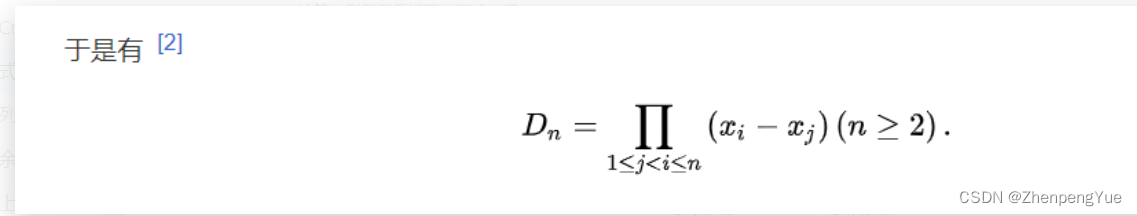文章目录
- 一、OODformer
- 二、Colorization Transformer
- 三、MUSIQ
- 四、LeVIT
- 五、Visformer
- 六、Twins-PCPVT
- 七、Conditional Position Encoding Vision Transformer
- 八、Twins-SVT
- 九、Shuffle Transformer
- 十、RegionViT
- 十一、LocalViT
- 十二、EsViT
- 十三、Multi-Heads of Mixed Attention
一、OODformer
OODformer 是一种基于 Transformer 的 OOD 检测架构,它利用 Transformer 的上下文化功能。 将变压器作为主要特征提取器可以通过视觉注意来利用对象概念及其区分属性以及它们的共现。
OODformer 采用 ViT 及其数据高效变体 DeiT。 每个编码器层由多头自注意力和多层感知块组成。 编码器中的 MSA 和 MLP 层的组合对属性的重要性、关联相关性和共现进行联合编码。 [class] 标记(图像的代表)通过全局上下文整合多个属性及其相关特征。 最后一层的 [class] 标记以两种方式用于 OOD 检测; 首先,它被传递给用于softmax置信度得分,其次用于潜在空间距离计算。

二、Colorization Transformer
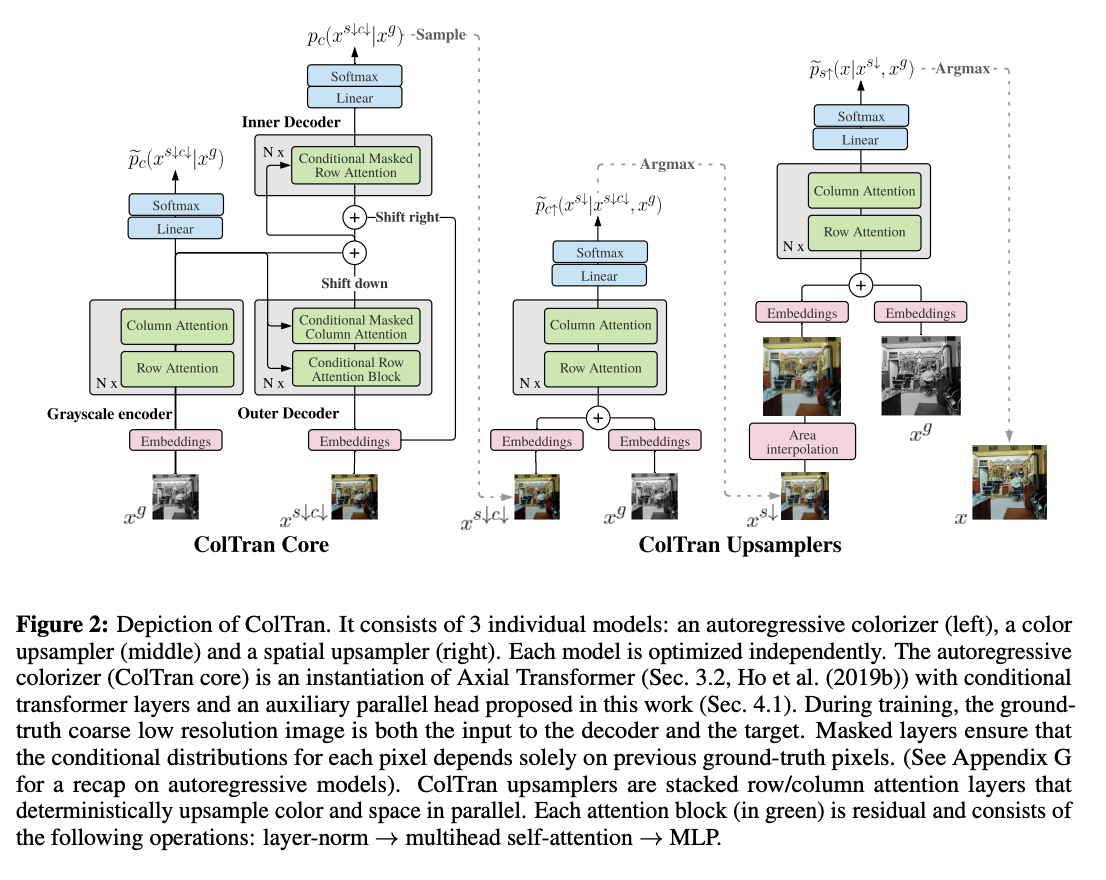
Colorization Transformer 是一种仅由轴向自注意力块组成的概率着色模型。 这些模块的主要优点是能够仅用两层捕获全局感受野。 为了实现高分辨率灰度图像的着色,该任务被分解为三个更简单的顺序子任务:粗略低分辨率自回归着色、并行颜色和空间超分辨率。
对于粗略的低分辨率着色,应用了 Axial Transformer 的条件变体。 作者利用 Axial Transformers 的半并行采样机制。 最后,采用快速并行确定性上采样模型将粗略彩色图像超分辨率为最终的高清晰度图像。
三、MUSIQ
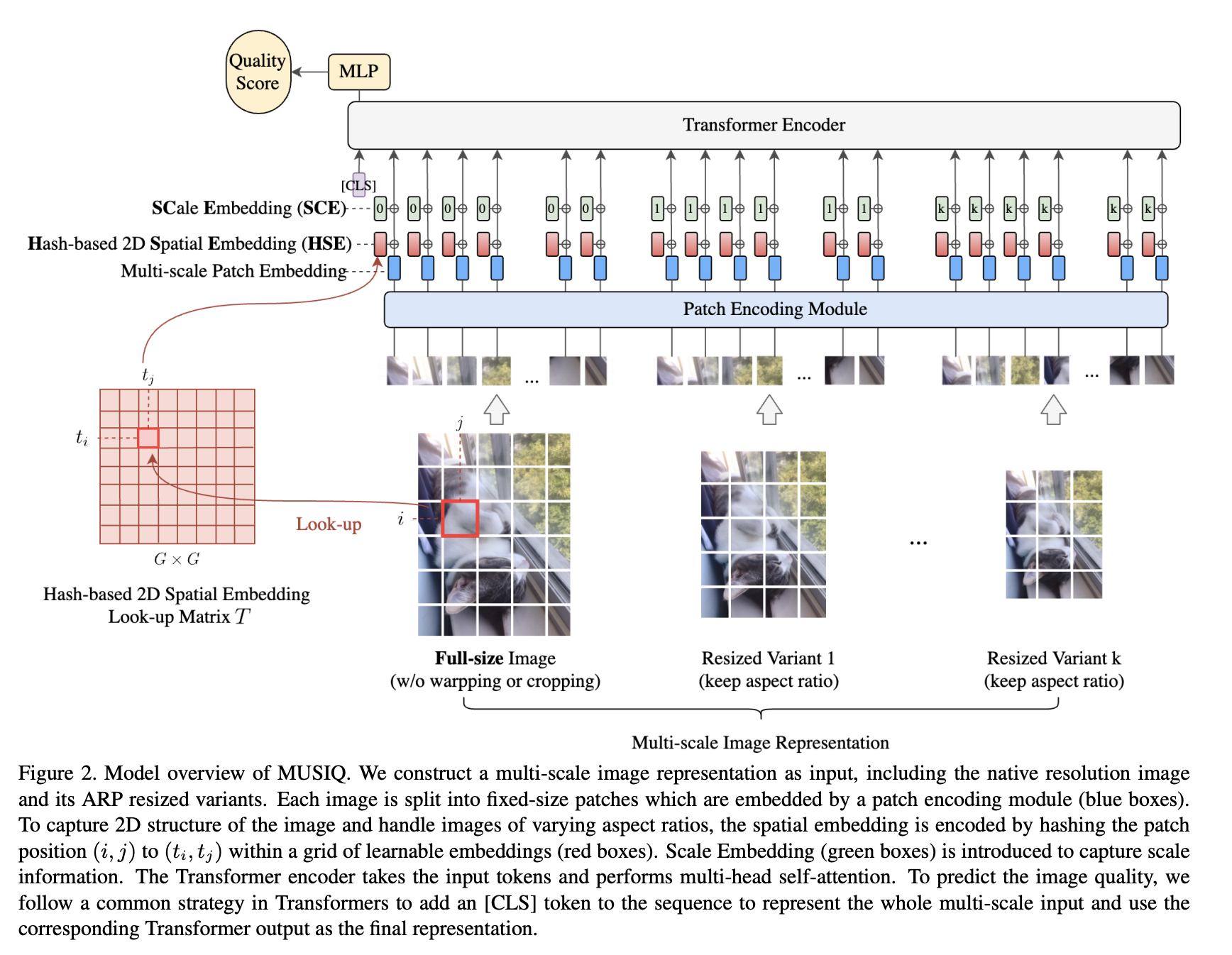
