
cache_is_vivt() ? "VIVT" :
icache_is_vivt_asid_tagged() ? "VIVT ASID tagged" :
icache_is_vipt_aliasing() ? "VIPT aliasing" :
icache_is_pipt() ? "PIPT" :
cache_is_vipt_nonaliasing() ? "VIPT nonaliasing" : "unknown");
}
4.2 Cache 代码文件组织
按 Cache 层级结构,简单说明下各级 Cache 功能相关实现代码文件。
L1 Cache:
arch/arm/include/asm/glue-cache.h
arch/arm/include/asm/cacheflush.h
arch/arm/mm/cache-v7.S
arch/arm/mm/flush.c
L2 Cache:
arch/arm/mm/cache-l2*.c
TLB:
arch/arm/include/asm/tlbflush.h
arch/arm/kernel/smp_tlb.c
arch/arm/mm/tlb-v7.S
4.3 Cache 操作接口 和 范例
// arch/arm/include/asm/cacheflush.h
/*
* Select the calling method
*/
#ifdef MULTI_CACHE
extern struct cpu_cache_fns cpu_cache;
#define __cpuc_flush_icache_all cpu_cache.flush_icache_all
#define __cpuc_flush_kern_all cpu_cache.flush_kern_all
#define __cpuc_flush_kern_louis cpu_cache.flush_kern_louis
#define __cpuc_flush_user_all cpu_cache.flush_user_all
#define __cpuc_flush_user_range cpu_cache.flush_user_range
#define __cpuc_coherent_kern_range cpu_cache.coherent_kern_range
#define __cpuc_coherent_user_range cpu_cache.coherent_user_range
#define __cpuc_flush_dcache_area cpu_cache.flush_kern_dcache_area
#define dmac_flush_range cpu_cache.dma_flush_range
#else
...
#endif
...
/*
* Flush caches up to Level of Unification Inner Shareable
*/
#define flush_cache_louis() __cpuc_flush_kern_louis()
#define flush_cache_all() __cpuc_flush_kern_all()
static inline void
vivt_flush_cache_range(struct vm_area_struct *vma, unsigned long start, unsigned long end)
{
...
}
static inline void
vivt_flush_cache_page(struct vm_area_struct *vma, unsigned long user_addr, unsigned long pfn)
{
...
}
#ifndef CONFIG_CPU_CACHE_VIPT
#define flush_cache_mm(mm) \
vivt_flush_cache_mm(mm)
#define flush_cache_range(vma,start,end) \
vivt_flush_cache_range(vma,start,end)
#define flush_cache_page(vma,addr,pfn) \
vivt_flush_cache_page(vma,addr,pfn)
#else
...
#endif
#define flush_cache_user_range(s,e) __cpuc_coherent_user_range(s,e)
#define flush_icache_range(s,e) __cpuc_coherent_kern_range(s,e)
#define clean_dcache_area(start,size) cpu_dcache_clean_area(start, size)
使用 Cache 接口可能存在不同的形式,有的是通过架构 cacheflush.h 提供的接口、间接调用架构底层实现进行 Cache 操作,有的是直接调用架构实现的底层接口,这里各给出一个示例:
// 使用 cacheflush.h 提供的接口
remap_pfn_range()
...
flush_cache_range()
...
// 直接使用架构底层接口
dma_sync_single_for_cpu()
arm_dma_sync_single_for_cpu()
__dma_page_dev_to_cpu()
if (dir != DMA_TO_DEVICE) { // DMA: 数据方向为 从 设备 到 CPU
outer_inv_range(paddr, paddr + size) // 将内存区间对应的 L2 cache line 级 cache 置为无效 (Invalidate)
dma_cache_maint_page(page, off, size, dir, dmac_unmap_area)
v7_dma_unmap_area() // 将内存区间对应的 L1 cache line 置为无效(Invalidate)
}
接下来看 TLB 的操作接口 和 范例:
// arch/arm/include/asm/tlbflush.h
...
#ifndef CONFIG_SMP
...
#else
extern void flush_tlb_all(void);
extern void flush_tlb_mm(struct mm_struct *mm);
extern void flush_tlb_page(struct vm_area_struct *vma, unsigned long uaddr);
extern void flush_tlb_kernel_page(unsigned long kaddr);
extern void flush_tlb_range(struct vm_area_struct *vma, unsigned long start, unsigned long end);
extern void flush_tlb_kernel_range(unsigned long start, unsigned long end);
extern void flush_bp_all(void);
#endif
...
进程切换时,会进行 TLB 操作:
/* kernel/sched/core.c */
schedule()
__schedule(false)
rq = context_switch(rq, prev, next, &rf); /* 进程上下文切换 */
struct mm_struct *mm, *oldmm;
...
mm = next->mm;
oldmm = prev->active_mm;
...
if (!mm) {
next->active_mm = oldmm;
mmgrab(oldmm);
enter_lazy_tlb(oldmm, next);
} else
switch_mm_irqs_off(oldmm, mm, next); /* 进程地址空间切换 */
...