MUSIQ(多尺度图像质量转换器)是一种基于 Transformer 的多尺度图像质量评估模型。 它处理具有不同尺寸和纵横比的原始分辨率图像。 在 MUSIQ 中,我们构建了一个多尺度图像表示作为输入,包括原始分辨率图像及其 ARP 调整大小的变体。 每个图像被分割成固定大小的补丁,这些补丁由补丁编码模块(蓝色框)嵌入。 为了捕获图像的 2D 结构并处理不同纵横比的图像,通过散列补丁位置对空间嵌入进行编码在可学习嵌入的网格内(红色框)。 引入尺度嵌入(绿色框)来捕获尺度信息。 Transformer 编码器获取输入标记并执行多头自注意力。 为了预测图像质量,MUSIQ 遵循 Transformers 中的常见策略,在序列中添加 [CLS] 标记来表示整个多尺度输入,并将相应的 Transformer 输出用作最终表示。
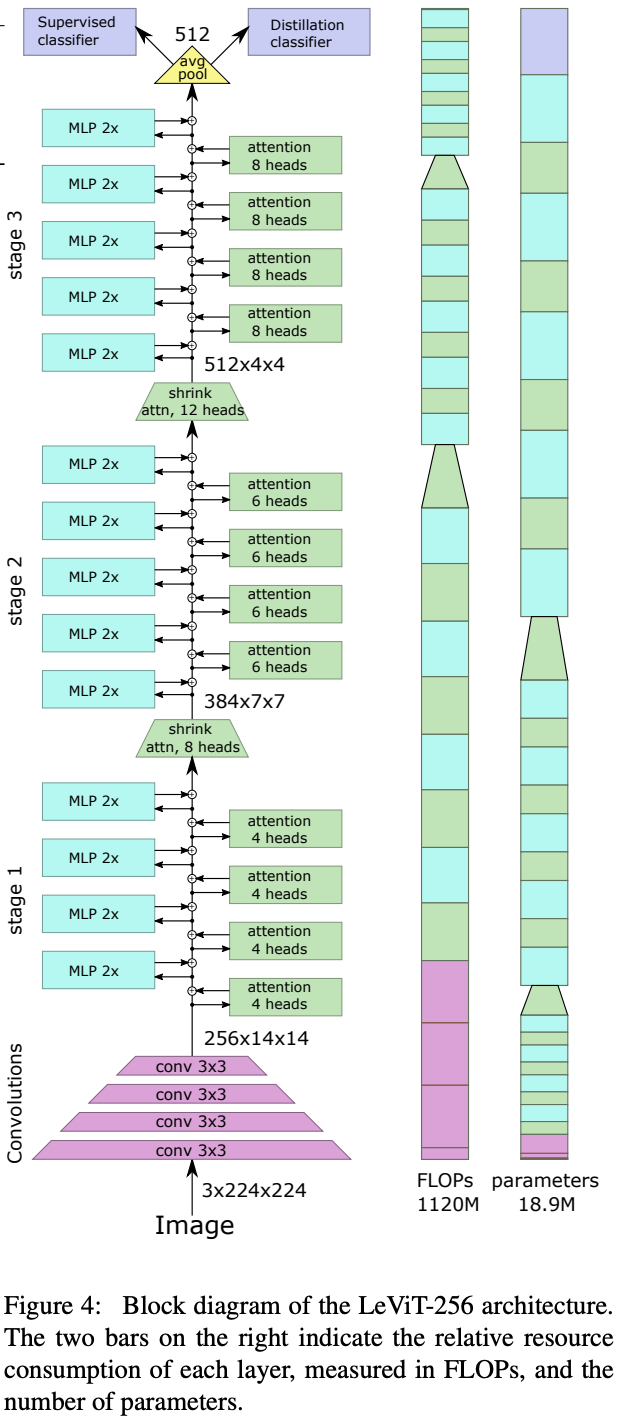
四、LeVIT
LeVIT 是一种用于快速推理图像分类的混合神经网络。 LeViT 是变压器块的堆栈,具有池化步骤来降低激活图的分辨率,就像经典卷积架构中一样。 这用带有池化的金字塔取代了 Transformer 的统一结构,类似于 LeNet 架构
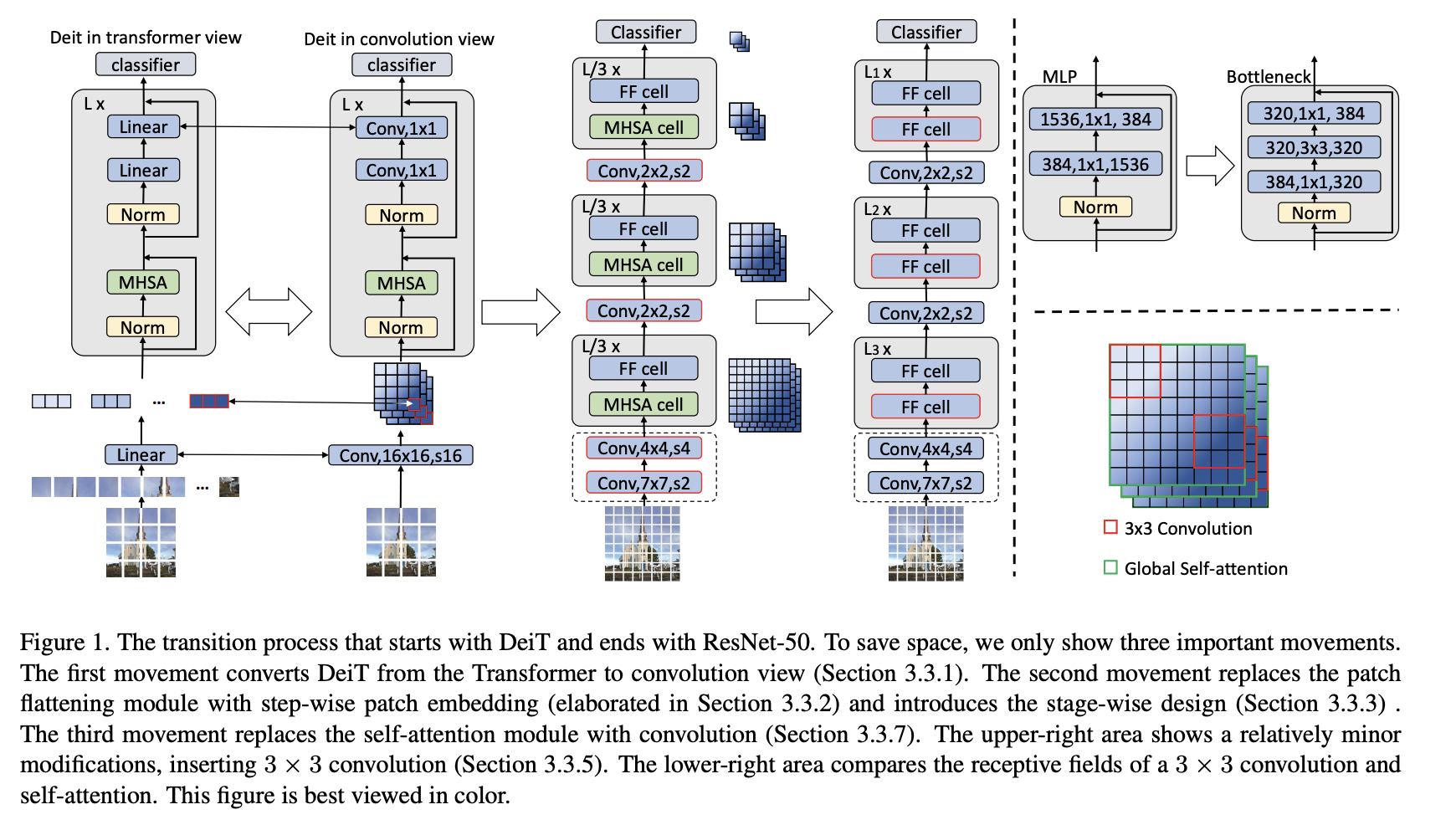
五、Visformer
Visformer,或视觉友好的 Transformer,是一种将基于 Transformer 的架构特征与卷积神经网络架构的特征相结合的架构。 Visformer 采用分级设计,具有更高的基础性能。 但自注意力仅在最后两个阶段使用,考虑到即使 FLOP 平衡,高分辨率阶段的自注意力也相对低效。 Visformer 在第一阶段采用瓶颈块,并在受 ResNeXt 启发的瓶颈块中使用 3 × 3 组卷积。 它还引入了 BatchNorm 来修补嵌入模块,就像 CNN 中一样。
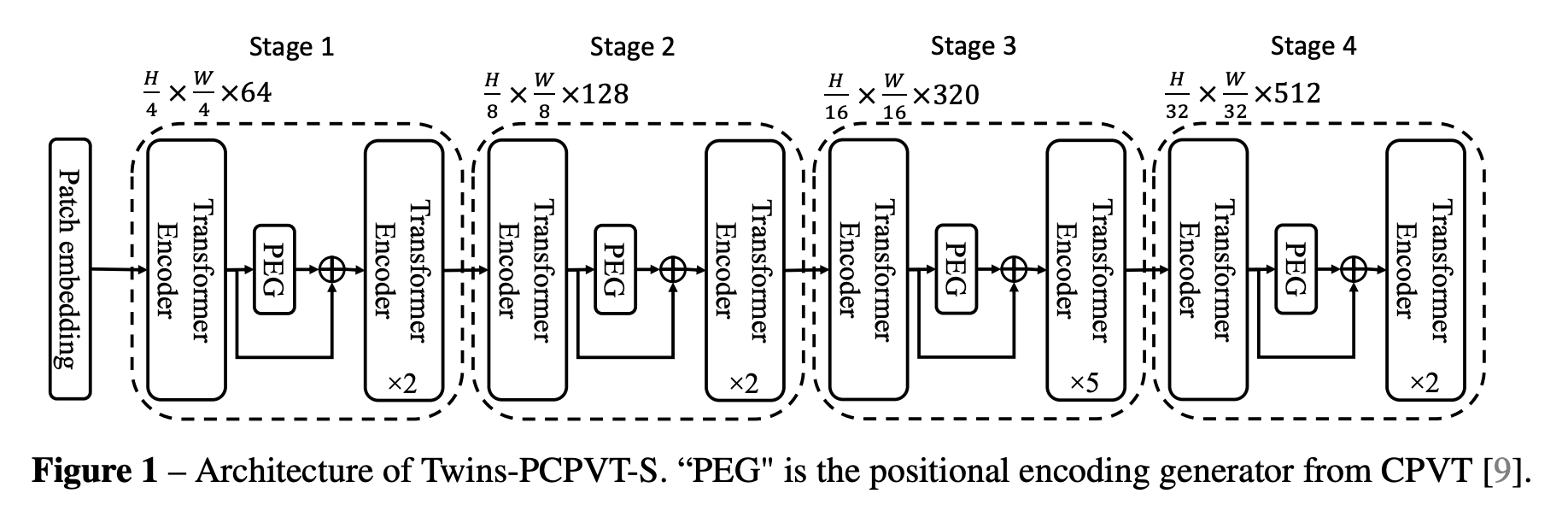
六、Twins-PCPVT
Twins-PCPVT 是一种视觉变换器,它将全局注意力(特别是 Pyramid Vision Transformer 中提出的全局子采样注意力)与条件位置编码(CPE)相结合,以取代 PVT 中使用的绝对位置编码。
生成 CPE 的位置编码生成器 (PEG) 放置在每级的第一个编码器块之后。 使用最简单的 PEG 形式,即没有批量归一化的 2D 深度卷积。 对于图像级分类,在 CPVT 之后,删除类标记,并在阶段结束时使用全局平均池化。 对于其他视觉任务,遵循PVT的设计。