/* arch/arm/include/asm/mmu_context.h */
static inline void
switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
#ifdef CONFIG_MMU
unsigned int cpu = smp_processor_id();
if (cache_ops_need_broadcast() &&
!cpumask_empty(mm_cpumask(next)) &&
!cpumask_test_cpu(cpu, mm_cpumask(next)))
__flush_icache_all();
if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next)) || prev != next) {
check_and_switch_context(next, tsk);
if (cache_is_vivt())
cpumask_clear_cpu(cpu, mm_cpumask(prev));
}
#endif
}
/* arch/arm/mm/context.c */
void check_and_switch_context(struct mm_struct *mm, struct task_struct *tsk)
{
unsigned long flags;
unsigned int cpu = smp_processor_id();
u64 asid;
/*
* We cannot update the pgd and the ASID atomicly with classic
* MMU, so switch exclusively to global mappings to avoid
* speculative page table walking with the wrong TTBR.
*/
cpu_set_reserved_ttbr0();
asid = atomic64_read(&mm->context.id);
if (!((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS)
&& atomic64_xchg(&per_cpu(active_asids, cpu), asid))
goto switch_mm_fastpath;
// 分配新的 ASID
raw_spin_lock_irqsave(&cpu_asid_lock, flags);
/* Check that our ASID belongs to the current generation. */
asid = atomic64_read(&mm->context.id);
if ((asid ^ atomic64_read(&asid_generation)) >> ASID_BITS) {
asid = new_context(mm, cpu);
...
asid = find_next_zero_bit(asid_map, NUM_USER_ASIDS, cur_idx);
if (asid == NUM_USER_ASIDS) { // ASID 耗光了,重新分配
generation = atomic64_add_return(ASID_FIRST_VERSION,
&asid_generation);
flush_context(cpu);
...
/* Queue a TLB invalidate and flush the I-cache if necessary. */
cpumask_setall(&tlb_flush_pending); // 需要 flush TLB
...
asid = find_next_zero_bit(asid_map, NUM_USER_ASIDS, 1);
}
...
__set_bit(asid, asid_map);
cur_idx = asid;
cpumask_clear(mm_cpumask(mm));
return asid | generation;
atomic64_set(&mm->context.id, asid);
}
// 刷 TLB
if (cpumask_test_and_clear_cpu(cpu, &tlb_flush_pending)) {
local_flush_bp_all();
local_flush_tlb_all();
}
// 设置当前 CPU ASID 相关数据
atomic64_set(&per_cpu(active_asids, cpu), asid);
cpumask_set_cpu(cpu, mm_cpumask(mm));
raw_spin_unlock_irqrestore(&cpu_asid_lock, flags);
switch_mm_fastpath:
cpu_switch_mm(mm->pgd, mm); // 进程地址空间(mm_struct)切换
}
5. Cache 调试方法
5.1 使用 Cache 调试工具
Linux 的 perf 工具可以用来查看 Cache Miss 的信息,进而用来调试 Cache 相关问题:
$ sudo perf list cache # 查询 perf 支持的 cache 事件
List of pre-defined events (to be used in -e):
L1-dcache-load-misses [Hardware cache event]
L1-dcache-loads [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
branch-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
dTLB-load-misses [Hardware cache event]
dTLB-loads [Hardware cache event]
dTLB-store-misses [Hardware cache event]
dTLB-stores [Hardware cache event]
iTLB-load-misses [Hardware cache event]
iTLB-loads [Hardware cache event]
# perf 记录 cache 事件数据
perf stat -e L1-dcache-load-misses
perf record -e L1-dcache-load-misses
注意,这些 Cache 事件查询都需要硬件底层架构提供支持。
5.2 查询 Cache 信息
$ lscpu
...
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 3072K
...