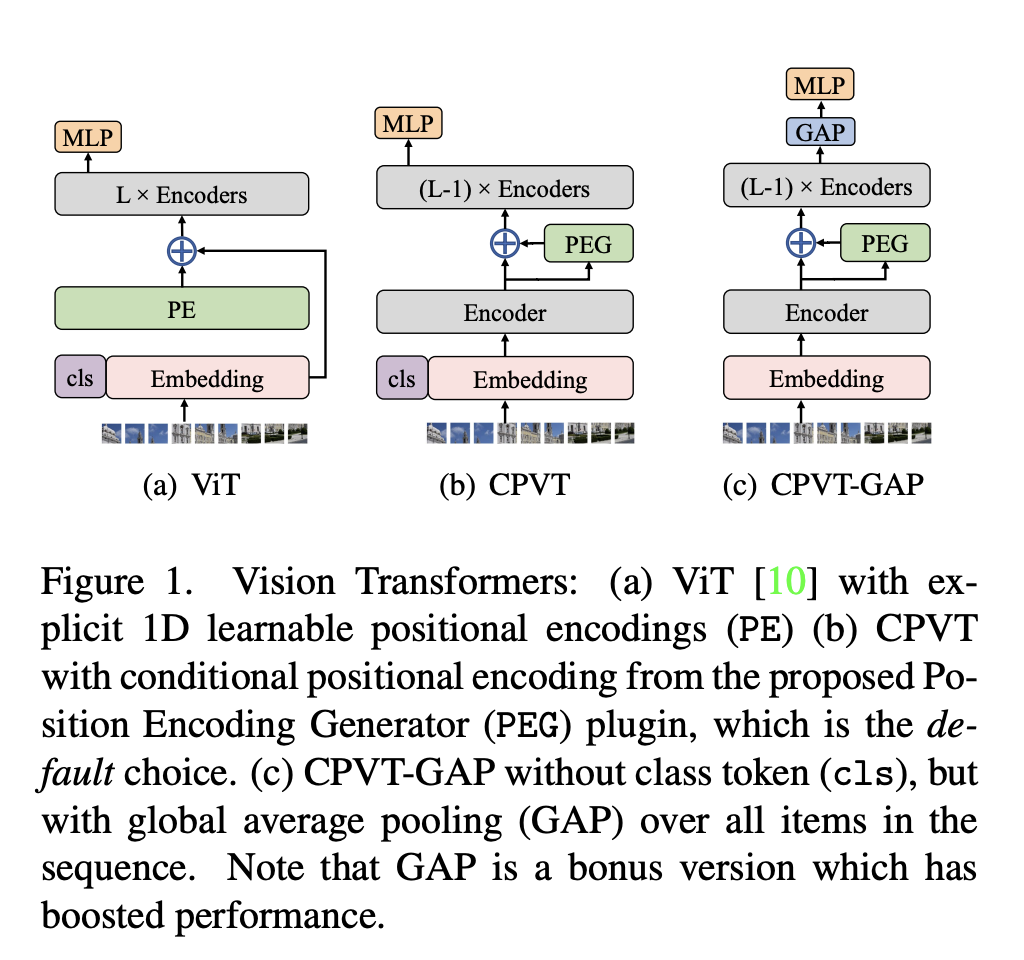
七、Conditional Position Encoding Vision Transformer
CPVT(条件位置编码视觉变换器)是一种利用条件位置编码的视觉变换器。 除了新的编码之外,它遵循 ViT 和 DeiT 相同的架构。
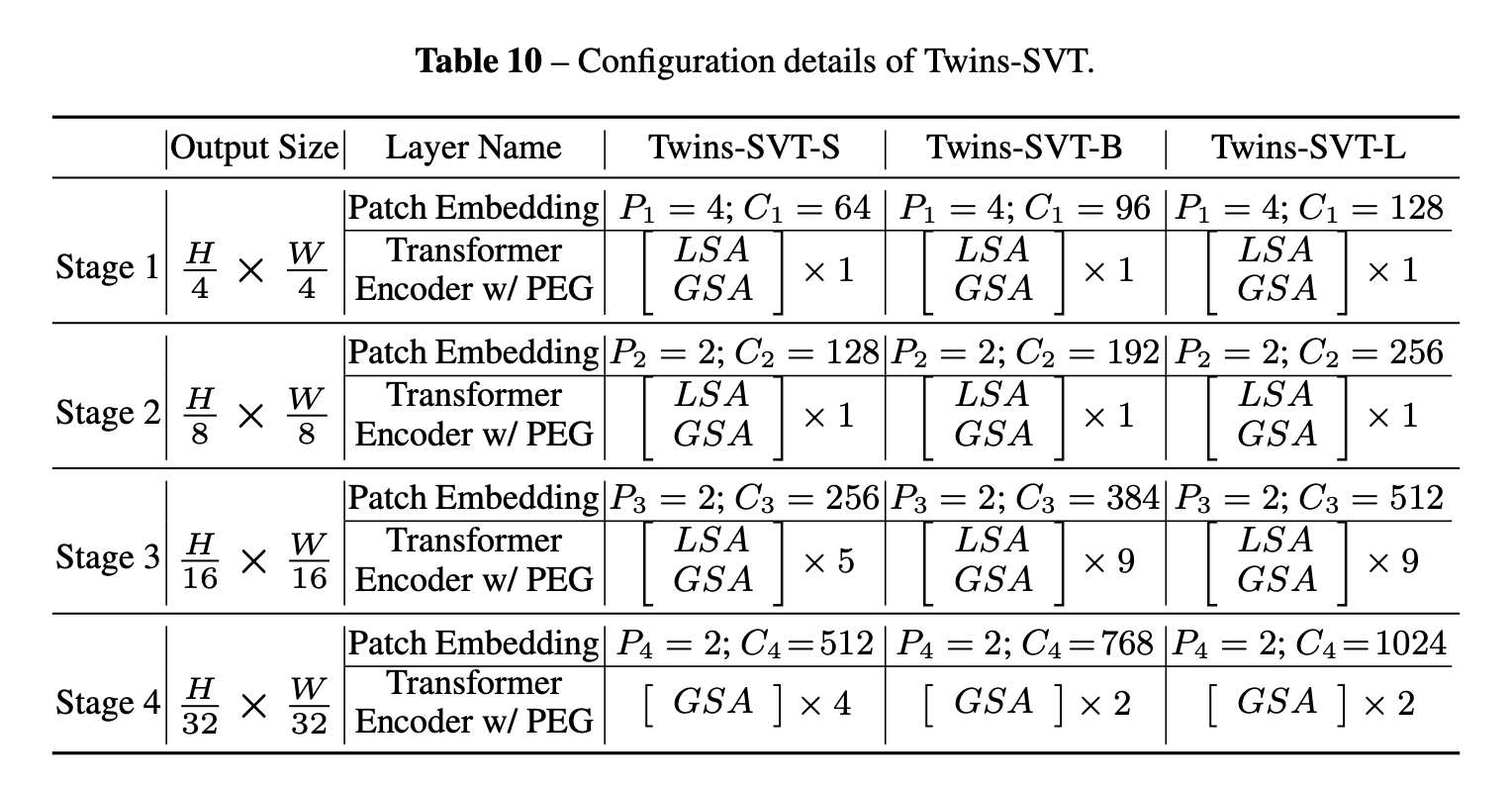
八、Twins-SVT
Twins-SVT 是一种视觉变换器,它利用空间可分离注意力机制(SSAM),该机制由两种类型的注意力操作组成:(i)局部分组自注意力(LSA)和(ii)全局子采样 注意(GSA),其中LSA捕获细粒度和短距离信息,GSA处理长距离和全局信息。 除此之外,它还利用条件位置编码以及 Pyramid Vision Transformer 的架构设计。
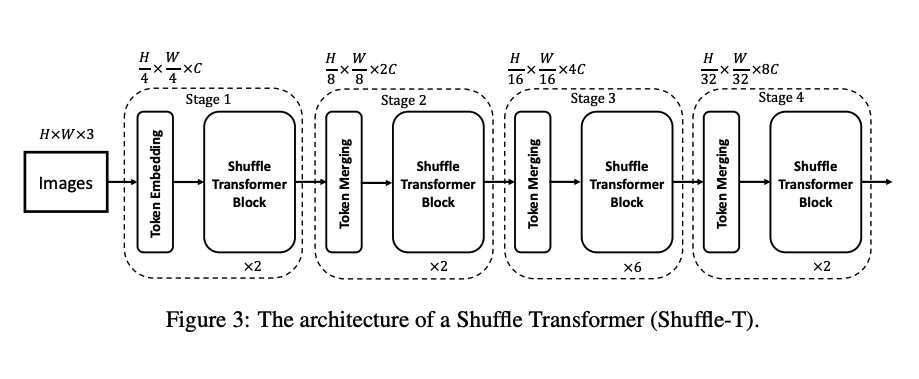
九、Shuffle Transformer
Shuffle Transformer 模块由 Shuffle Multi-Head Self-Attention 模块 (ShuffleMHSA)、Neighbor-Window Connection 模块 (NWC) 和 MLP 模块组成。 为了引入跨窗口连接,同时保持非重叠窗口的高效计算,提出了一种在连续的 Shuffle Transformer 块中交替使用 WMSA 和 Shuffle-WMSA 的策略。 第一个基于窗口的 Transformer 块使用常规窗口分区策略,第二个基于窗口的 Transformer 块使用基于窗口的自注意力和空间混洗。 此外,每个块中还添加了邻居窗口连接模块(NWC),以增强邻居窗口之间的连接。 因此,所提出的洗牌变压器块可以构建丰富的跨窗口连接并增强表示。 最后,连续的 Shuffle Transformer 块计算如下:

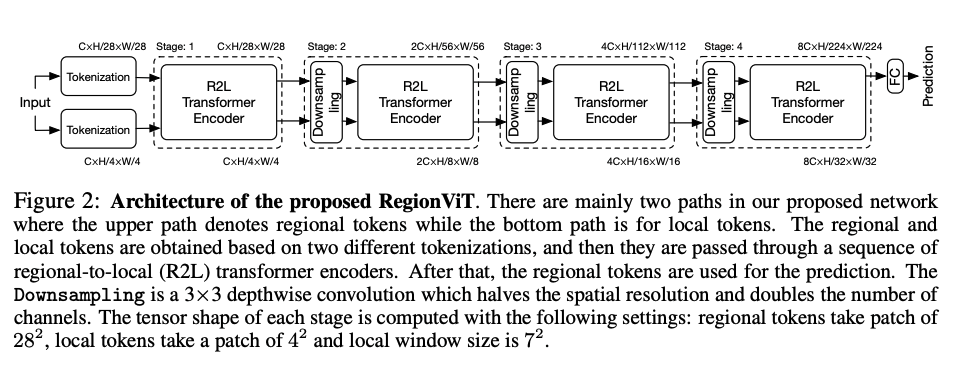
十、RegionViT