// 查看 /sys/devices/system/cpu/cpuN/cache 目录
$ ls /sys/devices/system/cpu/cpu0/cache/ -l
total 0
drwxr-xr-x 3 root root 0 9月 17 14:19 index0
drwxr-xr-x 3 root root 0 9月 17 14:19 index1
drwxr-xr-x 3 root root 0 9月 17 14:19 index2
drwxr-xr-x 3 root root 0 9月 17 14:19 index3
drwxr-xr-x 2 root root 0 9月 17 14:20 power
-rw-r--r-- 1 root root 4096 9月 17 14:20 uevent
$ ls -l /sys/devices/system/cpu/cpu0/cache/index0/
total 0
-r--r--r-- 1 root root 4096 9月 17 14:22 coherency_line_size
-r--r--r-- 1 root root 4096 9月 17 14:22 id
-r--r--r-- 1 root root 4096 9月 17 14:19 level
-r--r--r-- 1 root root 4096 9月 17 14:22 number_of_sets
-r--r--r-- 1 root root 4096 9月 17 14:22 physical_line_partition
drwxr-xr-x 2 root root 0 9月 17 14:22 power
-r--r--r-- 1 root root 4096 9月 17 14:22 shared_cpu_list
-r--r--r-- 1 root root 4096 9月 17 14:19 shared_cpu_map
-r--r--r-- 1 root root 4096 9月 17 14:19 size
-r--r--r-- 1 root root 4096 9月 17 14:19 type
-rw-r--r-- 1 root root 4096 9月 17 14:22 uevent
-r--r--r-- 1 root root 4096 9月 17 14:22 ways_of_associativity
$ cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
64
$ cat /sys/devices/system/cpu/cpu0/cache/index0/level
1
$ cat /sys/devices/system/cpu/cpu0/cache/index0/number_of_sets
64
$ cat /sys/devices/system/cpu/cpu0/cache/index0/size
32K
$ cat /sys/devices/system/cpu/cpu0/cache/index0/type
Data
$ cat /sys/devices/system/cpu/cpu0/cache/index0/ways_of_associativity
8
$ getconf -a | grep CACHE
LEVEL1_ICACHE_SIZE 32768
LEVEL1_ICACHE_ASSOC 8
LEVEL1_ICACHE_LINESIZE 64
LEVEL1_DCACHE_SIZE 32768
LEVEL1_DCACHE_ASSOC 8
LEVEL1_DCACHE_LINESIZE 64
LEVEL2_CACHE_SIZE 262144
LEVEL2_CACHE_ASSOC 4
LEVEL2_CACHE_LINESIZE 64
LEVEL3_CACHE_SIZE 3145728
LEVEL3_CACHE_ASSOC 12
LEVEL3_CACHE_LINESIZE 64
LEVEL4_CACHE_SIZE 0
LEVEL4_CACHE_ASSOC 0
LEVEL4_CACHE_LINESIZE 0
还可以通过函数 sysconf(_SC_LEVEL1_DCACHE_LINESIZE) 查询 dCache 行大小,不过这个方法似乎有些场合下不奏效。
6. Cache 性能优化案例
6.1 热点代码 iCache & dCache Miss
频繁被调用的代码,可以通过 LLVM 对 内核 和 应用代码 进行 二进制重排,将热点集中在局部,可以提高 iCache 命中率,还可以减少应用 page 换入换出。
6.2 Cache 伪共享(False Sharing)优化
// false_sharing-1.c
#include <stdio.h>
#include <pthread.h>
#define N_LOOP 1000000000
// thread1_data 和 thread1_data 共享一个 L1 数据 Cache 行
struct
{
int thread1_data;
int thread2_data;
} data;
void *thread1_entry(void *args)
{
int i;
for (i = 0; i < N_LOOP; i++)
data.thread1_data = 1;
}
void *thread2_entry(void *args)
{
int i;
for (i = 0; i < N_LOOP; i++)
data.thread2_data = 2;
}
int main(int argc, char *argv[])
{
pthread_t t1, t2;
pthread_create(&t1, NULL, thread1_entry, NULL);
pthread_create(&t2, NULL, thread2_entry, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}
修改上面代码结构体的定义,将数据 thread1_data 和 thread2_data 隔离到两个不同的 L1 数据 Cache 行:
// false_sharing-2.c
...
// 通过在 thread1_data 和 thread1_data 中间插入 pad[] ,使得
// thread1_data 和 thread1_data 位于两个独立 L1 数据 Cache 行
struct
{
int thread1_data;
char pad[64];
int thread2_data;
} data;
...
编译测试 false_sharing-1.c 和 false_sharing-2.c :
$ gcc -o false_sharing-1 -pthread false_sharing-1.c
$ gcc -o false_sharing-2 -pthread false_sharing-2.c
$ time ./false_sharing-1
real 0m4.125s
user 0m8.236s
sys 0m0.004s
$ time ./false_sharing-2
real 0m2.288s
user 0m4.554s
sys 0m0.004s
可以分别多运行几次,以避免偶发因素导致的错误结论。从多次测试结果看,很明显 false_sharing-2.c 的性能优于 false_sharing-1.c 。注意,代码中的 N_LOOP 数值应该尽可能的大,以使得 thread 1, 2 有机会运行于不同的 CPU 核上,同时,足够多的访存次数,才能够看的到性能的差异。产生性能差异的原因在于,在 false_sharing-1.c 中,当 thread 1,2 运行不同 CPU 核上时,thread1_data 和 thread2_data 会同时位于不同 CPU 核各自的 Cache 行内,当某一个改变了 CPU 改变了 thread1_data 或 thread2_data 时,需要做两个 CPU Cache 数据之间的同步;而 在 false_sharing-1.c 中,由于 thread1_data 和thread2_data 位于不同的 Cache 行,所以改变 thread1_data 或 thread2_data 无需做 Cache 数据同步,因而减少开销,挺高了性能。
7. 参考资料
https://blog.csdn.net/kakaBack/article/details/126537156
https://zhuanlan.zhihu.com/p/577138649
https://www.freesion.com/article/9682678000/