RegionViT 由两个标记化过程组成,将图像转换为区域标记(上方路径)和本地标记(下方路径)。 每个标记化都是具有不同补丁大小的卷积,在第 1 阶段,两组令牌通过建议的区域到本地转换器编码器传递。 然而,在后期,为了平衡计算负载并获得不同分辨率的特征图,该方法使用下采样过程将空间分辨率减半,同时在区域和局部标记上将通道尺寸加倍,然后再进入下一个阶段 阶段。 最后,在网络的末端,它简单地平均剩余的区域标记作为分类的最终嵌入,而检测在每个阶段使用所有本地标记,因为它提供了更细粒度的位置信息。 通过金字塔结构,ViT 可以生成多尺度特征,因此可以轻松扩展到更多视觉应用,例如对象检测,而不仅仅是图像分类。
十一、LocalViT
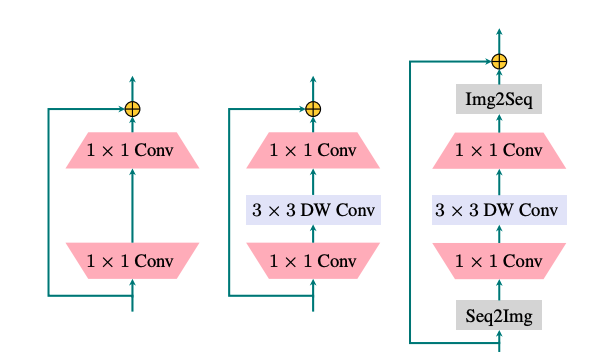
LocalViT 旨在引入深度卷积来增强 ViT 的局部特征建模能力。 如图(c)所示,该网络通过深度卷积(用“DW”表示)将局域机制引入到变压器中。 为了应对卷积运算,通过“Seq2Img”和“Img2Seq”添加序列和图像特征图之间的对话。 计算如下:
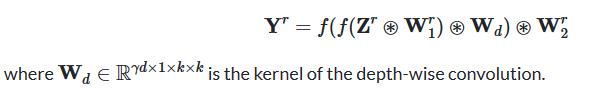
输入(标记序列)首先被重塑为在 2D 晶格上重新排列的特征图。 将两个卷积和一个深度卷积应用于特征图。 特征图被重塑为一系列标记,这些标记被网络变压器层的自注意力所使用。
十二、EsViT
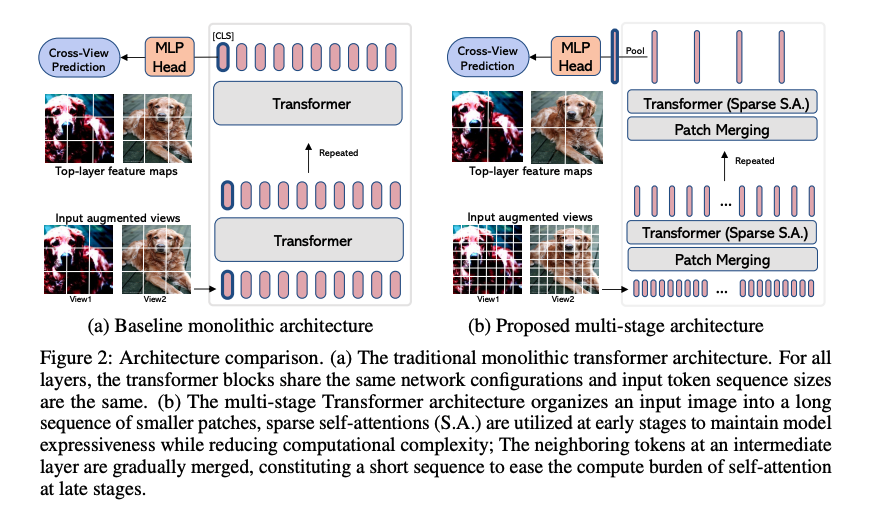
EsViT 提出了两种开发高效自监督视觉转换器以进行视觉表示学习的技术:具有稀疏自注意力的多阶段架构和新的区域匹配预训练任务。 多级架构降低了建模复杂性,但代价是失去了捕获图像区域之间细粒度对应关系的能力。 新的预训练任务允许模型捕获细粒度的区域依赖性,从而显着提高学习视觉表示的质量。
十三、Multi-Heads of Mixed Attention
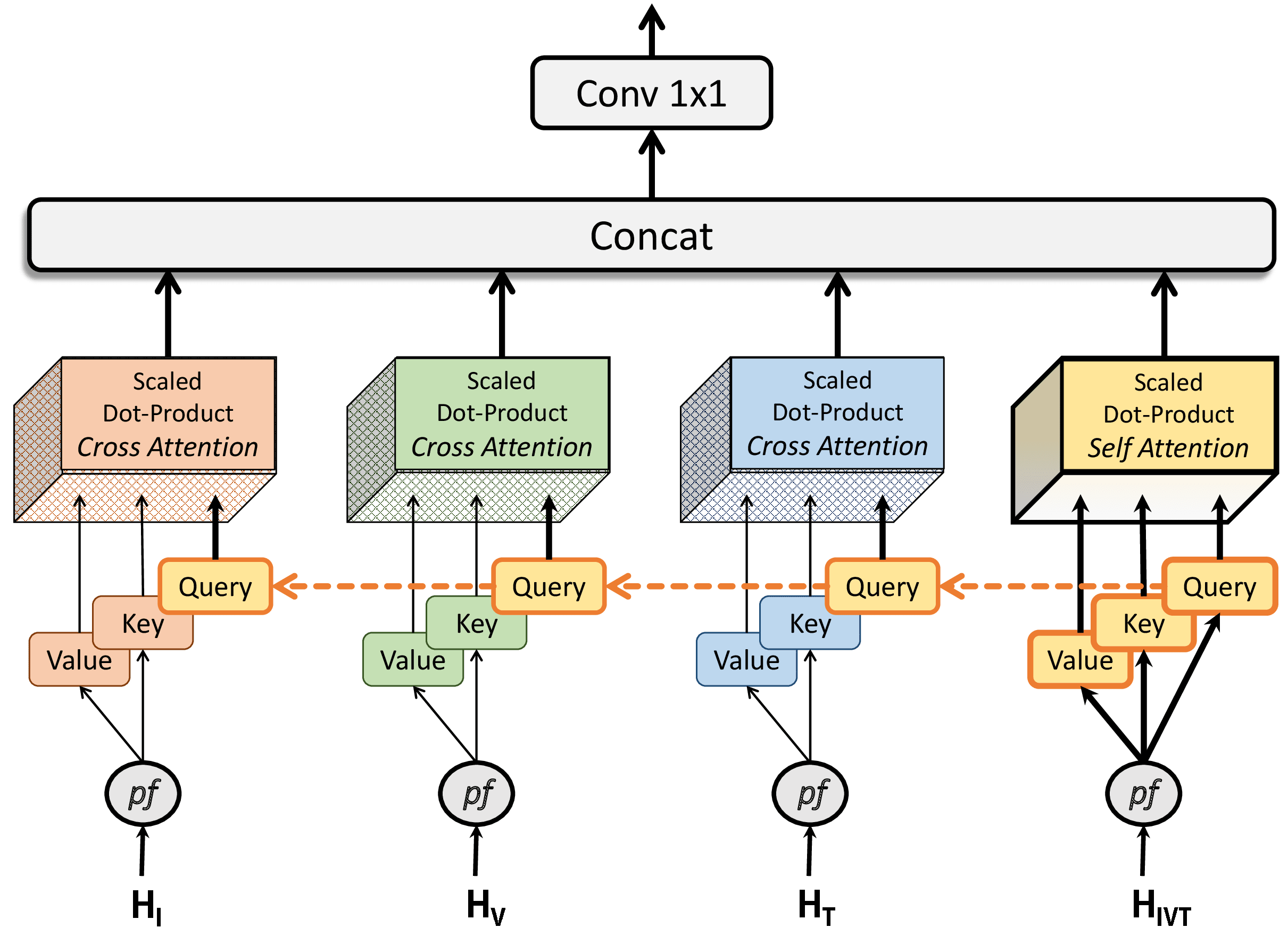
混合注意力的多头结合了自我注意力和交叉注意力,鼓励对各种注意力特征中捕获的实体之间的交互进行高级学习。 它由多个注意力头构建,每个注意力头都可以实现自我注意力或交叉注意力。 自注意力是指关键特征和查询特征相同或来自相同的领域特征。 交叉注意力是指关键特征和查询特征是由不同的特征生成的。 MHMA 建模允许模型识别不同域的特征之间的关系。 这在涉及关系建模的任务中非常有用,例如人与物体交互、工具与组织交互、人机交互、人机界面等。